
基于LKJ 异常数据的复杂关联网络模型研究
2020-02-22 08:36:32王继丽
控制与信息技术 2020年6期
言 圣,杨 献,王继丽
(1.湖南中车时代通信信号有限公司,湖南 长沙 410100;2.中车株洲电力机车研究所有限公司,湖南 株洲 412001)
0 引言
列车运行控制装置(简称“LKJ”)是列车的重要设备之一,其性能的好坏决定了列车运行过程的安全性与稳定性。目前对LKJ 车载设备的故障分析依然是采用人工方法,通过对LKJ 运行记录数据的分析并结合人工现场经验进行判断。这种方法不仅对分析人员经验的依赖程度高,而且人工分析劳动强度大(一次行车所产生的LKJ 记录数据一般有成千上万条),分析时容易出错。为及时发现LKJ 潜在故障隐患,避免LKJ 运行途中出现故障,需要研究LKJ 运行记录数据分析的新方法。
本文基于LKJ 车载设备运行记录数据文件,研究复杂关联网络模型;并利用先进的大数据挖掘技术,建立LKJ 典型故障的复杂关联网络模型。该模型由一定数量的节点和节点的连边共同组成,用来描述LKJ 设备运行过程中事件、数据之间的相互联系,并对不同状态下LKJ 异常数据进行综合分析和分类研究,实现LKJ设备故障诊断的关联分析,以及时发现LKJ 设备异常或故障,并对设备故障进行及时处理,有效保障列车运行的安全与稳定。
1 复杂网络模型及其设计思路
1.1 复杂网络模型简介
复杂网络是将现实世界中各种大型复杂系统抽象成网络来进行研究的一种理论工具,自然界中存在的大量复杂系统都可以通过形形色色的网络加以描述[1]。一个具体的复杂网络可被抽象为一个由点集和边集组成的图,而边集中的每条边都有点集中的一对点与之相对应[2]。
不同的复杂网络所拥有的节点和边是复杂多样的,因此会出现不同类型的网络模型。一般情况下,根据模型图中节点对之间的连边是否具有方向及连接关系的强弱,可以分为有向图和无向图、加权图和无权图[3](图1)。由于本文研究的是变量的关联性,因此采用相关系数来衡量变量与变量之间的关联性;因相关系数是无向的,故本文要建立的故障关联复杂网络模型为无向加权网络模型,见图1(c)。
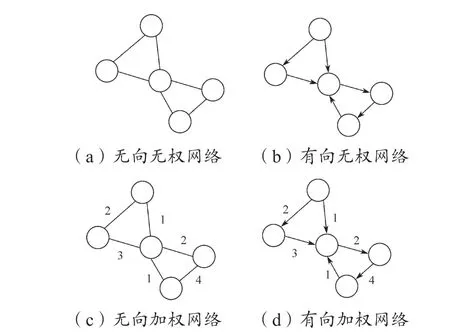
图1 不同类型网络模型 Fig. 1 Different type network models
1.2 模型设计思路
