
引入时间效应的SVD++线性回归推荐算法
2020-02-19 15:16:14章静芳李小妹
计算机工程 2020年2期
苏 庆,章静芳,李小妹
(广东工业大学 计算机学院,广州 510006)
0 概述
随着互联网技术的飞速发展,各类信息容量剧增导致严重的“信息过载”问题[1],一方面用户从海量数据中获取感兴趣的信息变得越来越困难,另一方面服务方难以从海量数据中抽象出个性化的用户需求。推荐系统作为一种信息过滤系统,能有效解决上述问题。在推荐系统中广泛使用的是基于协同过滤(Collaborative Filtering,CF)[2]的推荐算法。该类算法基于用户对商品的评分或其他行为模式为用户提供个性化的推荐。目前协同过滤采用的主要技术包括基于邻域的方法[3]和隐语义模型,其中,基于矩阵分解的隐语义模型[4]具有较好的预测稳定性以及精确度。
文献[5]利用奇异值分解(Singular Value Decomposition,SVD)进行矩阵分解,其主要缺点在于一开始就需要补全评分矩阵的缺失值,即将一个稀疏矩阵转化为一个稠密矩阵后再进行分解。然而对高维稠密矩阵进行SVD分解的时间复杂度和空间复杂度都非常高。因此,文献[6-7]分别提出基于正则化的矩阵分解(Regularized SVD,RSVD)模型和非对称矩阵分解模型(Asymmetric SVD,ASVD),通过充分的正则化来避免过拟合,且取得了较好的预测准确性。文献[8]提出基于信任的正则化分解模型TrustSVD,将社会信任关系融入到推荐模型中,有效提高了模型预测结果的准确度。文献[9]提出一种联合正则化的矩阵分解(Co-Regularized Matrix Factorization,CRMF)推荐模型,将关联关系与社会关系相融合,有效缓解用户的冷启动问题。SVD++模型[7]在RSVD模型基础上融合隐式反馈信息使得预测的准确度进一步提高。
上述算法模型忽略了一个重要影响因素:用户的偏好和物品的流行度都可能会随着时间变化而改变。文献[10]提出一个基于时间依赖模型的推荐系统,将时间因子引入到协同过滤算法中,有效提高了推荐系统的预测准确度。但是,在该模型引入的时间因子中,物品偏置只与物品相关,用户偏置只与用户相关,导致推荐结果稳定性较差。
