
基于BERT的用户画像
2020-01-18 05:52翟剑锋
电子技术与软件工程 2019年24期
文/翟剑锋
计算机和互联网技术的快速发展给人们的学习、生活带来了极大的便利的同时,也带来了数据爆炸式的增长。面对海量数据,信息处理的效率较低,人们往往没有办法快速获得精准数据。分析这些海量数据可以挖掘出用户基本的属性信息和潜在的兴趣偏好,给人们提供重大的帮助,用户画像及其相关技术在这种背景下应运而生。如何从数据中抽取中所需的用户特征,构建精准的用户画像值得进行深入研究。BERT模型对遮挡语言模型和下一个句子预测任务同时进行训练,能够更好的获取上下文信息,学习句内和句间关系。本文研究了基于BERT预训练模型的用户画像相关问题,在一定程度上能够解决一词多义问题,更好的抽取用户特征并进行实验分析。
1 相关工作
用户画像是指根据用户的属性、用户偏好、生活习惯、用户行为等信息而抽象出来的标签化用户模型。标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等。每个标签分别描述了该用户的一个维度,各个维度之间相互联系,共同构成对用户的整体描述,可以更容易理解用户,并且更方便计算机处理。如何通过一定的机器学习方法从预处理的数据中抽取出所需要用户特征,是构建用户画像的关键问题。简而言之,创建用户画像的过程就是依据所构建用户模型在用户信息中得到特征并将特征标签化的过程。
吴桐水和贺亮[1]基于决策树的航空公司客户流失分析,为航空公司客户流失采取改进措施。Slanzi,Balazs 和 Velasquez[2]对预测Web用户点击意图的方法,用逻辑回归提升推荐能力。Torres-Valencia,Álvarez 和 Álvaro[3]将支持向量机作为分类器提取用户的情感特征。Kuzma 和 Andrejková[4]使用神经网络模型提取用户偏好特征。蔡国永和夏彬彬[5]利用卷积神经网络捕捉文本情感特征和图像情感特征之间的内部联系,更准确地实现对图文融合媒体情感的预测。付鹏,林政和袁凤程等[6]提出基于卷积神经网络的方法解决短文本特征抽取及特征稀疏问题。
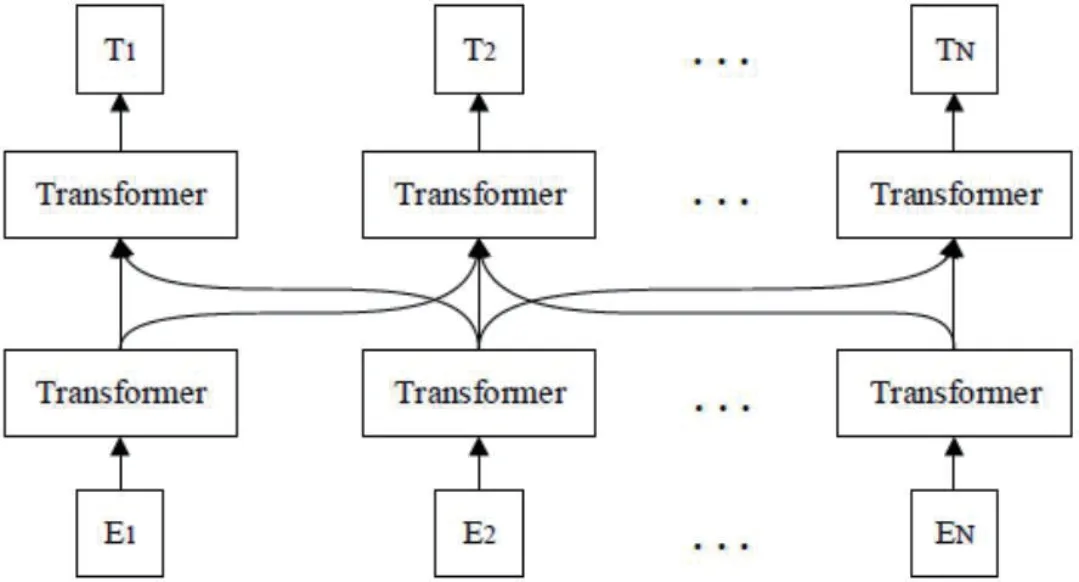
图1:BERT预训练语言模型
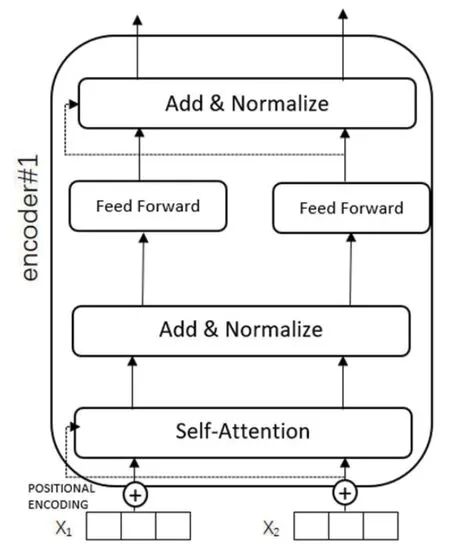
图2:Transformer编码器
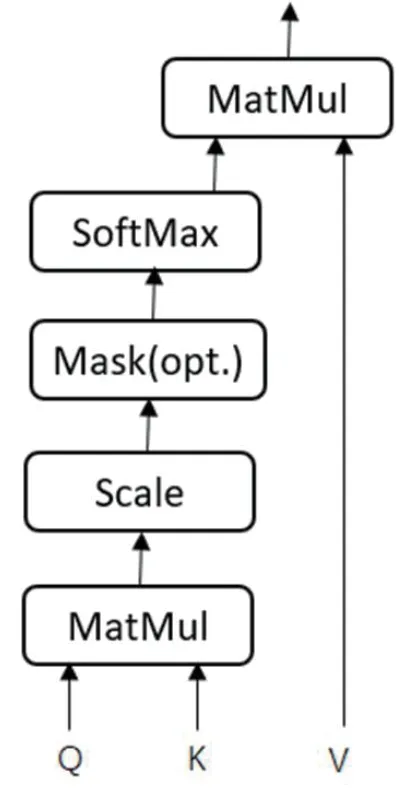
图3:自注意力机制

图4:流程图
近年来,随着深度学习在自然语言处理领域的快速发展,Bengio[7]等人提出词向量的概念,用低维的实向量表征词语的语义信息,并将语义相似的词语映射到向量空间中距离相近的位置。大多数现有的词向量已经获得了广泛的应用,但大多数词嵌入方法都是假定用每个词能够用单个向量代表,无法解决一词多义和同音异议的问题。多原型向量空间模型[8]是将一个单词的上下文分成不同的组,然后为每个组生成不同的原型向量。遵循这个想法,Huang[9]等人提出了基于神经语言模型的多原型词嵌入。