LKJ 运行记录数据是LKJ 列车在运行过程中实时记录的状态数据,包括系统自检和按键信息、机车条件变化信息、运行状态信息、制动试验信息、数据调用信息、GPS 信息以及检修人员/机车乘务员输入信息等内容。这些数据中,LKJ 事件发生时间类数据具有时间序列性;速度、管压、缸压及机车信号等数据中既存在连续变量数据,也包含离散型事件类数据;开机与关机、鸣笛开始与鸣笛结束等时间数据,前后数据之间可能存在关联关系;速度与管压、管压与工况等数据,同一序列数据之间存在关联关系。基于这些数据特点及LKJ 记录的异常数据,本文采用相关分析法,研究LKJ 异常变量之间的关系,借鉴复杂网络模型,构建LKJ 设备故障关联的复杂网络模型;探索LKJ 设备故障的关联性,通过模型关键节点找出关键异常变量,即中心性节点(图2)。
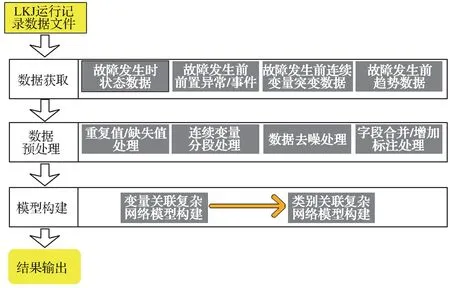
图2 基于LKJ 异常数据的复杂关联网络模型设计流程Fig. 2 Design process of the complex association network model based on LKJ anomaly data
基于LKJ 异常数据的复杂网络模型设计主要包括数据获取、数据预处理及模型构建3 个过程,其中数据获取主要针对已经发生故障的LKJ 运行数据文件处理分析;数据预处理主要是对获取的异常数据进行清洗及规整;模型构建则是实现复杂关联网络模型的构建及应用。
2 数据获取及预处理
2.1 数据获取
数据获取阶段主要获取以下4 种数据:故障发生时状态数据、故障发生前的前置异常事件或事件、故障发生前连续变量突变数据、故障发生前的趋势数据作为复杂网络模型构建的样本数据。
(1)故障发生时状态数据
故障在发生时,常伴随一些故障状态数据,如车型、载重、总重、速度值、缸压值、管压值等。在进行复杂网络模型之前,有针对性地提取潜在故障相关状态数据,以便后续从整体上挖掘故障的共性规律。
(2)故障发生前的前置异常事件/事件
故障在发生前,可能伴随一些关联LKJ 事件。在进行复杂网络模型之前,按照模型分析需求,有针对性地提取故障发生前半小时(可以调整)内所有异常事件或正常事件,便于后续从整体上挖掘故障的共性规律。
(3)故障发生前连续变量突变数据
故障发生前的连续变量突变数据包括LKJ 记录的速度、管压、缸压、转速(电流)、均衡风缸压力等参数在半小时内突变数据。突变计算时,按照数据记录序号,统计数据中相邻记录之间的突变值以及故障发生时状态信息数据,包括故障发生时的文件名、发生时的文件序列号等字段。
(4)故障发生前趋势数据
