
基于主成分分析-相关向量机的高速公路路基沉降量预测
2020-02-24 07:36:12邝贺伟
科学技术与工程 2020年1期
张 研, 邝贺伟
(1.桂林理工大学土木与建筑工程学院, 桂林 541004; 2.桂林理工大学,广西岩土力学与工程重点实验室, 桂林 541004)
随着中国交通运输业的迅猛发展和公路修建技术的不断提高,高速公路成为中国连接主要城镇的重要纽带。路基作为高速公路关键组成部分及路面交通荷载承担者,其质量的好坏直接影响着高速公路的安全使用[1-2]。路基沉降是造成高速公路路面裂缝、道路倾斜、公路塌方等工程事故的主要原因,确切了解路基沉降情况有利于及时发现安全隐患,减少交通事故发生,提高道路使用寿命[3-5]。
然而,路基沉降受到自然和人为等多种因素的影响,各个因素相互影响、交叉作用,很难精准获得路基沉降量,很多学者关注到该问题的复杂性,开展了一系列的相关研究,如:戴少平[6]针对广东软土地区高速公路工后沉降问题,基于路基沉降规律及Taylor原理推导出幂多项式模型,并采用实例对该模型进行了验证;薛凯元等[7]对黄土地区高填路段地基沉降进行观测与分析,建立路基沉降量与地基土质量、施工速率、填土容重等4个相关参数的关系。传统的基于现场数据建立的沉降量经验公式难以涵盖多种影响因素,并且存在类似工程推广性差、精度难以保证等众多公开问题。因此,更加适用、准确、高效的路基沉降量预测模型亟待提出。
近年来,随着计算机科学的快速发展,学者们将机器学习技术应用于路基沉降量预测,并提出了多种预测模型,如:彭立顺等[8]提出高速公路路基沉降量预测的遗传优化神经网络预测模型;刘文豪等[9]针对某省高速公路近10年的路基沉降量实测值,利用神经网络和双曲线混合的模型对路基沉降量进行预测;胡习阳等[10]分别运用基于灰色理论的GM(1,1)、Verhulst和UGM (1,1)三种模型对张桑高速公路近47 d路基沉降量数据进行分析预测,结果表明Verhulst灰色模型精度最高。然而,神经网络方法本身存在着学习样本过少预测精度无法保证、样本过多泛化能力较低、本身收敛速度慢等问题;灰色模型需要求取原始序列变化规律,计算过程烦琐、计算效率较低。寻求更加准确、合理的机器学习模型已为学术界所关注。
基于支持向量机提出的相关向量机(relevance vector machine, RVM)[11-12]机器学习方法采用了马尔科夫性质、数据稀疏化、最大似然理论等多种数据处理技术,使得其能够高效、高精的处理回归问题[13-14]。然而当输入样本影响因素(即样本维数)较多的时候,会降低RVM模型学习效率,增加计算成本。为此,引入主成分分析法(principal component analysis,PCA)[15-16]对影响因素进行分析,选取较少的、线性无关的影响因素组成新的输入变量,该过程将原变量映射关系经过线性组合转移到新变量,使得新变量剔除影响因素间的冗余信息,仅包含各种有效原始信息;然而处理后变量个数得到压缩,达到降维的效果。采用RVM模型对新变量进行学习,建立PCA-RVM预测模型,并应用于高速公路路基沉降量预测,为高速公路路基沉降量高效、精确获取提供一条新途径。
