
桥梁健康监测系统中的大数据分析与研究
2020-02-22 03:25:32向阳,杜君
铁路计算机应用 2020年1期
向 阳,杜 君
(中国中铁大桥局集团有限公司 武汉桥梁特种技术有限公司,武汉 430205)
桥梁在建成通车后,随着温度、湿度、风速等自然气候环境的侵害,以及日益增加的交通荷载,会导致桥梁逐渐老化、结构性能不断退化,严重时会引起限载通行、关闭交通甚至倒塌的严重后果,给人们的生命财产安全带来危险。因此,很多的桥梁安装桥梁健康监测系统,桥梁健康监测系统通过安装在桥梁上的温度、挠度、索力、湿度、倾角、应变、位移、振动和风速等传感器实时采集监测数据,将这些数据实时传输至后台服务器,后台专家系统根据相应的阈值对其进行预警及分析评估。其中,振动、索力等采样频率较高,每秒至少采集1次、有的甚至高达上百次。平均一座桥梁上安装100多个传感器进行实时监测,传感器每天采集的数据早就达到GB级别[1-9]。面对桥梁监测传感器网络中的高速监测数据流以及数据库存储的海量大数据,若在单个服务器上实现数据的存储及处理分析,传统的关系型数据库管理系统已经到达极限,并不能有效地存储和分析处理这种级别的大数据,现在需要有效、可靠的大数据分析与处理方法,专门快速采集及海量存储解析这些大量数据。因此,有必要对桥梁健康监测系统中的大数据采集、存储和分析处理做相应的
研究[10-18]。
1 桥梁健康监测系统中的大数据采集
1.1 桥梁监测传感器网络中的高速数据流
数据流的定义:一个由有先后顺序关系且个数随时间不断增加的元组构成的数据集,如式(1):
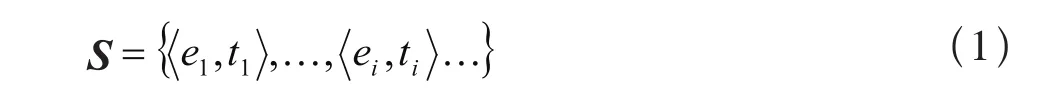
其中,ei是时刻ti出现的序列元素。桥梁健康监测系统传感器网络中传递的传感器监测数据即为数据流,这些数据具有如下特点:
(1)传感器数据流中的数据实时高速传输、转瞬即逝,每个数据只能够被“看”一次;
(2)传感器数据流是无限的、源源不断的;
(3)传感器数据流中的数据规模很大。
1.2 基于时间片的滑动窗口数据流查询
面对桥梁监测传感器网络中海量数据流的数据查询,需要多次不断地采集查询传感器,区别于对传统数据库的单次或者几次查询,属于一种长期不间断实时查询[18]。桥梁监测传感器网络中的海量高速数据流可以采用基于时间片驱动的滑动窗口技术,滑动窗口为计算机缓存,保存的是当前时间周期间隙内的最新数据序列。通过这种方式可以实现对桥梁监测传感器网络中海量数据流的实时查询采集。
时间片驱动的滑动窗口的定义:设S[t–T:t]为t时刻传感器数据流S的滑动窗口,Δt是时间片周期。若是S[t–T:t]于每一个Δt周期的结束时刻产生变化为S[t+Δt–T:t+Δt],则称S[t–T:t]为时间片驱动的滑动窗口。时间片驱动滑动窗口每隔Δt固定的时间间隔更新一次,实际应用中应按照具体情况设置Δt数据的大小,根据理论要求及实践规律,T值应大于时间周期Δt。
