
基于LSTM 神经网络的电网文本分类方法
2020-03-05 09:33张云翔饶竹一
现代计算机 2020年2期
张云翔,饶竹一
(深圳供电局有限公司,深圳518001)
0 引言
在电力物联网高速发展的今天,电网系统中有着大量的电子文本,如电网客户信息、电网业务数据等。而由于当前电网信息管理混乱,数据模型未统一,同一信息可能因为不同业务格式存在文本上的差异,没有统一的标准,这会严重影响电网系统的各项业务效率和成本。因此,对电网系统中的海量电子文本进行检索和信息提取,再进一步进行分类,就显得十分有意义。
文本分类(Text Classification)是自然语言处理(NLP)的主要研究问题之一,指的是在一个被事先定义好的固定类别中根据文本的特征将给定的文本对象进行分类的技术。典型的应用有判定垃圾邮件、网页自动分类[1]、情感分类[2]和新闻个性化推荐[3]等。在20 世纪50 年代,单纯依靠文档中出现与类名相同的词来进行文档分类的词匹配法[4]出现,之后又出现了向量空间模型[5]和知识工程,但这些算法十分依赖于人力,且方法十分简单,分类结果并不能满足要求。之后,随着机器学习算法的发展,SVM 模型[6]、贝叶斯网络[7]、决策树[8]等算法开始应用于文本分类。现如今,人工智能(AI)技术的快速发展使文本分类得到了新的发展,其成为了AI 子领域自然语言处理(NLP)的一个重要分支,神经网络,如卷积神经网络(CNN)[9]与深度神经网络(DNN)[10]也越来越多的应用到文本分类中来。但这些传统的网络存在梯度消失问题,无法处理长时间序列数据,基于此,专门用于处理时间序列数据的长短期记忆网络(LSTM)被提出,本文便是利用LSTM 神经网络来进行电网文本分类。
1 方法准备
1.1 自然语言处理NLP
自然语言处理(NLP)是一种人机交互方式,目的是让计算机理解人类所用的自然语言,从而实现诸如人机交互或是语言翻译等功能[11]。它涉及人工智能、语言学和计算机科学三大领域,是人工智能的重要分支。从语言学角度,语言可以分为形式语言和自然语言,形式语言是人为创造的用数字等符号描述的语言,可以被机器处理,如编程语言、化学符号等,而自然进化的语言,如人类的语言就是自然语言,跟形式语言相比,它缺乏固定的格式,存在大量歧义语句、相似语句等,使得其无法直接被机器所理解。自然语言处理便是研究如何对自然语言进行加工处理,从而实现人机交互的学科。
NLP 的研究问题主要包括信息检索、机器翻译、机器写作、语音识别、文本分类、文本挖掘和文本匹配等,其中文本分类便是本文的研究重点,由于自然语言是由大量人群进行长时间对话交流演变而来的语言,所以它是一种“经验主义”的语言模型,即基于统计的模型。因此,将大规模的真实语言文本进行收集整理形成一个真实语言库,再运用统计技术对该语言库进行分析,就可以进行语言文本分类。文本分类一般分为文本预处理,文本特征提取和文本分类几大部分。
