
面向私有云平台的日志收集与分析系统设计
2020-02-04 02:04张文燕温俊阳
电子技术与软件工程 2020年20期
张文燕 温俊阳
(1.南京中兴新软件有限责任公司 江苏省南京市 210012 2.杭州海康威视数字技术股份有限公司 浙江省杭州市 310052)
1 引言
随着云计算技术的快速发展和广泛应用,越来越多的企业将IT基础设施迁移到私有云上,以更低的成本获得更高效、弹性、可靠,且优于公有云安全性的IT 服务。因此,私有云的应用和规模也随之扩大,对日常运维提出了更高的挑战。
构成私有云平台的各分布式服务进程在运行时会记录大量运行状态、访问及安全日志,为运维和开发人员了解系统运行状况、排查故障提供了大量信息。然而,随着云平台规模的扩大,其分布式系统节点不断增加,运行于各节点上的服务进程也不断增加,从而导致日志的分散化和海量化,使得日志查找和检索异常困难。集中化、自动化的日志收集和分析平台成为解决这一问题的有效方案。
开源的分布式日志收集和分析平ELK[1](Elasticsearch、Logstash和Kibana)是目前业界采用的主流解决方案。本文将ELK日志系统应用于开源云平台0penStack[2],构成私有云平台的日志收集和分析系统,通过统计系统日志量,针对系统运行中日志量较大、且只增不减的问题,提出了日志数据磁盘占用量优化方案。
2 ELK日志收集和分析系统架构
ELK Stack 是由三个开源组件Elasticsearch、Logstash 和Kibana构成的一套分布式日志收集和分析解决方案,可完成分布式日志的实时收集、解析、传输、存储、检索、分析、告警及可视化等功能。最简单的架构如图1所示。
Logstash 是Jruby 开发的数据收集、过滤、扩展、传输的通道,可通过其丰富的插件配置应用于分布式数据处理领域。常用的插件如input 和output 类的file、http、redis、kafka、rabbitmq、elasticsearch、tcp、udp、syslog 等,分别完成数据源端的收集和终端的发送;filter 类如grok、ruby 等完成数据的过滤和扩展。具有多种数据类型访问和弹性扩展的特点。
Elasticsearch 是基于全文搜索引擎Apache Lucene 构建的实时分布式搜索引擎,提供对数据的存储和分析功能,支持Restful API和集群部署,具有高可靠性、易扩展、节点自动发现、索引分片和副本机制。
Kibana 是专门为Elasticsearch 设计的数据可视化Web 平台,它可以在Elasticsearch 的索引中查找、交互数据,并生成各种维度的图表。
3 私有云平台的日志收集和分析系统部署实践
OpenStack 是一个开源的云计算管理平台,由Nova、Cinder、Neutron、Glance、Ceilometer、Keystone 等组件共同为私有云和公有云提供弹性的计算、存储、网络等服务。基于OpenStack 构架了私有云平台,考虑私有云平台需支持大规模部署(可达500 节点)的分布式系统,且日志类型不限于OpenStack 组件的日志,还包括访问日志、安全日志以及系统日志等,如messages、httpd日志等,日志量很大。最简架构ELK Stack 无法满足系统日志分析的需求,部署于该平台的ELK 分布式日志收集和分析系统架构如图2所示。

图1:ELK Stack 最简架构图

图2:私有云平台ELK Stack 架构
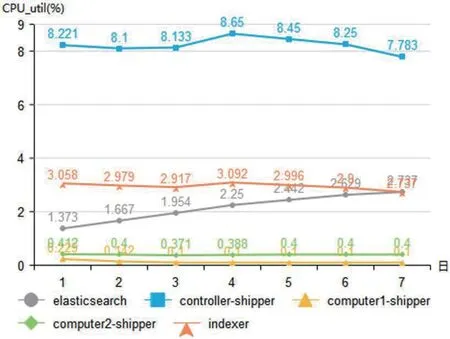
图3:各进程日均CPU_util
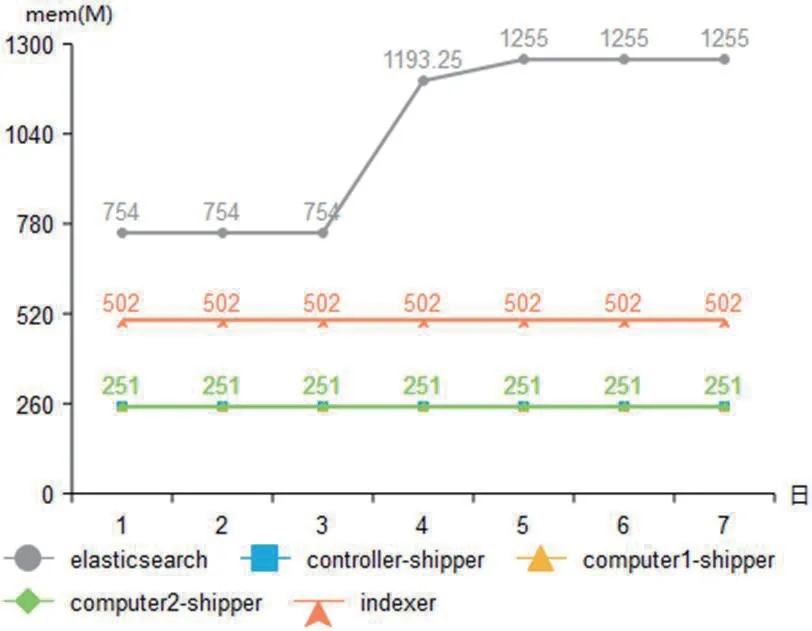
图4:各进程日均内存使用量