1.3 K线图
K线图又称蜡烛图,由股市的开盘价和收盘价以及股市的最高价和最低价这4个数据组成,用于统计分析股价的涨跌趋势,普遍运用于股票证券市场。K线图中的矩形实体有2种,其中,红色实体是阳线,绿色实体为阴线。X轴坐标为时间,Y轴坐标为监测数据,将每天的阳线阴线全部画出即形成K线图。如果实体表示的时间周期内的结束值大于起始值,即监测值增涨,则实体为红色阳线,相反则为绿色阴线。如果起始值与结束值大小相同,则为十字线。最高值和实体之间的线被称为上影线,最低值和实体间的线称为下影线。根据时间周期大小的不同,绘制小时K线图、日K线图和月K线图等[19]。
面对桥梁监测中实时采集数据流的查询统计,例如,查询时传感器监测的数据超出给定的阈值,则发出警报;统计某段时间内,监测数据的最大值、最小值等。只需要长期保存监测参数在每一个时间周期中的4个数据:起始值、最高值、最低值和结束值,如图1所示,摒弃了周期中无需长期保留数量庞大的中间值,只保留了4个关键数据,具有数据存储量小的特点,是监测系统中处理海量数据流的一种好方法。同时,用K线图描述监测参数的方法,能实时形象地反映出监测数据的波动状况。
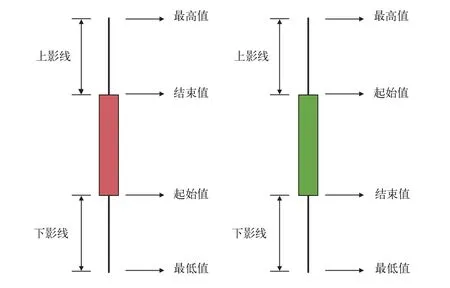
图1 传感器网络中的大数据采集K线图
1.4 基于K线图时间片驱动的滑动窗口数据流处理模型
图2描述了一个基于K线图时间片驱动的滑动窗口数据流查询处理模型,用于实现桥梁健康监测中的大数据采集。其具体工作原理流程:传感器采集的数据流,通过数据缓冲区并添加到时间片滑动窗口,不断查询窗口计算结果,自动预警。流查询处理器读取采集每个时间片滑动窗口数据流的K线图关键数据(起始值,最高值,最低值,结束值)并上传云端存入到海量存储设备,滑动窗口根据实际情况设置时间片周期,当到达固定时间片周期时,更新当前K线图概要数据,同时抛弃前一个周期的数据,并将最新的数据进行上传保存。
本文提出的这种基于K线图时间片驱动的滑动窗口数据流处理模型,是将基于时间片的滑动窗口数据流查询与K线图相结合,不仅实现了对桥梁监测传感器网络中的海量数据流的实时快速采集,而且还通过K线图较少的数据个数,快速、形象地反应了桥梁数据流的变化趋势及波动状况。
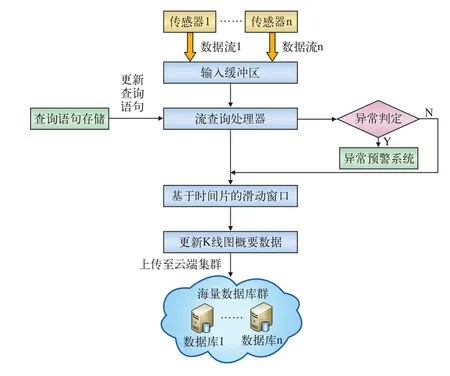
图2 基于K线图时间片驱动的滑动窗口数据流处理模型
2 桥梁健康监测系统中的大数据存储
2.1 桥梁健康监测中的海量数据
桥梁健康监测系统是对桥梁外部环境及结构内力状态进行实时监测采集,如环境温湿度、应变、振动和索力等。其中,温湿度属于外部环境,变化周期较长,测量周期可以是小时级别,因此数据量较小。但某些结构内力如振动、索力等属于变化周期较短的参数,采集频率平均可以达到50 Hz,并要求每天24 h不间断工作,才能实时反应桥梁的内力状况。以某单个桥为例,其振动及索力监测点总共达到100个,每个监测点数据采集频率为50次/s,精确度为16 bit,一天的纯数据将近1 GB。同时,随着监测的桥梁数目的增多,以及对监测数据长年的累积存储,桥梁监测数据库的存储量将会超过TB,甚至达到PB级别。
