
基于Spark的农产品智能推荐系统研究
2020-02-04 06:32沈黄金朱大洲王辉刘蕾
电子技术与软件工程 2020年21期
沈黄金 朱大洲,2* 王辉 刘蕾
(1.黑龙江八一农垦大学 黑龙江省大庆市 163000 2.农业农村部食物与营养发展研究所 北京市 100081)
近年来农产品电子商务发展迅速,根据商务部发布的信息,2019年前三季度我国农村网络零售额达1.2 万亿元,同比增长19.7%,全国农产品网络零售额2824.7 亿元,同比增长了26.4%[1],农产品电商规模逐渐增大。而对于农产品电商企业的分析表示,多数企业仅依靠传统的B2C 模式进行商业营销,没有对用户需求进行针对性的营销[2],农产品智能推荐系统的出现可以把用户在平台上留下的大量行为数据进行分析,预测用户需求,为用户提供个性化的推荐服务。
推荐系统的关键在于推荐算法的实现。推荐算法通常分为六大类,分别是基于内容的推荐,基于人口统计学的推荐,基于知识的推荐,基于社区的推荐,基于协同过滤的推荐以及混合推荐[3],其中使用最为广泛的是基于协同过滤的推荐算法[4]。协同过滤算法主要分为基于用户的推荐算法User-Based CF 和基于物品的推荐算法Item-Based CF。基于用户的协同过滤算法是通过计算用户之间的相似性,将与目标用户相似度较高的用户喜欢的商品推荐给目标用户。基于物品的协同过滤则是计算物品之间的相似,将与目标用户喜欢的物品相似度较高的物品推荐给目标用户[5]。
推荐系统要在海量的产品和服务中发掘出最适合用户的一小部分内容,它要处理的数据量十分巨大,对实时性也有很高的需求,电商网站淘宝每日就需要处理十亿计的商品浏览、购买和收藏数据,所以推荐系统在架构和算法方面面临着巨大的考验,面对规模庞大的数据集,往往需要消耗计算机大量内存和运行时间[6],在单机上实现这些推荐算法需要漫长的运行周期,不能得到及时的反馈和更新。因此,通过在Spark 平台上并行化实现推荐算法的方式就能很好地提高计算效率。另外在电商系统中,用户的隐式反馈数据和显示反馈数据通常不超过项目总数据的百分之一[7],数据的稀缺性也是推荐系统需要解决的重要问题之一,王雪蓉等人提出了将用户行为关联聚类的方式可以更好地实现推荐效果[8]。本文将通过EM 算法将用户行为关联聚类,在Spark 平台上并行化运行协同过滤算法来解决农产品推荐系统实时性以及数据稀缺性问题。
