
基于数据挖掘技术的天然气价格预测方法研究
2020-03-11 10:48王建良雷昌然
中国矿业 2020年2期
王建良,雷昌然
(1.中国石油大学(北京)经济管理学院,北京 102249;2.中国石油大学(北京)中国油气产业发展研究中心,北京 102249)
天然气作为一种低碳的化石能源,在应对气候变化、改善空气等方面具有巨大的优势。大力开发和利用天然气已成为世界多国能源战略的重要构成。而天然气价格对于天然气产业的发展和天然气相关企业的生产经营有着重要的影响。对天然气价格的预测也是国内外学术界和产业界所关注的热点话题。本文重点尝试采用一种改进的数据挖掘技术对天然气价格进行预测。
1 相关研究文献评述
针对天然气价格的预测研究,国内外学者已作了大量的研究工作。国内方面,范贻昌等[1]认为油品价格与天然气价格有着密切的关系,前者的变化对后者有着重要的影响,因此可以通过对油品价格序列的预测来间接预测天然气价格,其采用的预测方法是时间序列中多维自回归模型。吴东武等[2]指出,学术界有关天然气价格预测的研究常围绕天然气价格的影响因素进行,忽略了天然气市场自身的“异质性”问题,因此根据天然气市场的异质性,构建了异质自回归模型,并将其应用到天然气价格预测中,取得了较好的预测效果。上述研究都是针对天然气现货价格的研究,也有一些学者对天然气期货价格进行研究。例如,胡创荣等[3]建立了修正的Markov模型,对纽约商业交易所天然气期货价格序列走势进行了实证研究,结果表明可以通过建立一个描述天然气期货价格变化的Markov模型来近似地估计天然气未来期货价格。邢文婷等[4]认为天然气期货价格序列具有明显的均值回复和跳跃特征,与经典的天然气期货价格模型相比,考虑这种价格跳跃性的期货定价模型具有更好的预测能力。

上述研究对天然气价格的预测都有着重要的贡献,且提供了多种多样的预测方法,如回归预测、神经网络预测、小波分析等,这些方法的一个共同特点就是基于对有限历史时间序列数据的分析。但是需要注意的是,这些分析对历史时间序列数据所蕴含的信息或规律的挖掘都是相对较浅的。近年来,数据挖掘技术的出现和发展为充分挖掘数据背后蕴含信息起到了很好的支撑作用,该方法已经被广泛地应用到电力价格等其他价格的预测当中[8]。本文的主要目的是将数据挖掘技术引入到天然气价格的预测领域,同时对现有的基于数据挖掘的价格预测方法进行改进,构建一种基于改进的数据挖掘的天然气价格预测方法。
2 基于数据挖掘的天然气价格预测方法及其改进
随着现代数据获取技术和计算机网络技术的迅速发展,数据资源急剧膨胀。海量的数据是一个巨大的宝库,其中必然蕴含着某些为人所感兴趣的规律。这些知识规律隐含在海量数据的深层,常规的技术很难有效获得,需要利用新的理论和技术来发现和利用。数据挖掘(data mining,DM)正是从这些拥有海量数据的数据库中抽取隐含的、用户感兴趣的知识,并发现其中有用特征的理论、方法和技术[9-11]。
2.1 基于数据挖掘的传统价格预测模型
基于数据挖掘的价格预测通常是指采用数据挖掘中相似性搜索方法,对目标时间序列进行分析,进而对价格进行预测。该方法较为成熟,且广泛运用在电力价格[12]、股票价格[13]、水文情况[14]和交通流量[15]等预测中。其本质是从海量历史数据中查找与当前时间序列相似的序列,通过查找到的一组或若干组序列来预测未来的趋势。具体过程如下:首先,借助数据挖掘算法获取全部模式序列;其次,确定适当的长度,即在全部序列集合中截取当前待查找序列——目标序列;然后,在历史序列中搜索,若发现与目标序列相似的序列,则将该序列下一天的价格计入结果集;最后,对结果集进行处理,得到最终预测结果。
在上述分析过程当中,全部模式序列的获取、相似序列的搜索和对结果集的处理是关键。因此,我们对这三方面进行具体介绍。
2.1.1 全部模式序列的获取
聚类分析是一种无监督学习算法,是将数据划分成群组的过程,是目前获取全部模式序列的主要方法[16]。聚类分析有多种不同的算法,大致可分为层次聚类算法、分割聚类算法、基于约束的聚类算法、机器学习中的聚类算法和用于高维数据的聚类算法[17]。具体而言,分割聚类算法中K-means算法比较适合运用在时间序列数据分析问题中,因此在时间序列数据的全部模式序列获取方法中应用最为广泛[18-19]。
2.1.2 相似序列的搜索
经过聚类分析获取全部模式序列后,下一步就要进行相似序列搜索工作,该工作是一个数据查找和对比过程,一般借助于计算机程序实现。而确保其实现最佳结果的核心是对相似做出合理判定。这就引出了差异度θ(θ≥0)和序列相似度D(D≥0)的概念。对于给定差异度θ,如果序列值α和序列值β间的相似度D≤θ,则可认为序列α和序列β在给定差异度θ下是相似的。序列相似度D常用欧式距离[20]计算见式(1)。