传统的单台服务器存储方式已经不能满足桥梁监测日益增长的数据量储存需求。本文采用HDFS分布式存储模型,解决海量数据存储问题。
2.2 HDFS分布式存储模型
HDFS(Hadoop Distributed File System)是一种Hadoop大数据框架下的分布式文件系统,主要用于大数据的分布式存储。HDFS实际上是由数百个甚至数千个廉价小型服务器组成的集群,通过众多服务器一起实现数据的分布存储,每个数据文件都至少有1个冗余备份,也就是每个数据文件都将至少被存储2次,如果存数据的某个服务器发生了故障,至少还有1个备份数据,所以,HDFS具有高容错性。这比单独使用一台大型服务器在遇到故障时的成本付出要少得多,现在,如果某个服务器发生故障,只需要付出一台廉价服务器的成本。
HDFS分布式存储模型,如图3所示。
(1)NameNode是一台中心服务器,在整个集群系统中有且仅有一台,是唯一用于管理所有的DataNode数据节点的服务器。
(2)每个DataNode节点为一台数据存储服务器,用于存储数据文件以及相应的冗余备份副本,并对数据进行一些读写操作。
(3)NameNode节点周期性地实时查询每个DataNode节点的状态,掌握每个数据块存储的服务器节点的位置等相关信息,并能知道节点是否需要维护。
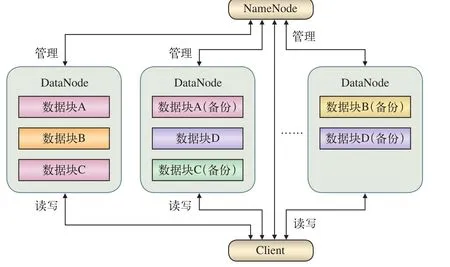
图3 HDFS分布式存储模型图
HDFS分布式存储模型工作原理:用户机Client通过向NameNode发送数据读写请求,NameNode返回数据块存储的DataNode节点位置,Client节点与DataNode节点进行相应的读写操作。在整个HDFS集群系统中,NameNode起到核心管理作用。
通过HDFS分布式存储模型,利用服务器集群分布式存储的方式有效解决了桥梁健康监测中的海量数据存储问题。
3 桥梁健康监测系统中的大数据分析处理
3.1 Map/Reduce模型
Map/Reduce模型是一种用于大数据计算处理的软件模型框架,其关键技术是“Map(映射)和Reduce(规约)”。将海量数据分割成多个独立的输入数据块给M台服务器进行并行处理;每台服务器通过Map映射函数计算处理自己那部分输入数据块,并生成计算结果;R台服务器通过Reduce规约函数将所有的计算结果进行规约汇总、分析计算,得到最终的处理结果。桥梁健康监测系统中的海量大数据可采用Map/Reduce模型,将海量数据分布在服务器集群中,通过服务器集群进行同时分析处理,相比传统的单台服务器分析处理运算,将会大幅缩短运算时间,提高计算效率。
3.2 斜拉索索力测量计算方法