本文提出一种引入时间效应的SVD++线性回归推荐算法timeSVD++LR,在SVD++模型的基础上引入时间效应属性,通过对时间效应建模进一步提高预测结果的准确度,同时根据初始预测评分构造特征向量Xk,将原始训练数据作为线性回归模型[11]的输入,使用梯度下降算法[12]优化最终代价函数,生成一组参数θ=(θ0,θ1,…,θn)T使得代价函数值最小,并利用预测函数模型hθ(Xk)=θTXk求得测试集上的预测评分,从整体上提高用户预测评分的准确性。
1 SVD++模型
SVD++模型在RSVD模型基础上融合隐式反馈信息,使得预测的准确度进一步提高。SVD++模型的核心思想是通过隐含特征关系联系用户兴趣和项目,将用户和项目两方面的信息融合隐式反馈信息映射到一个因子维度[13]为f的联合隐语义空间,用户-项目之间的交互作用被建模为该空间中的内积。

(1)
(2)
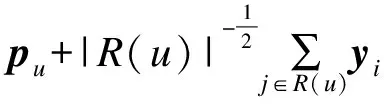
2 线性回归模型
线性回归是按照给定的特征,对其和实际值之间的组合关系进行分析,并通过线性组合的方式来拟合真实值。对于每一条评分记录(样本k),预测评分函数模型如式(3)所示。
(3)
其中,n表示特征个数,x(k)表示样本k的特征向量。最终代价函数如式(4)所示。
(4)
其中,J(θ0,θ1,…,θn)表示误差平方和,y(k)表示真实值,m表示训练集的评论数总和(样本数)。代价函数用于计算参数θ=(θ0,θ1,…,θn)T。利用梯度下降法优化代价函数J(θ0,θ1,…,θn)并求解最小值,对θ进行求偏导操作,解出求导部分如式(5)所示。
(5)

3 timeSVD++LR推荐算法
3.1 算法原理
SVD++模型适用于对时间因子建模。通过将评分分解为各个不同项,分别对应于不同方面的时序影响,定义随时间变化的偏置因子[14]:用户偏置bu(t)和物品偏置bi(t)。用户偏置bu(t)体现为随着时间的变化,用户可能会改变他们的基准评分,例如某位过去倾向于对电影评分为3星的用户可能现在给出的评分为4星;物品偏置bi(t)体现为物品的流行度或许随时间变化,例如在最新一部电影里某位演员的出现或许会导致该电影的流行或过时。在第tui天,用户u对物品i的评分如式(6)所示。