1.2 LSTM神经网络
长短期记忆网络(LSTM)是一种专门用于处理时间序列数据的网络[12],传统的RNN 神经网络的神经元是将输入运用函数进行计算后进行输出的单元,而LSTM 将神经元变为记忆单元,每个记忆单元由输入门、遗忘门和输出门构成,其单元结构图如图1 所示。其中长期状态c 用于存储长期记忆信息,使得序列的长期状态可以保存下来,并传递到下一层,同时,遗忘门的设计又使得c 得到更新,丢弃已经过时的信息。LSTM 的这一设计解决了RNN 网络存在的梯度消失和梯度爆炸问题。
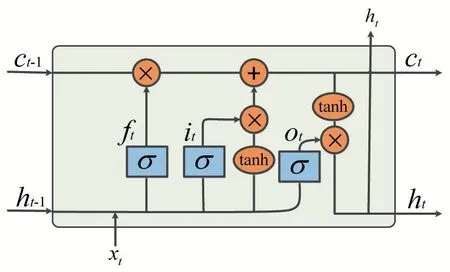
图1 LSTM神经元
t 时刻的数据xt到达网络后,与上一时刻LSTM 的输出ht-1一起作为输入,对Ct-1进行更新,得到新的长期状态Ct,计算公式如公式(1)所示。
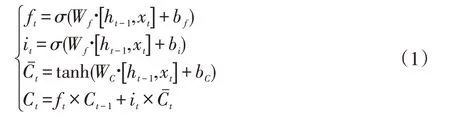
之后,输入进行sigmod 计算后,与更新后的长期状态Ct进行计算,得到该时刻的输出ht,ht的计算公式如公式(2)所示。

2 方法构建
在本节,针对电网行业文本分类存在的问题,提出了一种基于LSTM 神经网络的文本分类模型。模型主要分为三部分:预处理、特征提取以及文本分类。如图1 所示为模型的三层框架。
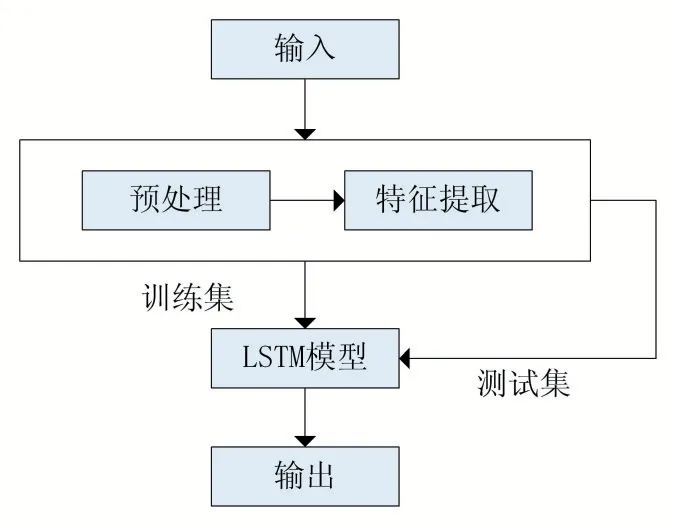
图2 文本分类模型的三层框架
2.1 预处理模块
在文本分类过程中,由于电网数据的多样化的特点,导致存储的大部分数据都为非结构化数据。面对这些复杂数据,计算机是无法直接处理的。这就需要先将文本进行预处理,并且将其转换成计算机能够识别出的形式。本文采用中科院的ICTCLAS 中文词法分析系统进行分词预处理并使用向量空间模型(VSM)进行文本模式化。
假设文档集合Y 中某一文本X,其中Y 的文档数量为N。向量空间模型是一种使用向量表示数据的模型,通过向量空间的模式化,可以降低文本分类的难度。 对于文本 X,通过向量空间模型得到,其中n 表示文本X 中词的数量,xi表示文本X 的第i 个词,wi为xi对应的特征权值,具体如下公式(3)所示:
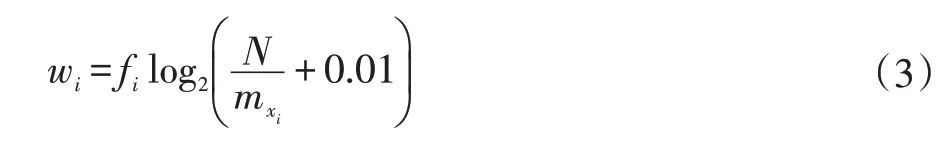
其中fi表示为xi在文档X 中的出现次数,mxi表示为在集合Y 中出现xi的总文本数量。
对其进行归一化处理,则wi由公式(4)所示:
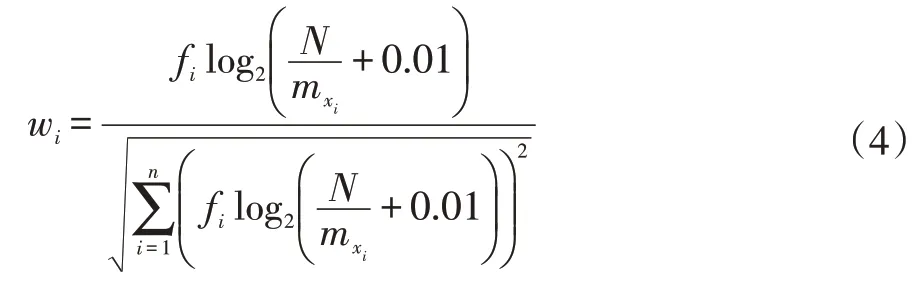
2.2 特征提取