由于桥梁斜拉索的锈蚀断丝等病害容易致使斜拉索索力及其相应的结构内力状态产生改变,甚至有可能导致桥梁倒塌,因此,需要对桥梁斜拉索的索力进行实时监测。
在每根索的中央断面处安装加速度传感器,传感器输出的数据经快速傅立叶变换计算处理后可得到每根索的主频率。索力可根据公式(2)计算[20-23]:

式(2)中:T为索力;f为拉索的一阶频率;L为索长;W为单位长度索重;g为重力加速度。
3.3 基于Map/Reduce的索力分布式并行处理模型
通过基于Map/Reduce的索力分布式并行处理模型可以实现对索力历史大数据的统计分析处理功能。例如,统计10年内索力超过指定阈值的次数:(1)通过Map/Reduce中的Map,将桥梁监测的历史索力数据输入文件分割成M份,把任务分解成M个子任务,通过服务器集群并行运算分析,提高系统的运算速度,减少分析时间;(2)通过Reduce把M个子任务计算的结果汇总统计,得到最终结果。其中,索力输入文件格式,如表1所示。
基于Map/Reduce的索力分布式并行处理模型的具体工作流程,如图4所示。Master节点服务器为整个模型框架的主节点服务器,负责整个系统的运行、管理、分配以及调度,为空闲的worker节点服务器分配Map作业以及Reduce作业。Master主服务器将海量数据分割成M份数据块,并将其分配给空闲的worker服务器集群,服务器集群并行读取对应分割的索力数据块文件,服务器每读取一条记录时,一旦超过阈值,就生成一条索力中间键值对<key,value>,其中,key为索力编号,value表示超过阈值的次数。Master将记录的索力中间键值对的位置转发给执行Reduce作业的R个worker服务器节点。执行Reduce规约作业的worker服务器最后读取所有的索力中间键值对,通过服务器集群并行统计,计算出最终结果。当所有的Map和Reduce作业都完成了,Master服务器将Reduce结果返回给用户程序。
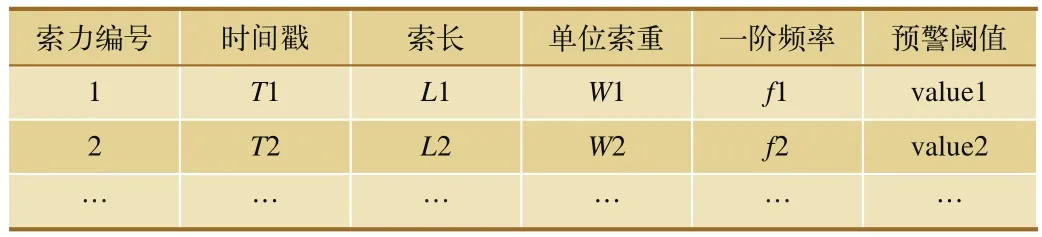
表1 索力数据文件格式
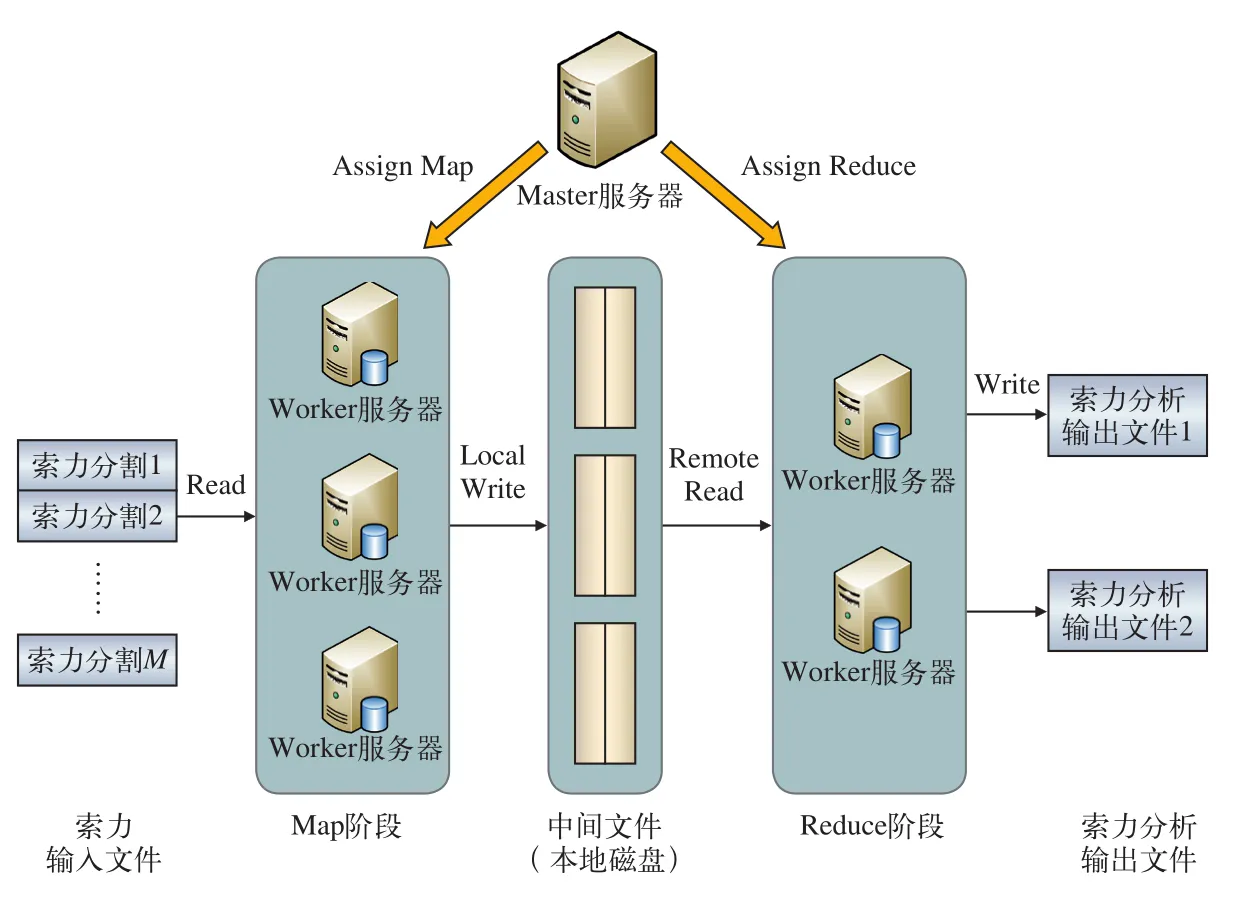
图4 基于Map/Reduce的索力分布式并行处理工作流程
4 实验结果分析验证
4.1 K线图时间片驱动模型的数据存储量分析验证
设监测传感器的数量为n个,采集频率为f,每天存储的数据量为S,存储一天监测数据的数据量为:

若采用基于K线图时间片驱动的滑动窗口数据流查询处理模型,使用k秒钟K线图,每k秒存储起始值、最高值、最低值、结束值这4个数据,那么存储一天监测数据的数据量为:

式(3)与式(4)中S值的大小取决于在实际的桥梁实时健康监测中,索力、振动等采集频率一般是20 Hz~100 Hz左右,采用4 s K线图基本可以满足桥梁监测的需求,使用本模型,实际存储的数据量至少可以减少20倍。