bui=μ+bu(tui)+bi(tui)
(6)
其中,bu(tui)和bi(tui)是随时间变化的实数函数,分别代表用户偏置bu(t)和物品偏置bi(t)。
bi(t)=(bi+bi·Sng(t))wu(tui)
(7)
(8)

(9)
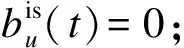
wu(tui)表示物品偏置与时间相关的扩展特征,zi(tui)表示用户偏置与时间相关的扩展特征,增加参数zi(tui)和wu(tui)以改善由于引入时间因子带来的预测结果欠缺稳定性的问题。
wu(tui)=wu+wu,t,zi(tui)=zi+zi,t
(10)
其中wu和zi是稳定部分,wu,t和zi,t代表特定天的变化。
物品偏置bi(t)和用户偏置bu(t)可被分为一个固定部分和一个随时间变化的部分。通过使用随机梯度下降算法来最小化数据集上相关的平方误差函数来完成学习过程,在SVD++算法中引入时间效应属性构造推荐模型,用户u对物品i的初始预测评分用式(11)表示。
(11)
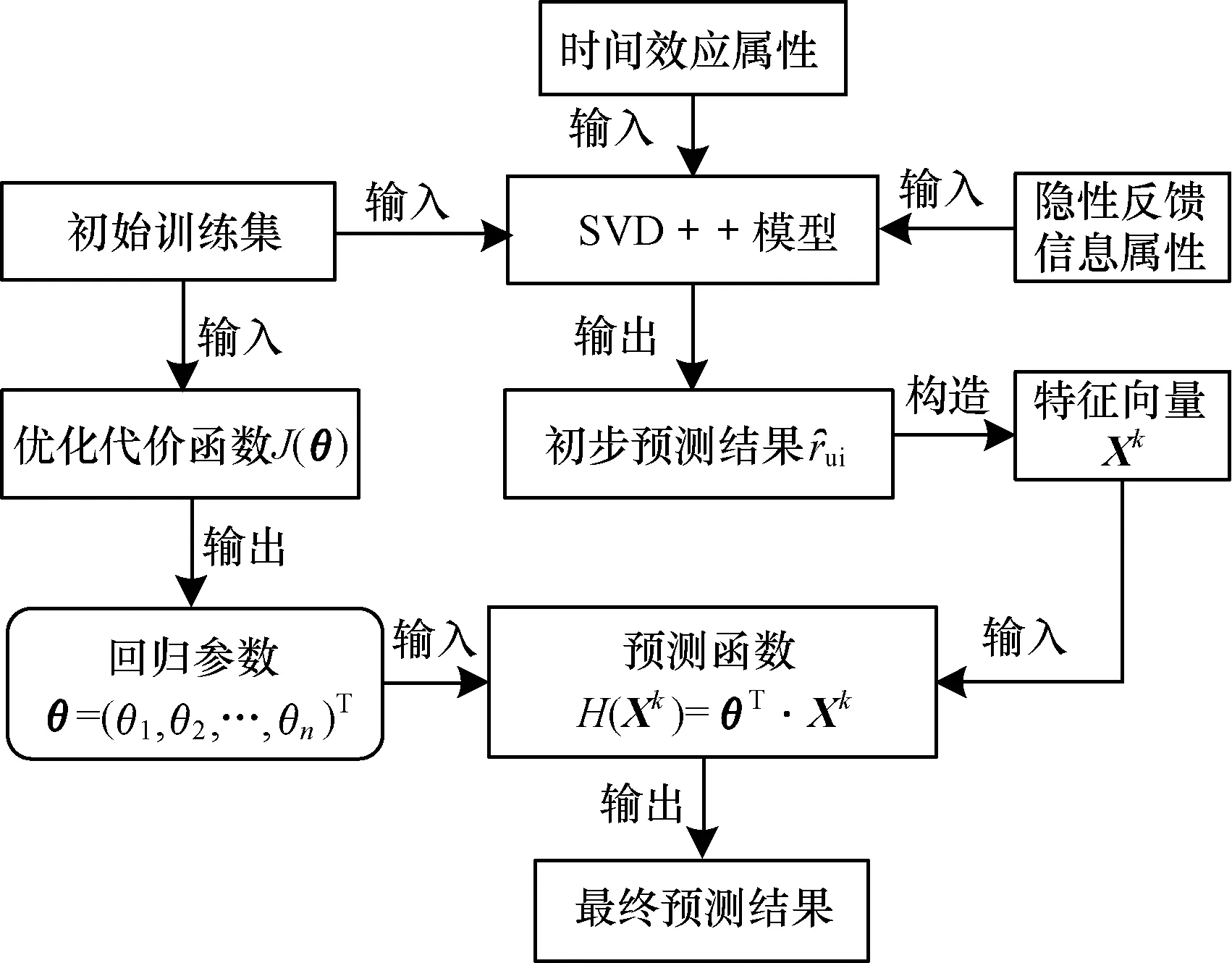
图1 timeSVD++LR推荐算法流程
3.2 算法构建
timeSVD++LR算法的构造步骤如下:

步骤1计算项目偏置项bi和用户偏置bu。
(12)
(13)
其中,R(i)表示评分了的物品i的所有用户列表,R(u)表示用户u给予评分的所有物品列表,λ2=25,λ3=10,全局平均数μ表示训练集的平均评分。
(14)
步骤3在矩阵因子分解方法中分别对项目偏置bi和用户偏置bu均加上时间效应属性,如式(7)和式(8)所示,用户u对物品i的初始预测评分如式(15)所示。
(15)
为了学习模型中的参数bi(t)、bu(t)、pu、qi,需要最小化相关联的正则化平方误差函数,如式(16)和式(17)所示。
(16)
(17)
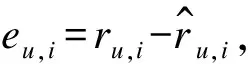
