
国际空间站健康管理系统对我国空间站建设的启示
2020-03-03 08:28:10李瑞雪张泽旭
载人航天 2020年1期
李瑞雪,张泽旭
1 引言
随着航天技术的发展,航天器的设计变得复杂,航天器的故障种类也迅速增加[1]。航天器本身应具有一定的监测、判断和诊断能力,即健康管理能力,以减少航天员和地面工作人员的工作量,降低他们开展故障诊断、处置工作的难度和复杂度。
目前,我国航天器健康管理技术较落后,航天器状态监测可实现自动阈值判断,但监测数据缺乏分析处理,导致出现故障多为突发性故障,处理较为被动;有基于规则的故障诊断工具,但是只能覆盖一小部分故障,且误报率较高,还要靠人工来分析。这些都极大地增加了操控人员的工作量和工作难度,需要操控人员具有丰富的知识和经验,且存在漏判、误判的隐患,影响了航天器的安全性和可靠性,长期占用大量测控资源,大大增加了任务成本。
像空间站这样的载人航天器,结构复杂,状态特征参数类型多,可靠性要求高,在轨运行时间长,对航天器健康管理能力提出了更为迫切的需求[1]。随着天宫二号实验室于2019年7月19日受控离轨,我国空间站工程全面展开,正式迈进空间站时代。急需学习国外先进的理论和技术,提高我国航天器健康管理的水平,为未来空间站运行做好准备。
自1998年国际空间站(International Space Station,ISS)首个组件——曙光号功能货舱发射成功,国际空间站已经成功在轨运行二十多年,开发了许多针对航天器健康管理的工具,为航天器健康管理积累了丰富的经验,对未来我国空间站的建设具有极高的借鉴意义。因此,本文对应用于国际空间站的健康管理工具进行介绍,并简述从中获得的启示。
2 发展历程和内涵
航天器集成式系统健康管理(Integrated System Health Management,ISHM)技术是在美国国防部和NASA的大力推动下不断发展、成熟起来的,起源要追溯到20世纪50年代和60年代可靠性理论、环境试验和系统试验以及质量方法的诞生[2]。60年代只进行简单的状态监测;70年代出现了基于算法的诊断故障源和故障原因技术[2];随着人工智能研究的重大突破,80年代专家系统开始用于故障诊断[3];随后NASA于90年代初期适时提出了飞行器健康管理(Vehicle Health Management,VHM)的概念[2];20世纪末到 21世纪初,NASA引入了航天器集成式系统健康管理的概念[2],从系统级考虑航天器的健康管理。
航天器集成式系统健康管理是指航天器能够对自身状态进行监控和感应,对出现的故障能够自主进行检测、隔离和恢复。这是一个综合的框架,涉及到的功能主要包括:①异常检测/状态监测;②诊断;③预测;④操作员的综合意识[4]。典型的航天器集成式系统健康管理功能流程[5-6]如图1所示。

图1 集成式系统健康管理功能[5-6]Fig.1 Functions of integrated system health management[5-6]
首先航天器系统必须提供相关数据以便进行实时监测,判断系统行为是否异常(异常检测/状态监测)。如果异常,需要采取有效措施去确定故障部件的位置(故障隔离)和与该故障最有关联的变量(故障识别)。确定故障位置和根源后,选择缓解故障的措施(故障响应)。此外,预测方法可以在故障发生前对其进行预测,并提示操作人员在部件失效前对其进行替换或维修,预防故障发生,并优化系统性能。
下面针对该框架涉及到的主要功能-状态监测和诊断,介绍ISS上应用的状态监测和故障诊断工具。没有对预测工具的介绍是因为目前为止ISS还没有专门的故障预测工具。
3 状态监测工具
NASA航天器状态监测/异常检测主要是通过归纳式监测系统(Inductive Monitoring System,IMS)实现的[7-9]。2007年,基于IMS的工具开始用于实时监视ISS控制力矩陀螺系统,后不断扩展,截至2012年基于IMS的状态监测工具已用于25个ISS子系统的实时监测[10]。此外IMS应用于多个其他航空航天项目:混合燃烧设施、先进的火箭燃料测试设施、RASCAL UH-60黑鹰直升机等。
3.1 基本思想
