
基于收缩极限学习机的故障诊断鲁棒方法
2020-02-08 04:11陈剑挺吴志国叶贞成朱远明
计算机工程与设计 2020年1期
陈剑挺,吴志国,叶贞成,朱远明,程 辉
(1.华东理工大学 化工过程先进控制和优化技术教育部重点实验室,上海 200237;2.安徽海螺集团有限责任公司,安徽 芜湖 241000)
0 引 言
随着人工智能和计算机技术的高速发展,基于数据驱动的故障诊断技术已成为工业界的热门研究领域,而极限学习机(extreme learning machine,ELM)的提出,为故障诊断技术提供了一种新的解决方案。ELM具有训练速度快,泛化精度高的特点[1]。但是在实际工业过程中,由于生产环境的影响,导致采集到的数据中带有噪声是一种常态现象,常规的ELM鲁棒性不强,容易受到噪声的干扰。
基于此,Horata等[2]提出了一种基于迭代重加权最小二乘法(iteratively reweighted least squares,IRWLS)的鲁棒ELM,通过对样本数据添加权重的方式进行迭代训练,提高了算法的鲁棒性。在此基础之上,Chen等[3]在ELM的目标函数中引入正则项,提出了基于迭代重加权最小二乘法的正则化鲁棒ELM算法框架,提高了算法的稳定性和泛化能力。罗等[4]将该思想应用到在线学习上,并提出了一种权重变化和决策融合的极限学习机在线故障检测算法模型,并通过集成的方式提高模型的综合决策能力。Chen等[5]结合相关熵准则提出了一种基于KMPE(kernel mean p-power error)损失的相关熵正则化极限学习机,用KMPE相关熵损失代替常规ELM的平方损失项,进一步提高了算法的鲁棒性。文献[6]在此之上提出了基于混合相关熵损失的鲁棒学习方法。但是以上的方法针对的都是标签噪声问题,对于带有特征噪声的数据集,训练出来的算法模型仍存在较大的偏差。鉴于此,Kasun等[7]在分类之前对特征进行提取,提出了一种多层学习架构,利用ELM自编码器(ELM-AE)来构建深层网络,以提取更好的特征表示。Tang等[8]提出了层级ELM(HELM)算法,并在其中提出了一种基于ELM的稀疏自编码器,通过该稀疏自编码器,HELM可以获得原始数据的更稀疏的特征表示,进一步提高多层ELM的分类性能,但是其在对抗噪声方面并没有给出较好的解决方案。
为此,本文针对特征噪声问题提出了一种收缩极限学习机(contractive-extreme learning machine,CELM)鲁棒算法模型,该方法主要分为两个阶段,第一个阶段为特征提取层,通过自编码器对输入数据进行重构,并将隐层输出值关于输入的雅克比矩阵的F范数引入到目标函数中,进而提取出更具鲁棒性的抽象特征表示,该阶段的隐层层数可以调整,且每一层都是独立训练,隐层的参数训练好之后就不再进行调整。第二个阶段为常规的ELM层,将第一阶段提取出的抽象特征表示作为输入,对该层进行训练。仿真实验对比结果表明,提出的方法在鲁棒性方面和分类准确率上都有很好的性能。
1 极限学习机ELM原理
极限学习机是一种单隐层前馈神经网络[1]。其模型结构如图1所示。

图1 ELM模型结构

hj(xi)=g(aj·xi+bj),aj∈Rn,bj∈R
(1)
(2)
T是训练数据集标签
(3)
β∈RL×m是输出权重矩阵
β=[β1,β2,…,βL]T
(4)
输出节点对输入xi的预测结果由下式给出

(5)
取预测结果的最大值作为标签
(6)
其中,c∈(1,2,…,m)。
对于ELM算法,其输入权重矩阵a和偏置量b是随机确定的,确定之后即不再改变。
因此,网络训练的目标函数为
(7)

采用最小二乘法求解式(7)中的目标函数得到隐层的输出矩阵
β=H†T
(8)
其中,H†是隐层输出矩阵H的Moore-Penrose广义逆矩阵
H†=(HTH)-1HT
(9)
为了进一步提高ELM的稳定性以及泛化能力,l2范数正则项被引入到了正则化ELM(RELM)之中,网络的目标函数为

(10)

