
关于实体关系信息在答案选择网络中应用
2020-01-18 05:50毛鹏苗航
电子技术与软件工程 2019年24期
文/毛鹏 苗航
1 引言
答案选择任务是自然语言处理中重要的一类任务,它的目标是:给定问题句和答案句,判断答案句是否为问题句的正确答案。目前基于神经网络的模型已达到较好的效果,但仍存在一定的提升空间,因此,引入外部知识库信息成为了提升模型效果的重要突破点。
外部知识库信息在本任务中存在特殊的利用价值,探索适当的方式利用这些知识库中的实体信息和关系信息,可以有效优化模型。例如,在某些问答句中,否定答案在词汇、句子结构上与给定的问题更接近,现有的基于句编码向量相似度计算的神经网络模型可能为否定答案分配比肯定答案更高的分数,如果结合已经建立的知识库中的背景信息,可以根据其中的相关事实为肯定答案匹配到高于否定答案的分数。文献[1]目前证明了引入知识库实体信息的方法能够优化模型。然而,知识库中的关系信息目前还没有适合的方法在答案选择任务上应用。因此,本文就此展开工作。
在已有的研究中,结合注意力机制的神经网络模型可能因为问答句中噪声和冗余信息的干扰而产生误判,利用知识库中的实体关系,可以优化注意力机制,加强近义词之间的注意力权重,减弱矛盾词之间的注意力权重从而降低噪声的影响。同时,利用实体关系向量结合问答句上下文进行加权求和所得到的基于关系向量的问答句编码也能有效地丰富问答句编码信息。以上思路在自然语言推理中起到了比较理想的优化效果[2]。
2 相关工作
各类深层神经网络已经被广泛应用于答案选择任务中,例如:卷积神经网络(CNN )[3]、循环神经网络(RNN)[4]、长短时记忆网络(LSTM) [5][6]以及双向长短时记忆网络(BiLSTM) [7]等。深层神经网络结合注意力机制[8]是目前常见的通用模型。引入注意力机制的目的在于有效地考虑问答句之间的交互信息,提高问答句中相同或相似部分在句向量表示中所占的权重,从而降低问答句中冗余信息的影响。
文献[8]提出了结合双向注意力机制的BiLSTM网络,利用注意力机制建模问答句之间的交互信息,提高问答句中相似部分在句向量表示中的权重,从而降低问答句中冗余信息的影响。然而,深层网络模型中,单词通常基于空间词向量表示,问答句中有些词之间存在着矛盾关系,但因词语类型相同,上下文应用场景接近,这些词对应的空间词向量的空间距离比较接近。这类词在现有的注意力权重计算方法下,往往会被赋予较高的权重,从而导致模型的误判。
文献[1][9]引入外部知识库信息,把知识库向量编码入句向量中,丰富了句向量内容。本文受此启发,并借鉴自然语言推理任务中的主要思想,在句矩阵压缩为句向量的步骤中结合了知识库信息,优化了句中各单词的权重,从而提升模型效果。
3 模型
答案选择任务的目标是:给定一个问题句Q,模型对一组候选答案进行排序通用方法的步骤为:
(1)根据问答句中的单词获取对应的空间词向量,这些词向量组成了句子的空间词向量表示矩阵,使用BiLSTM分别对问题句和答案句的空间词向量矩阵进行编码,得到句编码矩阵;
(2)将所得的句编码矩阵使用双向注意力机制的方法进行处理,得到问答句之间的注意力矩阵;
(3)句编码矩阵与注意力矩阵相乘,得到问答句的句向量表示;
(4)将问答句的句向量输入全连接层,计算问答句的相似度。在基准模型的基础上,本文结合知识库关系信息,对基准模型进行优化,结合知识库中的实体关系向量,计算得到问答句逐词的关系矩阵Mr,利用问答句关系矩阵在步骤(2)对模型进行了优化,优化后得到融入知识库关系信息的问题句和答案句的句向量表示。
3.1 BiLSTM编码空间词向量

图1:整体模型结构
利用BiLSTM网络得到问答句的句矩阵表示。根据问题句、答案句中的单词,从空间词向量库中得到对应的词向量,组成的问答句矩阵为向量维度,分别表示问题句和答案句的长度),把句矩阵中的元素逐列输入BiLSTM模型中,利用BiLSTM对问答句进行编码:
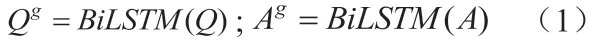
3.2 引入双向注意力机制
将问题句和答案句中的单词逐词进行向量相乘,计算得到双向注意力矩阵Mg:

对矩阵Mg进行逐行、逐列之间的归一化处理,得到权重矩阵α、β:

3.3 提取知识库关系信息
考虑利用知识库中关系信息,代替传统的最大值池化或平均值池化方法。问题句中第i个词和答案句中的j个词的关系向量为由外部知识库提供。rij对应的矩阵表示为对应的矩阵表示为指问答句之间的关系矩阵,元素计算方式为:

表1:分别在三种模型上进行实验

3.4 计算句向量表示
根据上文编码得到的问题句、答案句的句矩阵,利用注意力机制和知识库关系信息,对问答句中隐藏层词向量进行加权求和,池化得到问题句和答案句的句向量表示、q:

3.5 归一化处理
将问题句和答案句的句向量、q输入全连接层(softmax函数)进行二分类,优化目标为最小化交叉熵损失函数,端到端地训练整体模型:
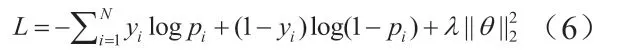
上式中,pi为归一化层输出,θ包含所有参数,是L2的正则化。
4 实验
4.1 数据
本文采用Wiki QA数据集[10]和TREC QA数据集[6]进行实验。WikiQA是目前最常用的开放域问答任务的数据集之一,大多数问答对来源于Wikipedia的QA系统。TREC QA同样是比较有影响力的公开问答数据集,大多数问题都比较简短,答案往往基于事实。
空间词向量来源于Glove向量集[11],Glove词向量集利用word2vec算法预训练出大量300维空间词向量,不同的维度指代单词不同的特点,如:词义、词性、词频等,Glove向量集将空间词向量存储在TXT格式的文件中,便于调用。
本文所使用的知识库关系向量来源于WordNet字典 [12]中的实体关系向量。WordNet字典由普林斯顿大学的研究者设计搭建的一个基于英语单词的词典。与普通词典相比,该词库不仅将单词以字母顺序进行排列,同时按照单词的意思组成单词网。该网络覆盖范围广,包括名词、形容词、动词、副词等。其中,不同词性的单词各自组成一个网络,每个网络都代表一类基本的语义,同时,这些网络之间也存在各种关系。WordNet库中包含一义多词、一词多义、单词类别、近义词、反义词等。本文取5个特征,组成关系向量,关系向量维度为5,对应5种不同的关系包括:近义词、反义词、上位词、下位词、同类词(有共同的上位词),5个不同的值分别表示5中不同关系的权重。
(1)近义词:指的是意思相近或相同的词,意思越接近值越接近1,越不相近越接近0,例如: [felicitous,good]= 1,[dog,wolf]= 0。
(2)反义词:如果两词语义相关且意思完全相反则取1,否取0[wet,dry]= 1。
(3)上位词: 如果前一个词指代的范围被后一个词包含,则称为两个词的关系为上位词,取值在0到1之间,值越大表示这类关系越重。例如: [dog,canid]= 0.875,[wolf,canid]= 0.875,[dog,carnivore]= 0.75,[canid,dog]= 0。
(4)下位词:如果前一个词指代的范围包括后一个词,则称这两个词的关系为下位词,取值在0到1之间,值越大表示这类关系越重。 例如:[canid,dog]= 0.875,[dog,canid]= 0。
“没个正形。”思蓉说,“我和你姐夫还真以为你们出了什么事情,下节目就一起跑过来,饭都没顾上吃。家里有吃的没有?”
(5)同类词:指的是两个词属于同一类型,有共同的上位词,但是两个词的语义完全不同。例如:[dog,wolf]= 1。
4.2 评估指标
文章采用的指标为:MAP(The Mean Average Precision)和MRR(Mean Reciprocal Rank),这两个指标被广泛应用于答案选择模型中,作为模型性能的评判指标。
4.3 参数设置
为了使实验结果更有具说服力,本文控制了无关实验变量,对于本文中所有搭建模型均采用相同的参数设置。深层神将网络的隐藏层设为200维,模型参数的学习速率为0.0005,训练时模型的丢失率设置为0.5,其他参数在 [-0.1,0.1]随机产生初始化值。进行归一化处理时L2正则化强度设置为0.0001。一个句子包含单词的极限为30。
4.4 实验结果
本文将三种不同的答案选择模型作为基准模型,并在不同的基准模型上进行优化处理。三种模型分别为:
(1)结合双向注意力机制后的双向上短期记忆网络,AP-BiLSTM模型;
(2)结合问题句对答案的单向注意力机制后的双向长短期记忆网络,CON-BiLSTM模型[13];
(3)结合外部知识库实体向量的双向长短期记忆网络,KA-BiLSTM模型[1]。在三种模型上反复进行实验,调整参数,比对结果,并取最优参数的多次结果取平均值作为最终的实验结果。
如表所1示,“r”指基准模型利用本文方法优化后的实验结果,括号中的数字指优化后模型所提升的值。
4.5 优化分析
知识库关系信息中反映了问答句中词与词之间的关系信息,弥补了空间词向量本身存在的不足,例如:某些词因为分类相似,使用语境相似,因此,对应的空间词向量的空间距离较近,但其语义互相矛盾,加入知识库关系信息后能有效降低之间的权重,减小问答句向量中的噪声和其他信息的干扰,关系信息还能把近义词之间的权重有效提升,突出句向量中的关键信息,从而弥补空间词向量的不足。
4.6 实验结论
通过上表中的数据对照可知:模型由外部知识库信息优化后,在Wiki QA数据集和TREC QA数据集上多次进行实验,取MAP和MRR两个指标的各自平均值作为最终结果,两个指标均有所提升。因此,可以得出结论:结合外部知识库关系向量,优化单词语义权重的方法,可以有效提升深层神经网络模型的效果。
5 结论
本文在AP-BiLSTM、CON-BiLSTM、KA -BiLSTM三个深层神经网络模型的基础上进行了如下优化:在传统注意力机制加权将句矩阵转化为句向量的步骤中,参照自然语言推理任务中的方法和思想,根据知识库关系向量,在句矩阵编码为句向量的步骤中,优化了问答句词和词之间的权重,从而提升模型效果。
通过与常用的答案选择基准模型结合并进行对比实验,可以得出以下结论:答案选择任务中,在深层神经网络模型的基础上,引入外部知识库关系信息能有效优化模型效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
制造技术与机床(2019年6期)2019-06-25
传媒评论(2017年3期)2017-06-13
中国交通信息化(2016年9期)2016-06-06
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
图书馆研究(2015年5期)2015-12-07
读写算·高年级(2009年3期)2009-11-16