IMS使用基于距离的聚类算法,其基本思想如下:假设某系统健康状态由一系列特征参数的值来表述,这些参数值(一般先经过归一化处理)映射为多维空间中的一个向量(点),不同时刻向量间距离大小可以表示状态差异的程度,这是聚类学习算法的基础。聚类算法使用系统正常状态的运行数据作为训练库,经聚类后获得簇集的信息,簇集的信息构成系统健康状态模型。
IMS工作流程如图2所示。在进行健康状态监视时,将被监控系统实时数据与系统健康状态模型进行比较,通过与系统健康状态行为的差异大小来判断系统是否处于健康状态;如果数据向量位于健康区域之内,则判断系统处于健康状态;如果数据向量到健康区域的距离为一个较小的非0值,则系统发送一个低等级的警报信息,表示当前状态暂时偏离正常工作状态,但系统仍处于健康状态。如果数据向量连续处于健康区域之外,且到健康区域的距离较大,则认为系统此时处于异常状态,根据距离值的大小发送中等级或高等级的警报。
与系统健康状态模型的显著偏差可以用来提供警报,以提醒注意潜在的系统故障或重大故障的前兆。IMS还提供与每个监测参数对检测到的偏差的相对贡献量有关的信息,报告相应的最有可能导致系统异常状态的遥测参数,这有助于隔离异常的原因。
3.2 优点
IMS采用了数据驱动的思想,与其他监测复杂空间飞行器的方法相比具有如下优点:

图2 使用IMS进行状态监测工作流程Fig.2 Workflow of State monitoring using IMS
1)自学习功能。开发人员不需要为系统建立详细模型,监视系统所需的知识来自于收集的归档数据,通过对正常数据进行处理和训练,自动生成健康监测知识库[8,11],且其形成的知识库也很容易更新。
2)定量判读功能。通过与健康状态的差异大小来定量描述系统的健康状态,区分系统异常状态的等级,IMS还提供与每个监测参数对检测到的偏差的相对贡献量有关的信息,这有助于隔离异常的原因[8]。
3)多维判读功能。通过对描述某一分系统或单机设备状态的多个参数进行组合处理,全面反映系统某一分系统或单机设备的状态,提高判读准确性[12]。
4)不需要异常(故障)行为的数据。IMS自动分析系统健康状态数据,可以直接从实际操作期间要监控的系统传感器收集,也可以从系统模拟中收集,或者两者兼而有之,不需要故障数据作为训练数据[7,13]。
5)具有较好的通用性。不同参数的组合均可以映射到多维空间中的向量[8],适用于不同类型的健康状态评估任务。
6)不需要过多的计算机资源。IMS可以快速计算来监控系统性能和检测异常行为,而不需要过多的计算机资源[7],非常适合在计算资源有限的环境中使用。
IMS具备许多优点,同时也存在虚警率较高的问题。IMS虚警率较高是因为它比较敏感,而且在安全性和可靠性要求很高的航天领域,监测系统敏感要远比漏报好得多。
4 故障诊断工具
NASA已经开发了一些较为成熟的故障建模分析工具和平台,大部分已在国际空间站中得到了应用。
所有需要计算机控制的国际空间站系统都依赖于指挥和数据处理系统(Command and Data Handling System,C&DH)。该系统是由多台计算机、总线、多路复用器(Multiplexor/Dimultiplexors,MDMs)等组成的网络。用于故障诊断的软件(主要 有 TEAMS-RT[14-16]、 Livingstone[17-19]和HyDE[20-21])运行在相应的机载计算机上。提醒和警告系统(Caution and Warning System,C&W)是由一组运行在MDMs上的软件和电子设备构成,负责检测、分类和报告包括C&DH在内的所有ISS子系统中的错误并作出相应提示[22]。输入通过MDMs从机载计算机进入C&W逻辑电路,以激活C&W警报。
4.1 TEAMS-RT
TEAMS-RT(TEAMS-Testability Engineering and Maintenance System)是美国Qualtech公司开发的实时诊断和在线健康监测的工具[14],已用于ISS指挥和数据处理系统、X-33飞行器的健康管理项目、深空栖息地(Deep Space Habitat,DSH)项目等[23]。