1 Spark相关技术
Spark 的核心部分是Spark Core,主要由三部分组成:
(1)Spark Context:应用的执行和输出都是通过Spark Context来完成的。
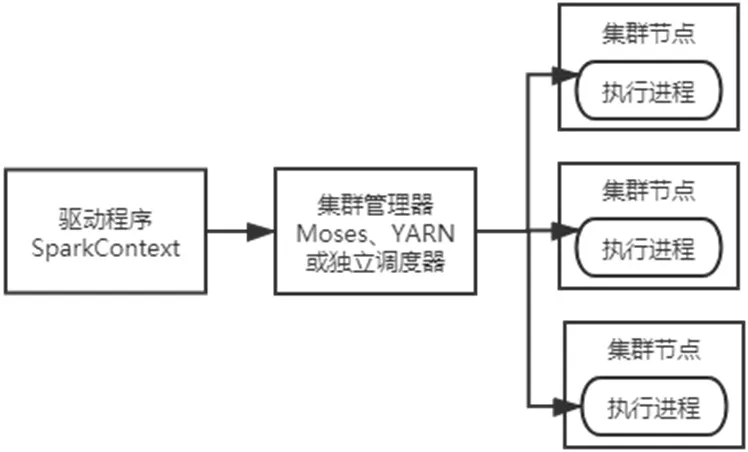
图1:Spark 应用程序框架
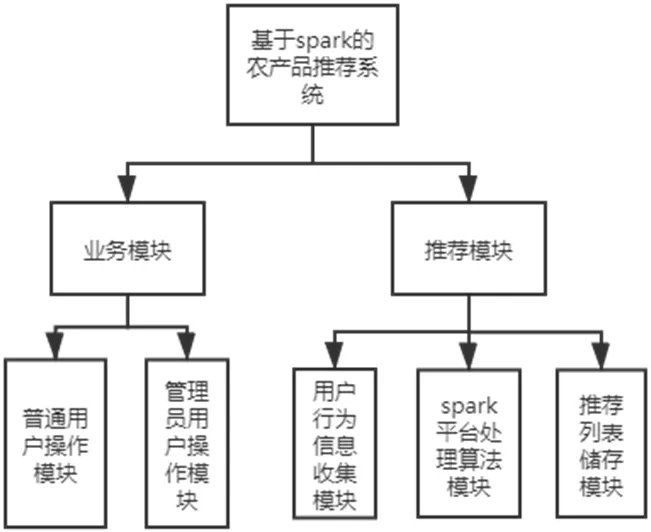
图2:系统功能模块设计图
(2)计算引擎:计算引擎由DAG、RDD 以及节点上的执行器组成,RDD 是Spark 的核心抽象模型,是一个只读的分布式数据集,可以通过转换操作在转换过程中对RDD 进行各种变换[9]。
(3)部署模式:Spark SQL 和Spark MLlib 也是Spark 体系中的重要部分,Spark SQL 提供了用于处理结构化数据的API,支持Hive,RDD,JSON 和JDBC 等多种数据源,Spark MLlib 提供了Spark 的机器学习库,包含了常用的机器学习算法和工具,还包含了算法的底层优化和高层次的管道API。
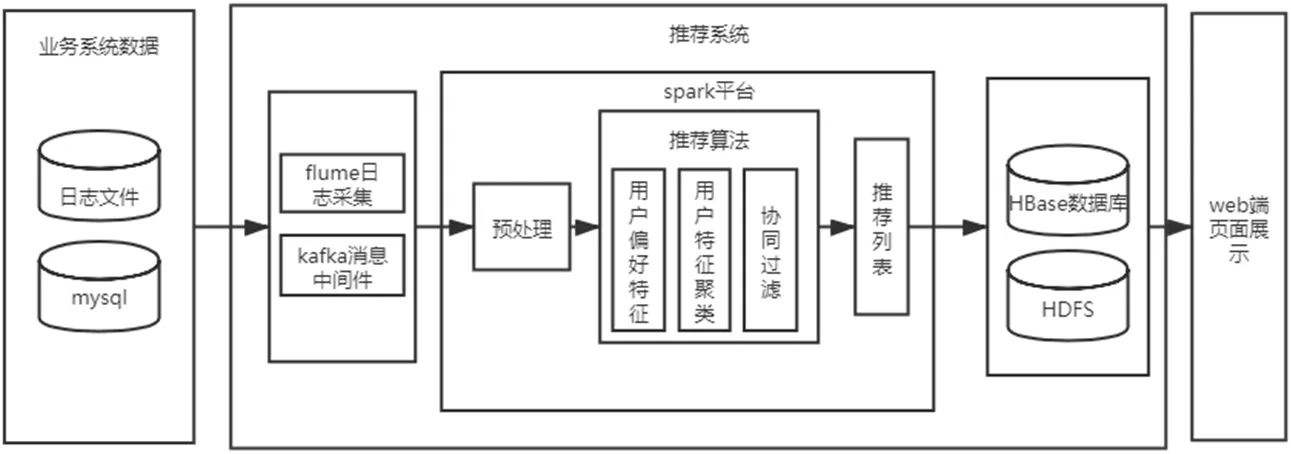
图3:系统架构图
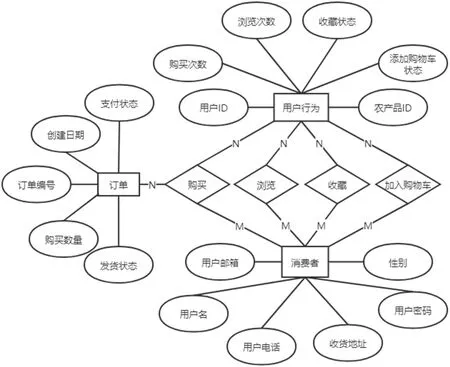
图4:消费者E-R 图
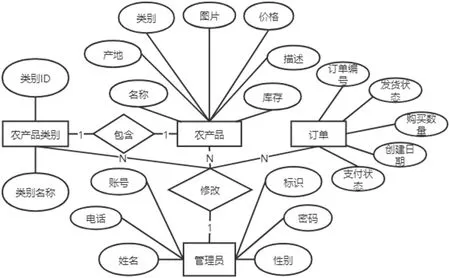
图5:管理员E-R 图
在Spark 中,提交给Spark 执行的计算任务被称为应用,一个应用是由一个任务控制节点和若干个作业构成的,当执行一个应用时,任务控制节点Driver 会向集群管理器申请资源启动Executor,发送应用程序代码和文件,然后在Executor 上执行任务,运行结束后将执行结果返回给任务控制节点Driver,写到HDFS 或者其他数据库中。Spark 计算程序框架如图1所示。
2 系统设计
基于Spark 的农产品推荐系统主要分为两大模块,一是系统的业务模块,二是系统的推荐模块。如图2所示。
