
结合运动与边缘信息的语义视频对象提取方法
2020-02-05 02:19方勇
电子技术与软件工程 2020年7期
方勇
(上海易维视科技有限公司 上海市 200082)
1 引言
在MPEG 系列标准中,将视频对象定义为“在视频场景中用户可以存取(搜索、浏览)和操作(剪切和粘贴)的实体”,如自然场景中一个人、一辆车、一栋大楼等,要求具有语义上的完整性[1]。但是,通过低层视觉分割来得到具有语义完整性的视频对象非常困难,因为视频对象的一致性在低层视觉特征上不一定能反映出来,往往需要借助语义概念,而目前语义概念还难以用机器语言进行准确的定义和描述。因此,视频对象提取一直是视频内容分析与计算机视觉中的难点,目前大多数的视频对象提取集中在运动目标的提取上,要实现语义上的视频对象提取,一般需要先验知识或模型。当前,视频对象提取是一个研究热点,提出的方法和相关的文献非常多,大体上可以分为三类:空域提取、时域提取和时空联合分析[2,3, 4]。
本文基于时空联合分析提出了一种视频对象提取算法,首先在空域运用Canny 算子获得边缘图[5],并对边缘图进行后处理,去除不闭合的较短的线段和分支边缘,然后结合运动检测提取运动边缘;再次,基于多阶段仿射运动分割获得运动区域图;最后,采用主动轮廓模型融合运动边缘图和运动区域图[6],进行边界校正,获得较准确的视频对象。
2 视频对象提取
2.1 算法概要
运动视频对象具有两个基本的特征:
(1)视频对象是运动的;
(2)对象的边界是图像边缘像素集合的子集。

图1:结合运动与边缘信息的视频对象提取算法流程

图2:Canny 算子与Sobel 算子边缘提取对比示例

图3:金字塔实现的L-K 光流估计示例
因此本文提出的视频对象提取算法主要依赖运动信息,再结合空域的边缘信息进行边界校正,整个算法流程如图1 所示。整个算法大体上可以分为四个部分,第一个是边缘分析模块,第二个是运动分析模块,第三个是映射与跟踪模块,第四个是综合分析模块。
2.2 运动边缘力场
运动边缘力场的基本过程是:第一步,用Canny 算子检测边缘;第二步,运动检测;第三步,检测运动边缘;第四步,高斯扩展,形成一个光滑的运动边缘吸引力场。
2.2.1 边缘检测
Canny 算子检测边缘效果很好,如图2 所示,图中用Sobel 算子做对比,其中(a)为原始视频帧,(b)为Canny 算子提取的边缘,(c)为Sobel 算子提取的边缘。从图中可以看出,Canny 算子应用到自然场景,会出现许多噪声边缘,主要表现为短的线段与分支;也有可能出现边缘不闭合的情况。
2.2.2 运动检测
镜头内相邻两帧之间的运动检测方法最简单的是帧差法;此外,对帧差进行阈值化操作,还可以获得运动区域掩模。设帧差图为

一般情况下,直接根据帧差法进行运动检测,获得的运动区域掩模往往很难准确地反映场景中的真实运动情况,如空洞、噪声斑点等。但是,如果只是利用帧差进行运动边缘检测,只要对帧差图进行简单的处理,就有可能获得比较理想的结果。本文对帧差图的处理主要有两点:第一,不进行阈值化处理,避免阈值对最终运动边缘检测结果的影响;第二,对帧差图进行一次窗口为3×3 的极大值操作,进行膨胀,以避免边缘检测时边缘定位偏差的影响,

2.2.3 运动边缘
获得Canny 边缘图与帧差图后,就可以进行运动边缘检测,运动边缘在视频对象提取中最大的优点是可以避免静态边缘对运动视频对象提取的干扰。运动边缘检测分两步进行:第一,将帧差图与二值边缘图相乘,获得运动边缘图;第二,在运动边缘图上使用类似Canny 边缘检测的双阈值方法进行二值运动边缘检测。设运动边缘图为

