
受限资源下制导武器末制导机器视觉技术研究
2020-02-18 05:23赵晓冬张洵颖程雪梅
导航定位与授时 2020年1期
赵晓冬,车 军,张洵颖,程雪梅
(1.西北工业大学无人系统技术研究院,西安 710072;2.航空工业西安飞行自动控制研究所,西安 710076;3.西北工业大学365研究所,西安 710072)
0 引言
在现代战争当中,精确制导武器的成功研制,促使定点攻击作战技术迈上新的台阶。光学制导技术作为精确制导的重要组成部分,是决定其作战性能的重要因素。光学制导包括可见光电视、红外、激光、光纤及复合制导等,其中可见光电视、红外和复合制导都属于图像处理与机器视觉的范畴。可见光电视制导由弹上成像系统负责完成目标的探测与识别,较为成熟的包括“GBU-15”制导炸弹、“KAB-1500KR”以及“AGM-144”反坦克弹等制导武器。红外制导利用热成像探测原理,实现目标的检测与识别,较为成熟的包括“萨姆-7”、“红缨-5”和美国“战斧”巡航导弹BlockIV等。复合制导采用多模式复合方式,取长补短,具有代表性的有美国的RAM航空弹和AARGM导弹,分别采用雷达与红外复合、微波与红外复合的制导方式。
在精确制导武器末制导过程中,国内军事上人工智能算法依旧处于无法落地的阶段。美国洛克希德·马丁公司的远程反舰导弹LRASM,已经成功完成了多次靶试任务。LRASM基于一款较为成熟的空间导弹进行研制,旨在依靠自身人工智能处理器,在舰队中检测并摧毁特定军事目标。该型导弹于2017年12月成功击中海上移动目标,标志着其技术已完全成熟,达到列装标准。同年2月,俄罗斯武器制造商与国防官员宣布开发内置人工智能的新一代武器,该类智能武器可自主选择目标。2019年6月,以色列拉斐尔公司已成功将人工智能集成到Spice炸弹中,在实现目标自主识别的基础上,加入了人工智能及场景匹配技术。凭借人工智能和深度学习技术,该武器可以识别移动的地面目标,并成功将其与其他物体及地形进行区分。
针对末制导视觉处理方面的经典算法研究成果较多,包括差分图像法[1]、光流场算法[2]、统计模型算法[3]、小波变换算法[4]等。差分法是指利用多帧图像计算出差分图像,并将其对应像素进行相乘,用以消除伪运动图像信息;光流场算法利用基于特征信息的光流场进行运动目标检测,同时利用图像分割获得目标的完整轮廓形状;统计模型首先对运动场进行粗略估计,并根据马尔可夫场理论,构造间断点,实现目标检测;小波变换利用在多尺度上计算由方向、尺度等参数构成的向量来实现目标检测。其中,差分图像法与光流法在工程实现当中应用较多。在信息化作战方面,智能化电子战的概念不断涌现。利用人工智能感知技术获取战场信息,并将信息应用到精确制导武器末制导阶段当中,是一种全新概念的作战方式。从算法理论到工程应用的鸿沟,直接影响武器装备智能化的升级程度。智能化技术的逐步发展,为制导武器的智能升级带来了新的技术突破口。智能化技术将显著提升信息化系统的作战能力,若能有效突破精确制导系统的智能化技术应用瓶颈,将使现有的制导系统可以更好地适应复杂战场环境以及激烈对抗条件下的多类别目标精确打击需求。
基于深度学习的军事目标检测识别技术可以有效、自动、快速地识别战场目标,是作战双方利用智能技术理解战场态势的基础。智能技术在军事应用当中需要具备三大核心要素,包括深度学习算法设计、高性能智能计算平台以及大规模的数据训练集。首先建立深层次的神经网络模型;其次在规模庞大的数据集上进行预训练,并在战场数据集上进行模型的再次训练与微调;最终以实时处理模式在高性能计算平台上实现网络的实时推理计算,对多类型目标进行实时计算识别。
目前,基于卷积神经网络(Convolutional Neural Networks, CNN)的自主目标检测识别算法大致分为两类。一是基于区域建议的算法,包括区域建议卷积神经网络[5](Region-CNN,R-CNN)、Fast R-CNN[6]、Faster R-CNN[7]和区域建议全卷积神经网络[8](Region-based Fully Convolution Network,R-FCN),这类算法将目标识别与目标定位划分成2个步骤,分别完成,错误率低,但识别速度较慢;二是基于回归的算法,包括只看一次(You Only Look Once,YOLO)算法[9]、YOLO9000算法[10]、单点多盒探测(Single Shot MultiBox Detector,SSD)算法[11]、去卷积单点探测(Deconvolu-tional Single Shot Detector,DSSD)算法[12]、YOLOv2算法和YOLOv3算法[13]等,该类算法直接产生目标类别概率和坐标,符合实时性要求,准确率也基本可以达到区域建议算法的准确率级别,可以在确保精度的同时,获得更高的时间效率。R-CNN算法开创了深度学习自主目标识别的先河,Faster R-CNN在R-CNN的基础上,直接提取候选区域特征图,并融入区域建议网络(Region Proposal Network,RPN),实现整个识别过程的网络统一,从而实现端到端之间的映射,大幅提升算法速度。在YOLO系列算法当中,YOLOv3算法采用Darknet53的基础网络结构,在检测速度与精度两方面均获得了优于SSD系列算法的检测结果。目前,科研人员对于YOLOv3算法的落地应用拥有极高的研究热情。
由于智能算法复杂度较高,所以智能算法对于计算需求有着较高要求,这与嵌入式受限资源条件下的应用存在显著的矛盾,基于神经网络压缩的算法[14-15]应运而生。网络压缩算法将原本复杂度较高、参数冗余较多的网络,基于最优理论,在网络精度损失较小的情况下,压缩为复杂度较低、参数规模较小的网络结构,使其更加适应于资源受限条件下的硬件推理。目前,基于网络压缩的算法大致分为基于剪枝思想[16-17]的、基于张量分解思想的、基于权值共享思想的、基于权重量化思想[18-20]的、基于低比特或二值化思想[21-24]的压缩算法等。总而言之,网络压缩通过优化思想,减少网络参数,降低对硬件的资源需求,在对网络性能影响较小的情况下,实现智能算法在硬件端的实时推理部署。
本文首先基于复杂背景及小目标,分析了当前主流的自主检测识别网络,包括基于区域建议的方法和基于回归的方法,并对网络进行性能评估,使用MAC统计及参数需求量对其硬件需求进行定量评估,构成智能算法硬件嵌入式平台的基础输入要求。其次,提出了基于卷积神经网络的压缩算法,并对算法进行普适性分析。最后,基于嵌入式GPU平台,实现了基于TensorRT路线的神经网络加速,然后推理分析了经优化算法优化后的网络结构,并对网络精度损失情况和网络加速比情况进行了评价。
1 网络性能评估和硬件资源需求定量评估
对目前主流的深度学习自主识别算法进行参数及MAC计算量统计,如表1所示。可以看出,针对不同的神经网络,所需要的硬件资源各不相同。MAC数目越多,代表硬件上所需的乘累加操作越多;权值合计越大,代表硬件上所需的存储空间越大。