1 PCA-RVM模型相关理论
1.1 PCA原理
设样本数据集有m个样本,每个样本的影响因素有n个,此时构建m×n阶矩阵:
(1)
在计算矩阵的协方差矩阵时,由于量纲不一致,需要对其进行标准化处理:
(2)
根据方程|λ-R|=0可计算出特征根,依据特征根λ1≥λ2≥…≥λm≥0得出对应的正交单位化特征向量为e1,e2,…,em。
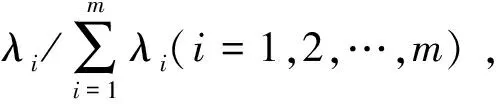
原数据矩阵经过主成分分析法降维处理后,由多个影响因素根据以下关系转化得到综合主成分变量y1,y2,…,yc(c≤n),得到新的变量与原影响因素关系为
(3)

1.2 相关向量机原理
RVM是一种基于贝叶斯原理的稀疏概率模型[17-18],其采用先验参数结构下的相关决策理论来除去不相关联的点,使得模型稀疏化,提高模型对样本的适应性[19-20]。设训练集为{yn,tn|n=1,2,…,N},其中,yn表示输入训练样本向量值,tn表示输出目标值且独立分布。设tn独立分布且带高斯噪声ξn,建立tn函数模型为:
tn=f(yn;ω)+ξn
(4)
(5)
式(5)中:t=[t1,t2,…,tN]T;ω=[ω0,ω1,…,ωN]T以及Φ都是由核函数预先设定的N×(N+1)矩阵,且Φ=[φ(y1),φ(y2),…,φ(yN)]T,φ(yn)=[1,K(yn,y1),K(yn,y2),…,K(yn,yN)]T。为避免过拟合现象发生,可以引入一些超参数α=(α0,α1,…,αN)T,对于不同的权重值都赋予均值为零的Gaussian先验分布型[21]:
(6)
引用超参数以后,RVM参数后验概率分布为P(ω,α,σ2|t),则训练样本后验概率分布为
(7)
(8)
由于后验概率分布P(ω,α,σ2|t)通过积分不能够直接算出,故分解为
P(ω,α,σ2|t)=P(ω|t,σ,σ2)P(α,σ2|t)
(9)
整理可得,则权向量ω的分布[22]为
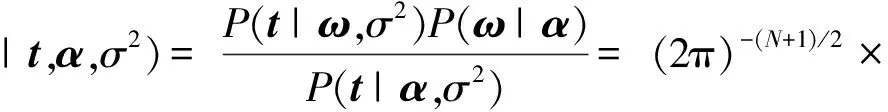
(10)
式(10)中:可以总结出概率分布服从多变量的高斯分布,Σ=(σ-2ΦTΦ+A)-1表示方差,其中,A=diag(α0,α1,…,αN)表示对角矩阵;μ=σ-2ΣΦTt表示均值。因P(α,σ2|t)不能直接计算,故利用狄拉克(Dirac Delta)函数近似计算,其表示为
(11)

αMP=argmax[P(α|t)]
(12)
(13)
对式(12)和式(13)求解可以将其转化为
P(α,σ2|t)∝P(t|α,σ2)P(α)P(σ2)
