
基于用户偏好动态变化的协同过滤推荐
2020-02-08 02:34姜书浩张立毅
计算机与现代化 2020年1期
姜书浩,张立毅,周 娜
(1.天津大学电气自动化与信息工程学院,天津 300072; 2.天津商业大学信息工程学院,天津 300134)
0 引 言
推荐系统在过去的十年中已经成为强大的工具,用户通过它可以根据自己的偏好浏览海量信息[1],同时有效地提高了使用的满意度和忠诚度。个性化推荐系统目的是为用户推荐可能感兴趣的信息或物品(如音乐、电影、书籍等),并且已经广泛地应用于电子商务、社交、新闻以及电子学习等领域[2]。
推荐系统最常用的2种方法是基于内容的推荐和协同过滤推荐。基于内容推荐根据用户已经评分的项目内容推断出用户的个人偏好信息,并根据对项目的特征描述和用户偏好特征向用户推荐可能感兴趣的项目[3],因此基于内容的推荐依赖于对项目和用户的描述性数据。而协同过滤推荐不依赖于项目的显示特征描述,它根据与其兴趣相似的用户已评分项目来预测用户的偏好。近些年来协同过滤技术得到了更加广泛的应用,但是仍然存在稀疏性、可扩展性以及过度拟合等问题。
首先,协同过滤技术最大的特点在于它仅仅依据用户对项目的评分,完全独立于所推荐项目的具体类别。所以采用协同过滤技术进行推荐的项目往往是分值较高的项目,而内容可能与用户期望获得的推荐大相径庭。例如,向某个特定用户推荐剧情类电影,结果计算出k个评分最相似的电影,但类型可能完全不同。也就是说,协同过滤技术中的相似度计算仅仅依赖于用户对项目的评分,而预测项目内容可能与已评分项目毫无关联。
其次,传统的协同过滤方法假设用户偏好是固定不变的,忽略了用户兴趣随时间的变化。例如,一位电子商务专业的本科生在高中时对历史书的评价很高,但是随着他进入大学后对历史书的评价可能有很大的变化。因此,大多数研究工作中对新数据的分析要比相对陈旧的数据分析更为重要[4],当然,仅仅考虑最新的数据也不能对用户偏好进行完整的描述。
本文主要通过引入项目类别信息来改进现有的协同过滤算法,并根据时间为每个项目评分设定不同的权重值,反映用户偏好随时间的变化。该算法使用与预测项目类别相关的项目计算相似性值,以产生更好地反映真实偏好的近邻集合。同时算法还设定了2个权重计算的原则:如果历史的评分数据不是周期性的,那么用户最近的数据值比早期的数据值权重更高;用户早期感兴趣的项目评分分值的权重适当减弱,而近期和周期的评分分值权重适当提高。
1 研究背景
协同过滤算法目前是个性化推荐使用最广泛的方法,很多优化和改进的算法被用来解决个性化推荐中的稀疏性、可扩展性以及运算复杂度等问题[5-8]。Chakraborty[9]采用k-中心点对用户和项目进行聚类,来解决计算复杂度的问题。Yang等[10]提出了一种基于项目聚类预测的协同过滤方法,提高了推荐算法的可扩展性。Acilar等[11]提出了一种基于人工免疫网络算法的协同过滤模型,解决了稀疏性和可扩展性的问题。上述的研究在进行相似性计算时考虑了项目类别带来的影响,但是忽视了时间因素对协同过滤的影响。
在协同过滤算法中,相似性计算是影响推荐质量的一个关键因素,它可以对系统的整体性能和推荐结果产生重大影响[12]。用户偏好的相似性计算是生成最近邻的最重要的方法,但是用户的偏好会随时间的变化而变化,因此对用户进行相似性计算时应该考虑时间因素的影响。一些研究在用户偏好的计算中考虑了时间因素的影响[13-15],另外一些研究通过动态的方法预测用户的偏好变化。Liu等[16]通过关键词查询图来表达用户的动态搜索,采用非线性逐步遗忘协同过滤算法,显示了用户的偏好随时间的动态变化。Xiong等[17]建立用户-项目-时间三维向量,利用向量分解的方式研究用户行为的动态变化。Huang等[18]提出了一种加入时间衰减序列模式的新的协同推荐方法来准确地模拟和预测客户的购买模式。Koren[19]通过将时间序列分段聚类,将每个分类作为一个隐状态得到状态转移概率矩阵,建立关于分段的隐马尔科夫模型,对用户的未来行为状态进行预测。Jeon等[20]提出了一种自适应的用户分析方法,该方法根据用户的喜好随着时间推移和区域变化动态的更新策略。