Liu Y[10]等人采用潜在的主题模型为文本语料库中的每个词分配主题,并基于词和主题来学习主题词向量。李雅坤[11]引入词向量,共同与特征向量构成文本特征向量,构建基于搜索引擎的用户画像。BERT[12]预训练语言模型通常采用大规模、与特定任务无关的文本语料进行训练,使模型输出的词向量表示尽可能全面、准确地刻画输入文本的整体信息,为后续的具体任务微调参数初始值。本文利用基于BERT预训练语言模型来构建用户画像,通过TF-IDF值进行词向量语义加权得到用户特征,对用户特征用随机森林进行分类并进行实验分析。

表1:不同算法的分类性能
2 基于BERT的用户画像模型描述
2.1 BERT模型
为了获得更好的词分布式表示,Google提出的BERT预训练语言模型在11个NLP任务上的表现刷新了记录,充分利用词左右两边的信息,能够更好的解决一词多义问题,结构如图1所示。
为了更好的获取上下文信息,学习句内和句间关系,BERT模型对两个任务同时进行训练,分别是遮挡语言模型和下一个句子预测任务。遮挡语言模型不同于常见的利用上文预测下一个单词或者利用上文和下文预测中间词的语言模型,遮挡语言模型随机遮挡一定比例的单词,利用其余单词预测这些遮挡词,由于遮挡词的位置是随机的,被遮挡的词可能是句子的任何成分,避免模型利用数据集的偏差,从而强迫模型从句子整体学习上下文的信息达到双向编码的效果。
为了让模型拥有更好的语义理解能力,同时训练下一个句子预测任务来学习句子之间的特征。下一个句子预测任务可以等效成句子级的二分类问题,输入两个句子,判断第二个句子是不是第一个句子的正确合理的下一句。
BERT预训练语言模型使用 Transformer 模型的编码器部分,其每个单元仅由自注意力机制和前馈神经网络构成,一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取。这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能,可以更直接地捕捉词与词之间的关系,从而使序列的编码更具整体性,更能代表整个序列的含义。其结构如图2所示。
Transformer 中最主要模块的是自注意力部分。注意力机制可以描述为给定一个查询(Query)和一个键值表(Key-Value pairs),将Query映射到正确输入的过程,此处的Query、Key、Value和最终输出都是向量矩阵。输出往往是一个加权求和的形式,而权重则由Query、Key和Value决定,其输出向量不但包含该词本身,还包含其它词与这个词的关系,自注意力机制是指使用序列自身和自身进行注意力处理,即Q=K=V,其结构如图3所示,公式为:
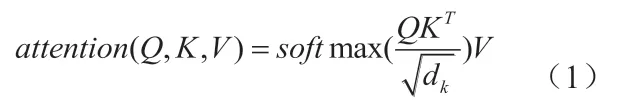
其中 均是输入字向量矩阵,dk为输入向量维度。
BERT预训练模型使用了由多个自注意力机制构成的多头注意力机制,扩展模型专注于不同位置的能力,用于获取句子级别的语义信息,如公式(2)(3)所示。
时序特征是自然语言的一个重要特征,而自注意力机制无法获取时序特征,Transformer采用位置嵌入的方式表示时序信息,如公式(4)(5)所示。
2.2 随机森林