(14)
因此,后验概率函数分布的极值估计就转换成极值估计,P(t|α,σ2)=N(0,C),C=σ2I+ΦA-1ΦT,则P(t|α,σ2),P(α),P(σ2)得到边缘估计:
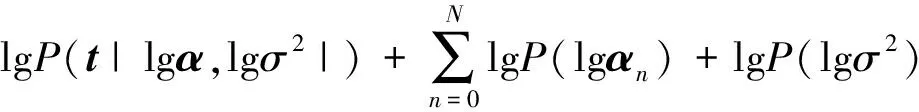
(15)
对式(15)求偏导可得
(16)
由此可得到矩阵对应的平均权重,令式(16)等于0,rn=1-αnΣnn可得
(17)
(18)

(19)
式(19)中:预测概率分布计算中,函数是两个高斯正态分布相乘得到,所以关于t*的预测分布也服从高斯正态分布,即
(20)
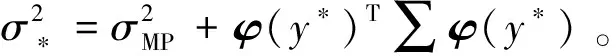
2 路基沉降量的PCA-RVM预测模型
2.1 数据样本确定
高速公路路基沉降量影响因子复杂,选择影响因子时经常会遇到影响因子不确定性、随机性等一系列问题。现利用主成分分析法探究各因素与路基沉降量之间的关系,对主要因素加以分析及降维得到新变量,再利用RVM建立预测模型。根据文献[8]综合选取处理方式、软土层厚、软土压缩模量、路堤高度、路基填筑期、竣工时沉降量等6个常规物理因子作为路基沉降主要影响因素,随机选取22组样本进行学习训练,剩余的6组作为预测检验,如表1所示。对表1标准化处理后的28组数据的6个指标进行主成分分析,得到各个变量间相关系数情况如表2所示。
由表2可见,处理方式、软土层厚、软土压缩模量、路堤高度、路基填筑期和竣工时沉降量6个影响因素之间的相关性绝对值均在0~1。基于1.1节所述各因素成分贡献率及累计贡献率计算方法,获得每个因素对高速公路路基沉降量的贡献率及累积贡献率情况,如图1所示。

表1 高速公路路基沉降数据集Table 1 The dataset of highway subgrade settlement

表2 各影响因素相关系数Table 2 Correlation coefficient of different influencing factors
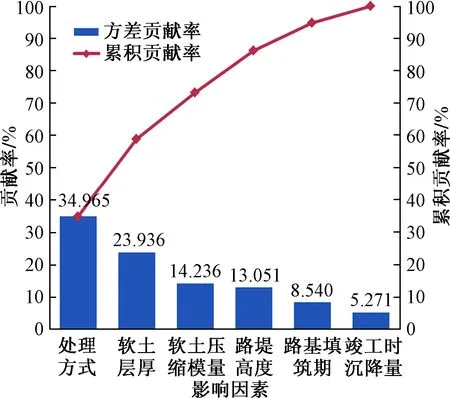
图1 各因素贡献率及累计贡献率Fig.1 Contribution rate and cumulative contribution rate of each factor
由图1可见,处理方式和软土层厚对高速公路路基沉降量的贡献率最大,软土压缩模量和路堤高度其次,路基填筑期和竣工时沉降量最小。前4个因素的累计贡献率大于85%,说明所包含的信息足够反映各个变量的内在关系。因此,选取前4个成分作为主成分进行分析。为研究不同影响因素在主成分变量下对应的权重,采用最大差分法得到成分得分系数如表3所示。
每个主成分变量等于各影响因素与对应成分得分系数的乘积,根据此关系可得到4个主成分变量的表达式分别为