TEAMS-RT是基于图模型的故障诊断和健康监测工具。在此工具集内,故障源、部件冗余和系统模式的信息以不同颜色的图模型(亦称作多信号模型)来标注。
图3展示了利用TEAMS-RT进行实时监控和故障诊断流程。TEAMS-RT通过观察不同监测点(测试点)实时监视系统的健康状态[15]。测试是通过观察不同测试点确定故障原因的过程。结合来自数据获取单元、滤波单元和特征提取单元的信息判断监视点状态,这一过程称为“测试”[24]。故障或异常的判断准则主要有:①阈值判断,通过周期性的测试设备各个输出参数是否与超过正常范围来检测是否发生异常;②一致性判断,对设备在同一工作模式和环境下,釆用相同的测试方法,对当前测试结果与正常工作情况下的数值是否一致,来判断是否发生异常;③趋势值判断,对设备相同的输出参数,当前数值与一段时期内数值进行比较,判断趋势是否正常,来判断是否发生异常;④预期值判断,通过对观测值与模型给出的预测值进行比较来检测是否发生异常。通过测试,确定各个测试点的状态,然后利用多信号模型包含的故障传播逻辑确定系统的状态。
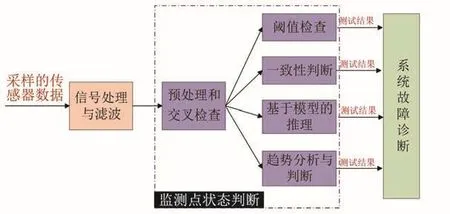
图3 使用TEAMA-RT进行实时监视和故障诊断Fig.3 Real time monitoring and fault diagnosis using TEAMS-RT
Teams-RT具有以下特点:
1)高效实时处理。0.1 s就可以处理1000多个传感器结果[14]。
2)响应系统模式变化。不断更新组件冗余等信息。
4.2 Livingstone
Livingstone是NASA所属的Ames研究中心开发的基于定性(离散)模型的故障诊断通用软件[24],现在用的 Livingstone 2(L2)版本已用于ISS热控等系统、深空探测器Deep Space-1、地球观测1号卫星(Earth Observe-1)等[17]。
Livingstone软件是基于定性模型的故障诊断系统,即通过预报行为和观测行为的比较和分析,确定其中的故障[24-25],图4显示了Livingstone的工作流程。L2模型以基于组件的方式被创建,首先定义组件,然后进行连接来创建整个系统模型[18,21]。L2模型是离散的,系统变量可取有限数目的值,L2组件连接模型描述组件的正常模式和故障模式[18]。
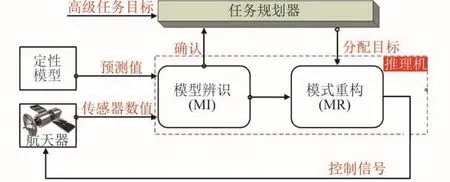
图4 Livingstone系统工作流程Fig.4 Workflow of Livingstone System
系统的观测行为通过系统的传感器实测给出。系统定性模型则用来预测在正常情况下系统应有的观测结果,即预测行为。L2通用推理机(General Diagnostic Engine,GDE)是固定的,不会因为被诊断对象的不同而改变。它包括模型辨识(Mode Identification,MI)和模型重构(Mode Reconfiguration,MR)两部分。MI负责模式确定,通过预测行为和观测行为的比较和分析,确定其中的不一致性,预测和实际观测值之间的差异就表征了一个故障,根据模型确定引起故障的元件。
如航天器运行正常,则系统仅保持实时观测而不作干预。如果出现故障,航天器的结构状态不能满足当前的预期目标时,L2启用MR来确定一系列控制过程,使航天器达到一个新的状态结构以满足预期目标。如果无法完全恢复,那么MR就将航天器恢复到一个安全状态,等待地面运行团队的援助。
L2系统具有以下特点:
1)能够同时诊断多个故障;
2)能够从诊断出的故障中恢复;
3)只能支持定性(离散)模型,不能诊断渐变、缓慢故障。
4.3 HyDE
NASA于2005年推出了混合诊断推理机(Hybrid Diagnostic Engine,HyDE),应用于 ISS 电力系统、火星自动钻探原型机DAME(Drilling Automation for Mars Environment)项目、先进的诊断和预测试验台ADAPT(The Advanced Diagnostic and Prognostic Test-bed)等[20]。