故障发生前趋势数据分析为探索性的挖掘分析,主要是通过对故障发生前30 min 的数据每隔5 min 切分一次,提取每30 min 内数据的趋势最大值和最小值、斜率最大值和最小值、周期变动因子及随机变动因子,其中趋势衡量数值靠近的取值,斜率代表数值波动的陡峭程度;同时利用关联规则算法,提取共性趋势之间的关联关系(如提取第1 个5 min 内“LKJ 速度”趋势最大值或最小值以及管压趋势最大值和最小值)。
2.2 数据预处理
数据预处理是针对从数据获取环节得到的模型样本数据进行处理,主要包括重复值/缺失值处理、连续变量分段处理、数据去噪处理、字段合并/增加标注处理。
(1)重复值/缺失值处理
在分析过程中,可能存在缺失值的地方,比如记录数据中的线路信息及车站信息的缺失。在不影响整理观测数量的前提下,首先确定缺失值范围,即对每个字段都计算其缺失值比例;然后再按照缺失比例和字段重要性,分别制定策略,以确定是丢弃还是填充处理。
(2)连续变量分段处理
在进行多属性的决策问题研究时,常采用人工神经网络、模糊集、粗糙集、概念格及统计决策分析等算法。为简化处理算法和计算过程,这些算法都会对数据进行一定的假设,比如属性之间相互独立、服从某种分布规律或者要求属性要尽可能少,可实际情况往往不能满足这些假设。对于在实际问题中遇到的连续变量问题,若将其科学、合理地转变成为符合实际数据分布特征的离散量,则可以大大提升模型分析的有效性[4]。
(3)数据去噪处理
在构建复杂网络模型时,由于获取的数据维度过高,若将很少发生的事件或数据维度代入模型,不仅影响分析效果,也会影响相应的分析效率。因此,在数据预处理阶段,对于这些数据维度需要进行一定程度的筛选,如给定一个阈值,在所有观测样本中,对仅有10%或更少出现频率的样本,可考虑将这些数据特征进行删除。
(4)字段合并/增加标注处理
来自不同数据源的数据经处理后,需按照对应的数据字段进行合并,从而形成最终的模型数据源。
3 模型构建及应用
模型构建是针对从数据预处理后的样本数据,其首先采用相关分析法,构建异常变量关联复杂网络,并通过关键节点输出关键异常变量;然后通过变量关联复杂网络模型输出的结果数据,构建类别关联复杂网络模型,最终完成基于LKJ 异常数据的复杂关联网络模型的构建。
3.1 变量关联复杂网络模型构建
采用相关系数[5]来衡量LKJ 变量与变量之间的关联性,建立变量关联复杂网络模型并通过关键节点找出关键LKJ 异常变量。主要实现过程如下:
(1)收集整理拦截的LKJ 运行记录数据,并对数据进行结构化整理;