用户偏好相似性计算的依据是用户对不同项目的评分,但是用户在不同时间阶段的评分对于用户当前偏好状态的影响权重也应各不相同。涉及时间因素的评价分为3种:近期评分、早期评分和周期性评分。上述研究成果关于时间的影响研究都是片面的,本文提出的基于用户偏好动态变化的协同过滤推荐算法,在基于项目类别的基础上,对3种时间因素相关的评分对个性化推荐的影响进行了深入研究。
2 基于偏好动态变化的协同过滤算法
协同过滤方法分为基于模型的协同过滤和基于记忆的协同过滤这2种方式。基于模型的算法首先通过构建用户评分模型来提供项目推荐。模型可以用贝叶斯网络、聚类以及基于规则方法等建立[21]。基于记忆的协同过滤算法利用整个用户项目数据集来生成预测,分为基于用户的方法和基于项目的方法。
协同过滤系统的目标是提高用户的推荐质量。目前的协同过滤系统的主要依据用户显式或隐式的数据,并基于用户(项目)的最近邻预测用户的偏好。然而,现实世界中的用户兴趣随时间的动态变化将导致系统偏离用户需求。本文提出一种改进的基于项目的协同过滤算法,其前提假设是用户的兴趣并不是固定不变的,它随着时间的变化而变化。该算法将项目评分时间引入权重函数,每个分值的权重根据时间确定,时间较远的评分数据权重较低,时间较新的评分和周期性的评分权重较高。
2.1 建立矩阵
建立项目评分矩阵用于发现项目之间的相似性。任何物品如书籍、视频等内容计算机都很难自动进行分析,算法首先基于项目的属性对项目进行分类。例如,在电影分类中,根据每部电影的内容类型可以将电影分为动作、戏剧、喜剧、动画等类型。通过这种方式将项目和用户分成子矩阵,每个子矩阵是由属于类型g和至少对该类型电影进行过一次评分的用户组成,称之为类型g的子矩阵:
其中,ng是属于类别g的项目的数目,mg是至少评价了一个类别g的项目的用户数目,Ru,i是用户u对项目i的评分。
2.2 生成邻居集合
最近邻集的产生最重要的是计算项目之间的相似性。该算法相似性的计算是基于与预测项目种类相关的项目,不是所有项目。子矩阵Ag(g=1,…,G)中,使用皮尔森相关系数计算项目i和项目j(i=j,j=1,…,ng)之间的相似性权重,如公式(1)[21]:
(1)

2.3 预测评分
在计算项目i与类别g中每一个项目的相似性权重之后,用户u对未评分项目i的预测评分可以通过公式(2)计算得出。
(2)
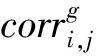
(3)
其中,α为时间权重,计算公式为式(4);β为重要性权重,计算公式为式(6);γ为评分率权重,计算公式为式(7)。将3个权重值α、β和γ相结合为权重函数。当α=1,β=1和γ=1时,f(u,i)的计算结果为1,所以权重函数的取值范围为[0,1],Ru(td)表示用户u在td时间的评分。
(4)
时间权重α是一种具有指数形式的单调递减函数,用来表示用户兴趣随时间的变化。α∈[0,1],Itr为用户2次连续评分之间的平均间隔时间,其中t由公式(5)计算得出。
(5)
式(5)中,t0表示用户最后一次评分的时间,td表示用户u对子矩阵Ag的项目最后评分时间。
(6)
重要性权重β表示类别g对于用户u的重要性,β∈[0,1]。Sug为用户u对属于Ag的项目的评分之和,Su为用户u的评分总和。
(7)
评分率权重γ∈[0,1],其中Nug表示用户u对属于Ag且评过分的项目的数目;Nu表示用户u评分过的项目的总数。
2.4 权重参数选择
用户的偏好会随着时间而变化。一个很久以前对某个项目或者内容感兴趣的用户现在可能对同一个项目毫不在意,因为他的兴趣偏好已经转移到别的项目上去了。在用户的兴趣不断变化的背景下,较近的时间段的评分通常比较早期时间的评分更能反映用户当前的兴趣偏好,也更加重要。当前时间与最后一次评价同一类别项目的时间之间的间隔就显得非常重要了,因此引入权重函数,换句话说,就是衡量属于目标类别的项目有多长时间没有被评分了。该值很小也就是时间很短,表明用户对这样的项目还是有很大的兴趣,当然,在某些环境下或者因为某些原因,用户因为长时间不使用该网站(系统)造成这样的情况,这并不意味着用户对这些项目失去了兴趣,仅仅是因为用户这段时间没有评价过该项目而已。