β=(λI+HTH)-1HTT
(11)
2 收缩极限学习机算法模型
文献[7]和文献[8]研究结果表明,如果能够提取更有效的特征表示,ELM能够获得更好的性能。本文中采用自编码器来提取新特征。
2.1 自编码器
自编码器[9]的原理:首先对输入特征进行归一化,然后使用编码器将n维输入x映射到L维隐层h,公式如下
h=f(x)=sh(Wx+bh)
(12)
其中,sh(·) 是一个激活函数,本文使用的是Sigmoid函数
(13)
W是一个dL×dn维的矩阵,bh是dL维的偏置向量,而解码器g将L维的隐层表示重新映射成y
y=g(h)=sg(W′h+by)
(14)
W′=WT
(15)
自编码器,通过最小化训练集Dn上的重构误差来训练并找到参数θ={W,bh,by},其对应于最小化式(15)中的网络目标函数

(16)

收缩自编码器[10](contractive-autoencoder,CAE)以隐层输出关于输入的雅克比矩阵的F范数作为自编码器目标函数的惩罚项。并通过最小化重构误差与该雅克比矩阵的F范数的平方,使得提取出的特征表示围绕训练样本的小幅变化具有鲁棒性,即该惩罚项使得特征空间的映射在训练样本的邻域内是紧缩的。网络的目标函数如式(17)所示

(17)
其中
(18)
(19)
(20)
文献[10]中给出了特征表示可采用的标准衡量如下:①可以很好地重构输入数据;②对输入数据一定程度下的扰动具有鲁棒性。
引入l1范数或者l2范数作为惩罚项的自编码器主要符合第一个标准,而当以隐层输出关于输入的雅克比矩阵的F范数作为自编码器目标函数的惩罚项时所提取到的特征相对更符合第二个标准。
2.2 提出的CELM鲁棒算法模型
在工业控制系统中,采集到的数据往往会带有噪声,为了提高ELM算法模型的鲁棒性,本文提出了一种收缩极限学习机鲁棒算法模型。
结构如图2所示。CELM的模型分为两个阶段,第一个阶段为无监督的特征提取层,该层通过CAE收缩自编码器从输入中提取抽象特征表示,挖掘训练样本之间的隐藏信息。第一个阶段隐层的输出可以表示为
Hi=g(Hi-1Wi)
(21)
其中,Hi是第i层隐层的输出,且H0=x。Wi为第i层的输出权重矩阵,通过求解式(17)得到Wi,Wi确定之后就不需要再进行微调,再利用求得的Wi将第i-1层的特征表示映射到第i层隐层空间。第一阶段的每一层都是独立的模块,分开单独训练。
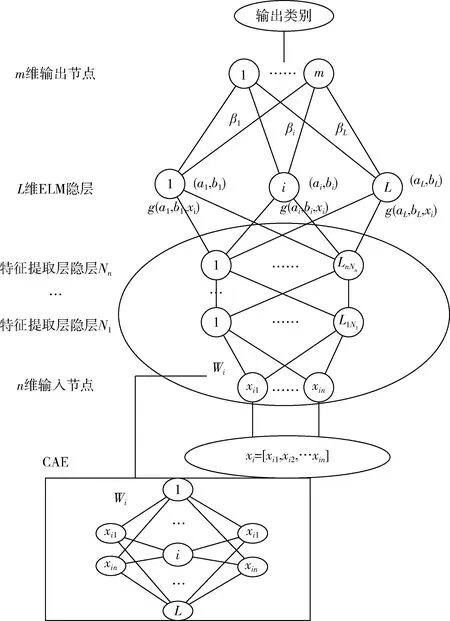
图2 CELM算法模型结构
第二阶段采用的是有监督的常规ELM层,将第一阶段从输入数据中提取出的抽象特征表示随机映射到L维隐层空间得到ELM层的隐层矩阵,再应用式(11)训练网络。
3 算法模型性能分析
由于故障诊断问题本质上是分类问题。本文首先以Mnist手写体数据集,以及11个UCI测试数据集为基准对本文提出的收缩极限学习机(CELM)算法模型进行分类性能分析,并与常规的HELM,ELM,SVM等算法进行对比。并通过在Mnist数据集中添加特征噪声的方式验证提出的方法的鲁棒性,最后再利用TE过程进行实验分析。
本文采用3.6GHz CPU,16G RAM,64位主机,在Python3.5环境下进行测试。
3.1 算法评价方法
本实验的性能评价指标选用ACC(准确率)。计算公式如下
正查准率:P-Precision=TP/(TP+FP)
(22)
负查准率:N-Precision=TN/(TN+FN)
(23)
正查全率:P-Recall=TP/(TP+FN)
(24)
负查全率:N-Recall=TN/(FP+TN)
(25)
准确率:
ACC=(TP+TN)/(ALL)
(26)
其中,TP,TN,FP,FN为表1表示分类问题混淆矩阵的元素。