表1 深度学习识别算法参数及MAC计算量统计Tab.1 Deep learning recognition algorithms parameters and MAC calculated quantity statistics
从性能方面讲,在所有算法当中,YOLOv3算法从速度和精度两方面均获得了较为惊艳的效果。Darknet53借鉴残差结构,采用类似ResNet的跳线连接方式,性能相比ResNet系列更加优异。目前在各类落地应用当中,YOLO系列算法更多采用Tiny网络,该网络层数较少,MAC统计量约为YOLOv3算法的1/13。Tiny网络容易实现硬件应用,且仿真较为容易,但是网络精度相对较低,无法适应精度要求较高的多目标分类场合。于是,如何实现检测精度较高的YOLOv3算法的真正落地,是目前亟待解决的难题;此外,类似YOLOv3这类深层网络算法如何在嵌入式端落地,也是目前亟待解决的难题。
2 YOLOv3网络结构与输出特征分析
YOLOv3网络结构共计107层,网络最终输出三部分特征图,如图1所示,分别为Conv_6、Conv_14和Conv_22卷积节点,在此基础上,进行分类与位置回归。这3个卷积节点分别称之为小尺度yolo层、中尺度yolo层和大尺度yolo层。13×13×255尺度用于检测较为大型的目标,26×26×255用于检测较为中型的目标,52×52×255用于检测较为小型的目标。三层特征输出层的详细输入、输出和卷积核参数如表2所示。