bu(t)←bu(t)+γ·(eu,i-λ5·bu(t))
(18)
bi(t)←bi(t)+γ·(eu,i-λ5·bi(t))
(19)
(20)
(21)
通过为每类待学习参数选择学习率γ和正则化因子λ来提高预测准确度,本文设置γ=0.02,λ6=0.015,λ5=0.005。

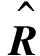
hθ(X)=θTX=θ0x0+θ1x1+…+θnxn
(22)
(23)
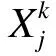
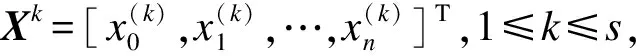
timeSVD++LR算法构造部分用到多个常量值,针对SVD++算法,当λ2=25,λ3=10,λ4=0.02,λ5=0.005,λ6=0.015时[15],推荐算法的预测效果最好,考虑到本文提出的算法与SVD++算法的相关性,故选取相同的正则化参数值,并且当学习率γ=0.02时,在MovieLens数据集上进行测试预测结果最稳定。
4 实验与结果分析
4.1 实验设置
为测试timeSVD++LR算法的准确性,本文将其与RSVD、SVD++、timeSVD++算法进行比较。实验采用MovieLens数据集[16]中的MovieLens_100k数据集,包含943名用户对1 682部电影的约100 000条评分信息(评分密度约为6.3%),记为MovieLens_LR数据集。文献[17]对推荐系统领域内的各种不同的评价标准做了总结,本文将采用检验推荐算法最常用的平均绝对误差(Mean Absolute Deviation,MAE)、均方根误差(Root Mean Square Error,RMSE)作为评价指标[18]。
(24)
(25)
其中,Xi表示timeSVD++LR算法对项目的最终预测评分,Yi表示用户的实际评分,N表示项目的数量。MAE和RMSE的值越小,表示算法性能越好。
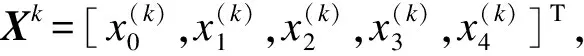
(26)
(27)
(28)
(29)