系统业务模块有普通用户操作模块和管理员用户操作模块两大类,系统推荐模块使用的是Spark 大数据计算框架进行数据处理和模型训练,分布式文件系统进行数据的储存和加载。系统通过在web 埋点页面中“埋点”监督用户行为,当用户点击加载某个页面时,获取用户ID、商品ID 以及用户行为等参数保存到数据库中。将获取到的数据加载至hdfs 分布式文件系统,并基于SparkContext读取和形成RDD,基于RDD建立用户模型和农产品模型,得到用户-农产品的预测评分,形成推荐列表保存到数据库。系统架构图如图3所示。
3 系统算法设计
系统用EM 算法将用户聚类划分成不同用户簇,在不同用户簇的基础上并行化实现基于物品的协同过滤算法。基于物品的协同过滤算法认为能引起用户兴趣的项目,一定与之前评分较高的项目相似,因此首先计算用户偏好模型,构建用户-农产品评分矩阵,然后计算农产品之间的相似度,利用相似度得到用户对农产品的预测评分。
3.1 计算用户偏好模型
用户行为数据分为隐式反馈数据和显示反馈数据,本系统将使用隐式反馈数据来计算用户的偏好模型。首先将用户在浏览网页过程中的点击、收藏、购买和加入购物车的用户行为,构成用户的偏好集合:IA={A1,A2,A3,A4},设置wi为用户对不同偏好特征的偏好权值,其中得出用户偏好模型为然后用熵权法确定不同偏好特征的权值:
(1)将用户Ui的偏好特征表示为i*4 阶矩阵(bij)i*4,bij表示用户i 在第j(j=1,2,3,4)个特征上的权值,用公式(1)和(2)来标准化处理数据。

(2)计算偏好特征中第j 项的熵值。

(3)计算偏好特征中第j 项的权值。

通过以上方法即可得到每一种用户偏好特征的权值。
3.2 EM算法将用户聚类
得到用户偏好模型后,使用EM 聚类算法对用户进行聚类。EM 算法先通过猜测隐含数据,基于观察数据和猜测数据一起来极大化对数似然求解模型参数。接着基于当前模型参数继续猜测隐含数据,继续极大化对数似然求解模型参数,不断迭代下去直到算法收敛即得到最终模型参数。EM 算法在一定程度上解决了原始数据的数据缺失问题。具体实现过程如下:
(1)首先将用户偏好模型划分到集群的各个节点上,在不同节点计算任意两个用户的相似度,将相似度较高的两个用户合并成一类。
(2)根据公式(5)计算每一类的相似性。
(3)使用Shuffle 函数划分类别,将不同类别缓存到内存中去。
(4)根据公式(6)对参数进行迭代,直到完成聚类。
(5)清除中间数据,将结果储存在不同节点上。
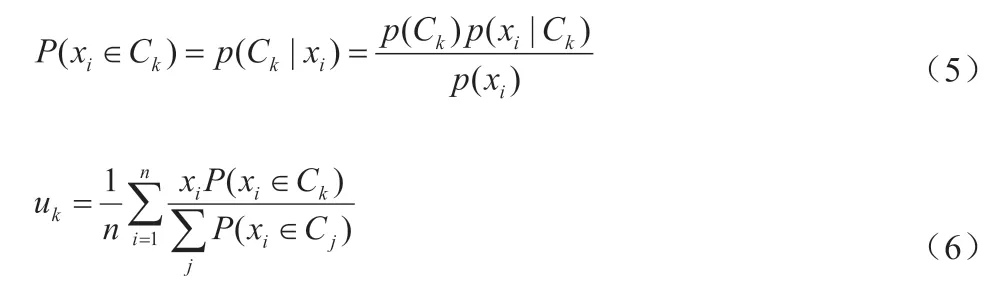
