
用于肺炎图像分类的优化卷积神经网络方法
2020-03-06 13:23:58雷印杰
计算机应用 2020年1期
邓 棋,雷印杰,田 锋
(四川大学 电子信息学院,成都 610065)
0 引言
肺炎(Pneumonia)[1]作为一种危害人类健康的常见疾病,在0~5岁婴幼儿以及65岁以上老年人的呼吸道疾病中尤为常见,且致死率逐年升高。根据世界卫生组织(World Health Organization,WHO)的统计,仅在2015年,因肺炎导致的儿童死亡人数就达到了92万人,占全世界五岁以下儿童死亡人数的16%[2]。在中国2000—2010年5岁以下儿童死亡原因中,肺炎排在第2位[3]。我国每年约有250万例肺炎发生,12万5千人因肺炎死亡,在各种致死病因中占第5位[4],而由于老人年身体素质和免疫系统能力下降,在我国患有肺炎的人群中,老年人所占的比例就达到了70%[5]。
在传统肺炎诊断过程中,肺炎影像的判断主要依靠有经验的医生,但由于人工经验的差别准确率得不到保证[6]。随着计算机与数字图像处理技术的发展,计算机辅助诊断系统(Computer-Aided Diagnosis, CAD)[7]逐渐被引入临床,并为放射科医生判断CT图像提供参考意见。针对肺炎影像的自动识别问题,中外学者们提出了许多不同的方法。岳路等[8]利用决策树算法对200例小儿肺炎进行分类,取得了准确率80%的成绩。决策树(Decision Tree)[9]是一种经典的机器学习分类方法,通过树形结构完成类型划分。决策树算法的优点是算法简单易于理解,可处理多种不同类型的分类问题,但是当数据量过大,容易产生过拟合问题,同时,在面对复杂数据时分类效果不是太好。Jun等[10]利用支持向量机(Support Vector Machine, SVM)算法[11]对间质性肺炎与非特异性肺炎进行分类,与放射科医生分类结果进行比较,准确率相差在5%~6%。邵欣蔚[12]也利用SVM算法对儿童社区获得性肺炎(Community Acquired Pneumonia, CAP)进行分类,在早期诊断问题上取得了准确率90%的良好效果。SVM算法作为一种优秀的机器学习方法,利用高维映射解决了许多线性不可分问题,在图像、文本信息分类等方面取得了十分良好的效果,但当数据量过大时常常导致模型计算量过大、效率降低,鲁棒性与准确率得不到保证。近年来,随着人工智能和大数据应用的发展,计算机辅助诊断技术越来越多地被应用到临床。随着深度学习(Deep Learning)[13]这一概念的兴起,一大批以卷积神经网络(Convolutional Neural Network, CNN)[14]为代表的深度学习方法开始出现。刘长征等[15]利用一个7层的卷积神经网络对400例肺炎患者的CT影像进行分类,识别准确率比SVM算法提高了5.7%。由于卷积神经网络“自主”学习的特性,避免了机器学习中人工提取图像特征的局限性,大幅度提高了识别准确率。为进一步提高卷积神经网络的识别准确率,通常的做法是增大数据集、增加神经网络层数。Rajpurkar等[16]提出一种121层的卷积神经网络,在总量为112 120张带标记的肺部X光图像数据集ChestX-ray14上进行训练,在检测14种不同肺部疾病过程中,有11种取得了与放射科医生相似或更优的表现。