根据式(3)可知,运动边缘图的特点是:只有同时存在边缘和运动才是运动边缘。由于运动图像的复杂性,真正有运动边缘的地方由于灰度的相似性,也有可能导致帧差很小,为了避免这种影响,不宜对运动边缘图直接进行阈值化处理,检测二值运动边缘。在本文中,使用双阈值的方法来检测二值运动边缘,如果ME(x,y)对于大阈值,则是运动边缘;如果ME(x,y)小于小阈值,则不是运动边缘;如果介于两者之间,则通过一个跟踪或生长过程来完成运动边缘检测。
2.3 多阶段仿射运动分割
运动信息是视频对象提取算法的主要依据,在自然场景的视频对象提取中,运动是最可靠的提取线索。本文中,采用多阶段仿射运动分割的方法进行运动分割。
2.3.1 稠密光流估计
要依据运动信息提取运动目标,首先要进行光流估计,获取稠密光流场。本文采用金字塔分层实现的L-K 光流估计方法估计光流场,该方法的最初目的是估计稀疏光流,用于特征跟踪,但是也可以实现任意尺度的光流估计。该方法由于对图像进行金字塔分解,逐层估计,在准确性、时间效率与鲁棒性方面取得了一个很好的折衷。其次,为了便于投影与跟踪,对于当前帧n,在n 与n+1 帧之间进行光流估计。图3 是典型视频帧的光流场,其中(a)和(b)分别为两组相邻的视频帧,(c)分别为对应的光流场。
2.3.2 全局运动估计
全局运动的一般过程是先用一个参数模型描述全局运动,然后再根据视频相邻帧的相关性估计模型参数。仿射运动模型的参数估计可以基于视频帧的运动场进行,本文采用基于运动场的六参数线性模型,

其中,(vx,vy)为运动速度或光流,使用最小二乘法来估计模型参数。设全局运动区域为A,根据光流场计算全局运动模型如下式:
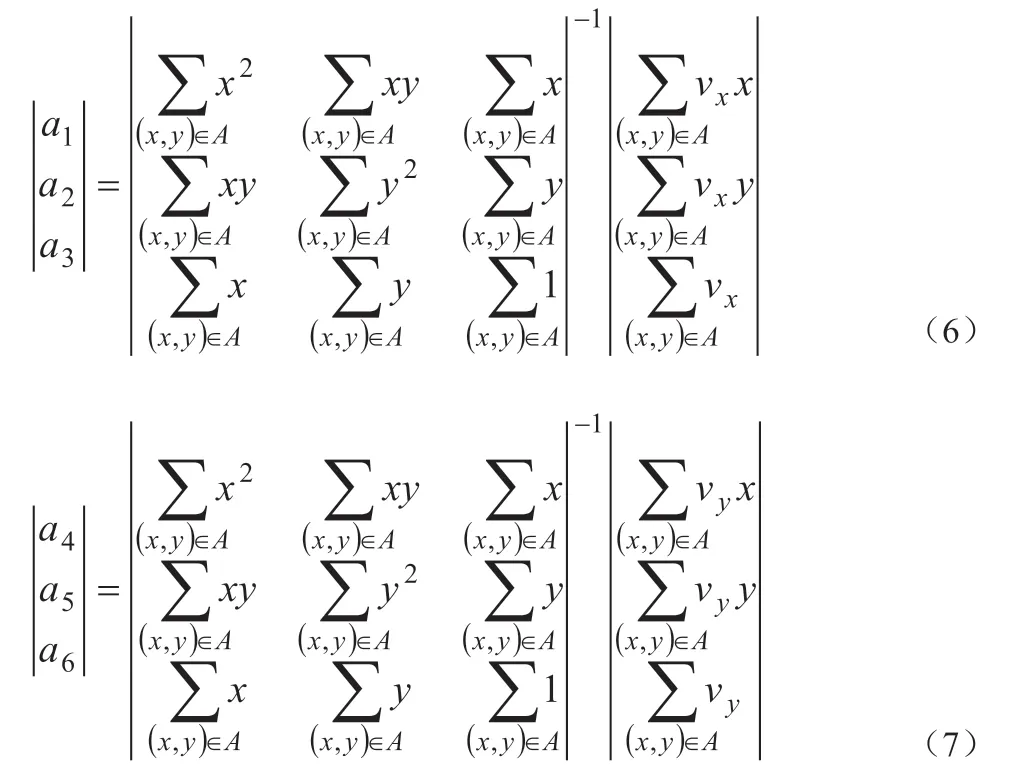
本文采用阈值可变双迭代方法估计模型参数,该方法将全局运动的迭代过程分解成为两个迭代过程:在第一个迭代过程中,使用一个递减的百分比阈值来排除外点,并估计模型参数的近似解,主要用来获得可靠的全局运动区域;在第二个迭代过程中,用一个固定阈值或自适应阈值来区分内点与外点,并获得完整的全局运动区域和准确的运动模型参数。
2.3.3 运动区域连通性分析与标识
根据视频检索的特点,使用对象进行检索,一般适合场景中主体不是特别多、特别复杂的情形,因此,我们采用快速分层的多阶段运动模型拟合与连通性分析方法来分割运动区域。经过全局运动分析后的,如果有多个运动目标,则在局部运动区域中,有可能存在多个运动区域。如果运动目标不重叠或不相邻,理想情况下,一个运动区域对应一个运动目标。但是,在实际场景中,运动目标有可能重叠,因此需要对每个运动区域进行运动一致性分析,判定是否属于一个运动目标。首先,对局部运动区域进行连通性分析,标识出全部连通区域;第二步,对每个连通区域用六参数模型进行拟和,如果异常点数小于连通区域像素数目的一定比例,即式(8)成立,

