
基于pandas实现烟草物流中心数据处理
2020-03-10 08:05
物流技术与应用 2020年12期
一、引言
目前在烟草物流中心的项目规划及设计中广泛应用的数据分析工具主要有Excel、R、SQL Server等。其中,Excel对可处理的数据行、列数都有明显限制。以Excel 2016版为例,最多可处理1048576行、16384列的数据,更适用于小型数据的简单分析;而商业软件SQL Server的可伸缩性有限,当多用户连接时性能会变差,更适用于数据类型相对规整的中小型数据;R在统计方面表现突出,但处理上GB数据时的运行速度较为缓慢,对于数据类型复杂的大型数据来说,其内含包如data.table、smartdata、cleanerR等也不如Python的工具集使用灵活。
Python作为一款免费的开源软件,在Windows、MacOS、Linux等操作系统中都有其对应的版本,具有代码简洁、可读性高等优势,其中的pandas工具集提供了大量处理数据的函数和方法,用于数据挖掘和数据分析,同时也提供数据清洗功能。pandas拥有更高的数据交换性,对xlsx、csv、mdf、txt、html等格式数据提供统一的导入模块,并转换为DataFrame格式数据;通过参数设置既能导入少量的数据进行预览,又能只导入需求的列进行分析;具有良好的交互模式,可以一个命令即时返回一个结果,也可以一次性运行所有命令得到最终结果;此外,烟草物流中心的订单分批现象给处理日期数据增加了难度,pandas则可以自动解析目标列中类似日期格式的数据,为以日期为分组依据的数据聚合运算提供便利。
二、处理目的
数据处理为数据分析及方案规划打下基础,原始数据中一般会含有大量冗余数据,比如同时存在条烟编号列和条烟名称列,且为一一对应关系,在导入数据时,只需保留数值型的条烟编号列以减少内存占用;再比如数据中含有多列关于客户信息的数据、且每一列都无法作为客户信息识别的唯一标识时,在保证其对应关系的前提下将几列或所有关于客户信息的数据列合并成为新的一列,并指定为“客户编号”,用作唯一标识客户信息的数据列。因此在数据分析前,一般会先根据需求设定目标列,然后导入对应的原始数据,最后对数据进行清洗和整理。
对烟草物流中心的销售数据进行处理时,通常把目标列设为:订单日期、订单编号、客户编号、品规及销售数量等,如果需要区分异型烟,可再多增加一列异型烟标记列。
三、处理工具
本文以某烟草物流中心一年的实际销售数据data2020.csv为例,详细说明如何使用pandas 0.24.2版来实现数据的导入、基本清洗及整理。
由于pandas是Python的工具集之一,正常情况下,在使用前都需要安装大量的工具包,安装步骤也非常复杂,而使用基于Python的Anaconda Navigator软件作为数据处理工具可以避免上述问题。Anaconda Navigator是一个开源的集成了大量工具包的工具合集,可以一次性安装所有运行Python时需要的各种工具包,降低了安装难度。
打开Anaconda Navigator中的Jupyter Notebook,在原始数据data2020.csv所在文件夹中新建一个Jupyter Notebook工程文件,利用import pandas as pd命令导入所需的pandas工具集。
四、数据预览
数据预览是在正式导入数据前,对数据进行的简单查看,其主要有两个目的:一是确认数据是否可以使用pandas进行导入;二是查看是否含有不需要导入的冗余数据列,以及是否有需要进行合并等二次处理的数据列。
大部分数据分析软件不具备数据预览的功能,只能一次性导入所有数据,一旦报错就会被迫终止导入。而pandas工具集在这一方面存在天然的优势,可通过参数设置导入指定行数据来对原始数据进行实验性导入,帮助我们对数据建立基本认识。
pandas中提供了多种导入数据的函数,并且都可以实现预览目的,可根据不同数据格式选择对应的导入函数。本文使用pd.read_csv()函数及其提供的部分参数实现对数据的预导入,参数如下:
nrows:设置导入行数,例如nrows=5,通过查看前五行数据,快速判断数据是否存在编码、格式等问题,以及是否需要导入所有列;
skiprows:设置需要忽略的行数或要跳过的行号列表,当样本数量很大时,可结合函数进行随机抽取,比如随机抽取1%的行数。

图1 编码格式报错

图2 数据预览

图3 数据导入结果
在上文新建的Jupyter Notebook文件中,导入data2020.csv的前五行数据预览并将其命名为“df”,代码如下:

返回结果,如图1。
由图1可知,因为文件自身的编码与pandas默认采用的“utf-8”解码方式不相符,从而使“utf-8”编码解码器无法解码该数据,所以返回报错提示,可通过添加参数encoding来解决。在含有中文编码的情况下,除常用的“gbk”编解码器外,还有“gb18030”、“hz”、“big5”等。
修改代码如下:

运行后,系统不再报错,使用df.head()函数查看成功导入的前五行数据,返回结果如图2。
因此,在正式导入数据前,利用参数nrows或skiprows进行数据预导入,可避免因编解码器错误、数据类型复杂等问题带来的重复操作,以提高数据导入效率。
通过简单预览,我们可得出:
(1)该数据没有列名;
(2)第七列产品名称列与第六列产品编号列含义相同,因此第七列可当做冗余数据,无需导入,以加快速度、节省内存占用;
(3)前三列分别代表年、月、日,可合并为新的一列并转换为日期格式。
但完整数据中可能还会存在预览中无法看出的问题,比如是否存在缺失值、异常值等问题,需要在导入所有行数据后再进行判断。
五、数据导入
以上主要介绍了pd.read_csv()函数中常用于数据预览的两个参数,本章中继续使用此函数中的以下参数对数据进行正式导入,并解决列名及冗余数据问题,减少导入的数据量,加快数据处理速度:
usecols:设置导入指定列,可以是列名或对应的索引值。在此数据中,以目标列为基础导入,需要导入的列索引值为:usecols=[0,1,2,3,4,5,7,8];
header:指定第几行作为列名称,默认为0,若如本文中数据需要另外指定列名,此参数设置为None;
names:指定列名,当header=None时,添加此参数设置列名。
综上,数据导入代码如下:

查看返回结果,如图3。
由图3结果可知,目标列数据已导入且命名成功,数据预览中的问题也得到解决。但返回一个第0列及第5列为混合类型的警示:因为在pandas内部以块的形式处理文件,会降低解析时的内存使用量,但如果在一列中有不止一个数据类型存在时,将被系统判断为混合类型并返回此警示,可以设置“low_memory=False”,或利用dtype参数指定每列的数据类型,但会占用大量内存和时间,可以等数据全部导入后再进行列数据类型的指定。
通过df.head()函数查看数据前五行发现:数据中的“month”、“day”、“qty”及“customer_code”等四列均被转换为浮点类型,由于pandas不支持存储含有缺失值的整型及布尔型数组,当引入含有缺失值的整型数组时,根据pandas对数据的处理规则,该列数据将被转换为浮点型,因此可以推断出这四列数据中可能含有缺失值,需要进行单独验证。
至此数据导入工作已经完成,除导入本文数据需要的参数外,pd.read_csv()函数中还有许多其他常用参数可以在导入数据时快速设置:
sep:指定分隔符,若其他非逗号分隔符的文件,也可以通过修改该参数导入;
index_col:指定列数据作为行索引,默认值为None;
na_filter:默认为True,是否检查丢失值(空字符串或空值),在没有任何缺失值的数据中,传递参数na_filter=False可提高读取大文件的速度;
skip_blank_lines:默认为True,忽略空白行而不是解析为NaN;
error_bad_lines:默认为True,若有含大量字段的行(例如大量逗号)在默认情况下会引发异常,并且不会返回任何DataFrame,若error_bad_lines=False,这些“异常行”将不被导入;
warn_bad_lines:默认为True,如果上一个参数设为False,而warn_bad_lines=True,则将为每个“异常行”输出警告;

图4 info()函数返回值

图5 提取缺失值

图6 删除缺失值
parse_dates:指定一列或多列字符串合并解析为日期格式。
六、数据处理
数据处理是在数据成功导入后,对数据进行的缺失值及无效值清洗、数据类型转换、日期格式处理等一系列操作,以达到规整数据的目的,为接下来的数据分析做准备。
利用pandas对数据处理之前,可以先通过info()函数查看数据的详细信息,例如数据类型、空值及内存占用情况等,info()函数中的常用参数有以下几个:
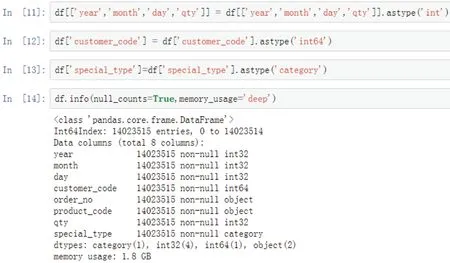
图7 转换类型及结果查询
(1)本数据共14023517行,除“year”列以外的其他列都只含有14023515个非空值行,说明除“year”列以外的其他列中都含有2个空值;