(1)
式中:α(i)、β(i)分别为序列α和序列β的第i个元素;m为序列元素个数。
2.1.3 对结果集的处理
相似性搜索工作结束后,还需要对结果集进行处理。最终的结果集包含一个或数个价格数据。对结果集中价格数据的处理是预测的关键,也是预测的最后一步,直接影响最终预测结果。传统对结果集的处理主要是采用简单的均值计算。具体而言,如果结果集中包含n个价格,则最终预测结果F计算见式(2)。

(2)
2.2 基于数据挖掘的改进的价格预测模型
前文所述的传统模型在众多领域都取得了较好的预测效果,然而该模型仍然存在一些缺陷和不足,导致预测结果和实际情况存在一定的误差。因此,本文在传统方法的基础上做出了两点改进。
2.2.1 差异度自动调整机制
在匹配历史序列时,需要设定合适的差异度θ。传统方法中,一般是根据经验人为设定差异度。如果对θ设定过高,会将大量本不需要的相似度较小的序列引入结果集,导致预测产生误差。如果对θ设定过低,则会出现无法查找到相似序列的情况,即结果集为空集,无法得到预测价格。为避免错误情况出现,提高预测准确度,本文设计了一种自动调整机制。该机制的原理是在全部检索完成后,先对结果集进行检查。如果判断结果集为空,则降低相似度要求,而后再次重复检索过程。具体步骤如下:①检索历史数据库,如果相似度符合要求,则将下一天的价格数据计入结果集;②检索完毕,判断结果集是否为空,若不为空,转到④,若为空,转到③;③启动调整机制,适当降低差异度要求,重复①和②;④对结果集进行处理。
显然,该机制中选择不同差异度降低量会影响求得结果的速度,可根据实际的时间限制情况进行调整。
2.2.2 结果集加权平均计算
传统方法在对预测结果进行处理时,采用了简单平均值法,此种算法是假设匹配到的不同时期的序列对最终结果的影响是相同的。显然,这种假设有很大的局限性。当目标序列和匹配序列时间距离较近时,两个序列所处时期的自然环境和社会环境差异较小,匹配序列对结果的影响程度较大,反之则较小。
因此,本文基于有关研究[21-23],提出用赋予权重的方式改进前文提到的传统结果集处理方法。赋权方法的核心在于权值的引入。根据前文所述可知,针对同一目标序列,来自不同时期的匹配对最终结果的影响不同。基于这种思想,在历史数据库检索完毕确认结果集非空后,在对结果集的处理过程中引入权值ω。权值ω定量反映了赋予权重的大小,即历史序列对结果的影响程度。其定义见式(3)。

(3)
式中:Len为结果集中的历史价格和目标序列的时间距离,当Len很小,即距离很近时,权值ω接近1,反之;当Len很大时,权值是趋于0的很小的数,应用此定义,会使得距离目标序列较近的序列获得高权重;Ω为控制权重增大或减小比例的参数。
有了权重的定义之后,可将权重的概念引入结果集的汇总计算中。引入权值后,最终预测结果F计算见式(4)。
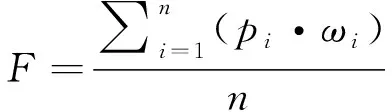
(4)
3 实证分析
3.1 数据来源及预处理
本文以对天然气日度现货价格的预测为例进行方法的验证,所使用的数据集来自于Henry Hub natural gas spot price。该数据集提供了1997年1月7日~2018年1月1日的天然气价格数据。该数据集主要包含两个字段,分别为日期和天然气价格。整体历史数据走势如图1所示。