由于互信息(MI)只考虑了xi和文本类别ck之间的关系,本文考虑到特征的选择一定程度上还会收到xi在整个文本集合Y 中的出现频率的影响,通过改进MI 算法得到如公式(5)所示:其中Pck表示属于ck的文档在集合Y 中所占比重,α 为控制阈值,为含有词xi的文本属于文本类别ck的比重,其表达式如下公式(6)所示:

其中hck表示为属于类别ck的文本的数量,Su 表示为属于类别ck的词的总数,Fk为所有词属于ck类的数量。
设置合适的特征选择阈值b,选择互信息值高于阈值b 的词,将其视为文本的特征值用于文本分类。
2.3 文本分类
假设经过上述预处理和特征提取之后得到的文本X 的对应特征向量为,其中w<=n。通过已知对应类别标签的文本训练集对文本分类模型进行训练。本文采用LSTM 神经网络作为文本分类模型进行分类训练。其算法伪代码如下所示:定义输入为文本Y,其某个文本X 经过预处理以及特征提取得到特征向量,作为LSTM 神经网络的输入节点,输出为分类模型对所有文本集合Y 做出的分类预测类别集合CY。
输入:文本Y
输出:分类预测类别CY
步骤3:根据控制阈值b 获得模型输入特征集合Y";
步骤4:CY=LSTM(Y");
3 实验验证
本文实验部分的数据来自于国家电网提供的变电站信息系统数据。根据电网的相关要求,可以将这些数据具体分为电网设备检修操作票、信息系统检修计划单、信息系统检修工作票、信息系统检修操作票、客服服务工作票。文本总量为3000 篇,平均每类为600篇。选取每类的70%作为文本训练集用于训练模型,剩余每类30%作为测试集测试分类模型的性能。经过训练以及测试,其结果如下所示:其平均率可以达到91%以上。
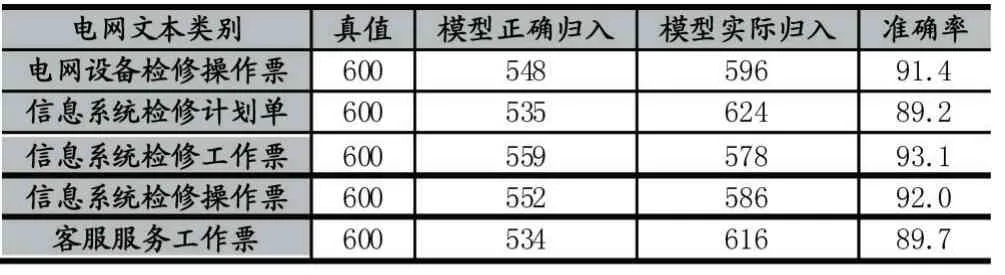
表1 实验分类结果
4 结语
本文基于电网系统中存在大量电子文本,但当前电网信息管理较为混乱,没有统一模型的现实,为了对电网系统中的海量电子文本进行检索和信息提取,构建了一个LSTM 神经网络分类模型来对电网文本信息进行分类,之后,通过基于国家电网提供的变电站信息系统数据的实验验证了本方法的有效性。
猜你喜欢
纺织标准与质量(2022年3期)2022-08-10
客联(2022年3期)2022-05-31
健康体检与管理(2022年4期)2022-05-13
化工进展(2022年3期)2022-04-12
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
建材发展导向(2021年23期)2021-03-08
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
电脑爱好者(2017年7期)2017-05-06