图8 数据描述结果

图9 提取负值

图10 数据保存图
(2)数据类型存在问题,例如“year”、“month”、“day”和“qty”列应转换为int整型,“customer_code”列在预览导入中可见共12位整数,应转换为int64整型;
(3)内存占用为3.4GB,其中,最后一列数据为异型烟标识列,代表是否为异型烟,存在大量重复字段且唯一值少,可目录化为category类型,不但可以继续显示原内容为阅读提供方便,而且可以在占用更少内存的同时兼顾运行速度。
1.缺失值的处理
在已经导入的原始数据中可能会存在少量缺失值,这会使某些函数及代码无法运行或增加其运行时长,例如使用to_datetime()函数将某列或某几列转换为日期格式时,当数据中存在缺失值时就会报错。因此,为使数据分析结果的准确性更高,需要对这些可能存在的缺失值进行优先处理。
首先利用isnull()函数和any()函数提取数据中的缺失值,设置any()函数中的参数axis=1选取含有缺失值的行,观察其分布情况,判断缺失值是否对数据分析结果有影响,使用代码如下:
df[df.isnull().any(axis=1)]
查看返回结果,如图5。
由图5可知,除“year”列以外的其他列中的缺失值均位于14023515和14023516两行,在判定不影响整体分析结果的情况下,将此两行数据删除;若缺失值较多或对数据分析结果有影响,则需根据实际情况对缺失值进行填充。
接下来再利用dropna()函数删除缺失值,相关参数如下:
how:当整行或整列中有至少一个缺失值或全为缺失值时,通过此设置确定删除方法,默认“any”,删除存在缺失值的行或列;“all”,删除全为缺失值的行或列;
axis:确定按行向下判断还是按列向右判断,默认axis=0,按行向下判断;
inplace:默认False,若inplace=True,直接在原始数据上进行;
subset:删除指定列中含有缺失值的行或指定行中含有缺失值的列。
删除缺失值并查看结果,代码如下:

memory_usage:是否显示DataFrame中所有元素(包括索引)的总内存使用情况,“True”,始终显示内存情况,“False”不显示内存情况,“deep”,精确计算内存使用情况;
null_counts:是否显示非空计数,“True”,始终显示非空数量,“False”,不显示非空数量。
使用代码如下:

查看返回结果,如图4。
由图4可知:

返回结果,如图6。
由图6可知,再次运行df.info()函数后所有列的行数相同,说明数据中已无缺失值。
2.数据类型的转换
在pandas中通常利用astype()函数实现对数据类型的转换,先返回一个结果作为预览,并不会改变原始数据,因此在转换时可先运行代码查看转换结果,确认无误后再通过赋值的方法对原始数据进行更改。
按照上文中提到的分别将“year”、“month”、“day”和“qty”列转换为int整型,“customer_code”列转换为int64整型,“special_type”列转换为category类型,代码如下:

全部数据列类型转换成功后,继续运行代码df.info()函数查看内存占用情况,返回结果如图7。
由图7可知,转换后的内存占用为1.8GB,比转换前减少了47%,因此在分析大型数据前尽量把中文字符处理成占用字节更少的数据类型,可有效减小内存占用,提升运行速度。
3.异常值处理
除上述操作以外,数据中可能还存在异常值,比如本文数据中的“month”列中是否有大于12的数值,比如“day”列是否有大于31的数值,再比如“qty”列中是否有零或负值等,可以使用df.select_dtypes()函数来提取上述可能含有异常值的整形列并判断其最值情况,代码如下:

图11 日期设为索引

图12 方式一运行

图13 方式二运行

图14 数据保存图

返回结果如图8。
由图8可知,只有“qty”列的最小值为-50,不符合实际情况,利用代码“df[df['qty']<=0]”将“qty”列中所有小于或等于零的数据全部提取出来,返回结果如图9。
由图9可知,“qty”列中只存在一个负值,由于负值的数量很少,可直接作为异常值进行删除,或根据实际分析需求进行处理。
4.日期格式处理
在分析基于时间序列的数据时,经常会碰到日期格式处理和转换问题,而pandas有着强大的日期数据处理功能,将其设置为整个数据的索引,更方便于利用resample()函数对数据进行频率转换和时间序列重采样等操作。下文将介绍两种情况下将数据转换为日期格式的方法:
(1)中小型数据集
运用read_csv()函数中参数parse_dates,在导入数据时直接将一列(如20181018、2018-10-18、2018/10/18等)或多列数据合并解析(以本文数据为例parse_dates={'date':['year','month','day']}),可快速将数据转换为日期格式。但该方法在解析时间格式时对内存占用较大,数据导入时间较长,且如果待解析列格式不统一或存在空值、异常值时,将不会转换为日期格式,只能作为普通数值类型返回,因此这个方法常适用于数据量较小的情况。
(2)大型数据集
当数据量很大且日期格式不标准时,可以在导入目标数据后,使用to_datetime()函数将DataFrame中指定的一列或几列合并后转换为datetime日期格式,且to_datetime可以解析多种不同的日期表示形式,常用参数如下:
errors:对错误的处理方式,默认为“raise”,无效解析将返回异常;“coerce”,无效解析设置为NaT;“ignore”,忽略无效解析返回输入值;
dayfirst:当待解析的对象为字符串或列表时,指定日期解析顺序,默认为False,若为True,优先解析day,例如10/11/12将被解析为2012-11-10;
yearfirst:与dayfirst同理,若为True,优先解析year,例如10/11/12将被解析为2010-11-12;
format:指定日期格式。
在本文数据中处理日期格式数据过程代码如下:


返回结果,如图10和图11。
为更直观的感受上述两种方式在运行速度上的差别,新建一个Jupyter Notebook文件并导入pandas,借助%time函数来分别计算两种方式的代码运行时间。本文用于实现的电脑基本配置为:Windows 7 64位操作系统、Intel Xeon CPU E5-1650 V3处理器、16G内存、128G固态硬盘。
第一种方式的代码如下:

运行结果,如图12。
第二种方式的代码如下:

运行结果,如图13。
由图12可知,第一种方式先用上文中提到的parse_dates参数合并日期列,再导入完整数据的所用时长为27分15秒;由图13可知,第二种方式先直接导入数据,然后再分步处理日期得到与第一种方式的相同结果,需要注意的是在上文中已知数据存在空值行,为避免to_datetime()函数报错,在合并日期数据前,先对空值行进行删除,所有代码的运行时间加和约为45秒。综上所述,对于含有需要合并的日期列且数据量大的数据来说,采用第一种方式虽然可以一次性解决日期数据问题,但逻辑不如第二种清晰,且读取csv文件的时间成倍增加,大约是第二种方式的36倍,此时优先选择第二种方式更能节省整体的处理时间。
七、数据保存
pandas工具集不但可以导入多种格式的数据,而且能根据数据处理情况将数据保存成多种格式。
若数据未处理完,可保存为hdf格式来快速暂存数据处理的中间结果。在将hdf格式数据保存到硬盘的过程中,会保留数据在内存中的排列顺序,以及列数据的格式类型,数据的保存和读取速度都十分迅速。
若数据已经完成处理,可保存为txt、hdf、csv等格式,其中csv格式数据可以被大多数电子表格和数据库系统支持,具有较高的通用性,因此将本文中处理好的数据也保存为csv格式数据。
pandas中一般使用df.to_csv()函数将已处理好的数据保存成csv格式,常用参数如下:
sep:指定分隔符,csv文件默认为逗号,若其他非逗号分隔符的文件,也可以通过修改该参数保存;
header:是否保存列名,默认为True,当值设为零时,不保存列名;
index:是否保存索引,默认为True,当值设为False时,不保存索引;
index_label:设置索引对应的列名,默认为None;
encoding:设置编码方式,默认编码方式为utf-8。
保存本文整理好的df数据,并将其命名为“data2020-1”,代码如下:
df.to_csv('data2020-1.csv')
数据保存结果,如图14。
由图14可知,处理后的数据不但文件大小得到改善,而且具有更高的交换性及准确性,可以直接用其他数据分析软件或仿真软件进行数据分析,也可以继续用pandas分析,节省导入时间的同时提高效率。
八、结论
本文通过使用pandas对烟草物流中心的实际销售数据进行导入、清洗、整理工作,将类型不规则、存在缺失值的数据规整为数据类型固定且只含有目标列的数据,为数据分析、挖掘及可视化奠定基础。从导入和处理过程中可以看出,基于Python编程语言的pandas工具集的代码可读性更高,可以快速简便地实现少量行数据或需求列数据的导入,导入速度也优于其他数据分析工具,其中内置的函数和方法可以更加高效的对大型数据集进行处理。但由于pandas处理数据时是把数据存储于计算机的内存中,如果数据量太大,比如数据量高达几百GB时,考虑内存限制也不适合用pandas工具集进行导入。烟草物流中心规划项目的特殊性使不同项目的原始数据间存在一定的相似性,因此引用的函数和方法可以对不同项目的原始数据进行重复使用,也可以利用其编程语言的灵活性,针对特殊问题编写个性化的函数使用,提高工作效率,具有良好的通用性和实用性。
猜你喜欢
家庭影院技术(2021年1期)2021-03-19
数码世界(2020年5期)2020-06-23
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
计算机时代(2017年2期)2017-03-06
电视指南(2016年11期)2016-12-20
时代金融(2016年27期)2016-11-25
电脑知识与技术(2016年13期)2016-06-29