虽然通过增加网络层数获得了更加优异的分类效果,但是相应网络参数数量比浅层网络增加了几十甚至几百倍,内存占用也由几十兆提升至几百甚至上千兆,对系统资源的占用比浅层网络提高了很多。深度神经网络对系统性能较高的要求,给客户端部署造成了很大的阻碍,而采用浅层网络的训练结果往往不能够达到实际应用的要求。
针对以上的问题,本文提出一种基于知识蒸馏(Knowledge Distillation)方法[17]优化的卷积神经网络,在减少系统资源占用的同时提高网络对于肺炎识别的能力。根据肺部CT图像特点,选择AlexNet与InceptionV3模型。AlexNet模型在ILSVRC2012竞赛中获得冠军,在Top- 5错误率上取得了15.3%的成绩;InceptionV3模型则在ILSVRC2014将Top- 5错误率降到了4.2%。两者相比,前者网络深度为8层,而后者为159层。在训练时采用迁移学习(Transfer Learning)方法避免因训练集过小引起的过拟合问题,将InceptionV3预训练模型作为Teacher Module,AlexNet模型作为Student Module,将前者的输出作为后者训练的监督信息,使训练完成后的AlexNet模型具有与InceptionV3模型相近的识别能力,同时减少对图像处理器(Graphics Processing Unit, GPU)的占用。
1 肺炎识别与网络压缩方法
1.1 深度学习与卷积神经网络
深度学习相比传统的简单学习,其区别就在于前者可以通过一种多层的非线性结构“自主”学习,来表征数据的特征,而后者大多数需要人工提取特征信息,且因人工提取的特征往往不能很好地表征事物的本质,故学习效果难以提高。相比于简单学习常用的决策树、SVM等方法,深度学习通过多层网络结构分层学习数据的特征,再单独对每一层的分类信息进行微调,可以以简单结构完成对复杂样本的描述。卷积神经网络是深度学习在图像处理领域的成功应用,作为一种具有深度结构的前馈型神经网络,一般由卷积层、池化层、全连接层与输出层组成。相比于传统的人工神经网络,两者主要的区别就在于前者通过卷积核以及权值共享大幅度降低了参数数量与训练难度。再结合大量数据的训练,使卷积神经网络突破了传统网络的限制,在图像处理领域取得了很大的进展。
1.2 肺炎分类网络结构设计
针对任务特点,本文首先比较了几种目前较为流行的深度学习网络架构,如AlexNet[18]、VGG16[19]、ResNet18[20]、ResNet34[20]、InceptionV3[21]。它们在错误率、参数数量、网络深度等性能指标的比较如表1所示。
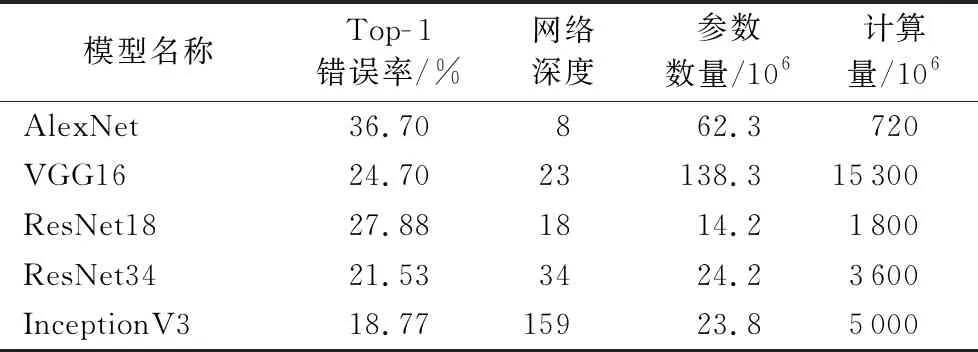
表1 各模型性能对比 Tab. 1 Performance comparison of different models
可以看出,在评价识别准确率指标的参数Top- 1错误率上,InceptionV3模型比其他模型具有较大的优势。其错误率比AlexNet模型减小了近1/2,比其他模型也有不同程度的下降。作为Google在2014年开发的GoogLeNet[22]模型基础上改进的版本,InceptionV3由5个卷积层、3个池化层、1个全连接层以及11个Inception模块组成。由表1可以看出,虽然InceptionV3模型的网络深度约为AlexNet模型的20倍,但得益于其Factorization操作,其参数数量比后者少了3 850万。在教师模型的选择上,主要考虑的参数为模型的识别准确率,因此本文选择InceptionV3模型作为教师模型。