同Livingstone系统一样,HyDE也是基于模型的诊断系统,不过它可以使用定性(离散)和定量(连续)混合的模型[21],利用系统模型预测与系统传感器观测输出之间的差异来诊断。HyDE所用诊断模型可采用分层和模块化形式来创建[26]:首先,建立每个部件的模型,部件间的相互作用以连接权的形式被建模,部件组合在一起就构成了分系统以及系统模型。每个部件模型捕捉相关联部件的故障转变和传播行为。转变模型描述该组件的所有操作模式和这些模式间的转变条件,故障作为特殊的转变被建模,其中转变条件必须能够由推理机推断而出。
由于在混合模型中引入了定量信息,诊断结果更为准确和全面[22]。在诊断推理的各个步骤中,有数种可供选择的算法。HyDE是可扩展的,支持添加新的建模范式以及诊断推理算法[20]。
HyDE系统具有以下特点:
1)可建立定性+定量的混合模型;
2)计算量大,给出的推理结果可能比较多;
3)可扩展,支持添加新的建模范式和推理方法。
5 集成式故障管理工具
2010年NASA开发了下一代载人航天器故障管理系统——高级提醒和警告系统(Advanced Caution and Warning System,ACAWS)[23,27-28]。 虽然现在还没有在ISS等载人航天器上使用,已使用HDU(Deep Space Habitat)对ACAWS系统进行了3次评估:2011年9月,作为沙漠研究和技术研究(Desert Research and Technology Studies,DRATS)的一部分;2012年6月,作为自主任务运行(Autonomous Mission Operations,AMO)测试的一部分;以及2012年9月,作为任务运行测试(Mission Operations Test,MOT)[23]。 该系统结合了航天器系统的动态和交互式图形表示、自动诊断分析、系统和任务影响评估等,以帮助航天器操作人员(包括飞行控制员和机组人员)更有效地理解和应对异常情况。
图5显示了ACAWS系统的构架。其中ACAWS的4个主要组成部分是:①异常检测(A-nomaly Detection);②故障检测和诊断(Fault Detection+Fault Diagnosis);③系统影响分析(SysEffects);④图形用户界面(Graphics User Interface,GUI)[23]。
异常检测模块采用了归纳式监测工具IMS,监测系统状态并在系统行为异常时通知操作员;故障检测和诊断模块使用了TEAMS-RT工具,用于确定故障类型及发生故障的组件;系统影响分析模块确定在特定组件故障的情况下,哪些组件将受到影响,从对应于需要确定影响的故障的节点开始遍历,确定下游组件是否受故障影响;图形用户界面以适当的灵活格式向操作员显示系统视图和诊断信息,并接受操作员的输入。这些模块通过面向中间对象的Internet通信引擎(Internet Communications Engine,ICE)相互通信,并与 HDU模块通信[23]。当确定一个明确的故障时,ACAWS建议一个程序来恢复功能(如果可能)或解决损失。ACAWS推荐程序发布在ICE上,并由程序显示工具WebPD接收(WebPD由NASA约翰逊航天中心(JSC)开发,操作人员使用它来完成程序说明)[23]。遥测值、诊断和推荐程序均显示在图形用户界面(Graphics User Interface,GUI)上。

图5 ACAWS的系统构架[23]Fig.5 System architecture of ACAWS[23]
将故障诊断等功能集成到ACAWS很简单,包括将故障诊断等软件连接到通信层(ICE),并将另一个显示窗格添加到 ACAWS GUI[23]。ACAWSGUI使用了多线程模型,它连接到通信中间件(ICE)以从ACAWS实时获取数据:HDU传感器读数、IMS状态监测、TEAMS诊断结果、推荐程序、维修程序[28]。以AMO测试任务为例,GUI显示由AMO各组件(监视器组件、异常检测组件等)生成的各种动态数据。这些组件与被监测系统生成的文件和数据进行交互,并进行地面数据更新(时间表或配置文件更改)[29]。AMO监视器组件查看新的被监视系统结果文件的共享文件空间。当检测到新的文件时,AMO监视器调用异常检测、故障检测和JSON编写器组件来处理新文件。生成的数据文件被动态写入以填充GUI结果和数据选项卡[29]。当收到新数据文件时,AMO体系结构做如下处理:
1)新文件将传递到共享文件系统;
2)AMO监视器组件检测到此文件,检查确定它是新文件;
3)AMO监视器调用异常检测组件中的IMS,异常检测执行系统与通信中间件(ICE)的连接,以检索实时遥测数据,为给定的操作阶段选择适当的知识库(KB),将数据编组到适当的向量中,发送到IMS,将IMS分析结果发布回ICE[28];
4)一旦IMS完成,AMO监视器调用故障诊断组件中的HyDE,文件接收和诊断结果发布也是通过ICE;
5)一旦HyDE完成,AMO监视器调用JSON编写器;
6)一旦JSON编写器完成,动态创建的内容已准备好由Web服务器和用户界面显示[29]。
只要航天器上生成的适当JSON文件被移动到正确的位置,地面将看到机组人员看到的内容[29]。
6 启示
通过对ISS健康管理工具的分析可以发现,美国已经对航天器健康管理技术进行了比较深入的研究和广泛地应用。虽然集成式健康管理工具还没有在载人航天任务中广泛应用,但美国航天器ISHM技术已经发展到可以为实时故障检测、诊断、引导式故障排除和故障后果评估提供重要的自动化帮助的程度[27]。
我国对ISHM技术的研究虽然也取得了一定成果,但整体技术能力还存在比较大的差距。综合分析ISS健康管理工具,对我国空间站健康管理技术的启示如下:
1)进行顶层的、全面的ISHM工作策划。应该形成系统化、体系化的研究方法和工程可实施架构,弥补系统级诊断与故障预测技术理论。
2)开发通用的系统级状态监测、故障诊断和故障预测工具。为各系统健康管理工具软件的开发和重用建立一个标准化平台。实用程序、数据库、遥测访问和其他必要组件将集成到一个标准工具集中,使操作人员能够构建定制的用户界面,降低软件开发和测试的总成本。
3)功能集成。开发一个允许多个产品集成的平台,并使用它们实时协作,同时提高态势感知,减少解决故障所需的时间,使操作员能够专注于完成任务,而不需要管理多个软件工具。将ISHM信息集成到相关的信息显示界面中,使操作员能够快速、有效地处理和理解ISHM系统信息。
4)重视对数据的挖掘。据悉,我国空间站未来一个舱段就有三万多个参数,整体参数可达十万。单纯的阈值判断忽略了参数的变化趋势以及参数间的关联性,不能满足航天任务的需要。通过历史数据的纵向对比,关联数据的横向分析,寻找规律和趋势进而进行异常检测、故障诊断和故障预测。
5)分阶段有序推进。根据实际工程需求和技术成熟度有序推进航天器集成式系统健康管理工作。借鉴NASA的IMS系统,我国已经实现了一种卫星健康状态监测软件,经测试,验证了该软件能降低数据判读门槛,提高状态判读的全面性和准确性[13]。因此完全可以开发用于我国空间站的新的状态监测软件。在故障诊断方面,我国已经进行了大量的理论研究,且已经有基于规则的故障诊断工具,可以开始开发通用的系统级故障诊断工具和允许多个工具集成的平台。国内外故障预测研究都开始相对较晚,我国在故障预测领域还有待进一步的理论研究,因此目前阶段还应着重于故障预测技术的理论研究。
猜你喜欢
军事文摘(2024年6期)2024-02-29 10:00:22
中学生数理化·八年级物理人教版(2023年6期)2023-05-25 11:59:34
军事文摘(2022年18期)2022-10-14 01:34:16
国际太空(2022年7期)2022-08-16 09:52:50
国际太空(2019年9期)2019-10-23 01:55:34
国际太空(2018年12期)2019-01-28 12:53:20
国际太空(2018年9期)2018-10-18 08:51:32
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
小猕猴智力画刊(2015年2期)2015-01-27 22:21:45
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