图4:独立运动区域分割示例
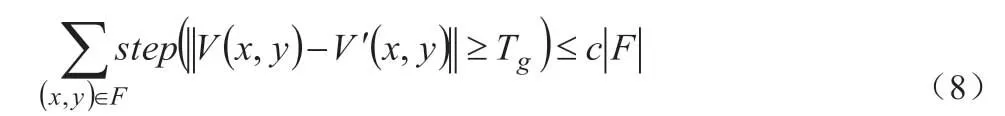
其中,V(x,y)为估计运动矢量,v'(x,y)拟和运动矢量,用拟合的六参数模型计算,F 为连通区域,Tg为异常点阈值,c 为异常点比例系数,通常取为5%,|F|为连通区域像素集合大小。则该连通区域为独立运动区域,对应着一个独立的运动目标。如果某个连通区域包含有两个或两个以上不同运动属性的运动目标,则采用多阶段的方法用类似全局运动分析对该连通区域进行运动模型拟合,直至分割出所有的独立运动区域,如图4(c)所示,其中,(a)为全局运动分析标识出的局部运动区域(黑色),(b)为局部运动区域进行连通分析的连通区域图,(c)为运动分割图。由于原视频序列中水面也在运动且图像中右边存在边缘,导致运动估计不准确,因此图像中右边出现干扰运动区域。
2.4 映射与跟踪
运动视频中的跟踪方法主要有两种:一种是区域跟踪法,另一种是轮廓跟踪法,当然,在视频对象跟踪中还有可能使用一些其它的信息,如颜色、背景模型等。区域跟踪法为整个目标区域建立参数运动模型,通过运动模型将当前帧中目标区域映射到下一帧中得到新的目标区域,然后再进行边界修正。区域跟踪法非常适合刚体运动跟踪,缺点是难以处理复杂的非刚体运动。轮廓跟踪法通常用于非刚体运动目标的跟踪,轮廓跟踪法包括轮廓演化与轮廓预测[6]。轮廓演化法使用主动轮廓模型,主动轮廓模型的缺点是容易受复杂纹理的干扰,其次是运算量较大;轮廓预测法是将前一帧中获得的目标区域的轮廓映射到当前帧中,作为当前帧中的目标区域轮廓,然后再进行目标边界修正,轮廓预测法的缺点是边界的不封闭性问题,尤其是部分目标区域在当前帧被遮挡的时候。
在CBVR 中,为了准确地提取视频对象的各种特征,重要的是视频对象不能出现大的区域性错误。为了满足这个要求,本文提出的视频对象跟踪方法自然地融合了以上各种方法的优点,避免其缺点。首先将前一帧中的目标区域根据其六参数仿射模型映射到当前帧,由于本文的运动估计是在当前帧与下一帧之间进行的,因此这种映射具有较好的准确性;其次,由于存在目标从场景中消失的可能,如目标遮挡、目标离开场景等,因此还应该进行目标的存在性判断,设目标区域为A,如果式(9)成立,则目标存在,否则为消失或遮挡,

其中,|A|为区域像素数目,Tp为阈值。如果式(9)成立,则当前帧的映射区域为跟踪区域。跟踪区域用于综合分析模块,与运动区域图、边缘图进行融合,以处理非刚体运动,利用轮廓预测法的优点。

图5:准确的视频对象提取示例
2.5 新目标检测与视频对象提取
在综合分析模块中,第一步就是新目标检测。在运动分析模块中,检测出了独立运动区域,但并没有区分是待跟踪区域还是新目标区域,因此首先根据运动分析模块与映射与跟踪模块的结果区分待跟踪区域与新目标区域。设前一帧中的目标在当前帧中的映射为Oi,当前帧中独立运动区域为Rj,如果

