
SVG中数据挖掘与应用
2020-02-04 06:33陈少英
电子技术与软件工程 2020年21期
陈少英
(厦门海洋职业技术学院 福建省厦门市 361012)
SVG 是由W3C 组织发布的一种基于XML 的二维矢量图形和矢量点阵混合图形的可扩展标记语言。其具有下载浏览速度快、动态、开放、便捷的图形定位与检索、良好的可交互性等优点,使其能更适用于不同系统间的图形系统交换。
在SVG 的图形系统数据服务端,图元动态数据的描述信息准确与否,会影响服务端的解析效率。在SVG 图形库庞大的情况下,提高服务器端对动态数据的特征提取及数据挖掘、对动态数据描述信息的解析就尤为重要。
1 数据解析
SVG 图形系统使用请求路由器MapDispatichServlet 来解析输入请求,并将请求分发到相对应的对象进行处理。MapDispatichServlet 分别实现doGet()方法和doPost()方法。doGet方法解析用户的请求,从输入中得到要取得地图的名称,从缓冲器中取得地图的SVG 文件,输出XML 格式的SVG 文件。同样地,doPost 方法解析用户的请求,按照地图名称取得SVG 地图,并根据请求格式的不同区分为SOAP 请求和普通的表单POST 请求,最后组成XML 文件输出。
SXW 格式解析器负责处理由SuperMap Deskpro 地图编辑软件产生的空间SXW 文件的解析,未来要考虑处理MapInfo、ArcMap等生成的工作空间文件。它提供外部所需的图层元素值,其中包括一个外部接口类(主类/驱动类):MapConfig;两个内部调用类:LayerBuffer,Parser;一个数据LayerBean,如图1所示。外部程序只能调用MapConfig 类,提供了两个入口,getValue 方法它返回的图层元素值为一个数据LaerBean,外部程序需要实例化该数据LayerBean。doParser 提供SXW 文档解析,外部程序首先应当调用该方法,驱动子系统解析SXW 文件,并返回true。
其中,图形配置模块MapConfig 中的getValue 用于获取Layer数据Bean,doParser 用于设置文件路径,检查文件是否存在,并调用缓存处理模块LayerBuffer 驱动XML 文件的解析。缓存处理模块LayerBuffer 中的getLayerValue 用于对解析出来的数据Bean 存储到HashMap。XML 文件解析模块Parser 中的getDocument 用于生成XML 文档解析器,生成Document 对象,elementParse 用于解析XML 文档元素生成Bean,dec2Hex 用于将十进制转换成十六进制。

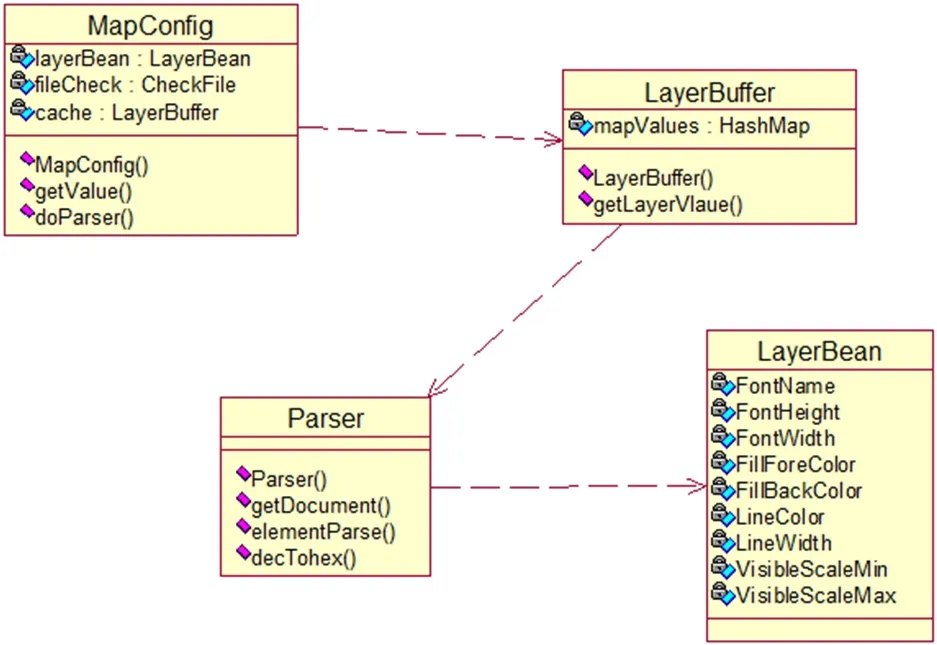
图1:SXW 类图框架