3.3 计算农产品的相似度
计算相似度主要有三种方法:余弦相似度、修正余弦相似度和皮尔逊相关系数。本文使用了皮尔逊相关系数计算两个农产品之间的相似度,首先找出对农产品i 和农产品j 都有评价的所有用户,将所有用户对所购买的农产品的评价作为一个向量,计算两个向量之间的皮尔逊相关系数来计算两个农产品间的相似度sim(i,j)。公式(7)是皮尔逊相似度的计算公式,集合U 代表同时对农产品i 和j进行评分的用户集,和分别代表农产品i 和农产品j 所获得所有评分的平均值,通过调用Computer Pearson()函数来进行两个农产品之间相似度的计算。
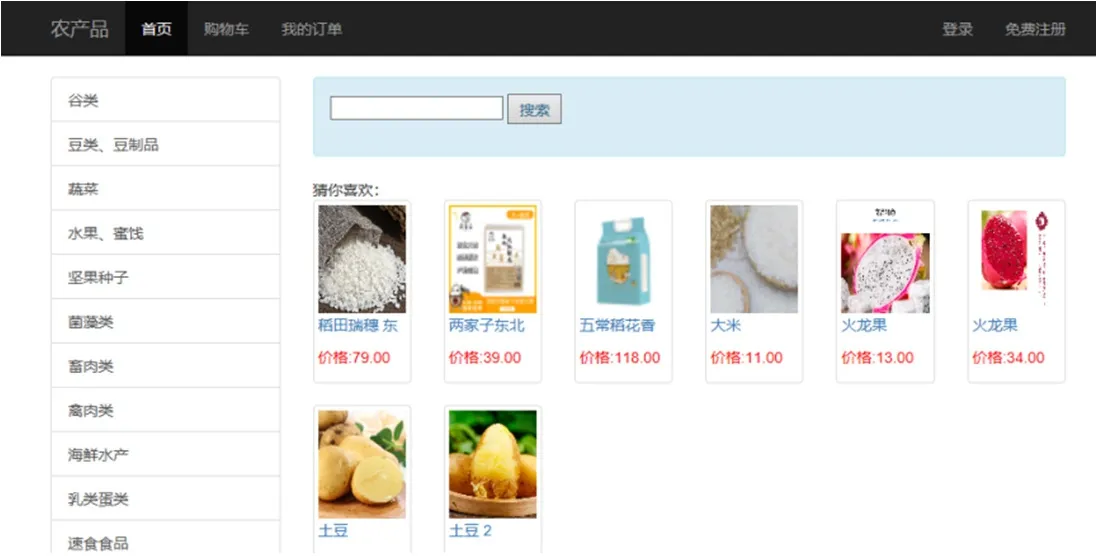
图6:农产品推荐系统的推荐与搜索页面
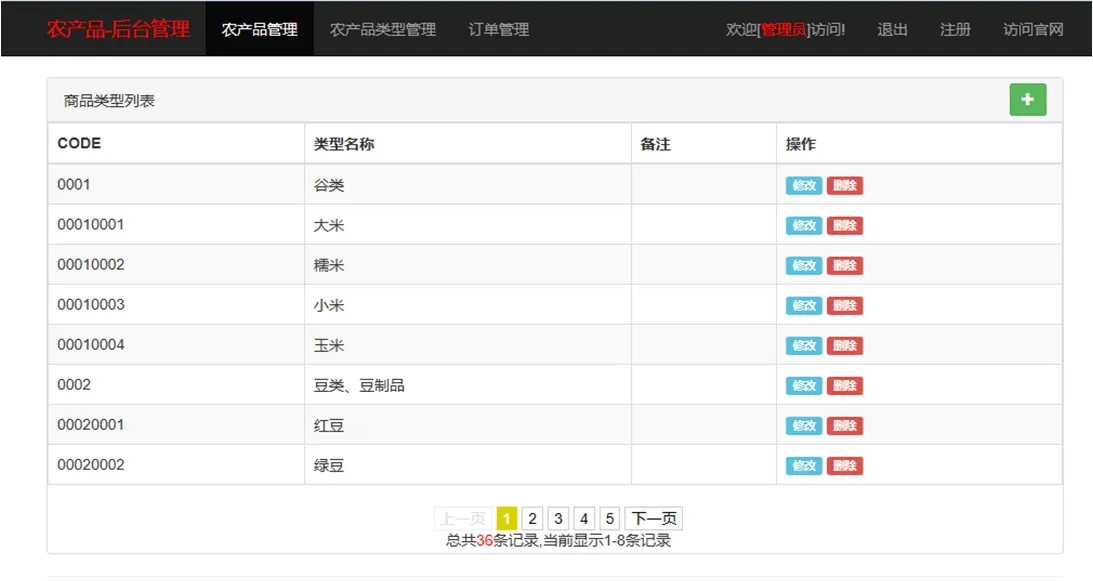
图7:农产品管理页面
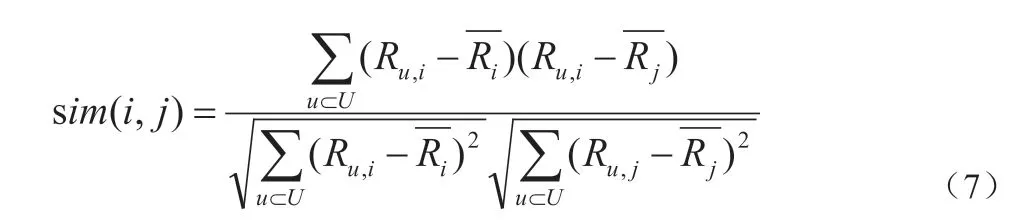
3.4 Spark平台并行化算法
将协同过滤算法并行化运行在Spark 分布式平台上,首先将数据加载到HDFS 分布式文件系统中,FLume 将从HDFS 中采集到的日志发送到Spark 集群。并经过预处理和算法建模等方式,对用户和农产品形成预测评分,形成推荐列表推送到用户手中。详细过程为:
(1)搭建Hadoop 平台与Spark 平台,将数据存放至Hadoop的分布式文件系统HDFS 中;
(2)根据用户的行为计算用户特征偏好权值,并储存;
(3)对用户进行聚类,将不同用户簇以及相应的用户-农产品评分数据存放至不同结点;
(4)并行运行协同过滤算法;
(5)预测用户-农产品评分;
(6)形成推荐列表。
4 系统业务模块
系统的Web 端业务模块包含了农产品查询、农产品管理、用户管理和农产品推荐等功能模块。有管理员和消费者两类操作人员,管理员身份登录可进行后台管理操作,即对农产品和农产品种类的添加、删除、查看和更新,以及对订单的管理和个人信息的修改。普通消费者登录后可通过农产品类型以及关键字查询农产品,查看农产品详细信息,对农产品进行购买、收藏、添加购物车等操作。系统E-R 图如图4 和图5所示。
根据E-R 图建立出具体的数据库表如下:
(1)用户信息表,包括用户名,用户ID,用户密码,用户性别,用户邮箱,用户电话,用户地址,用户类型;