在学生模型的选择上,主要考虑模型的参数数量与计算量,参数数量对于内存要求影响较大,计算量则对GPU运算能力要求有较大影响。AlexNet作为上表中层数最浅的网络,是由加拿大多伦多大学教授Hinton等[18]在2012年提出的深度神经网络模型,通过5层卷积层与3层全连接层构成。在计算量方面,AlexNet仅有InceptionV3模型的1/7,VGG16模型的1/21。虽然参数数量指标上没有特别的优势,考虑到实际应用场景中用户端GPU运算能力普遍较弱的情况,本文选用AlexNet模型作为学生模型。
1.3 网络模型压缩
在医学影像分类领域,随着深度学习的崛起,许多层数更深、结构更加复杂的卷积神经网络开始在这一领域得到应用。如Rajpurkar等[16]提出的121层神经网络,Kermany等[23]提出的159层神经网络。一般来说,层数越多结构越复杂的神经网络,往往需要消耗更多的系统资源。知识蒸馏是由多伦多大学教授Hinton等[17]在2015年提出的一种知识迁移的技术,常用于网络模型压缩。本文考虑实际应用中用户端计算机性能的限制,将知识蒸馏方法引入到医学影像分类领域,在压缩模型的同时提高模型的分类性能。
本文选用两个大小不同的模型,将结构复杂、层数更深的InceptionV3模型作为教师模型(Teacher Module),结构简单、层数更浅的AlexNet模型作为学生模型(Student Module),两种模型的网络结构参数如表2、表3所示。表2中编号为8~18层网络结构为InceptionV3模型特有的Inception模块,每一个模块由多个层数不同的卷积层构成,所以有多个尺寸不同的卷积核存在。在表2、表3中的“—”符号表示该网络层中没有此参数。首先,单独训练教师模型,取得较为理想的结果后固化其训练参数;其次,训练学生模型,在训练过程中将教师模型的输出除以参数T,再经过softmax变换后作为参数,传递给学生模型,起到提高后者的泛化与识别能力的作用。
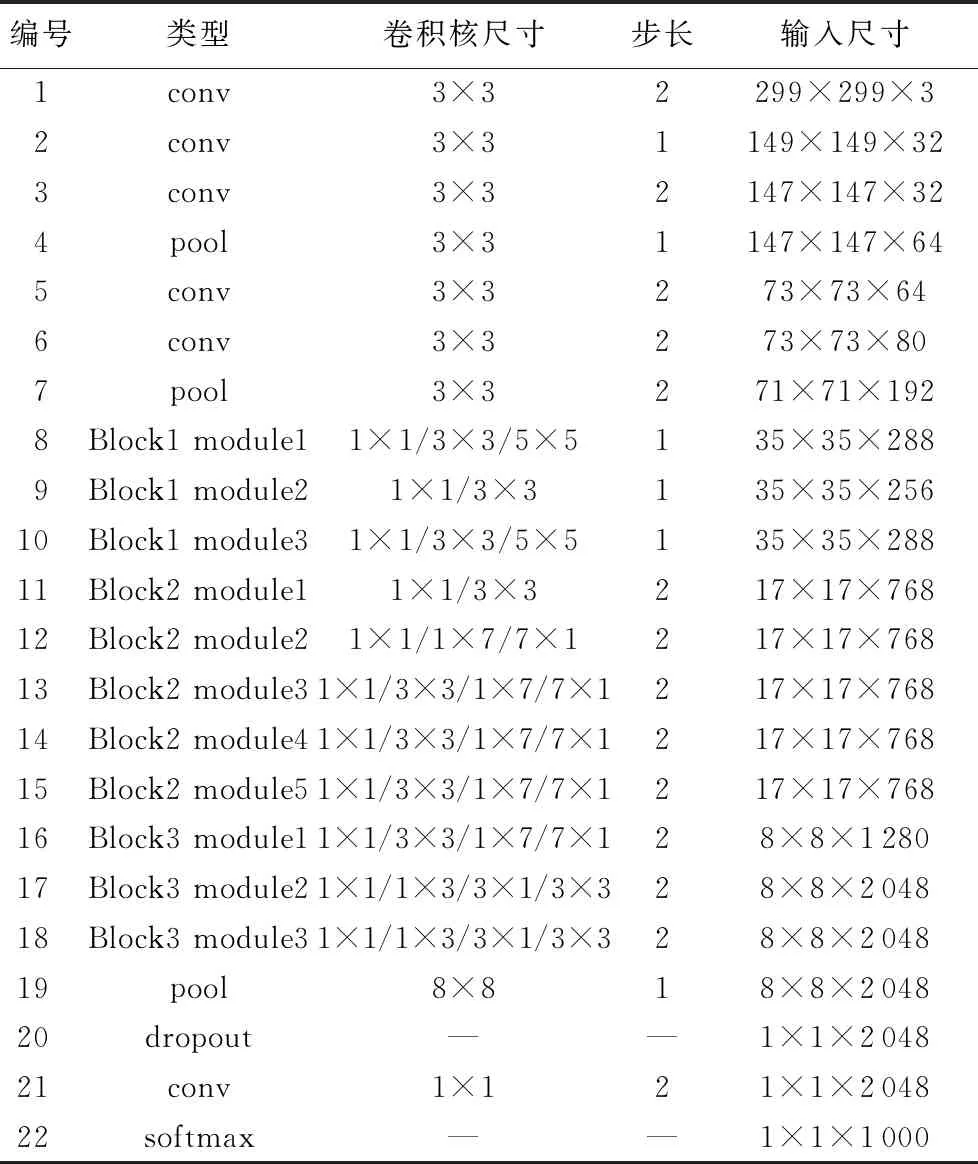
表2 教师模型网络参数 Tab. 2 Network parameters of teacher module

表3 学生模型网络参数 Tab. 3 Network parameters of student module
如图1所示,先将教师模型InceptionV3的训练结果用温度参数T“软化”,再经过softmax变换得到软化后的概率分布—软目标(soft target),计算公式如下:
(1)
其中:qi为教师模型给出的每一类的可能性;zi为教师模型最后一层的神经元;T为调节参数;在软目标中包含了许多未标记但对于分类十分有用的信息,因此通过提取教师模型中的软目标可以大幅度提高学生网络的识别能力。

图1 知识蒸馏网络结构Fig. 1 Network structure of knowledge distillation
训练过程中,调节参数T的大小对训练结果有较大的影响,一般设置为大于0的整数。此处选择1、10、20、30、40、50作为实验参数,比较Student Module在参数T不同大小下的训练结果,如表4。可以看出,参数设为1时,实验取得的准确率、特异性以及灵敏度等性能指标均优于其他选项,故之后的训练过程中,设置调节参数T的大小为1。