图形数据解析完毕,接着需要装载SVG 地图。通过loadSVGMap 函数先读出地图的基本信息跟SVG 内容,并按照每条基本信息构造SVG 的名称,并将其作为索引写入svgMap 哈希表内,也将相对应内容写入svgMap 的内容中。接着doParser 调用缓存处理模块驱动XML 文件的解析,数据缓存器自行维护一块缓存数据,采用名称—内容方式存储数据。数据缓存器在服务器启动时自动建立唯一实例,并从Oracle 数据库中的缓存数据存储表中读入所有数据。调用方传入数据名称,缓存器负责从缓存区中读取相对应的数据,并以byte 数组方式返回请求的内容。如果请求的数据不在缓存区中,调用方可以从数据库中读取相应内容,并将读出的内容写入到缓存器中,以便下次调用的时候可以提高性能。数据缓存器不负责读取请求的解析,不负责访问数据库,仅仅用于查找、匹配、读取、写入数据。
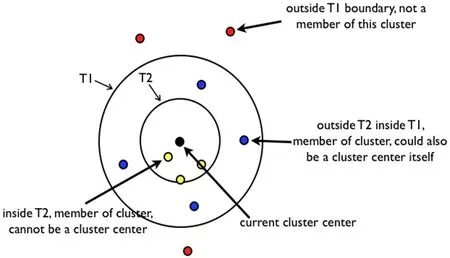
图2:canopy 算法概念图
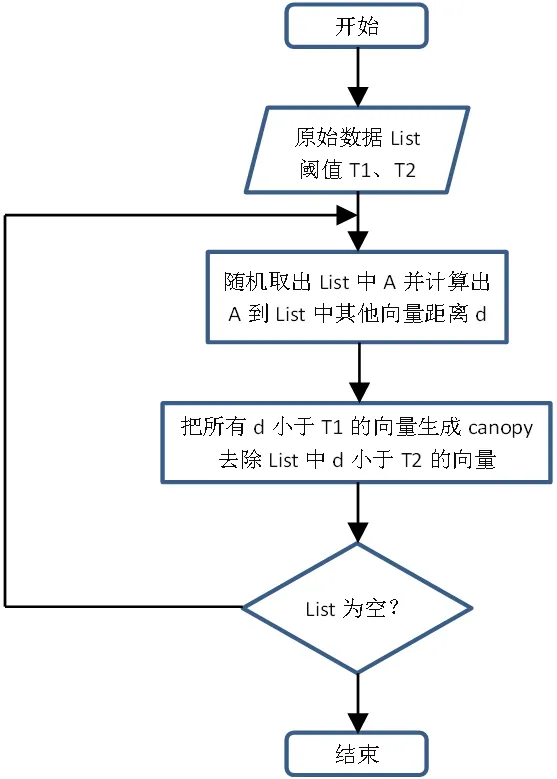
图3:canopy 算法流程图
调用Parser.elementParse 解析XML 文档元素生成Bean。使用compose 函数进行组装,从结果集中取出所有的SXW 文件名、province、city、Datalink 值,建立mapConfig,使用doParser() 方法传入SXW 文件名,设置LayerInfo,按照对应的Datalink 取得Wing_LayerInfo 表中LayerInfo 的其他值,设置对应的LayerInfo 类中的各个值,按照查询出的列数和行数进行双循环,查询出Wing_BlockInfo 中对应的各个块的内容,构造BlockInfo,并将其传入svgFactory,svgFactory 返回SVG 内容,完成组装。
2 K-means算法数据挖掘
在SXW 文件解析过程中,要对所有的SVG 图形图像元素及属性进行特征提取和数据挖掘,以提高整个系统查询的效率和准确度。可以采用K-means 算法来进行基于划分的聚类方法的数据挖掘。
其算法过程如下:
(1)从N 个SXW 解析文件随机选取K 个SXW 解析文作为质心。
(2)对剩余的每个文件测量其到每个质心的距离,并把它归到最近的质心的类。
(3)重新计算已经得到的各个类的质心。
(4)循环重复2~3 步直至新的质心与原来质心相等或小于指定阈值,算法结束。
具体实现如下:
(1)输入k,data[n]; 选择k 个初始中心点,例如
c[0]=data[0],…c[k-1]=data[k-1];
(2)对于data[0]….data[n],分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3)对于所有标记为i 点,重新计算c[i]=;
(4)重复2、3 步,直到所有c[i]值的变化小于给定阈值。
当目标函数达到最优或者达到最大的迭代次数就终止算法。针对不一样的距离度量,目标函数是会有差别的。当采用欧几里得方法计算距离度量时,目标函数一般通常采用最小化对象到其簇质心的距离的平方和,如下:
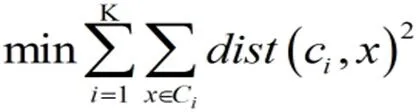
当采用余弦相似度时,目标函数一般为最大化对象到其簇质心的余弦相似度和,如下:

K-menas 算法试图找到使平均误差准则函数最小的簇。若潜在的簇是凸形状的,那么簇间的区别就会比较明显,而且若簇大小相近时,那么使用K-menas 算法的聚类结果比较理想。K-menas 算法的优点在于算法时间复杂度O(tKmn)和样本数量线性是相关的,因此,当在处理大数据集时,该算法高效、伸缩性较好。但其不足在于该算法要事先确定簇数 K,同时对初始聚类中心、“噪声”、孤立点敏感,因此,该方法不适合非凸面形状的簇或大小差别很大的簇。
3 使用Canopy 聚类算法改进数据挖掘
当数据的条目很多、数据向量其维度很大、包含多个属性,或者在进行数据挖掘时无法事先就判定应该聚成多少类,无法进行K值的设定时,就要采取另外的途径,改进聚类算法,采用Canopy算法。
3.1 Canopy算法的主要思想
Canopy 算法把数据挖掘分为两个阶段,具体来说,阶段一,使用一个简单粗糙的距离计算方法来产生具有一定数量的可重叠的子集,设定一个距离阈值,当计算的距离小于这个阈值的时候,就把数据向量归到此子集,也就是canopy。每个数据向量有可能存在于多个canopy 里面,每个数据向量至少要包含于一个canopy 中。同一个canopy 中的样本数据向量彼此间还是存在相似性,有可能被分为同一个类。由于距离计算方式是粗糙的,因此不能够保证性能(计算精确度)。但是通过允许存在可叠加的canopy 和设定一个较大的距离阈值,在某些情况下可以保证该算法的性能。
3.2 创建Canopy算法
创建一个普通的canopy 算法的概念图与简单步骤,如图2所示。
(1)从SVG 元素工厂生成相应数据库表的SVG 元素,获取对应的SVG 元素数组。原始数据集合列表按照一定的规则进行排序,初始距离阈值为T1、T2,且T1>T2。T1、T2 的设定可以根据用户的需要,或者使用交叉验证获得。
(2)在数据集合列表中随机挑选一个数据向量A,运用粗糙距离计算方式计算A 与列表中其他数据向量之间的距离d。
(3)根据第2 步中的距离d,把d 小于T1 的样本数据向量划到一个canopy 子集中,同时把d 小于T2 的样本数据向量从候选中心向量名单,也就是数据集合列表中移除。
(4)重复第2、3 步,直到数据集合列表为空,算法结束。
创建canopy 算法的流程图如图3所示。
阶段二,可以在阶段一的基础上应用传统聚类数据挖掘算法,比如贪婪凝聚聚类算法、K 均值聚类算法,当然,这些算法使用的距离计算方式是精准的距离计算方式。但是因为只计算了同一个canopy 中的数据向量之间的距离,而没有计算不在同一个canopy的数据向量之间的距离,所以假定它们之间的距离为无穷大。例如,若所有的数据都简单归入同一个canopy,那么阶段二的聚类挖掘就会退化成传统的具有高计算量的聚类算法了。但是,如果canopy不是那么大,且它们之间的重叠不是很多,那么代价很大的距离计算就会减少,同时用于分类的大量计算也可以省去。进一步来说,如果把Canopy 算法加入到传统的聚类挖掘算法中,那么算法既可以保证性能,即精确度,又可以增加计算效率,即减少计算时间。