表1 混淆矩阵
3.2 算法分类准确性测试
Mnist手写体数据集是由60 000个训练图像和10 000个测试图像组成,样本数字是0-9。Mnist数据集测试结果见表2。

表2 Mnist数据集测试结果
图3为Mnist数据集测试结果。就分类精度而言,CELM明显优于ELM和HELM算法模型;就中间隐层数而言,CELM的中间隐层数为2时的分类精度高于中间隐层数为1时。

图3 Mnist数据集测试结果
对于UCI数据集,本文将80%数据集作为训练数据,20%数据作为测试数据。对ELM,HELM,CELM分别测试20次,取平均结果。UCI数据集测试结果见表3。
根据测试集的结果,可以得出除了在Adult数据集中,CELM的分类精度会低于ELM,在其它数据集中CELM的分类精度都在ELM之上,且在White_wine_quality,Red_wine_quality,Wine,Seeds,Letter,Glass,Ecoli以及Dermatology中CELM的精度都是最高的,尤其在White_wine_quality数据集中,CELM的分类精度要比ELM高出12.8%,在Red_wine_quality数据集中,CELM的分类精度比ELM高出11.8%。通过表3可以得出,CELM的分类性能较好。

表3 UCI数据集测试结果
3.3 算法模型鲁棒性测试
为了验证所提出的CELM对特征噪声数据的鲁棒性,本文选用Mnist数据集,并在其训练样本中加入混合高斯噪声。噪声生成公式如下

(27)