表4 不同参数T的实验结果 Tab. 4 Experimental results with different parameter T
在训练学生模型AlexNet时除了正常训练结果——硬目标(hard target)外,同样地采用上面的方法得到一个soft target。在计算损失函数时将两者结合,计算公式如下:
L=Lsoft
(2)
其中:L为训练学生模型最终使用的loss,Lsoft是使用温度参数T软化后的loss。在实验中,采用Lsoft作为最终训练学生模型的loss。
1.4 分类过程
训练卷积神经网络分类肺炎图像时常常会有过拟合问题,本文中为提高训练效果,降低过拟合现象发生的几率,决定采用迁移学习[24]的方法,让卷积模型由ImageNet数据集训练过后,保留训练参数并删除原来的全连接层,在新建的全连接层上随机初始化参数并训练。实验结果表明,采用迁移学习方法能够有效地防止过拟合问题。
本文采用教师模型“教”学生模型的方法,让学生模型学习教师模型的训练参数,让小网络有了大网络的识别能力,起到了模型压缩的作用,训练整体流程如下。
输入:实验所用的数据集D。
输出:教师模型与学生模型的预测结果。
1)将实验所用的数据集D中所有图片合并,按一定的比例随机分为训练集DTR、测试集DTE与验证集DVE。
2)将训练集DTR、测试集DTE与验证集DVE中的图片采用拉伸缩放的形式,缩放至适应教师模型InceptionV3与学生模型AlexNet的大小。
3)使用训练集DTR训练教师模型InceptionV3,使用验证集DVE与测试集DTE实时测量InceptionV3的分类性能并更新其参数。
4)将训练好的教师模型参数固化,获得其输出Z。
5)使用训练集DTR训练学生模型,在训练过程中将Z作为监督信息用于loss计算,使用验证集DVE实时测量AlexNet的分类性能并更新其参数。
6)将训练好的AlexNet模型参数固化,利用测试集DTE获得相应的预测结果。
2 实验设计
2.1 实验平台
实验在一台桌面级高性能GPU工作站上进行,运行系统为Linux,操作平台为ubuntu 16.04。工作站配备一颗Intel Xeon E5- 1650 v4六核心处理器,主频为3.6 GHz,内存32 GB,GPU为Nvidia Geforce GTX 1080Ti,显存11 GB。实验使用的深度学习框架为PyTorch,运行平台为JetBrains公司提供的Python语言开发工具Pycharm。PyTorch是由Facebook公司的研发团队开发的一款针对深度学习与深度神经网络编程的工具包,使用PyTorch构建神经网络,用户可以方便地调用相关的函数工具包,而不需要自己编写所有的实现算法,从而节省了大量时间,提高了学习效率。
2.2 数据集及预处理
实验采用的数据来自广州市妇女儿童医学中心,由医学中心患者常规临床检测时拍摄的医学影像组成,并由美国加州大学圣地亚哥分校研究员Daniel Kermany等在2018年发布于开源数据库Mendeley。该数据集中包含了总量为5 856张的人体胸部X光照片,图像格式为JPEG,数据分布情况如表5所示。
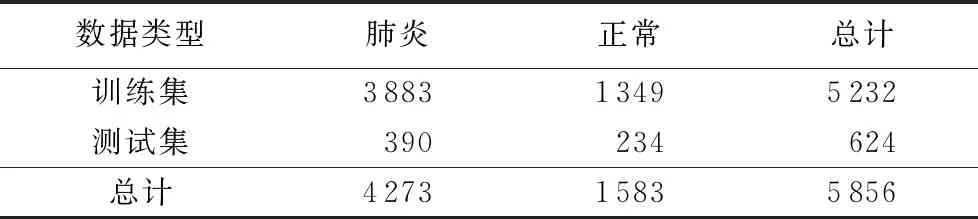
表5 数据集成分分布 Tab. 5 Component distribution of datasets
