
基于粒子群算法的EFSM模型的测试用例自动生成
2020-02-02 06:46周燕彬
电子技术与软件工程 2020年15期
周燕彬
(湖南财经工业职业技术学院 湖南省衡阳市 421001)
从互联网刚开始出现,一直到现在,都是以飞速蓬勃的姿态在发展着。无论是电脑,还是手机等电子设备,都离不开软件的支持,它已应用到社会发展、人类生活、城市建设等各个领域。由于软件应用广泛,软件的质量也必须要得到保证。
总体上讲,软件测试是一个需要不断重复的工作,在条件不成熟时,软件测试大多数还是依靠人工,人工设计测试用例,然后手动执行这些测试用例,这样就会导致耗费大量的人力和物力,而且人并不能时时刻刻都高度集中精神,所以稍有疏忽就容易出现不必要的错误,没法保证百分之百的正确率。一旦软件的规模不在手工的承受范围之内,它所需要的开销也变得异常昂贵,也是没办法被接受的。因此,自动化软件测试被提出并成为一种倾向。其中,测试用例的自动生成是一个非常重要的部分,一个典型的测试用例生成方法是先创建一个软件的测试模型,然后基于这个模型来自动生成测试用例[1]。而经常用到的模型有有限状态机(FSM)和扩展有限状态机(EFSM),相对于有限状态机,后者增加了迁移、谓词条件和迁移被触发后的操作,因而更能准确地描述软件系统的动态行为。
尽管在基于EFSM 模型的测试用例生成上前人已经做了很多研究工作,但是实现有效的测试还存在一些挑战。由于一些不可行路径的转换之间的相关性,以及检测不可行路径的问题一般是不可判定的[1],因此,基于FSM 的测试生成方法不能直接用于基于EFSM 的测试。
1 EFSM模型
EFSM(Enhanced Finite State Machine),即扩展有限状态机。是在有限状态机(FSM)的基础上添加了上下文变量、谓词和操作,而有限状态机本质上是一个传感器,它是由状态、输入、输出组成的有限集合,其中输出和状态迁移、输入相关。一个EFSM 是由许多状态和状态之间的转换共同构成的。
EFSM 模型可用一个六元组(S,S0,V,I,O,T)来表示,其中:
(1)S 是逻辑状态集;
(2)S0∈S,是初始状态;
(3)V 是内部变量和环境变量有限集;
(4)I 是输入操作有限集;
(5)O 是输出操作有限集;
(6)T 是有限状态迁移集。
在EFSM 中,当机器的一个转换被采用时,就会发生状态转换。如果初始状态为source,且接收到输入input 并满足保护guard,则T 中每个迁移元素t 又可以表示为一个五元组<source(t),input(t),guard(t),operation(t),end(t)>,简化为<ss,i,g,op,se>,其中:
(1)source(t)是迁移t 的初始状态;
(2)input(t)∈I 为迁移t 上的激励事件,由若干个输入变量组成或者为空;
(3)guard(t)是称为保护的逻辑表达式,有的也称作守卫;
(4)operation(t)∈O 是迁移t 引起的操作,是由诸如输出语句和赋值语句之类的简单语句组成的顺序操作;
(5)end(t)是其结束状态。
当EFSM 处于某个迁移t 的初始状态source(t),接收到输入input(t)且迁移的保护条件guard(t)为true 时,就会执行该迁移的operation(t)操作,并将状态由初始状态source(t)转换到结束状态end(t)。
在过去几年中,基于EFSM 的测试用例生成有比较大的发展,这促使我对近年来自动化测试的现状以及基于EFSM 的测试用例生成技术进行了系统的调查。
到目前为止,各种搜索算法已经成功运用在EFSM 模型的测试用例自动生成上,文献[2]提出了利用禁忌搜索算法来对EFSM 模型生成测试数据,文中分析了测试数据的生成时间与路径之间的不同影响因素的相关性,从而得到影响生成效率的主要因素,作者还通过与遗传算法进行对比,验证了该算法的可行性。