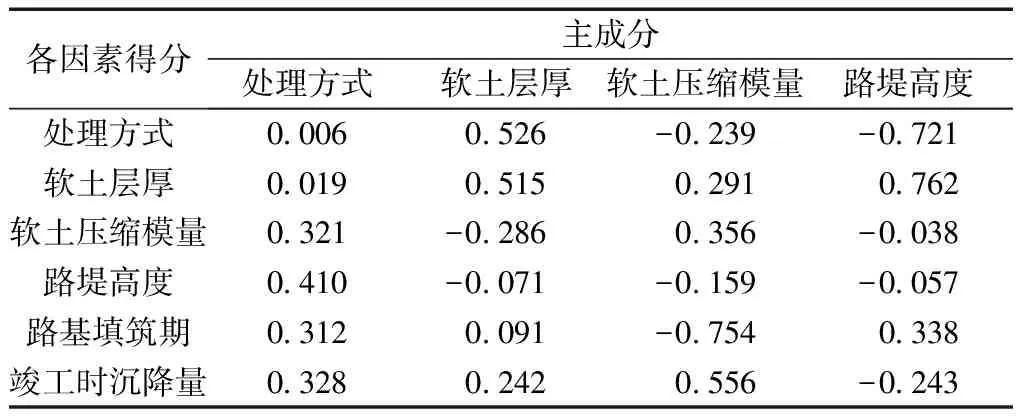
表3 成分得分系数Table 3 Component score coefficient
y1=0.006x1+0.019x2+0.321x3+0.410x4+0.321x5+0.328x6
(21)
y2=0.526x1+0.515x2-0.286x3-0.071x4+0.091x5+0.242x6
(22)
y3=-0.239x1+0.291x2+0.356x3-0.159x4-0.754x5+0.556x6
(23)
y4=-0.721x1+0.762x2-0.038x3-0.057x4+0.338x5-0.243x6
(24)
由主成分变量组成新的4×28维数据矩阵,代替了原来影响因素组成的6×28维数据矩阵,有效降低了模型维数,优化了相关因素,提高了运算效率和模型预测的准确率。
2.2 路基沉降量预测模型
基于主成分分析法对文献[8]选取的6个主要影响因素转化成4个主成分变量,选取4个主成分变量作为高速公路路基沉降量主要影响因子。依据PCA-RVM回归预测模型的原理,建立基于4个主成分的PCA-RVM路基沉降量预测模型,基本原理如图2所示。
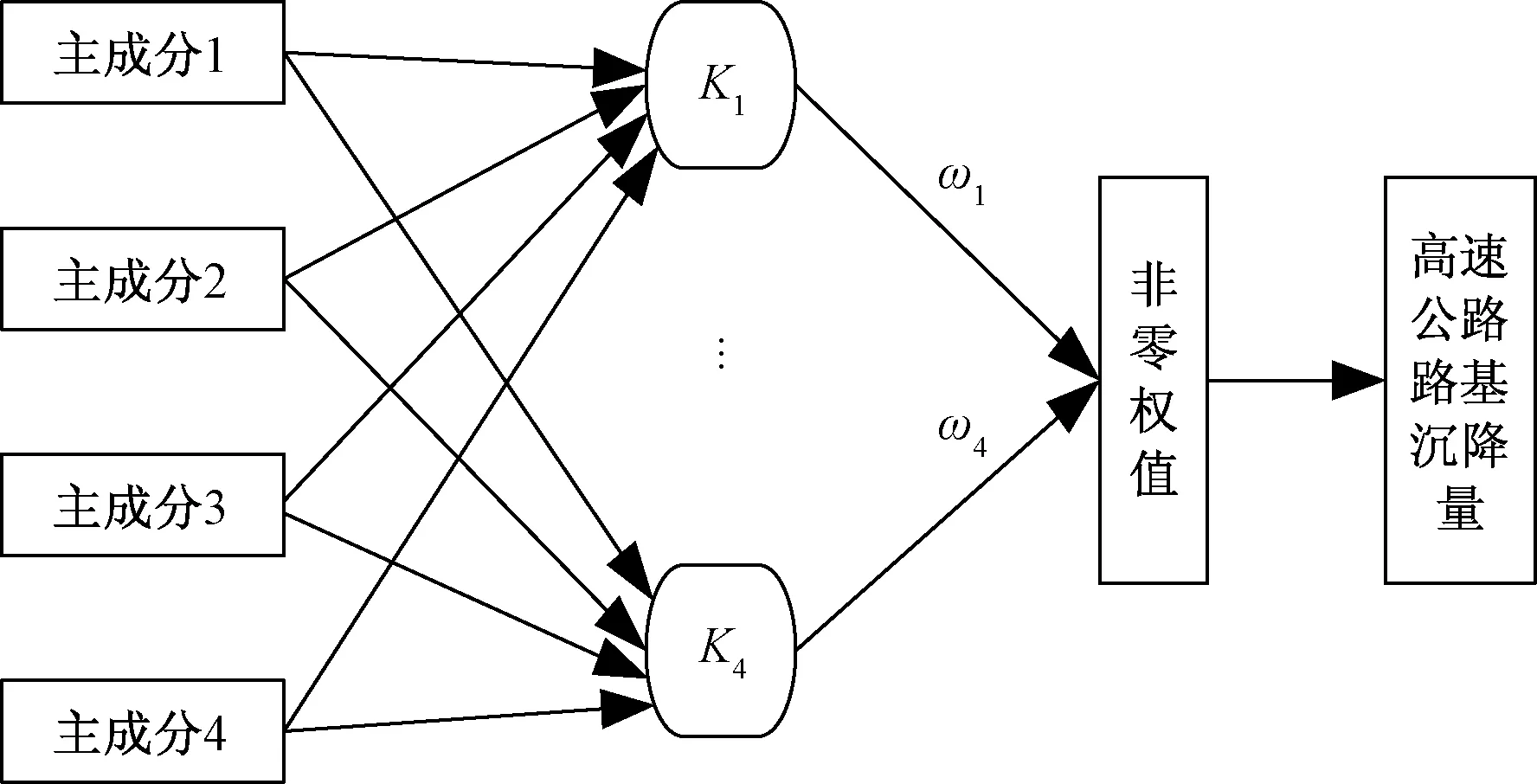
图2 基于PCA-RVM的高速公路路基沉降量模型Fig.2 Model of highway subgrade settlement based on PCA-RVM
2.3 模型实现步骤
(1)根据高速公路路基沉降的主成分分析原理收集主成分数据,并对收集的主成分数据依照式(21)标准化处理,确定其中影响高速公路路基沉降的4个主成分为输入,高速公路路基沉降量为输出。
(25)
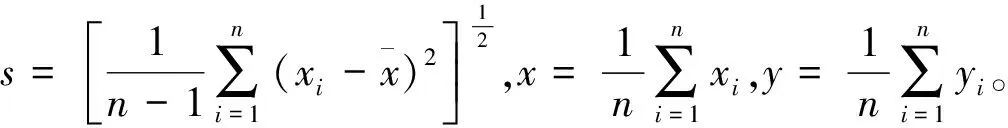
(2)选取前部分数据作为学习样本,用于模型的拟合训练学习;剩余数据作为预测样本,用于模型的效果检验。
(3)建立PCA-RVM预测模型,对学习样本进行训练学习,以模型训练的预测值和实测值的误差作为精度要求,通过调整迭代次数、超参数寻求符合精度要求的PCA-RVM模型参数。
(4)基于上述给出的模型参数建立的PCA-RVM预测模型,对预测样本进行预测;通过相对误差、均方差等指标验证PCA-RVM预测模型的精确度及可靠性。
3 应用实例分析
采用上述PCA-RVM预测模型对工程实例进行应用分析,具体数据情况如表1所示,其中前22组为数据训练样本,剩余6组数据为预测样本;并在相同样本条件下与文献[8]所提出的RBF神经网络、BP神经网络、Elman神经网络和GABP神经网络预测结果进行对比分析。初始化MATLAB模型程序,综合考虑并选取具有较强的局部插值能力的高斯核函数作为PCA-RVM模型RVM的核函数,对核函数参数(高斯核宽度)值分别选用0.74、0.76、0.78、0.80、0.82、0.84进行优化,不同参数取值对应的学习样本平均相对误差情况如图3所示。