其中,μ为全局平均数,σ1=0.000 05、σ2=-0.000 05为调节因子,其作用主要是为稳定特征向量值的变化,对整体特征向量值影响不大。
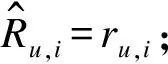
4.2 结果分析
实验1在MovieLens_LR数据集上测试不同最大迭代次数下算法的表现。为减弱学习率γ和因子维度f带来的影响,令γ=0.002,f=20。在设置的最大迭代次数内,将损失函数J(θ)所能达到的最小值对应的一组θ=(θ0,θ1,θ2,θ3,θ4)T值作为预测函数hθ(Xk)的参数,求出最终的预测分数。实验1的结果如图2和表1所示。在表1中,加粗数据为各算法的最优MAE/RMSE值。从图2可以看出,timeSVD++LR算法的MAE、RMSE值均较其他3种算法小,其MAE值在0.68附近波动,RMSE值保持在0.86左右。timeSVD++算法仅在SVD++算法基础上引入时间效应属性,未进行线性回归操作,故其MAE和RMSE值较为不稳定,但最大迭代次数小于70左右时,相较于RSVD和SVD++算法,其MAE和RMSE值均相对较小,说明在timeSVD++中引入时间效应属性在能有效提高推荐算法的预测精度。TimeSVD++LR在TimeSVD++基础上又引入线性回归操作,还能进一步提高推荐算法稳定性。特别地,当最大迭代次数为80时,timeSVD++LR算法模型的MAE值最小,约为0.673 6;当最大迭代次数为50时,timeSVD++LR算法模型的RMSE值最小,约为0.857 2。
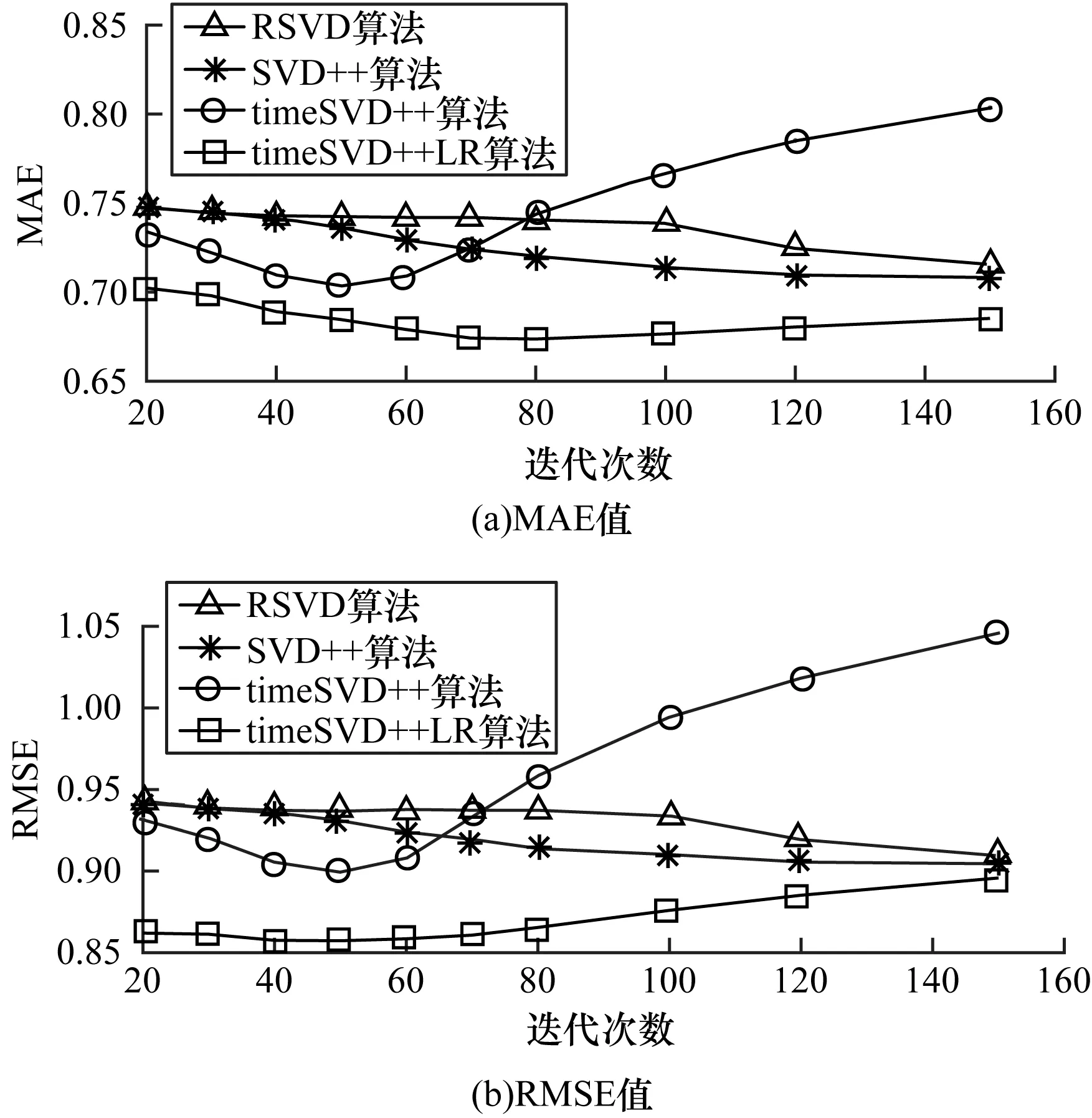
图2 不同迭代次数下各算法MAE、RMSE值的比较
Fig.2 Comparison of MAE and RMSE values of different algorithms under different iterations
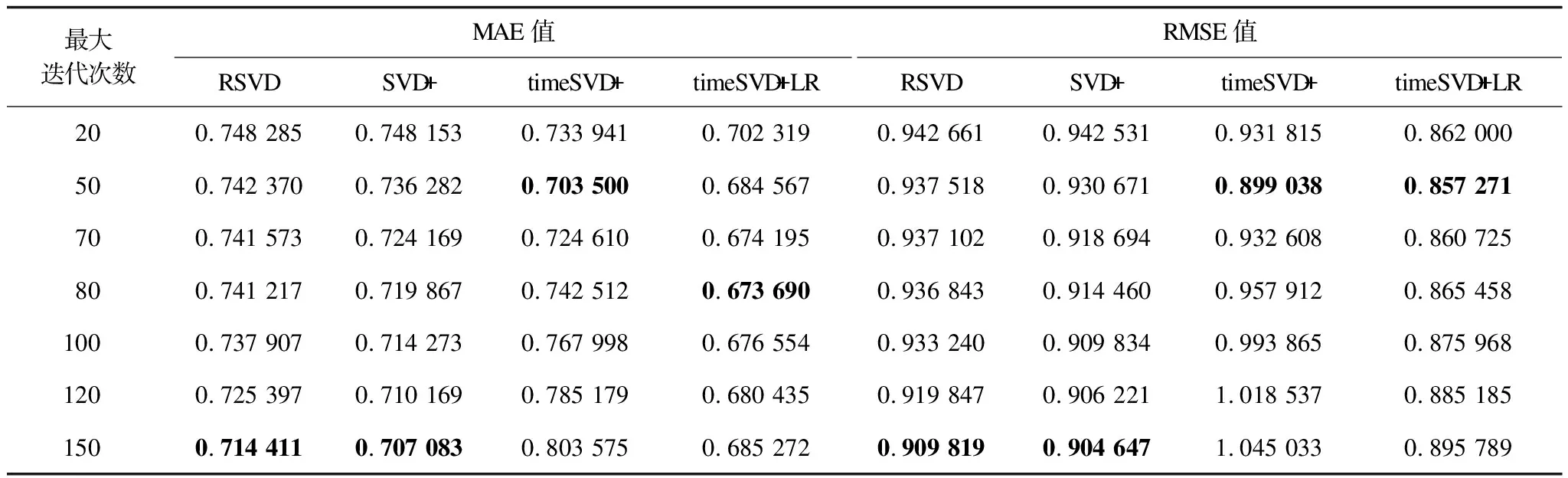
表1 不同最大迭代次数下各算法MAE、RMSE值的比较结果