(2)针对上一步异常拦截后的变量计算各变量的相关系数;
(3)基于变量间相关系数建立变量关联网络;
(4)分析变量关联复杂网络模型关键节点,并优化网络模型。
模型优化即删除相关系数较小的关联,具体则根据更多运行数据进行学习修正。当前删除的是相关系数不大于0 的关联,并将连接边数大于等于5(具体需根据运行数据的增多进行学习调整)的节点作为关键节点输出。
3.2 类别关联复杂网络模型构建
采用典型相关系数(取第一对典型相关系数)来衡量类与类之间的关联性,建立类别间关联复杂网络模型并试图找出关键节点[6]。基于LKJ 异常数据的复杂关联网络模型的构建流程如图3 所示。
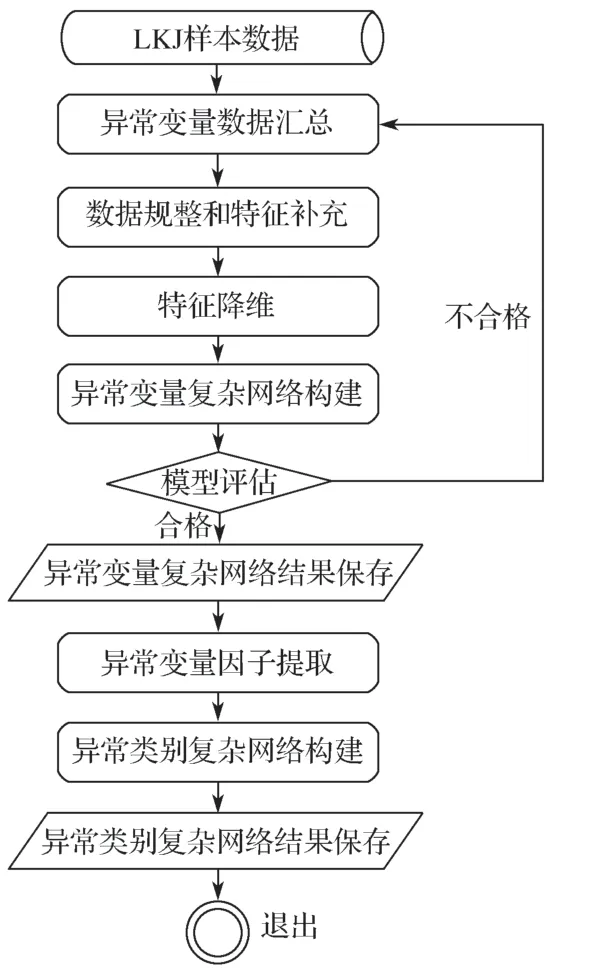
图3 基于LKJ 异常数据的复杂关联网络模型构建流程Fig. 3 Construction process of the complex association network model based on LKJ anomaly data
该复杂关联网络模型主要实现过程如下:
(1)提取异常变量因子
整理分析变量关联复杂网络模型输出的结果数据以提取异常变量因子。首先将原始数据标准化,见式(1),以消除变量间在数量级和量纲上的不同;接着,求解标准化数据的相关矩阵[7]及其特征值和特征向量[8],计算方差贡献率与累积方差贡献率;最后,确定因子。F1,F2, …,Fp为上述计算得出的p个因子,当前m个因子的累积贡献率不低于80%时,可取前m个因子来反映原评价指标。

式中:Xi——原始数据中所有变量集合,下标i代表第i个变量;xi——Xi具体样本的真实值;E(Xi)——Xi所有样本的均值;var(Xi)——Xi所有样本的方差。
(2)对提取的异常变量因子进行分类整理
采用因子分析法,根据样本数据进行分类;后续可根据更多运行数据进行学习,修正分类结果。
(3)计算上一步各类变量的典型相关系数
采用典型相关分析中第一对典型相关系数来衡量类别之间的关联性。典型相关系数分析方法[9]通常用简单相关系数来描述两组变量的相关关系,其只孤立地考虑单个X与单个Y间的相关性,却没有考虑X变量组与Y变量组内部各变量间的相关性。它是研究两组变量之间相关性的一种统计分析方法,也是一种降维技术。
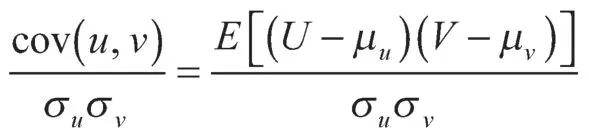
(4)建立模型
基于第3.2 节步骤(3)所述异常类别间的典型相关系数,建立类别关联复杂网络模型。
(5)优化模型