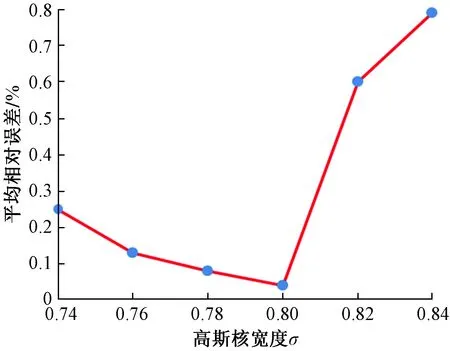
图3 不同核宽度的学习样本平均相对误差Fig.3 Average relative error of learning samples with different kernel widths
由图3可知,选取高斯核宽度σ=0.8时得到的平均相对误差最小。故选用核宽度σ=0.8,初步拟定迭代次数为1 000。模型通过最大似然法得
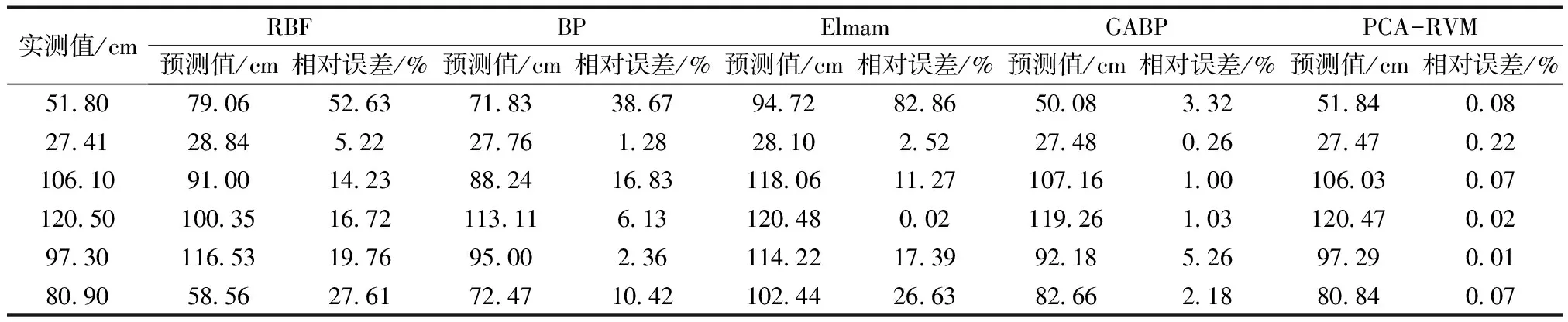
表4 不同方法的预测结果比较Table 4 Comparison of prediction results of different methods
到最优超参数α,α=[14.33 29.09 15.13 16.41 21.93 282.15 24.20 70.11 14.66 83.48 1.85 47.30 2.16 3.98 19.13 281.07 335.53 24.85 4.55 159.68 14.81 4.42 1.85 4.63 10.44],输出对应权值ω=[0.26-0.18 0.26-0.25-0.21-0.06 0.20 0.12-0.26-0.11 0.73 0.14 0.68 0.50 0.23-0.06 0.05 0.20 0.47-0.08-0.26 0.48 0.74 0.46 0.31]。基于学习样本及选取的参数建立预测模型,对预测样本数据进行预测,预测结果如表4所示。
表4中列出了PCA-RVM模型预测结果以及文献[8]中采用相同数据的4种神经网络预测结果。在5种模型预测结果中可见:PCA-RVM模型预测结果最大相对误差仅有0.22%;GABP模型最大相对误差为5.26%;而Elmam模型最大相对误差高达82.86%;BP模型最大相对误差也有38.67%;RBF模型最大相对误差为52.63%。由此可见,PCA-RVM模型单个样本预测精度远远高于其他模型。
为了更直观对比5种模型预测结果的样本分布特征,将5种模型的路基沉降的预测值和实测值进行对比,如图4所示。由图4可见:PCA-RVM模型各个样本预测值均比文献[8]中4种神经网络模型预测结果更接近真实值,几乎与实测值曲线重合,表明PCA-RVM模型的预测精度最高;而4种神经网络模型中GABP最好,但相比PCA-RVM模型,23号、27号样本偏差较大略显不足;RBF神经网络模型、Elmam神经网络模型和BP神经网络模型的预测值明显偏离了实测值,误差过大。

图4 不同方法预测结果Fig.4 Predicting results of different methods