实验2在同一数据集上测试不同因子维度f下算法的表现。4种算法模型的学习率均取γ=0.002。从表1可知,RSVD、SVD++、timeSVD++和timeSVD++LR算法最佳最大迭代次数依次为150、150、50和80,故在实验2中设置最大迭代次数为最佳迭代次数,结果如图3和表2所示。在表2中,加粗数据为各算法的最优MAE/RMSE值。从图3可看出,在一定范围内随着因子维度的增大,4种算法的MAE和RMSE值均逐渐减小。这说明在一定范围内因子维度的增大可提高算法的预测准确度。从表2可看出,当因子维度为200时,timeSVD++LR算法的RMSE值最小,约为0.858 3,此时 MAE值约为0.669 1,其结果均小于其他3种算法的最小RMSE和最小MAE值。

图3 不同因子维度下各算法MAE、RMSE值的比较
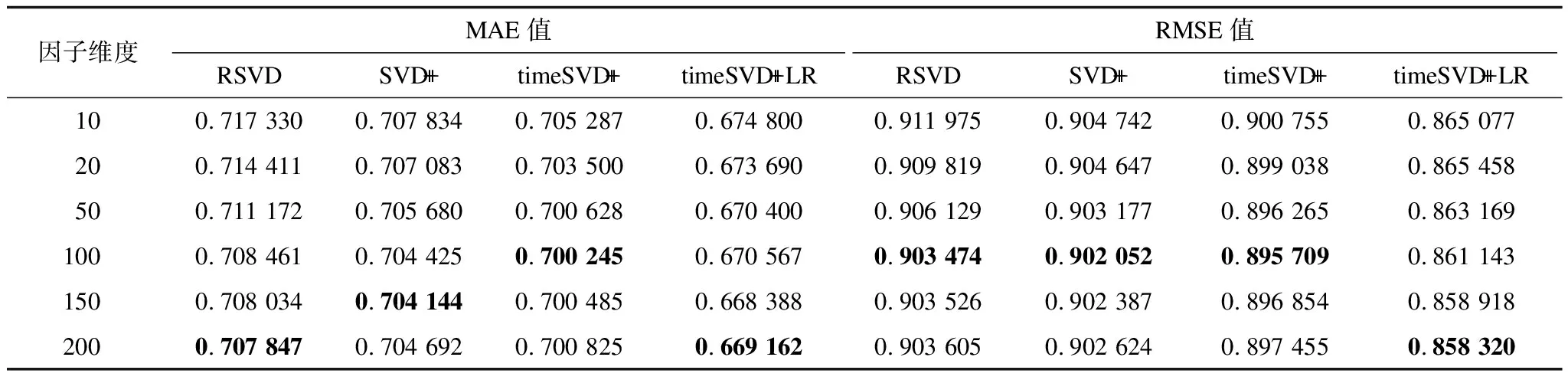
表2 不同因子维度下各算法MAE、RMSE值的比较结果
通过2组实验对比可知,在4种算法中,timeSVD++LR算法的稳定性和预测精度较好。
5 结束语
本文提出一种引入时间效应的推荐算法timeSVD++LR。在SVD++模型基础上引入时间效应属性,根据预测评分构造特征向量。将原始训练数据作为线性回归模型的输入,采用随机梯度下降算法优化代价函数,使得代价函数值最小,生成回归参数,并根据特征向量和回归参数求得预测评分。实验结果表明,timeSVD++LR算法的推荐准确性较RSVD、SVD++、timeSVD++算法有显著提高且推荐结果较为稳定,同时还能较好地改善评分矩阵稀疏和扩展性弱等问题。下一步将在本文算法的基础上研究其他分类算法对推荐系统的影响。
猜你喜欢
汽车实用技术(2022年15期)2022-08-19 02:48:32
中国信息化(2022年5期)2022-06-13 11:12:49
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
北京航空航天大学学报(2016年6期)2016-11-16 01:50:49
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