图1 YOLOv3网络结构的三部分特征输出Fig.1 Three-part feature outputs of YOLOv3 network structure

表2 YOLOv3网络输出特征图详细参数Tab.2 Detailed parameters of YOLOv3 network output characteristic diagram
3 神经网络裁剪算法
为神经网络设定合适的裁剪滤波器,从网络结构中剔除掉相对不重要的参数,将剩余网络结构进行微调或重新训练,可以在较短时间内有效对神经元或权重连接实现裁剪,网络裁剪过程如图2所示。

图2 神经网络裁剪结构对比图Fig.2 Contrast diagram of pruning structure of neural network
利用阈值方法对网络权重进行整体裁剪,是网络裁剪算法中最常用的步骤。假设阈值为ω,保留每层中filter权重绝对值之和大于阈值ω的权重。阈值法裁剪方式如式(1)所示,其中i和j代表卷积核的维度
(1)
式(1)很难从全局进行分析,并且不能将训练融入裁剪当中,从而导致网络精度降低。文献[25]采用一种基于注意力模块的剪枝滤波器,称为SEBlock,由全局池化层、全连接层和激活函数组成。将通过注意力模块的输出称为缩放因子,其变换过程描述如式(2)所示
F(X〈n,W,H,C〉)=sig(FC2(ReLU(GAP(X〈n,W,H,C〉))))
(2)
其中,X〈n,W,H,C〉代表输入,FC代表全连接层,GAP代表全局池化层,ReLU和sig代表激活函数。
为了更好地使得裁剪过程自适应,本文提出将SEBlock与BN层缩放因子同时进行正则化训练裁剪的方法,算法策略如下所述:
1)通过SEBlock计算缩放因子,获得能够反映通道重要性的参数,结合通道在样本数据集下的平均值进行综合分析,更准确地反映通道重要性。
2)利用L1正则方法,在网络原本代价函数的基础上,将步骤1)计算出的缩放因子,与BN 层的缩放因子同时归入目标方程,进行稀疏化训练,如式(3)所示
(3)

3)依照步骤2)进行训练裁剪后,对网络进行微调,从而恢复裁剪后网络的检测精度。
网络裁剪的目标是在保持网络精度的前提下,保留重要权重,去掉不重要权重,其核心在于如何在裁剪的同时,更好地保持精度。文中所提出的自适应稀疏化训练方式可以在裁剪的同时,最大程度上保证网络精度。整个裁剪过程训练流程图如图3所示,首先利用式(3)对网络进行稀疏化训练,随后裁剪掉稀疏的网络连接,其次对裁剪后的网络进行微调,获得剪枝后的网络。此外,该训练过程还可重复进行,并不断迭代,以便获得最优结果。

图3 裁剪过程训练流程图Fig.3 Pruning process training flow chart
本文提出的网络裁剪算法可以明显保持裁剪后的网络精度,针对本文裁剪算法已经经过测试的网络结构包括VGG、ResNet、Darknet53和DenseNet网络,该网络裁剪算法针对CNN具备普适性。
4 神经网络量化算法
最主流的权重量化方式包括Fp16量化和Int8量化,其中Fp16相比Fp32减少50%的位宽,Int8相比Fp32减少75%的位宽。线性Int8量化将权重数据量化到(-127~127)的范围当中,这种映射称为不饱和映射,将导致精度损失较大。本文将采用饱和映射进行量化,这也是TensorRT技术采用的量化方式。饱和映射的过程是寻找阈值|T|,将±|T|映射到±127范围当中,超过阈值之外的,直接映射到±127,饱和映射过程示意图如图4所示。