图5:删除和备份日志流程图
实践部署系统中Logstash 配置为shipper 和indexer 角色:shipper 驻守在各被管理节点上,完成各节点日志的收集、过滤和解析,以减少传输通道中的日志量,将日志解析的计算量进行负载均衡;indexer 部署于三个节点上,以负载均衡方式完成数据透传。开源流处理平台Kafka[3]通过Zookeeper[4]构成集群作为信息流传递的缓存,实现负载均衡以提高可靠性和吞吐量。Elasticsearch 通过自身的集群功能由三节点构成集群,共同完成数据存储,并对外提供索引和搜索的功能,提高数据存储的可靠性和数据处理效率。Kibana 部署于一个节点上,完成数据的可视化呈现和用户交互。实验系统配置如表1所示。

表1:私有云平台日志收集和分析系统实验配置

表2:elasticsearch日志数据日增长量

图6:优化后elasticsearch 的日志数据占盘空间统计
4 私有云平台的日志收集和分析系统优化
为了将该私有云平台的日志收集和分析系统应用于大规模环境(500 以上计算节点),对系统日常运行的资源占用情况进行统计。
4.1 CPU使用率和内存使用量的统计
CPU 使用率和内存使用率的监控,需要在Linux 系统安装sysstat 包,使用其中的pidstat 命令分别对进程logstash-shipper、logstash-indexer、elasticsearch 以10 秒间隔周期监控持续7 天的CPU 使用率(CPU_util)和内存使用率(mem_util),再计算日平均使用率。因Kibana 使用率取决于用户负载,未计入统计。各进程对CPU 和内存的日平均使用统计如图3-4所示。
私有云平台日志收集和分析系统的负载是日志量,服务的复杂和增加,平台节点规模的增加,都会导致日志量增加。分析以上数据与日志量的关系,统计各节点落盘日志量大小关系为controller >computer2 >computer1。可见logstash-shipper 和logstash-indexer 的内存使用量与日志量关系不大,都保持在固定值;CPU 使用量与日志量正相关,尤其controller 节点的logstash-shipper CPU 使用率占比相对太高,需要考虑优化。Elasticsearch 的CPU 使用率随时间推移,有逐渐增高趋势,内存使用量基本保持在恒定值。
4.2 Elasticsearch日志数据磁盘占用量统计和优化
私有云平台的日志通过logstash-indexer 传输到elasticsearch 后,elasticsearch 会对原始数据建立索引,并在其data 目录下保存索引文件和原始数据。原始数据可配置为不保存,若有重建索引的需要,则需要保留原始数据。在保留原始数据的前提下,统计data 目录日增长量,以评估大规模环境对磁盘空间的需求,统计7日增长量如表2所示。
规模为15 个计算节点的系统,日均新增数据量3.74G,预估500 节点系统日均新增数据量124.76G;且日志量只增不减。数据量删减是必不可少的。因而设计了通过elasticsearch API 按日志保存时间,阶梯式备份和删除日志数据量的算法,如图5所示。其中提供配置项:
log_days_to_live:表示日志保留天数,<0 表示不删除日志;
backup_days_to_live:表示备份日志保留天数,<0 表示不进行日志备份。
该算法通过Linux 系统的定时工具crontab 设置为每日定时执行一次,设置log_days_to_live=2,backup_days_to_live=-1,对elasticsearch 的data 路径统计占盘空间如图6所示。
执行效果可以保证占盘空间最多不超过9G,有效保障了系统磁盘空间使用的稳定性,提高系统可靠性。
5 结语
集中式自动化的日志管理是对大规模分布式系统运维的有效方案。本文对OpenStack 的私有云平台设计了集群式、负载均衡的ELK日志收集和分析系统,提高系统可靠性和吞吐量;并统计系统占用资源情况,分析其与系统负载的关系;指出Logstash-shipper的CPU 使用率较高,且与日志量正相关,elasticsearch 的CPU 使用率也有随时间推移增高的趋势,需要进一步优化;各进程内存使用量与日志量相关性不大;针对elasticsearch 存储日志数据量只增不减的问题,设计了阶梯式日志数据删除和备份算法,实验表明该方法可按需控制日志数据占盘量保持在可接受范围内,提高系统可靠性。
猜你喜欢
华人时刊(2021年13期)2021-11-27
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
心声歌刊(2020年4期)2020-09-07
电子制作(2019年13期)2020-01-14
综艺报(2019年5期)2019-03-18
小学生(看图说画)(2017年6期)2017-11-06
汽车文摘(2015年11期)2015-12-14
电子设计工程(2014年19期)2014-02-27
中国建设信息化(2011年2期)2011-09-22
