
基于聚类分析的异常数据检测
2020-02-02 06:46丁卫东
电子技术与软件工程 2020年15期
丁卫东
(德州职业技术学院 山东省德州市 253000)
随着网络技术和应用的飞速发展,网络资源的双刃剑效应日渐凸显。网络数据窃贼、黑客侵袭以及各种恶意攻击行为,严重损害了人们的利益。在大数据环境下,海量的数据流需要不断的去更新和处理,不可避免的给网络异常检测带来了巨大的挑战。为此,在这一趋势下迫切需要探索出一种能够检测异常数据的机制,该机制不仅能够检测网络中的常见故障,而且能够及时发现攻击行为、判别不法行为。关于网络异常数据检测算法,学者进行了一系列探索,朱应武、杨家海、张金祥(2010)的基于流量信息结构的异常检测方法[1];张玉清、吕少卿、范丹(2015)的在线社交网络中异常帐号检测方法[2];周鹏、熊运余(2017)的基于数据挖掘的网络状态异常检测[3];丁建立、邹云开、王静等(2019)提出的基于深度学习的ADS-B 异常数据检测模型[4]。这些算法都为异常数据监测提供了依据,但是适用范围有限,计算过程复杂。为此,本文以聚类分析为基础,提出异常数据检测算法,旨在为网络中异常数据的检测提供新的方法。
1 基于聚类分析的异常数据检测算法
本文对异常数据检测算法进行研究,主要是采用K-means 算法构建网络正常行为模型后,通过将正常行为模型与待检测数据进行对比,从而判断数据是否异常。
1.1 网络正常行为模型
K-means 算法的核心思想是给定数据集合和需要的聚类数目k时,通常情况下,用户指定 k,根据某个距离函数进行迭代运算,把所有的数据分入k 个聚类中,直到类簇的数据点与类簇中心的平均距离最小位置[5]。
该算法的基本步骤如下:
(1)从n 个样本集里随机选取k 个样本作为初始聚类中心;
(2)对于样本集里的其他样本点,计算它们与初始聚类中心的距离,根据距离最近原则,将其分配到聚类中心所在的类,具体距离采用欧几里得距离公式(1)计算;
(3)通过计算每一个新类的均值,从而更新聚类中心;
(4)重复第(2)和第(3)两步骤,直到所有的样本点分类不再改变为止;
(5)将(4)中最后得到的簇集V 进行初始化操作,从中得到一个最大的cNi,将Ni 划分为q 个子簇,每一个子簇对Ni 进行聚类操作,来计算误差平方和大小,进而选择出具有一个子簇,该子簇具有最小总数误差平方和;
(6)重复第(5)步的步骤,直到得到k 个簇。

式中:Dist(Xi,Xj)——样本点Xi与Xj之间的距离;Xik、Xjk分别表示第i 和第j 个样本第K 个指标的取值;m——待聚类的个体特征,本文取4。其中,Dist(Xi,Xj)越小,说明样本之间的性质距离就越相近。
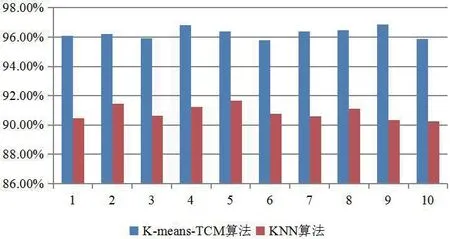
图1:两种算法的检测率

图2:两种算法的检测率与误报率平衡关系
采用K-means 算法对网络异常数据进行检测,主要是构建网络正常行为模型,判定待检测的数据是否正常,进而进行异常检测。其中,Xik、Xjk在网络异常数据检测中表述不同时刻的数据属性度量值。
在K-means 算法中,计算效率为O(tKmn),其中,t 为迭代次数,K 为类簇格式,m 为参与聚类的特征属性个数,n 为待处理的数据集大小。但是K-means 算法中需要对类簇中心进行迭代修正,因此算法的复杂度较高,且无法对其聚类信度进行检验,不适合于直接对网络异常数据进行检测。
1.2 异常数据检测模型
针对K-means 算法的不足,本文采用直推式信度机(TCM)形成一种新的K-means-TCM 算法,该算法改进了K-means 聚类算法异常数据检测算法。直推式信度机核心思想是对样本归属已知类别的可信程度评价,利用检测函数得到P 值。实际上,P 代表一个概率,若P 越大,表示这个将要分类的样本被分配到某一类已知样本集的概率越大,刚好能够弥补K-means 算法的不足。
K-means-TCM 算法是将直推式信度机与K-means 聚类算法结合的综合性算法,具体是首先根据现有的样本集,计算将要分类的样本点与样本集的空间距离,然后采用直推式信度机对P 值进行计算,从而对分类样本进行分类。K-means-TCM 算法步骤如下:
(1)采用1.1 中的网络正常行为模型将正常数据集划分成h个簇,采用欧氏距离公式分别计算h 个簇与待测样本点的簇中心距离,将距离最近的一个簇作为检测样本点加入到正常数据集中;
(2)根据奇异值,计算得到待测样本点相对于正常类别的P值;
(3)判定P 值,如果P 值小于设定的阈值(通常为0.05),那么置信度(判定异常的指标)就为1-τ。
关于奇异值计算公式如下:

式中:
k——参数,即最近距离数目。
待测样本点i 相对于类别m 的P 值为:(3)

式中:
#——集合的“势”,主要表示有限集合的元素个数;
αi——待分类样本i 的奇异值;
αj——集合中任意样本的奇异值;
N——集合的个数。
2 基于聚类分析的异常数据检测算法仿真
2.1 数据来源
为了验证基于聚类分析的异常数据检测算法有效性,采用1999DARPA 数据集包作为原始数据集。1999DARPA 数据集包中有5 周时间采集的sniffer 网络流数据,本次仿真分析主要是以“inside”流数据为主,即网关路由与受害主机之间的数据。第一周和第四周中没有含有任何恶意攻击数据,在研究中作为正常行为模型的训练集;第二周、第三周和第五周是正常和异常的混合数据集,其中异常数据中包含DoS 攻击、U2R、R2L 等201 个攻击,为此将混合数据集作为待检测网络数据。
2.2 仿真环境
本次算法仿真软件为MATLAB R2008b。仿真环境中,CPU为Intel Pentium4 3.20GHz,内存为2GB,操作系统为Microsoft Windows XP Professional SP2。
2.3 评价标准
在基于聚类分析的异常数据检测算法仿真分析中,本文采用检测率和误报率对算法性能进行评价,具体计算公式如下:
检测率(TPR):

误报率(FPR):

式中:
TP——将属于类别S 的样例正确地判定为属于S;
FN——将属于类别S 的样例错误地判定为不属于S;
FP——将不属于类别S 的样例错误地判定为属于S;
TN——将不属于类别S 的样例正确地判定为不属于S。
2.4 结果分析
异常数据检测的基本流程是数据采集、数据清理、正常行为模型建立、异常数据检测。通过对2.1 中原始数据进行清理,得到5000 条数据集样本。采用基于聚类分析的异常数据检测算法对数据集样本进行30 次检测。检测过程中,网络正常行为模型聚类个数为5,异常数据检测模型中最近邻数目k 为8,得到异常数据检测率以及误报率。
总体来说,本文提出的算法检测率较高,30 次检测的均值达到了96.73%,同时误报率也保持在一个较低的水平。由此可知,基于聚类分析的异常数据检测算法不仅能够增强异常数据检测的高检测率,而且能够保持较低的误差。
为了进一步检验基于聚类分析的异常数据检测算法的优势,将基于聚类分析的异常数据检测算法与传统的KNN 算法检测效果进行比较。具体是从数据集合中分别取10000 条正常的数据及1000条异常的数据,利用十折交叉验证,取90%作为训练分类器的训练集,剩下的10%数据作为测试集,用来验证不同异常数据检测算法的效果。检测过程中,聚类个数为5,最近邻数目k 为8。检测10 次后,两种算法的检测结果比较见图1所示。
由图1可知,本文提出的算法检测率明显高于KNN 算法。进一步对两种算法的检测率与误报率平衡关系进行仿真,结果见图2所示。
通过图2可知,本文基于聚类分析的异常数据检测算法,具有较高的检测率,较低的误报率,该算法能够有效地解决异常数据检测问题。
3 结束语
聚类分析在大数据处理中具有广泛的应用,但是针对海量数据背景下聚类结果不稳定和收敛速度较慢的问题。本文结合K-means算法优势与不足,提出K-means 算法与直推式信度机相结合的异常数据检测算法。通过仿真分析,基于聚类分析的异常数据检测算法总体检测率较高且误报率低,检测效果明显优于传统KNN 算法。随着大数据时代的深入发展,未来还需要对基于聚类分析的异常数据检测算法进行不断改进与优化,从而提高总体性能与应用效果,发挥其在数据检测方面的巨大优势。
猜你喜欢
湖南文理学院学报(自然科学版)(2022年2期)2022-05-06
世界科学技术-中医药现代化(2021年7期)2021-11-04
煤气与热力(2021年6期)2021-07-28
设备管理与维修(2020年14期)2020-08-12
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
管理现代化(2016年6期)2016-01-23
听力学及言语疾病杂志(2015年5期)2015-12-24
现代电子技术(2015年21期)2015-11-09
中国康复理论与实践(2015年7期)2015-05-09