图8:订单管理页面
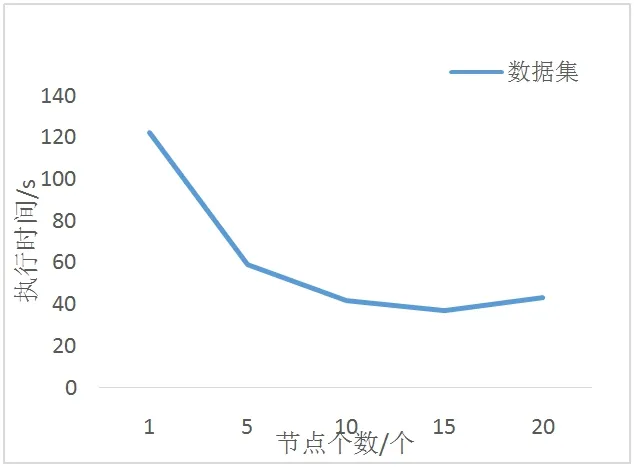
图9:不同节点个数的性能表现
(2)农产品类别信息表,包含农产品类别ID,农产品类别名称;
(3)农产品详细信息表,包含农产品名称,产地,类别,价格,库存,描述,图片,创建时间等;

表1:算法运行结果
(4)订单信息表,包含订单编号,创建日期,购买数量,发货状态,支付状态,用户ID 等;
(5)用户行为信息表,包含用户ID,农产品ID,浏览次数,收藏状态,添加购物车状态,购买次数等。
Web 前端部分使用了html/css,javaScript,bootstrap 技术,后台使用了ssm 框架开发,数据库使用的是mysql。图6、图7 和图8 是系统的部分Web 端页面。
5 系统性能验证
用公开数据集对该农产品推荐系统进行以下两方面性能研究:
(1)验证本文实现的推荐算法与传统算法相比,推荐效果是否有提升。
(2)验证基于Spark 平台的分布式实现,对算法的扩展性是否有提升。
5.1 验证过程
在实验集群中设置一个master 节点和两个slaves 节点,三个节点分别布置在CPU i5-5200U 四核处理器,内存为4GB 的主机上,操作系统为CentOS-7。首先在master 主节点中安装和配置Hadoop环境、spark 环境、Scala 环境以及JDK 环境,本试验采用的是Hadoop2.6.0、spark2.1.0、Scala2.11.8、jdk1.8.0,然后使用scp 命令将主节点中配置好的的Scala 和jdk 拷贝到两个slaves 从节点。
搭建好集群环境后,将数据存放到HDFS 分布式文件系统中,Spark 会生成一个全局常量SparkContext,从HDFS 中读取数据。TextFile()函数将从HDFS 中读取的数据形成一行一行的RDD。一个RDD 是一个只读的分布式数据集,可以通过转换操作在转换过程中对RDD 进行各种变换,Spark 通过RDD 弹性内存处理,将计算结果储存到HDFS 中,同时通过农产品建模、用户建模和智能推荐模块对数据分析处理。
实验数据来自阿里巴巴天池大数据平台提供的公开数据集UserBehavior.csv,一共20 万条行为记录。字段包含了user_id(用户ID)、cate_id(商品ID)、btag(用户行为),用户行为包含pv(浏览)、fav(收藏)、cart(加入购物车)和buy(购买)。