为了定量化对比5种预测模型的整体预测精度和离散情况,分别计算各模型平均相对误差(ARE)和均方差(FMSE),评判预测结果的可信赖程度和离散程度,计算公式为
(22)
(23)
式中:n为样本数量;yi为实际值;y′i为预测值。
5种模型平均相对误差和均方差计算结果如表5所示。

表5 平均相对误差及均方差Table 5 Average relative error and mean square error
本文提出的PCA-RVM预测模型平均相对误差为0.08%,均方差为0.05;GABP模型的平均相对误差为2.17%,均方差为2.41;Elman预测模型平均相对误差为23.45%,均方差为21.35;BP预测模型平均相对误差为12.62%,均方差为11.91;RBF预测模型平均相对误差为22.70%,均方差为19.36。PCA-RVM模型均比其他4种神经网络预测模型整体预测精度更高,预测结果离散性更小,具有更高的可信度。
4 结论
建立高速公路路基沉降的精确预测模型,对路基沉降量的研究和公路灾害防控等实际问题具有重要参照意义。在保证同种学习样本数据情况下,PCA-RVM预测模型选取的影响因子更加明确,预测的结果具有较大优势。说明了PCA-RVM预测模型精确度高、离散性更小等优点,为高速公路路基沉降预测提供一条新途径。主要得到以下结论:
(1)高速公路路基沉降受到多种因素影响,路基沉降与影响因素之间存在着错综复杂的非线性关系,本文建立的PCA-RVM预测模型能够准确筛选出相关的主成分并建立路基沉降与4个主成分的非线性映射关系,建立相对应的回归模型,把复杂的问题简单化,利于解决实际问题。
(2)实例表明,PCA-RVM模型在高速公路路基沉降预测得出的结果均优于4种神经网络预测模型。说明了PCA-RVM模型选取影响因素简单准确,具有预测结果精准度高、预测值离散度较小,可信度高等优点。
(3)PCA-RVM模型在实际工程运用中,收集广泛的学习资料样本有利于筛选出贡献率较大的影响因素,总结更完整的非线性映射关系,提高PCA-RVM模型的精度及可靠度;同时,也可以结合高速公路施工现场的实际问题和设计师提出的宝贵意见合理调整参数和影响因素,可以极大改善PCA-RVM模型适用性。
猜你喜欢
建材发展导向(2022年3期)2022-04-19 12:51:50
建材发展导向(2021年6期)2021-06-09 05:57:06
电子制作(2019年19期)2019-11-23 08:42:00
中国公路(2017年14期)2017-09-26 11:51:51
中华建设(2017年1期)2017-06-07 02:56:14
中国交通信息化(2016年9期)2016-06-06 07:42:10
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
小说月刊(2014年4期)2014-04-23 08:52:20
