
基于文本信息的SparkSQL处理研究
2020-02-02 06:46史媛
电子技术与软件工程 2020年15期
史媛
(山西机电职业技术学院 山西省长治市 046011)
1 前言
近年来,大数据技术已经深入到生活的方方面面,大数据处理技术更是以前所未有的速度在向前发展。在大数据处理技术中,Spark 技术取得的成就引人注目。Spark 是快速通用的大规模数据处理引擎,它是基于内存的、分布式的大数据处理框架,和Hadoop中的MapReduce 类似,都是对数据进行处理,处于同一个层面,但是Hadoop 允许部署在一些低端的硬件上,这就造成了Hadoop在运算过程中的速度受限于最低速的硬件,而Spark 是面向内存的大数据处理引擎,基于内存的运算速度远远大于基于磁盘的运算速度,相当于“高富帅”,因而Spark 越来越被重量级的数据企业所青睐。
在Spark 中,主 要 有SparkSQL、SparkStreaming、GraphX、MLlib 四个组件,其中,SparkSQL 是Spark 用来操作结构化数据的组件,通过SparkSQL,用户可以使用SQL 或者Apache Hive的HQL 语言来查询数据,它支持多种数据源类型,如Hive 表、Parquet 以及JSON 等。SparkSQL 为Spark 提供了SQL 借口,还允许开发者将SQL 语句融入到Spark 应用程序中。本文就SparkSQL在图书信息上的应用做简单介绍。
2 问题描述
图书馆中的图书藏量十分庞大,要从中分析图书的相关信息,比如:统计各种分类中图书数量、统计图书借阅量、统计读者借阅情况等。图书馆的管理人员就能够根据这些分析出来的信息得出相应的结果,从而做出对应的决策,例如:下架借阅量低的图书、增加受欢迎图书类型的购书量、举办图书推荐活动吸引读者等,以此来增加图书馆的人流量和借阅量。图书馆中图书数据、借阅数据十分庞大,采用以往的手段来统计,费时费力,可以将数据用Spark技术处理,运用SparkSQL 组件计算相关信息。
3 解决步骤
3.1 将图书相关信息文件转换为DataFrame数据集
图书信息中有图书表——存储图书相关数据、读者表——存储读者相关数据、借阅表——存储借阅相关数据,原始数据文件都不是SparkSQL 能处理的格式,需要转换为SparkSQL 能处理的格式——DataFrame 数据集。
DataFrame 是以RDD 为基础的分布式数据集,和传统数据库的二维表格类似,它是以列方式存储数据的,每一列都带有名称和类型,这和以往以行方式存储数据的数据表不同,它对数据的内部结构有非常强的描述能力。SparkSQL 处理的对象就是DataFrame。
选择通过反射机制创建DataFrame。