成立,则Rj为待跟踪区域,且待跟踪区域扩展为其中,Tn为跟踪运动区域阈值。在判断待跟踪区域时,由于非刚体运动的存在,一个跟踪目标可能会产生多个独立运动区域,因此可能出现多个独立运动区域为同一个目标的待跟踪区域,此时,目标的跟踪区域应该为映射区域与可能的多个独立运动区域的并。同样,如果在当前帧中,存在独立运动区域对所有的映射区域Oi都不满足式(10),则该独立运动区域为新目标区域。
经过新目标区域检测后,跟踪目标与新目标区域都已获得,但由于运动分割的局限性及非刚体运动的存在,目标区域的边界一般不是很准确,如图5 所示。此时,需要进行边界校正。本文采用主动轮廓模型来引进边缘信息,进行边界校正,其主要优点是能较好地拟合边缘,且能处理空域边缘不闭合的情况。主动轮廓模型也称为Snake 模型、可变形模型,能够较好的实现目标的轮廓提取与跟踪[6]。主动轮廓模型实质上是对一个目标能量函数进行优化的过程,使之在内力与外力平衡时停止运动,内力来自于曲线本身,如曲线的平滑力与弹性力;外力来自于图像数据,通常是图像的梯度场等,根据提取的特征的不同而不同,在本文中就是前面计算得到的边缘吸引力场。设图像平面内的轮廓曲线为,其中,s 为空间参数,即曲线参数,t 为时间参数,即迭代参数,则主动轮廓模型的能量函数的基本形式为

其中,Xs、Xss分别为X 的一阶和二阶导数,α 和β 分别为控制主动轮廓模型张紧和刚性的权重,其目的是控制轮廓曲线光滑且有弹性;Eimg(X)是外部能量项,通常由图像的灰度或边缘等获得,用来引导模型去拟合目标的边缘轮廓,本文中,

拟合边缘的过程就是能量函数式(11)最小化的过程。求式(11)的最小值,可通过Euler 方程求解,具体的计算过程可参见文献[6]。具体实现时,第一步根据跟踪目标与新目标区域提取每一个目标的轮廓,设目标区域个数为N 个,则可以得到N 个初始轮廓曲线;第二步,根据主动轮廓模型算法进行曲线演化,求取能量极小值时对应的轮廓曲线,得到目标准确的轮廓曲线;第三步,对N 个闭合轮廓曲线进行填充,从而获得目标区域,输出结果,整个过程如图5 所示,其中,(a)和(b)为原始视频帧,(c)运动分割掩模,(d)为当前帧图像的边缘,(e)为最终提取的视频对象掩模,(f)为最终提取的视频对象。一般情况下,主动轮廓模型的计算量比较大,由于本文算法是根据目标的运动分割掩模提取初始轮廓,不会偏离真实边缘太大,一般情况下只需迭代有限的若干次即可获得满意的结果。应用主动轮廓模型的主要目的是:第一,校正视频对象边界,运动分割由于运动矢量估计的原因,边界一般不准确,需要校正,主动轮廓模型在扩展边缘吸引力场的作用下可以实现平滑的调整,收敛到真实边缘;第二,处理断裂边缘,许多情况下,目标边缘不连续,即使是扩展边缘也不一定在所有的边缘像素处形成平滑的吸引力场,主动轮廓模型在曲线的平滑力与弹性力的作用下,在一定程度上可以解决这个问题。
获得目标区域后,对每一个目标区域根据其对应的光流用六参数仿射模型进行拟合,用于下一帧视频对象提取时的映射与跟踪模块。
4 小结
本文提出了一种有效的视频对象提取方法,采用时空联合分析方法提取视频对象区域,优点有三个:一个是使分割结果更加完整,连接或去除孤立的小区域和小的空洞,目标边界更加准确,更加接近对象真实边界;第二个能够处理视频对象的各种运动状态;第三个是在一定程度上可以处理非刚体运动和肢节运动,因为纯粹的刚体运动在实际视频场景中很少见。通过全局运动估计来提取局部运动区域,同时实现摄像机操作识别;对局部运动区域进行运动分割,获得独立运动区域,并与前一帧的提取结果进行融合,检测出跟踪目标与新目标区域;最后再结合边缘信息采用主动轮廓模型校正视频对象的边界。实验结果表明这种时空联合分析方法能有效的提取视频场景中的视频对象。但是,基于目前计算机视觉技术的局限性,背景复杂的视频场景中的视频对象提取依然是一个难以解决的问题。
猜你喜欢
装备制造技术(2020年1期)2020-12-25
制造技术与机床(2019年11期)2019-12-04
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
河北遥感(2017年2期)2017-08-07
通信产业报(2016年44期)2017-03-13
衡阳师范学院学报(2016年3期)2016-07-10
计算机工程(2015年4期)2015-07-05
舒适广告(2008年9期)2008-09-22
雕塑(1999年2期)1999-06-28