Canopy 算法的优势在于先进行数据预处理,在数据预处理中,使用粗糙距离计算方法将数据分到几个可重叠的子集中,再而只需计算在同一个重叠子集中的数据向量,以此来减少数据计算量。
3.3 Canopy算法实施
使用Canopy 算法对SVG 向量数据进行聚类分析,涉及到以下几个过程:
(1)将SXW 序列文件进行向量化转换。使用sequence2TFVectors 方法将信息转换为<词ID,词频>的向量形式,每一个词ID 就代表了一个变量的坐标,而这个词ID 对应的词频即为该变量值,每一个词组成的位置信息则转换为了一个稀疏变量,SXW 序列文件便转换为了稀疏矩阵。

Input 用于输入的序列文件路径,analyzerClass 是使用的Lucene 解析器,Output 指具体的输出目录。
(2)运行canopy 算法初始化聚类重心。使用canopy 算法API对向量化后的文件初始化聚类中心。这里CanopyDriver 方法需要设置的三个重要参数为距离选择,以及阈值T1,T2 的取值。这里选择的是适合文本分析的余弦距离公式,比如T1 为0.6,T2 为0.4。
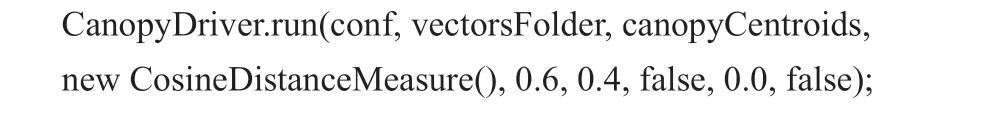
(3)运行kmeans 算法对SVG 信息进行聚类。在运行完了canopy 方法后,便要进行kmeans 算法,利用canopy 生成的结果作为初始聚类中心,由于此时聚类中心数已经确定,则不需要设置k值,最终的聚类数会根据收敛阈值变化而变化。

其中涉及到重要的参数设置,收敛阈值为 0.3,迭代次数为100。
(4)调用ClusterDumper 类将最终的聚类结果转换为可以读懂的信息,由于聚类结果是序列文件,而且是以词ID 的形式出现的,因此需要将在文本向量化过程中生成的dictionary 文件关联至该方法。

(5)利用dump 接口对聚类结果进行解析。执行完第3 个过程后,生成了一个序列文件保存结果,这个序列文件的key 为进行比较的两组向量的ID 信息,value 为这两组向量的距离。我们只需要通过SequenceFile.Reader 将距离信息读出,然后进行排序,即能得到最终结果。
4 结论
基于 SVG 的图形系统结合了基于图像内容和基于图像特征的挖掘检索与应用,在 SVG 图形库非常庞大的情况下,从SVG 图形基本信息的 XML 文件中采用K-means 和Canopy 算法进行聚类数据挖掘,包括文本向量处理部分的参数设置、Canopy 与K-means算法的收敛阈值参数设置,以及向量相似度算法的距离度量选择,为提高检索、解析速度提供了一种方法。
猜你喜欢
商品与质量(2019年34期)2019-11-29
测控技术(2018年5期)2018-12-09
电力与能源(2017年6期)2017-05-14
信息安全研究(2016年4期)2016-12-01
摄影之友(影像视觉)(2016年2期)2016-08-16
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
中国信息化·学术版(2013年1期)2013-05-28