5.2 验证结果
5.2.1 准确度(Precision)、召回率(Recall)计算及运行时间分析
准确率是实际应用中最重视的指标之一,它直接决定了推荐的质量,准确率的定义如公式(8),召回率的定义如公式(9)。R(u)是算法根据训练集得出来的N 个推荐农产品集合,T(u)是用户在测试集上喜欢的农产品集合。
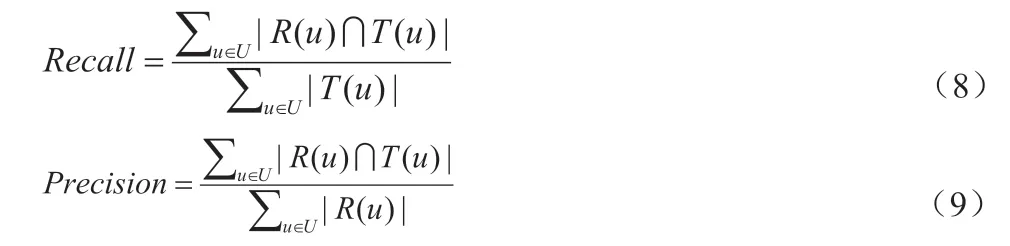
从表1看出,相比于传统的User-based CF和Item-based CF而言,本文的基于EM 聚类的协同过滤方法在准确率上分别提高了21.7%和17.21%,在召回率上分别提高了7.87%和2.84%。
5.2.2 算法扩展性测试
本测试分析了EM 聚类协同过滤算法在Spark 集群不同节点个数下的性能表现。
在计算性能方面,从图9 可看出在Spark 平台上运行的算法,可以通过增加节点的方式来提高计算效率,使算法具备一定的可扩展性。当集群节点个数增加到15 个以上时,算法的执行时间便不再减小。
6 总结
本文设计开发了一种基于Spark 平台的农产品智能推荐系统,系统使用基于EM 聚类的混合协同过滤推荐算法,算法集成运行在Spark 分布式计算平台上,通过实验对比分析,与单独使用基于用户的协同过滤和基于物品的协同过滤相比,本文使用的方法显著提高了算法的运行时间和准确率,并可以通过增加节点的方式提高算法的扩展性。在大数据环境下,Spark 平台基于EM 聚类的协同过滤农产品推荐系统能为用户提供针对性推荐,为农产品的购买和销售问题提供有效解决方案。
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2021年7期)2021-07-28
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中国卫生(2016年5期)2016-11-12
电子设计工程(2015年6期)2015-02-27
生物进化(2014年2期)2014-04-16
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