图1 美国Henry Hub天然气日度现货价格Fig.1 Daily Henry Hub natural gas spot price for the U.S.(资料来源:http:∥tonto.eia.gov/dnav/ng/hist/rngwhhdd.htm)
为提高数据挖掘的效率和质量,在获得天然气时间序列价格后,首先是要对所获得的价格数据进行标准化预处理,即采取一些措施使得数据变得干净、准确和简洁。这是因为直接获取的原始数据存在杂乱性、重复性和不完整性等问题[24-26]。在时间序列数据的预处理中,通常有清理、集成、转化和归约等方法[27]。
本文采用一种常用的比例平均值方法来对历史数据进行标准化处理[28],计算见式(5)。

(5)


(6)
式中,n为当月天数。
3.2 基于改进方法的预测结果
为了验证预测效果,本文将历史价格数据的时间轴划分为两部分:2017年1月之前的数据作为训练集;2017年1月~2017年12月的数据作为测试数据。为了更直观的展示,我们将测试数据集进一步划分为12个子时段,即每月对应一个时段。然后用本文提出的改进的模式序列相似性搜索的天然气价格预测方法(adjusted pattern sequence similarity search,APSS)对2017年以前的数据进行训练测试,并对2017年1月到12月的天然气价格进行预测,最后与实际值进行对比。为了量化对比结果,本文采用学术界常用的MRE(mean relative error)和MAPE(mean absolute percentage error)两个指标来衡量天然气价格预测的准确性[29-30]。MER和MAPE的计算见式(7)和式(8)。
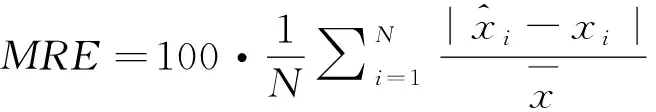
(7)

(8)
本文预测结果如图2所示。从图2中可以看出,本文对于日度天然气价格的预测结果与实际值拟合程度很高,其预测的MRE和MAPE见表1,可以看出12个时段内,除了第10个时段,即2017年10月的MRE和MAPE超过10%以外,其余基本在7%以内,而12个阶段的整体MRE和MAPE为5.41%和5.65%。
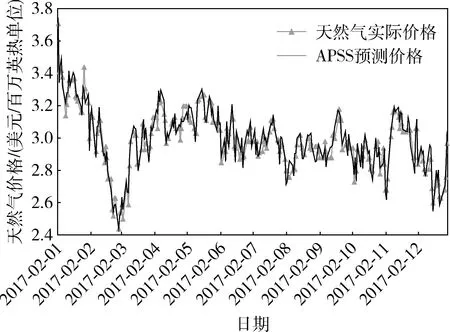
图2 APSS整体预测结果Fig.2 The overall forecast results of APSS
3.3 与传统数据挖掘技术预测结果的对比
为了验证本文提出的改进方法是否比传统方法更为有效,本文同时也采用传统模式序列相似性搜索方法(pattern sequence similarity search,PSS)对天然气价格进行了预测。其预测结果与改进后的预测结果的对比见表1和图3。
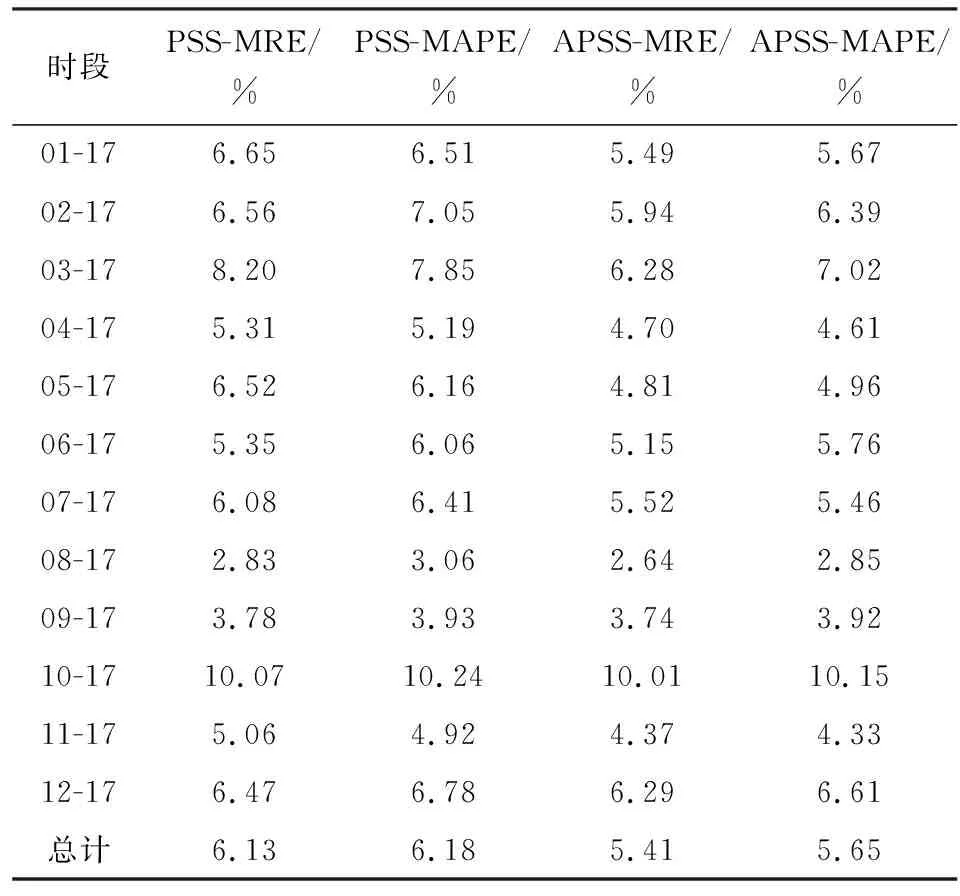
表1 采用传统PSS和改进的APSS方法下预测结果的MRE和MAPETable 1 Comparison of MRE and MAPE of forecast results from traditional PSS and modified APSS