文献[3]提出了将模拟退火算法的思想应用于EFSM 模型的测试用例生成中,分别对算法中的参数选取不同的值,来分析不同的参数设置对测试数据生成效率的影响,并对传统的模拟退火算法进行了改进,进一步提高了测试数据的生成效率。
2 遗传算法和模拟退火算法的优缺点
优化算法在自动化测试方面已经被证明是有效的[4],把优化搜索的原理运用到测试数据的生成中,就是把测试数据的生成问题转化为搜索和优化问题。
2.1 遗传算法
遗传算法实际上是一个优化搜索问题,首先从一个种群开始,按照适者生存和优胜劣汰的法则来寻找存活下来的个体,在不断的进化中,通过存活下来的优秀个体的繁衍,会产生出越来越好的一个种群。在每一代,通过判断适应度的好坏,从而挑选一部分优秀个体复制到下一代,即选择操作,另外还能对基因进行交叉以及变异操作,从而产生新种群。这个过程就像自然界中的进化过程一样,新得到的子代种群会比父代更适应环境,而整个进化过程中得到的最优个体就是问题的最终解。
遗传算法使用适应度值来进行评价,而且根据适应度值来进行一定的随机搜索,不一定能保证找到最优解,另外该算法在收敛于最优解的速度上可能会比较慢。
2.2 模拟退火算法
模拟退火算法是用固体退火的方式来模拟组合优化问题,其原理简要概括为:首先给固体升温,至温度够高,则内能越大,其内部的粒子则会进行快速的无规则运动,给固体降温时,则内能减小,粒子的运动速度降低,慢慢排列有序,最终固体处于常温时,则此时内能最小,粒子最稳定。用内能E 模拟为目标函数值f,用温度T 模拟成控制参数t,用来解决组合优化问题。
模拟退火算法虽然具有跳出局部最优解的能力,能够以随机搜索的方式从概率的意义上找出目标函数f 的全局最小点。但是,由于该算法对整个搜索空间的状况不了解,不能立即使搜索过程进入到最有希望的搜索区域,因此它的运算效率并不高,另外该算法对参数(如初始温度)的依赖性较强,且进化速度慢。
同样作为元启发式搜索算法,粒子群算法在寻找最优解方面存在一定的优势,因此尝试基于粒子群算法生成EFSM 模型的测试用例。
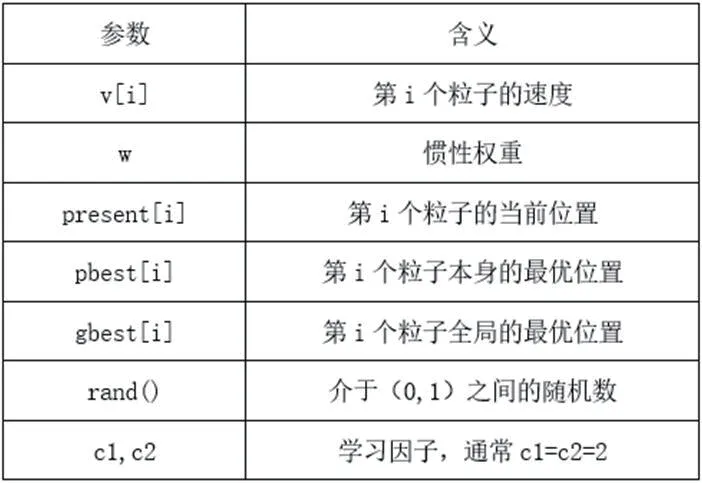
表1 :公式1、2 中各个参数及其含义

表2:生成的可执行路径
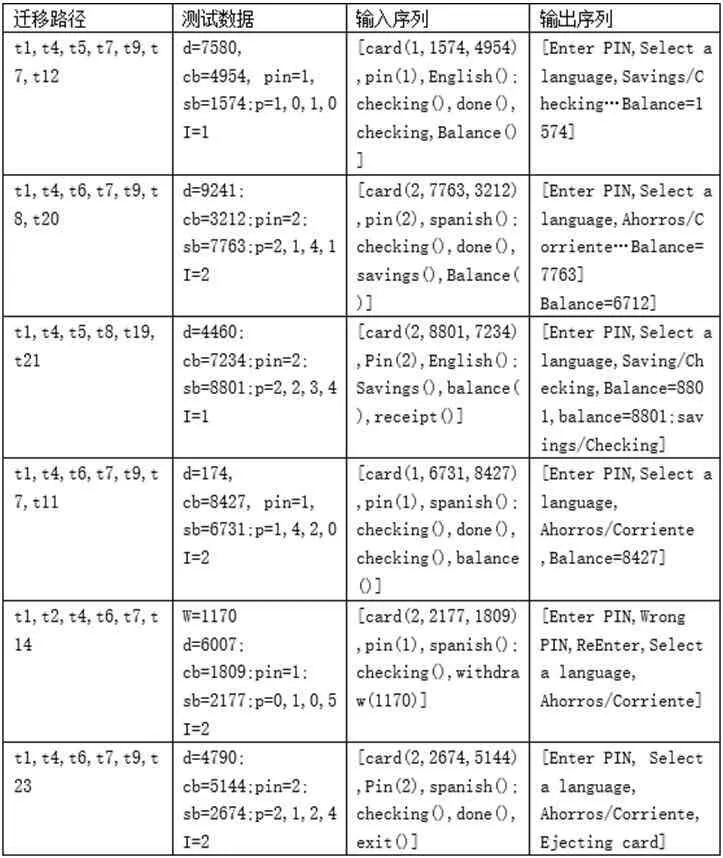
表3:ATM 模型上生成的部分测试数据
3 基于粒子群算法的EFSM模型的测试用例自动生成
3.1 粒子群算法的原理
粒子群算法(Particle Swarm Optimization,以下称PSO),是受到鸟类捕食的行为特征启发而得到的,有一群鸟在空中觅食,它们不知道食物在哪,但是它们知道自己距离食物有多远,它们只能慢慢去寻找,那么食物就是整个问题的最优解,而每一只去捕食的鸟就是在空间中进行搜索的一个个粒子。
在PSO 中,将需要被优化的问题的解看成是一个个粒子,每一个粒子都具有以下属性:位置X,速度V,它本身经历的最好的位置pbest,它在全局中所经历的最好位置gbest 和它本身的适应度值。每个粒子都包含着一个适应度值,它的作用是表示粒子的优劣程度,若适应度值越小,则表明粒子的位置更优,若适应度值越大,则表明粒子的位置更差。
以下公式1,2 表示的是当找到最优值pbest 和gbest 时,粒子更新自己速度和位置的依据。

公式中各个参数代表的含义如表1。
最初的粒子群算法是没有w 惯性权重这个参数的,即w=1,后来经过改进,加入了惯性权重,可以取不同的值,成为标准的粒子群算法。从之前的经验来看,如果惯性权重偏大,算法的全局搜索效果更好,而惯性权重偏小,则更有利于局部搜索。
公式中使用学习因子是为了提高算法的局部求精能力。
3.2 基于粒子群算法的EFSM测试数据生成实现流程
对于一个已经存在的EFSM 模型,根据生成的可行测试序列,将其作为指定的输入,通过粒子群算法,找到满足各个前置条件的变量的值,从而生成测试用例。下面主要介绍算法的具体实现流程:
(1)随机生成一组初始粒子群(包含多个粒子),即初始解来作为当前的解。而该初始解是根据EFSM 模型中存在的一条可执行迁移路径的event 中的输入变量来生成的。
(2)根据给出的适应度函数计算出每个粒子的适应度值,由此来评价它满足路径的执行要求与否,如若满足,则输出结果,说明测试用例生成成功,结束算法。
(3)如果不满足,则根据公式1 和公式2 更新粒子的位置和速度,并增加迭代次数。
(4)对新得到的粒子群重新进行适应度的评估。
(5)直到满足执行条件或者达到最大迭代次数。
3.3 基于粒子群算法的EFSM测试用例生成关键元素设计
3.3.1 群体规模

表4:三种算法生成测试用例迭代次数对比(单位:次)

表5:三种算法生成测试用例迭代时间对比(单位:秒)
不同的粒子群规模大小不同,而不同的粒子群规模对于最后的结果也可能产生不同影响,在设计可行性证明实验时,取种群规模N=100。
3.3.2 最大迭代次数
最大迭代次数即粒子群进行更新的最大代数,若是超过了这个数值还没有得到最优解,则表示实验失败。一般来说,都会在最大迭代次数以内产生一个最优解。这里设置Tmax=1000。
3.3.3 最大速度
即粒子在这个空间内运动时的最大速度Vmax。
3.3.4 权重因子
包括惯性因子w 和学习因子c1,c2。一般选取经验值,w=0.7,c1=c2=2。
3.3.5 适应度函数构造
构造适应度函数的方法一般有两种,一是层接近度法,二是分支距离法,本文则采用第二种方法来构造适应度函数。对于粒子群优化算法,构建适应度函数能够让其发挥出它的优化能力,从而去解决测试用例生成的问题,本文采用分支距离法来构造适应度函数。
3.4 实验过程及结果分析
为了验证本文中的测试序列自动生成方法是否有效,将该方法应用于ATM 模型(一个典型的EFSM 模型)的测试序列的自动生成中,为了生成测试序列,也就是可行迁移路径,而且要使最终得到的测试用例可以满足全状态-迁移覆盖标准,本文将ATM 模型中的所有迁移当做目标迁移,来寻找从初始前已出发,到达目标迁移的较短可行迁移路径的集合,生成的可执行路径的结果如表2。
从表2可以看出,ATM 模型最终得到了30 个较短测试序列,覆盖了EFSM 模型中的所有迁移。如表3所示。
进行实验时,选取ATM 模型,选取路径长度[4-50]范围内的若干条路径,为每条路径各取5 条不同的可执行路径,每条路径分别应用三种算法10 次,表4和表5分别表示用三种算法生成正确的测试数据所需要的迭代次数和平均迭代时间,这里仅仅列出了一部分数据。通过比较三种算法生成测试用例的平均迭代时间和迭代次数来判断粒子群算法是否更高效。
从表4和表5的数据可以看出,粒子群算法在测试数据生成的迭代次数少于遗传算法和模拟退火算法,而且时间上大大减少,提高了生成效率。
4 结论
本文提出了基于粒子群优化算法的EFSM 模型测试用例自动生成的设计思路,介绍了粒子群算法的原理、生成测试用例的具体的算法流程、参数设置等。通过实验,比较了遗传算法,模拟退火算法,粒子群优化算法在ATM 模型上生成测试用例的平均迭代时间,可以看出粒子群优化算法在ATM 模型的测试用例生成上的效率比遗传算法和模拟退火算法要高。
猜你喜欢
铁道通信信号(2020年6期)2020-09-21
北京航空航天大学学报(2019年9期)2019-10-26
测控技术(2018年3期)2018-11-25
传感器与微系统(2018年7期)2018-08-29
电测与仪表(2016年17期)2016-04-11
电源技术(2015年5期)2015-08-22
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
城市轨道交通研究(2015年3期)2015-02-27
黑龙江科学(2011年2期)2011-03-14
空间控制技术与应用(2010年5期)2010-12-23