分析类别关联复杂网络模型关键节点并优化网络模型。
3.3 模型应用
模型应用时,对当前的LKJ 运行记录数据文件进行处理分析,获取其中的异常数据并对其进行数据规整、特征补充等处理;变量关联复杂网络模型调用变量关联复杂网络模型构建过程形成的模型参数,对新拦截的异常数据进行识别,获取其关联节点、关联关键节点信息并输出;类别关联复杂网络模型则调用异常类别关联复杂网络模型构建过程中形成的模型参数,对新拦截的异常变量进行异常类别匹配,从而预测LKJ 设备可能发生的异常或故障。随着LKJ 异常样本数据的不断积累,可通过机器学习不断优化模型参数,提高LKJ 设备异常预测的准确度。图4 示出基于LKJ 异常数据的复杂关联网络模型的应用流程。
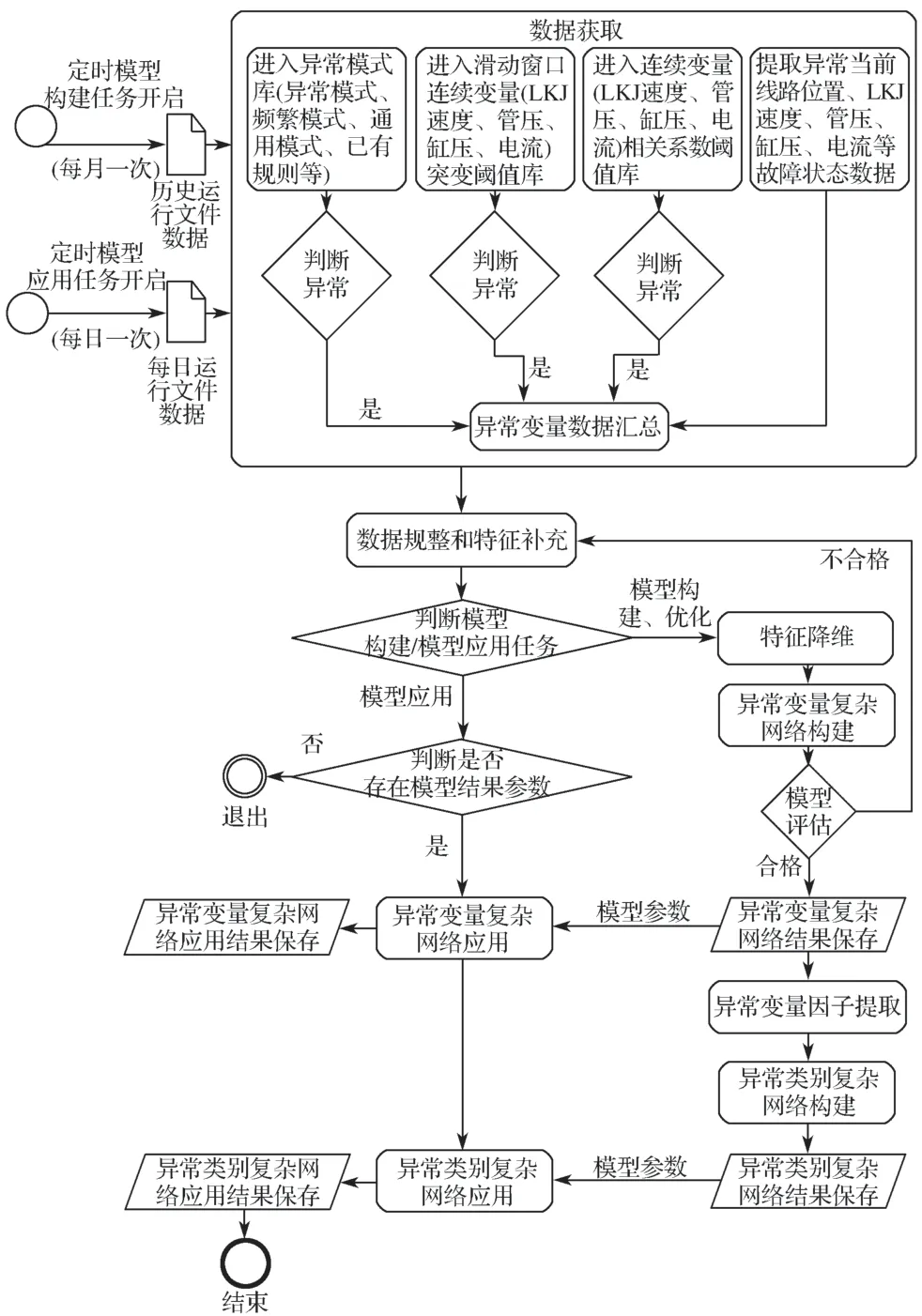
图4 基于LKJ 异常数据的复杂关联网络模型应用流程Fig. 4 Application process of the complex association network model based on LKJ anomaly data
4 模型应用评估分析
为了验证所建模型的有效性,本文以LKJ 典型故障“单机运行”为例对LKJ 运行记录数据进行分析,并对分析结果进行评估。结合LKJ 运行记录数据中“单机运行”发生的状态、发生前30 min 伴随的状态、异常事件等,利用复杂关联网络模型对典型故障规则进行提取,分析结果如图5 所示。
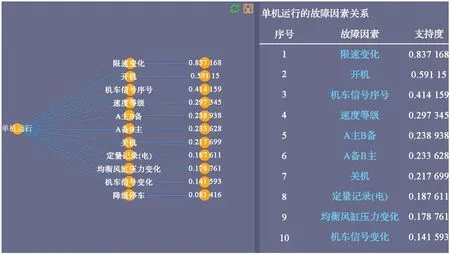
图5 复杂关联网络模型单机运行故障分析结果Fig. 5 Fault analysis results of the complex associated network model
通过复杂关联网络模型提取单机运行故障的关键要素。这些要素说明,当发生单机运行时,其前30 min发生这些要素的可能性大,其可能性的大小可通过后续深入的挖掘工作进行分析。
复杂关联网络模型主要用于挖掘故障发生前存在的潜在影响因素,其不同于监督分类或者预测模型,没有一个严格的坏样本标准来评估模型的好坏,因此其需结合实际情况进行评估。对复杂关联网络模型的评估主要涉及两方面,一是专家评估,这种方法存在一定的主观性,且专家之间的评估方法无法通过数字化的方法进行定量说明;二是机器评估,其借鉴监督类学习方法,假设将所有关键节点作为故障发生的必要条件,识别所有运行文件中发生关键节点个数超过90%的文件并将这些文件预测为单机运行故障,预测后的结果与实际发生单机运行故障的结果进行对比,查看预测的准确度。