表4 算法鲁棒性测试结果
在图4中可以看出,随着噪声强度的增加,CELM,ELM和HELM的分类精度也随之下降。ELM的下降幅度最大,在添加了方差为0.5的高斯噪声后分类准确率下降到了81.7%,说明常规的ELM在抗噪声方面性能较差。HELM与本文提出的CELM相比较,两者在方差为0.5的高斯噪声下分类准确率都保持在了91%以上,但是随着噪声强度的增强,HELM下降速率更快,两者的精度差也逐渐加大。因此,可以得出本文提出的算法模型在较ELM和HELM具有更好的鲁棒性。
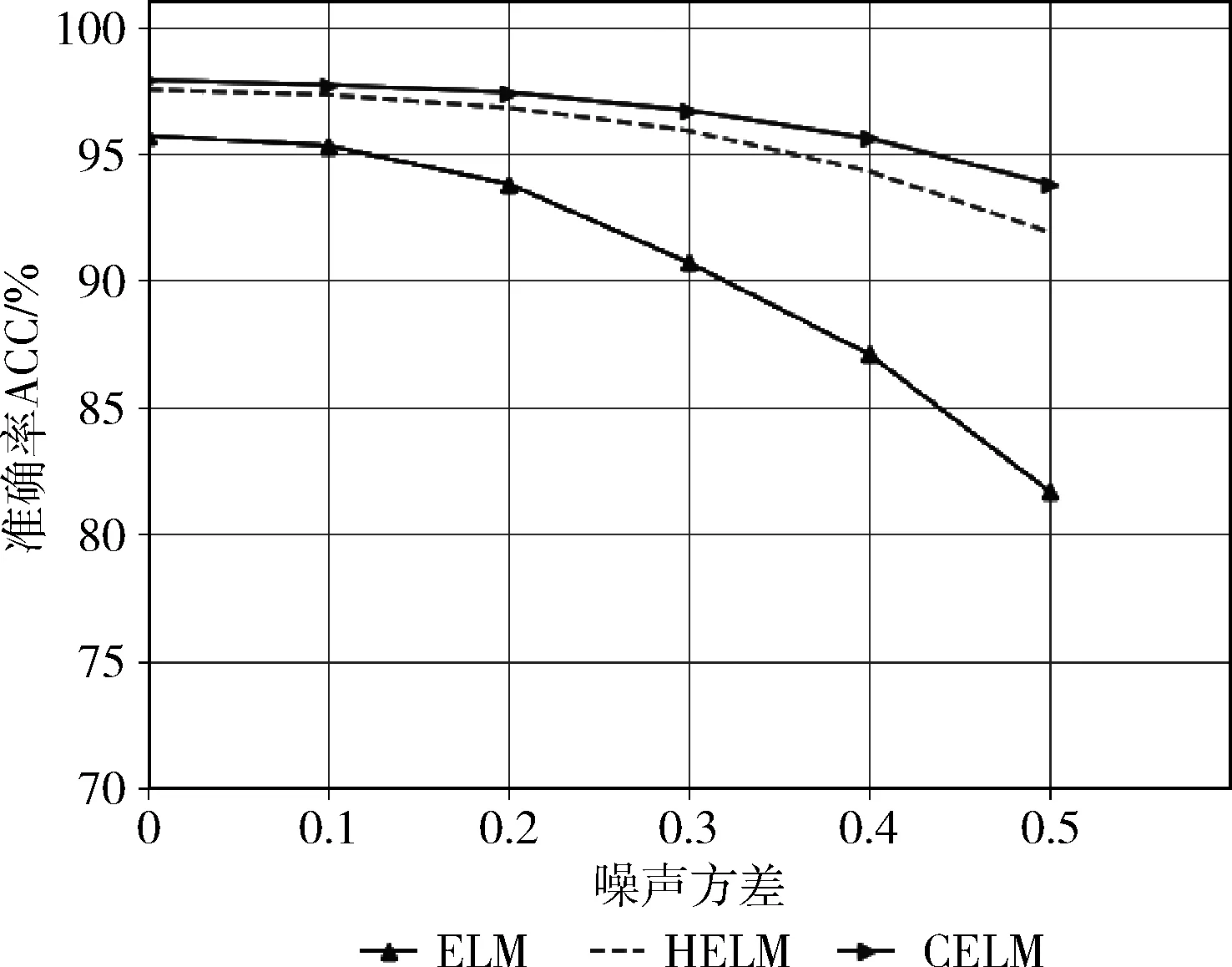
图4 添加不同级别噪声后的实验结果
3.4 TE故障数据集仿真分析
本小节中,分别以ELM,HELM以及本文提出的CELM对TE过程分别进行实验分析。TE过程共有52个测量变量,并且可以模拟20种不同的故障类型。
本文中选取其中10种不同故障类型以及正常过程的所有训练数据训练出一个分类模型,并以各种类型的1/3数据集作为训练数据集,2/3数据集作为测试数据集,对本文提出的CELM算法模型进行故障诊断性能分析。测试结果见表5。
由表5结果可得,针对上述故障类型,CELM较ELM,HELM有7种类型的分类精度最优,分别是正常类型、故障4、故障5、故障8、故障10、故障12以及故障20。

表5 10种不同故障类型的诊断性能比较(ACC)
表6为算法模型的平均训练时间。与ELM和HELM相比,CELM模型训练时间平均值有所增加,但在故障诊断方面的精度更高。

表6 3种算法模型的训练时间平均值
综上所述,本文提出的算法模型在准确率方面有较好的表现,且较ELM,HELM具有更好的鲁棒性,但是模型训练效率方面较ELM,HELM耗时要多一些。
4 结束语
本文针对工业系统中采集的数据变量多,且普遍带有特征噪声的现象,提出了一种基于收缩极限学习机的鲁棒算法模型。首先本算法模型以多层ELM网络模型结构为基础,然后利用自编码器,并将隐层输出值关于输入的雅克比矩阵的F范数引入到目标函数中,提取出围绕输入的微小变化具有鲁棒性的抽象特征表示,最后以常规的ELM层作为分类器进行训练。本文所提出的算法模型CELM在Mnist数据集、UCI数据集、带有混合噪声的Mnist数据集以及TE数据集上进行测试分析,实验结果表明,CELM较ELM、HELM具有更高的分类精度、更好的鲁棒性,以及更优的故障诊断精度。但是在本文中,CELM相比ELM以及HELM的训练时间较长,因此后续笔者下一步的重点在于优化隐层权重矩阵的计算过程,以提高模型的训练效率。
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
科技研究·理论版(2021年22期)2021-04-18
商洛学院学报(2020年4期)2020-07-08
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
人民珠江(2019年4期)2019-04-20
铁路计算机应用(2018年5期)2018-06-01
自动化学报(2018年2期)2018-04-12
北京航空航天大学学报(2017年6期)2017-11-23
制造技术与机床(2017年4期)2017-06-22