随机森林是一种基于Bagging的集成学习算法,将多棵决策树进行整合来完成预测。对于分类问题预测结果是所有决策树预测结果的投票;对于回归问题,是所有决策树预测结果的均值。训练时,通过Bootstrap抽样来形成每棵决策树的训练集,则对于一个输入样本,有多少棵决策树就会有多少个分类结果,随机森林将投票次数最多的类别指定为最终的输出。假设N表示训练用例(样本)个数,M表示特征数目,随机森林的构建过程如下:
(1)输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
(2)从N中以有放回抽样的方式,取样N次,形成一个训练集,并用未抽到的用例(样本)作预测,评估其误差。
(3)对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据m个特征,计算其最佳的分裂方式。
(4)每棵树都会完整成长而不会剪枝;
(5)将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果。
2.3 基于BERT的用户画像模型
BERT模型主要分两个部分,一个是训练语言模型的预训练部分,另一个是训练具体任务的fine-tune部分。由于预训练过程需要耗费大量的运算资源,直接在Google发布的BERT预训练模型基础上对自有的数据集进行fine-tune。本文利用基于BERT预训练语言模型来构建用户画像,通过TF-IDF值进行词向量语义加权得到用户特征,对用户特征用随机森林进行分类,模型大体框架如图4所示。
3 实验结果与分析
实验数据集来源于中国计算机学会组织的大数据竞赛。实验数据包括10万条,提供用户历史一个月的查询词与用户的人口属性标签(包括性别、年龄、学历)作为训练数据,对新增用户的人口属性,即年龄、性别、学历的判断。
Google 提供的预训练语言模型分为两种,两种模型网络结构相同,实验中采用的是BERT-Base,默认使用12头注意力机制的Transformer,预训练词向量长度为768维,最大序列长度为128,每批次大小为64,学习率为5×10-5。
评价指标采用查准率(P),用于表示模型对样本分类的正确比率、召回率(R)用于表明模型对样本的识别程度。将基于BERT的方法同Word2Vec词向量、LDA+Word2Vec词向量的方法进行比较,三种模型都使用随机森林分类器对用户的基本属性进行分类,本文采用的方法的各项评价指标都要高于其它两种方法,具体如表1所示。
4 结束语
本文研究了基于BERT预训练模型的用户画像相关问题,BERT模型对遮挡语言模型和下一个句子预测任务同时进行训练,能够更好的获取上下文信息,学习句内和句间关系。相比于传统的词向量,BERT在一定程度上能够解决一词多义问题,更好的抽取用户特征。实验表明,基于BERT预训练模型在处理用户画像上能够达到较好的效果。由于数据集中文本的内容与用户属性存在一定的偏差,数据中的噪声较大,数据存在不平衡,需要进一步提高用户画像的分类精度。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