图4 饱和映射过程示意图Fig.4 Schematic diagram of saturation mapping process
本文采用的保精度量化算法策略如下所述:
1)从验证集当中,选取子集当作校准集,用于校准Int8量化带来的精度损失;
2)在选取的校准集上进行Fp32推理,对于网络的所有层,分别收集相关的激活值,列出直方图;
3)针对不同阈值实施遍历操作,选取可以使得KL散度取得最小值的阈值,最终获得一系列的阈值,并且所有层均返回一个阈值,称之为校准表(Calibration Table),最终利用校准表实现神经网络Int8的保精度量化过程。
本文采用的网络量化算法可以明显保持量化后的网络精度,针对本文所采用的量化算法,已经经过测试的网络结构包括VGG、ResNet、Darknet53、AlexNet和GoogleNet网络,该网络量化算法针对CNN具备普适性。
5 TensorRT神经网络优化技术
TensorRT技术属于英伟达的不开源神经网络加速技术,为神经网络部署提供基于GPU平台的加速解决方案。目前,TensorRT技术最擅长CNN优化,TensorRT技术程序部署流程如图5所示。

图5 TensorRT程序部署流程Fig.5 Program deployment process based on TensorRT
TensorRT通过对网络进行合并与量化,形成更为紧凑、硬件资源需求更小的网络结构,能够确保在减小资源使用率的同时,使得网络结构性能损失程度较小。TensorRT技术首先通过优化技术生成如图5所示的中间层engine,随后利用该优化后的engine对网络结构进行部署,实现各类受限资源条件下的神经网络实时应用。
对于如图6所示的原始网络,TensorRT技术可将其垂直方向优化为如图7所示的优化后网络结构,从而有效实现网络推理加速,水平方向的优化与垂直方向类似。此外,结合网络裁剪技术,可在推理过程当中获得更高的加速比。

图6 原始网络结构Fig.6 Original network structure
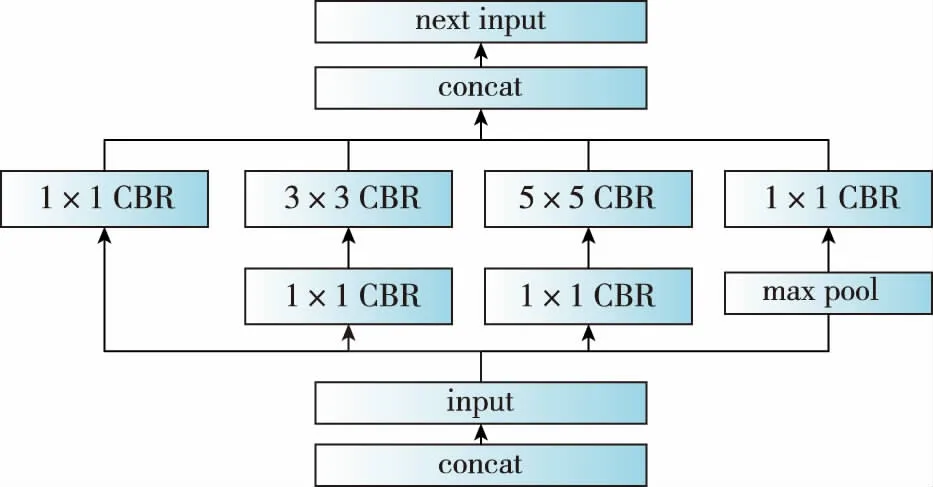
图7 垂直方向优化后的网络结构Fig.7 Vertical optimized network structure
6 仿真验证
为了验证本文提出和采用的网络压缩算法在嵌入式端的加速能力,选取Nvidia Jetson Xavier作为验证平台,并与TensorRT优化进行比对。Xavier是英伟达的异构嵌入式GPU平台,CPU具备8核ARM64架构,GPU具备512颗CUDA核心。在公有数据集VOC2007与VOC2012上进行数据训练,利用获得的权重计算初始精度mAP值。随后利用裁剪与量化算法进行优化,并利用经算法优化后的权重计算新的mAP值。经过20次裁剪与量化仿真测试,选取最优仿真结果,同时,对未开源的TensorRT技术进行技术应用,仿真验证结果如表3所示。