另一方面,人们通常有不同的习惯。有些用户对电影更感兴趣,所以经常花时间看电影,而其他人可能很长时间才看一场电影。例如,2个用户,第一个每天看好几部电影,而第二个每个月才看一部电影。在这种情况下,对于第一个用户来说一个月前看到的电影已经是非常久远的了,对于第二个用户来说时间是最近的。也就是说,周期长度是每个人的相对值,因此公式(5)中需要将(t0-td)值除以目标用户连续2次评分之间平均时间间隔。
此外,最近被评分的项目并不一定意味着用户对其有特殊偏好,也有可能是用户最近对其进行了低评。区分一个项目最近被用户评分还是低评,权重函数计算时考虑了最后一次评分的分值(Ru(td))。例如,仅考虑时间权重α作为权重函数,不考虑β与γ的值,假设项目i和项目j在t=1时的评分分别是0和5,则对应的权重函数分别是0.367和0.846,可以看出评分值对权重函数的结果有较大的影响,也就意味着权重函数能正确反映评分值的高低。
根据上述研究,可以看出时间权重增加了用户近期行为的影响,降低了用户历史偏好行为的影响,同时考虑了用户的偏好特征(Ru(td))和行为习惯((t0-td)的平均评价周期)。有些用户的偏好是有周期性的,因此如果有人长期不评价某一类别的项目,并不一定意味着他不会再去选择这类项目。重要性权重和评分率权重都考虑了用户周期性偏好的问题。
为了处理用户偏好随时间变化的情况,本文引入一种新的不依赖于任何阈值的权重函数,同时考虑α、β和γ,也就是通过公式(3)计算权重函数。
2.5 基于权重函数的协同过滤算法
输入:用户项目矩阵A,时间戳矩阵B和项目类别集C。
输出:预测用户项目矩阵P。
算法过程:
1)将矩阵A根据项目类别C划分为g次矩阵Ag(g=1,…,G)。
2)根据公式(1)计算生成目标项目子矩阵Ag的近邻集合。
3)根据公式(3)和矩阵B计算目标项目的权重函数。
4)根据公式(2)计算预测用户项目矩阵P。
5)回归预测用户项目矩阵P。
3 实验与结论
3.1 数据集
实验采用的数据集是公开的数据集MovieLens的子集。MovieLens数据集包含943个用户对1682部电影的100000个评分数据,评分的范围为1~5,用户集是随机选择至少为20部电影评过分的用户。将数据子集划分为80%的训练集和20%的测试集。
电影信息包含在电影文件中,类型主要分为:动作、冒险、动画、儿童、喜剧、犯罪、纪录片、戏剧、幻想、黑色电影、恐怖、音乐、神秘、浪漫、科幻、惊悚片、战争和西部。
3.2 评价指标
平均绝对误差(MAE)是一种被广泛使用的度量方法,它通过比较测试数据集中对用户推荐项目的预测分值与实际用户评分的误差情况来反映推荐的准确性[22-24]。MAE首先计算N个相应的评分预测对的绝对误差,然后计算平均值。MAE越低,推荐系统预测用户评分的准确性就越高。
3.3 实验结果
1)类别因素在皮尔森相关度量中的影响。
在第一个实验中,在相似性计算中采用皮尔森相关系数与考虑项目类别因素这2种方法进行比较,结果如图1所示。显然,采用考虑类别因素计算相似性可以有效提高协同过滤的预测准确性。传统的协同过滤使用所有邻居项目,其中包括内容上与目标项目毫无关系的项目,而本文提出的方法仅仅考虑与预测项目种类相关的项目。类别属性的引入意味着预测的基础是相似性计算仅考虑内容相似的邻居的评分。

图1 皮尔森相关系数与考虑项目类别因素的MAE对比
2)时间权重对准确性的影响。
实验中,对采用时间权重与无时间权重的协同过滤算法进行比较,结果如图2所示,系统的预测准确性随着时间权重参数个数的增加而逐步提高。当相似性值大于等于0.4,且权重函数仅考虑评分时间的远近问题,此时权重函数为公式(8),通过对历史数据降低权重来减少历史偏好的影响,提高了预测准确性。原因是用户的兴趣随着时间的推移而变化,最近的项目评分在预测当前用户的偏好项目方面可能起到更重要的作用,而早期的评分数据对最终推荐的贡献度相对较小。