胸部X光照片作为肺炎诊断的重要依据,照片的质量对于诊断结果的影响很大,因此,数据集中的照片首先由有经验的医生初步筛选,得到质量较为稳定的图像后,再由相关专家进行人工标记。数据集中的X光照片分为训练集与测试集,训练集的人工标记由两位肺部疾病专家完成。为避免因人工标记造成的误差,保证检测效果,测试集的标记由另一位专家完成。测试集与训练集X光照片的数量比例为约为1∶10,同时为满足InceptionV3与AlexNet模型的输入要求,采用拉伸缩放的方式,将X光照片的大小分别调整为299×299和224×224像素尺寸,如图2所示。

图2 胸部X光图像示例Fig. 2 Examples of chest X-ray images
2.3 参数设置
在实验过程中,训练InceptionV3模型采用迁移学习的方式,将全连接层的参数随机初始化后开始训练。将学习率设置为5×10-3,并设置衰减率为0.9,每隔7个epoch衰减一次。分类函数使用softmax函数,损失函数则使用交叉熵函数(Cross Entropy Loss),优化方法采用随机梯度下降(Stochastic Gradient Descent,SGD)算法。虽然常用的优化方法为Adam,但它也有收敛过快难以达到最优解的问题。在本实验中经过比较发现,采用SGD能够取得更优的结果。在AlexNet模型训练过程中,将学习率设置为2×10-4,衰减率设为0.9,采用与InceptionV3模型相同的迁移学习方法。损失函数使用交叉熵函数,分类函数使用softmax,优化方法同样采用随机梯度下降算法。
2.4 评价标准
对于医学影像分类,评价其性能的指标一般有三个,分别为准确率(Accuracy,Acc)、特异性(Specificity)与灵敏度(Sensitivity)。准确率即预测患者是否患有肺炎与实际结果之比,体现模型的预测能力;特异性又被称为正阳率(True Positive Rate,TPR),即将正常患者预测为正常的概率,正阳率越高则误诊的概率越低;灵敏度又被称为正阴率(True Negative Rate,TNR),即将肺炎患者预测为患有肺炎的概率,正阴率越高则漏诊的概率越低。
计算准确率(Acc)、特异性(TPR)与灵敏度(TNR)的公式如下:
Acc=(TP+TN)/(TP+TN+FN+TN)
(3)
TPR=TP/(TP+FN)
(4)
TNR=TN/(FP+TN)
(5)
其中:TP、TN、FP、FN分别代表正阳性、正阴性、假阳性与假阴性。同时,为了全面衡量优化前后的AlexNet以及InceptionV3模型的性能,采用的指标还有显存占用量、GPU使用率及训练时间。
3 实验结果与分析
3.1 实验过程及结果
针对分类任务特点,实验首先比较了几种较为流行的深度学习模型对本文所用数据集的识别准确率及损失。其中,损失为交叉熵函数的输出,主要体现预测值与真实值的概率分布情况。在训练过程中损失常常作为训练结果的参考,通常在0.02及以下时说明分类器已经取得了较好的训练效果。选取的模型有AlexNet、VGG16[19]、ResNet18[20]、ResNet34[20]、InceptionV3,在同一训练集与测试集下,它们的分类性能如表6所示。

表6 各模型识别准确率 Tab. 6 Recognition accuracy of each model