表3 YOLOv3算法嵌入式端仿真验证结果Tab.3 Simulation and verification results of YOLOv3 on embedded GPU platform
YOLOv3算法的部分网络裁剪结果如表4所示。由表4可以看出,裁剪算法针对不同的卷积层会进行相应的裁剪,有些层通道数目变小,有些层通道数目不变。网络裁剪将直接改变网络结构,裁剪结果与训练数据集密切相关。
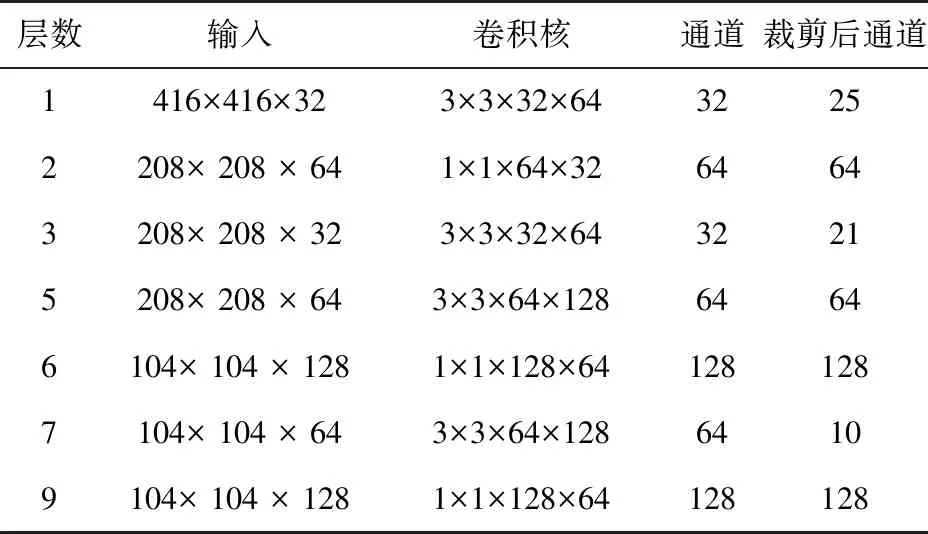
表4 YOLOv3算法部分网络裁剪结果Tab.4 Partial network pruning results of YOLOv3
YOLOv3算法裁剪前后的精度与帧频对比结果如表5所示,表中结果均是分别在相应条件下运行10次程序后选取的最优结果。可以看出,针对不同的裁剪力度,精度下降情况和帧频变化均不同,裁剪力度越大,精度下降越快,帧频越高。

表5 YOLOv3算法裁剪前后精度与帧频对比Tab.5 Accuracy and frame frequency comparison of YOLOv3 before and after pruning
从表3~表5的仿真验证结果可以看出,裁剪与量化的方式可以在网络精度损失较少的情况下,使得嵌入式平台上的网络推理获得理想的加速比。原版darknet在异构嵌入式平台的帧频为8帧/s,经TensorRT技术优化后可获得3倍的速度提升。经本文提出的网络压缩算法,可以在精度损失小于5%的前提下,获得3倍以上的速度提升。
相比不开源的TensorRT技术,本文算法思想可以实现自主可控的神经网络压缩及嵌入式应用。此外,基于本文思想,结合复杂算法实现裁剪与量化,将使得目标检测识别网络精度下降幅度更小。
7 结论
本文提出了针对卷积神经网络的压缩算法,并进行了相应的嵌入式平台应用。相比不开源的针对GPU平台的TensorRT优化技术,本文算法思想可以合理进行各类硬件平台的技术复用。针对神经网络的定量硬件资源评估,以及针对GPU嵌入式平台所进行的裁剪和量化实验分析表明:
1)各类自主目标识别神经网络算法的硬件资源需求量可通过计算获得,针对目标算法,可以利用资源计算分析来合理设计硬件。
2)基于英伟达目前的TensorRT技术,利用8bit量化技术,在嵌入式GPU平台可以实现神经网络3倍的推理速度提升。由于此项技术为不开源技术,所以精度损失程度未知。从公开资料来看,网络精度损失较小。
3)基于本文所提出和采用的网络裁剪及量化优化算法,在网络精度损失小于5%的前提下,获得了3倍以上的推理速度提升。本文算法与针对GPU平台的不开源TensorRT技术相比,为针对不同平台的神经网络优化技术应用提供了新的技术思路。
经验证,本文的优化算法思想可直接应用于FPGA平台。本文的下一步研究方向是基于FPGA平台的硬件优化[26-27]。在具备国产自主性、低功耗的FPGA平台,利用网络优化技术实现神经网络的实时应用部署,为制导武器末制导人工智能机器视觉技术的军事应用提供进一步的技术解决方案。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年13期)2022-07-19
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
家庭影院技术(2021年7期)2021-08-14
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
软科学(2014年8期)2015-01-20
图书馆界(2013年5期)2013-03-11