f(u,i)=e-(t0-td)
(8)
如果最后一次评分项目的类别与目标项目类别相同,则权重函数为公式(9),预测准确率进一步提高,因为最近评分的项目如果得分较高的话,这说明用户目前对这类项目有很高的兴趣偏好。
(9)
虽然前面介绍了评价时间(t0-td)对系统推荐质量的影响,但是这一指标具有个体差异性,所以有必要通过评分的平均时间间隔来考虑每个用户的行为习惯。此时权重函数为公式(10),其中t由公式(5)计算得出,从图2可以看出,通过引入评价时间和平均评价周期后,在不同相似性值的情况下,MAE值均显著低于传统方法。

图2 权重函数不同情况下与传统协同过滤的MAE对比
f(u,i)=e-t
(10)
最后,从图2中可以看出,如果权重函数采用时间权重α,系统的预测准确性会进一步提高,这是因为如果用户最近的评价是积极的,时间权重函数将增加对用户最近行为的考量。
3)重要性权重和评分率权重对预测准确性的影响。
实验中将重要性权重和评分率权重的方法与无权重的方法进行比较,结果如表1所示,当相似性值高于0.4时,单独考虑2种权重方法的MAE值均优于无权重函数的协同过滤的MAE值。原因是相同的,就是这2个加权函数为用户经常评价的项目提供了更多的推荐机会。
表1 3种方式的MAE对比

相似性值协同过滤重要性权重α评分率权重β00.8161.8121.7970.10.8211.7651.7010.20.8391.6491.5940.30.9621.4821.4650.41.2431.1881.1630.51.5020.9360.8920.61.9620.6680.6340.72.4680.4810.4700.82.7610.3900.389
4)与经典的基于项目的协同过滤算法比较。
表2中显示了传统协同过滤、时间权重、重要性权重、评分率权重以及完整权重参数共5种情况下MAE的最佳结果。实验还比较了完整权重函数的协同过滤算法与经典的基于项目的协同过滤算法。图3显示了完整权重与传统协同过滤的推荐方法的比较,从相似值大于等于0.4开始,相对于经典的协同过滤能够给出更高的推荐准确度、更低的MAE值。融合了3个权重函数组合的推荐算法增加了用户最近时期个人偏好的推荐权重,更真实地反映用户当前的兴趣并满足用户的推荐需求。
表2 权函数中各参数最佳MAE结果的比较

传统协同过滤f(u, i)=αf(u, i)=βf(u, i)=γf(u, i)=(α+β)2×γ0.8160.4810.390.3890.36

图3 传统协同过滤与完整权重函数的MAE对比
4 结束语
协同过滤算法在以往的研究中已经通过各种各样的算法得到改进和优化。本文在基于项目的协同过滤框架下,引入了一种不依赖于任何阈值的新的简单加权函数,考虑了项目类别因素和用户兴趣随时间的变化,建立基于用户偏好动态变化的协同过滤推荐模型。通过实验验证,考虑用户的行为习惯和周期性需求,新算法在推荐准确性方面明显优于传统的协同过滤算法。
近年来,时间信息在协同过滤中占有越来越重要的地位,而用户偏好中的时间效应在推荐中起着越来越重要的作用。本文只考虑了时间因素对于推荐准确性的影响,下一步工作将重点研究时间因素对于推荐多样性的影响。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
当代陕西(2020年17期)2020-10-28
河北画报(2020年8期)2020-10-27
人大建设(2018年5期)2018-08-16
民族古籍研究(2018年1期)2018-05-21
西夏学(2016年2期)2016-10-26
浙江大学学报(工学版)(2016年2期)2016-06-05
应用科技(2015年5期)2015-12-09
浙江大学学报(工学版)(2015年1期)2015-03-01
中国中医药现代远程教育(2014年16期)2014-03-01