图1:DataFrame 创建

图2:各类图书借阅量排序结果
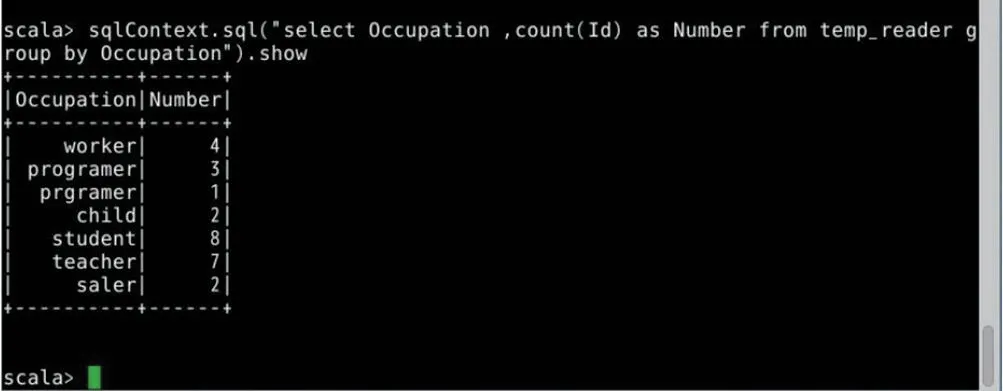
图3:各类职业读者数量

图4:各类图书价格总和
首先,在集群上将文件上传到HDFS 上,以图书文件为例。
hdfs dfs -put Book.txt/Book_Spark/data
第二步,进入Spark 环境,定义对应的样本类。
case class Book(Id:String,Name:String,Price:Int,Publisher:String,A uthor:String,Classification:String)
第三步,加载文件,转换为RDD
scala>val rdd=sc.textFile(“/Book_Spark/data/Book.txt”).map(_.split(“,”)).map(p=> Book(p(0),p(1),p(2).trim.toInt,p(3),p(4),p(5)))
第四步,使用toDF()方法转换为DataFrame
scala>val book=rdd.toDF()
第五步,将DataFrame 注册为临时表
scala>book.registerTempTable(“temp_book”)
scala>book.show
运行结果如图1。
从图1可以看到图书文件中的信息,这表明已经将图书文件成功转换为DataFrame。读者文件和借阅文件转换DataFrame 采用上述同样的方法进行转换,转换后的DataFrame 名称分别为reader 和borrow。
3.2 数据处理
上面步骤完成后就可以使用SparkSQL 进行数据处理了。为了分析读者喜好哪一类图书,可以看看哪一类图书的借阅量最大。
3.2.1 统计各类图书借阅量,降序排序
scala>sqlContext.sql(“selecth.Classification,count(h.Id) as count from temp_book h join temp_borrow k on h.Id=k.Bid group by h.Classification order by count”).show
根据图2统计结果,图书馆在购置图书的时候可以偏向借阅量比较大的图书类型。对那些节约量比较低的图书,可以适当调整书架位置或者是下架。
3.2.2 查看借书读者信息
scala>sqlContext.sql(“select r.* from temp_reader r join temp_borrow b on r.Id=b.Rid”).show
从查看借书读者的结果可以分析,经常借阅图书的读者年龄、职业等。
3.2.3 统计男女读者数量
scala>sqlContext.sql(“select sex,count(Id) from temp_reader group by sex”).show
3.2.4 统计借阅图书读者年龄段数量
scala>sqlContext.sql(“select count(r.Id) as Less_then_10 from temp_reader r join temp_borrow b on r.Id=b.Rid where r.Age <10”).show
年龄可以更换,各个年龄段的数量都可以统计。
3.2.5 统计各类职业读者数量
scala>sqlContext.sql(“select Occupation,count(Id) as Number from temp_reader group by Occupation”).show
从注册登记读者性别数量中可以分析出,经常或者有意愿来图书馆看书、借书的人是男读者多还是女读者多;从年龄统计上可以看出借书的是哪个年龄段的人比较多;从注册登记读者职业数量上来看,哪类职业的读者更有意愿来图书馆看书或借书,综合借书读者信息的统计结果进行分析,这样,图书馆在举办相关活动的时候主题可以有所偏向,比如,可以举办相应的图书展览会,作者读者见面会、主题活动等吸引更多没有注册登记读者来参加活动,更加符合读者年龄、类型和读者看书意愿,在推荐图书的时候目标性更强,活动举办的效果更好。
另外,图书馆还可以统计图书的一些信息。
3.2.6 对图书价格进行降序排序,看看图书最高的价格和最低的价格
scala>book.orderby(book(“price”)).show(5)
或者
scala>book.sort($“price”.desc).show(5)
3.2.7 统计各类图书数量
scala>sqlContext.sql(“select count(Id),Classification from temp_book groupby Classification ”).show
3.2.8 求各类图书价格总和信息
scala>sqlContext.sql(“select Classification,sum(price) from temp_book group by Classification”).show
根据图4结果可以帮助图书馆对图书进行调整和编制购置预案等。
4 总结
可以看出,SparkSQL 在处理结构化数据上有着良好的处理能力,Spark 技术的Scala 语言比较精炼,能够很高效、准确地进行数据处理,SparkSQL 不仅仅可以使用Scala 语言实现,还可以融入到Python、Java 语言中,而且SparkSQL 还可以结合Hive 等大数据工具进行更复杂的数据处理和分析,即在大数据生态圈里进行数据的采集、处理和分析。本文中的案例只是单独运用了SparkSQL组件进行数据处理,原始数据来源于文本文件,没有存储到数据库中,这有缺陷,比如,年龄的更改和计算,文本文件去更改就比较麻烦,但是如果放入到数据库中就可以使用SQL 语句很方便地更改或计算年龄。学生要掌握SparkSQL,前提是对数据库和SQL 语言要十分熟悉,并且能够灵活运用。在以后的教学中,可多多增加Python 和Java 语言融合Scala 的案例和结合Hive 等大数据工具分析处理数据的案例,接近工程实际,灵活运用SparkSQL。
猜你喜欢
数学小灵通(1-2年级)(2022年6期)2022-06-17
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
小学生学习指导(低年级)(2019年3期)2019-04-22
快乐语文(2018年12期)2018-06-15
数学小灵通(1-2年级)(2017年6期)2017-06-22
中国惯性技术学报(2015年1期)2015-12-19
测绘科学与工程(2013年3期)2013-03-11