经过比较后发现,具有inception结构的InceptionV3模型在肺炎CT图像分类上表现更加优异。故本文选取了InceptionV3模型作为优化方法中的Teacher Module,同时选取网络结构更加简单的AlexNet作为Student Module。在训练过程中,比较两者对于系统资源的占用情况,如表7所示。可以看出,与前者相比,AlexNet模型无论在显存占用、GPU使用率还是训练时间上都更加具有优势。

表7 AlexNet与InceptionV3模型系统资源占用情况 Tab. 7 Occupation of system resources of AlexNet and Inception V3 models
训练结束后,比较由本文方法优化后的AlexNet(以下称AlexNet_S)与优化前的AlexNet模型对肺炎CT图像分类性能的差异,同时使用InceptionV3模型(表8中称为Teacher Module)作为参考标准。可以看出,优化后的模型对肺炎的识别准确率有了明显的提高,在衡量模型性能的参数特异性与灵敏度上也有一定的提升。
3.2 结果分析
如表8所示,AlexNet_S模型与InceptionV3模型相比,前者作为Student Module,比后者节省了近一半的显存,使其能够更加灵活地部署在拥有不同大小显存的计算机上;同时,GPU使用率下降了51个百分点,使Student Module能够应用于GPU计算能力较弱的计算机上,让神经网络的可移植性大幅度提高。
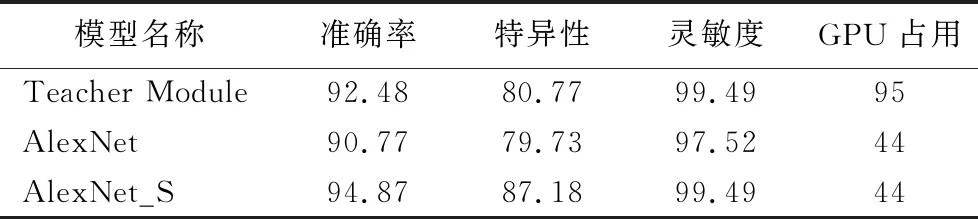
表8 优化前后AlexNet模型性能对比 单位:% Tab. 8 Performance comparison of AlexNet model before and after optimization unit:%
在衡量模型性能的指标方面,如表8所示,AlexNet_S模型比未优化的AlexNet模型在衡量模型分类能力的指标准确率上,前者比后者提高了4.1个百分点,比InceptionV3模型提高了2.39个百分点。在肺炎诊断的过程中,及时发现及时治疗对于患者最为有利,而灵敏度越高,模型对于肺炎判别的漏诊率越低。AlexNet_S模型比AlexNet模型的灵敏度提高了1.97个百分点,且与InceptionV3模型在灵敏度参数上性能相同。特异性作为衡量模型正确识别正常患者能力的重要指标,特异性越高,模型对于肺炎判别的误诊率越低。在特异性这一指标上,AlexNet_S模型比AlexNet模型提高了7.45个百分点,比InceptionV3提高了6.41个百分点。
综合实验结果,可以看出通过知识蒸馏的方法能够有效增强学生模型的识别能力,提高其分类性能。学生模型在特异性指标上比原有模型大幅度提高,在识别准确率以及灵敏度指标上达到甚至超过教师模型。
4 结语
针对医学影像分类特点,本文提出了一种使用卷积神经网络实现肺炎CT图像分类的方法。利用两种结构、深度不同的神经网络模型AlexNet与InceptionV3,使用知识蒸馏方法得到优化后的模型AlexNet_S,在分类性能上接近甚至超过InceptionV3模型的同时,大幅度降低了模型对系统资源的需求。在今后的工作中,进一步提高教师模型的性能,同时减少学生模型对系统资源的需求可以作为未来研究的方向。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