这里将单机运行复杂关联网络模型的11 个节点提取出来(表1),查找运行文件中出现9 个以上节点的文件,并标记为“预测发生”单机运行,预测结果如表2 所示。
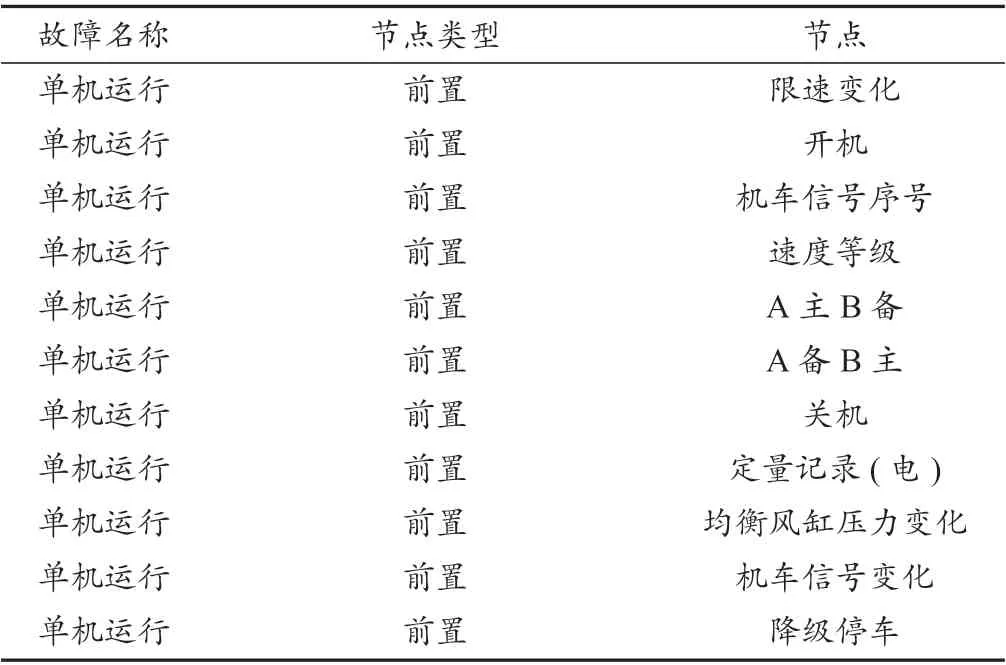
表1 单机运行关键节点Tab. 1 Key nodes of single machine operation

表2 单机运行预测结果表Tab. 2 Forecast results of single machine operation
从误差率(错误分类的样本数与检测样本总数的比值)、准确率(正确分类的样本数与检测样本总数的比值)、灵敏度(正例中被准确预测的比例)、特异性(负例中被准确预测的比例)这4 个指标来看,该模型误差率约为5.2%,说明模型预测情况良好;灵敏度达33.8%,说明覆盖预测到的正例比例小,在预测上还有一定的提升空间,具体原因跟正例的样本数量少有一定的关系。
5 结语
本文基于LKJ 车载设备运行记录数据文件,根据复杂网络模型,建立了基于LKJ 异常数据的复杂关联网络模型,实现了LKJ 故障的关联分析。采用该模型,不仅能对LKJ 设备故障关联信息进行智能挖掘,还能帮助LKJ 设备故障诊断业务专家或维修人员及时对设备进行诊断,减少了维修时间,及时排除设备隐患。其应用可提高LKJ 故障诊断和关联分析的效率和可信度。
目前,受故障样本数据数量的限制,暂时无法进行反复的模型训练;后续,随着故障样本数据的不断补充,我们将采用机器学习、深度学习方法对模型进行反馈修正,进一步提升模型的应用性能。
猜你喜欢
新疆钢铁(2021年1期)2021-10-14 08:45:36
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
当代陕西(2019年15期)2019-09-02 01:52:00
航天工业管理(2019年11期)2019-04-20 07:05:38
学苑创造·A版(2018年11期)2018-02-01 06:29:20
能源(2017年9期)2017-10-18 00:48:22
读者(2017年5期)2017-02-15 18:04:18
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
新高考·高二数学(2014年7期)2014-09-18 00:42:02