4.2 Map/Reduce索力分布式并行处理模型性能测试实验
实验采用4台服务器组建计算集群,每台服务器配置相同,CPU:Intel双核1.80 GHz,内存:8 GB。利用Hadoop大数据框架中的Map/Reduce模型,验证基于Map/Reduce的索力分布式并行处理模型,其中,一台服务器作为Master管理节点,其余3台服务器作为worker计算节点。针对不同大小的索力文件,分别采用传统的单机计算模式与本文的Map/Reduce并行模型进行处理,利用专家分析评估系统,统计索力超过某一阈值的次数,将系统的运算执行时间进行比较,实验结果,如图5所示。
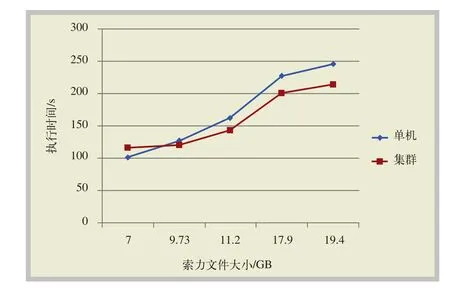
图5 单机系统与Map/Reduce集群系统执行时间对比
从以上仿真结果可以看出,运行Hadoop平台需要一定的时间开销,因此当数据量较小时,集群并行计算的运行时间反而大于单台服务器执行的时间。但随着数据量的增大,Map/Reduce集群将索力数据文件分派给多个worker节点进行并行处理,其运算总时间小于单台服务器的执行时间,随着索力文件大小的不断增加,两者的总时间差距也越来越大。
5 结束语
本文在桥梁健康监测的大数据采集、存储及分析处理3个方面,提出一种基于K线图时间片驱动的滑动窗口数据流处理模型,该模型实现桥梁实时监测传感器网络大数据的高速采集,通过K线图模型,不仅形象地反应监测数据的状况波动,而且减少了数据采集量,优化了云端海量存储。将HDFS分布式存储模型应用到桥梁健康监测中,解决了健康监测中海量数据的存储问题。提出基于Map/Reduce的索力分布式并行处理模型,并将该模型应用于索力大数据分析计算处理,通过搭建基于该模型的分布式计算集群,实现专家系统对索力历史海量数据的分析评估,减少系统分析时间,提高评估效率。
本文分别对桥梁实时健康监测的大数据采集,大数据存储,大数据分析3个部分进行了分析与研究,但对于大数据预测还有待进一步的挖掘和分析。
猜你喜欢
现代临床医学(2023年4期)2023-09-26 09:40:38
能源研究与利用(2022年1期)2022-03-03 07:43:08
汽车维修与保养(2020年11期)2020-06-09 05:42:22
供水技术(2020年6期)2020-03-17 08:18:36
电脑与电信(2018年12期)2018-03-23 02:37:36
东北史地(学问)(2016年6期)2016-12-14 02:03:20
西北工业大学学报(2015年3期)2015-12-14 13:08:48
西安建筑科技大学学报(自然科学版)(2014年1期)2014-11-12 13:03:36
中国卫生(2014年7期)2014-11-10 02:32:54
振动、测试与诊断(2014年5期)2014-03-01 01:14:42