图3 APSS和PSS预测结果对比Fig.3 Comparison of forecast results from APSS and PSS
由表1可知,APSS方法下的MRE和MAPE无论是每一个时段的表现,还是整体的表现,都比PSS方法下的低。以整体表现为例,APSS方法的MRE和MAPE分别为5.41%和5.65%,而PSS方法为6.13%和6.18%。这表明,APSS相对于PSS预测效果更好。由图3可知,APSS的预测结果与真实值之间无论在趋势上还是数值上都比PSS方法更为匹配。综上,本文提出的改进的数据挖掘方法能够实现对天然气价格的有效预测,且与传统方法相比,具有更高的预测效果。
4 结 语
作为影响天然气产业发展的重要因素,对天然气价格的预测具有重要意义。本文在分析现有文献有关天然气价格预测的基础上,提出了一种基于改进的数据挖掘技术的天然气价格预测方法,该方法的核心是序列相似性搜索技术。在方法提出之后,利用美国天然气日度现货价格进行了实验验证和对比分析。结果表明,数据挖掘技术可以运用在天然气价格预测中,而本文所提出的改进方法的预测效果相较于传统方法更优。
需要注意的是,本文提出的基于数据挖掘的价格预测方法需要以大量的历史数据输入为前提,且数据本身是受多种因素影响呈现较强波动性的(事实上,正是由于这种波动性的存在,才使得预测变得有价值)。而目前国内自产天然气价格仍然受政府指导价影响,价格波动性小且可预期性强;中国进口LNG和管道气价格虽然实现了与其他价格的联动波动,波动性较强,但是历史数据非常有限。基于此,本文提出的方法目前还无法直接在中国应用,但是该方法能够很好地对美国的Henry Hub、英国的NBP和日本的LNG等价格进行预测,而这三大中心的天然气价格是国际天然气价格水平的重要标尺和价格涨跌的风向标[2]。因此,这些地区的天然气价格预测结果对于了解中国进口天然气价格的变化趋势具有重要的意义。随着国产天然气价格市场化的逐步推进、进口天然气价格数据的不断积累,可以预期该方法也将在未来直接应用于中国的天然气价格预测当中。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
小学科学(学生版)(2020年5期)2020-05-25
小学科学(学生版)(2019年11期)2019-12-09
能源(2018年10期)2018-12-08
能源(2018年8期)2018-01-15
电子技术与软件工程(2016年24期)2017-02-23
汽车之友(2016年18期)2016-09-20
汽车之友(2016年10期)2016-05-16
