
基于半监督谱聚类集成的售后客户细分
2020-01-17 01:47:16杨静雅孙林夫吴奇石
计算机工程与应用 2020年2期
杨静雅,孙林夫,吴奇石
西南交通大学 信息科学与技术学院,成都610031
1 引言
客户细分(Customer Segmentation),是企业在明确的战略、业务模式和特定的市场中,根据客户的属性、行为、需求、偏好以及价值等因素对于客户进行分类,并提供有针对性的产品、服务和营销模式的过程[1]。能够正确评估客户价值的企业可以对不同客户提供个性化的服务,在有效管理客户关系的同时增加企业的利润[2]。
汽车售后服务供应链中的企业包括配件供应商、制造厂和售后服务商。汽车售后服务供应链云平台为实现售后服务供应链企业间的业务协同提供了一种基于公共服务平台的解决方案。作为平台的增值服务,根据购车客户在售后服务商处的历史维修保养数据对客户细分,将客户划分为一个个具有不同特征的客户群体,对每个客户群适时地给予个性化的维修保养建议,可以有效改善售后服务质量,提高客户满意度,对售后服务供应链的发展至关重要。
目前,国内外关于客户细分的研究中,聚类分析及其改进算法最常用[3-6]。文献[3]使用K-Means算法对零售业客户进行细分。文献[4]运用自组织映射神经网络对客户进行聚类,通过对聚类结果进行分析与识别得到4S店客户细分结果。文献[5]提出了一种基于k 均值和多变量量子混合蛙跳算法(MQSFLA)的聚类算法,用作电信客户营销中的客户细分。文献[6]提出了一种基于进化的聚类算法,将元启发式与核心直觉模糊c 均值(KIFCM)算法相结合,用于女装销售客户细分。然而,这些研究大都基于单一聚类算法或聚类算法与其他数据挖掘算法的结合,没有完整地揭示数据集的潜在结构,难以获得精确的聚类结果。
聚类集成[7]算法通过训练多个基聚类器,充分挖掘数据集的内在特征,再利用共识函数集成所有基聚类结果标签,得到一个更具鲁棒性和稳定性的划分[8-9]。半监督聚类[10-11]能够结合少量标签或者成对约束信息指导聚类过程,利用数据集本身潜藏的先验知识,使得聚类算法能够获取更多的启发式信息,从而减少搜索过程的盲目性,提高聚类质量。谱聚类算法[12-13]可以在任意形状的样本空间上聚类且通过特征分解收敛于全局最优解。本文作者在文献[14]中同时运用了聚类集成、半监督学习和谱聚类算法的优势,提出了半监督谱聚类集成算法,用成对约束信息指导聚类集成过程,获得了较优的聚类效果。现有客户细分研究中很少运用聚类集成和半监督学习思想,基于此,本文将半监督谱聚类集成算法应用到汽车售后服务客户细分过程。
此外,客户细分指标的选择与细分目的相关,影响细分结果,是客户细分的关键任务。RFM模型[15]是应用最广泛的一种客户细分指标模型,模型通过客户最近一次消费(R)、消费频率(F)以及消费金额(M)三项指标评估客户的价值状况,用于监测客户消费行为异动、防范重要客户流失。后来的很多研究都继承自RFM 模型[16-18,4],做了相应发展。文献[16]引入总利润属性,创建RFP 模型,用于电子商务企业客户细分;文献[17]增加购买倾向属性,提出了RFAT指标模型,用于食品连锁销售企业的客户细分;文献[18]提出了LRFMP模型,用于对杂货零售行业的客户分群。但这些细分指标模型均不适合汽车售后服务客户保养的场景。文献[4]虽然针对汽车维修服务业的特点,提出了YKFM客户细分模型,但不适合本文只研究保修期内客户的特点,因此无法指导本文研究的汽车售后服务客户细分。
综上分析,本文根据汽车售后服务客户细分的目的及研究对象的特点,设计了RFMD 细分模型;并将半监督谱聚类集成算法应用于细分过程,提出了基于半监督谱聚类集成的售后服务客户细分方法。
2 汽车售后服务客户细分
2.1 课题研究对象及其特点
保修期内,客户对车辆的关注度非常高,对服务商(本文指整车特约服务商和能提供维修保养服务的整车特约经销商)的依赖度也相当高,关于车辆的几乎所有的保养与维修都在服务商处进行,是服务商最基本的目标客户。服务商处也会因此记录客户从购车以来的所有维修保养数据,该数据真实反应了不同客户的驾驶习惯、消费习惯、购买能力、喜好,以及对车辆的使用频率、使用环境、保养维修频率等,依据这些数据对客户细分,可以从不同侧面或层次了解客户、定位客户,分析客户的潜在价值,从而有针对性地向客户提供差异化的产品和服务,提高客户的满意度和忠诚度,使客户在保修期过后仍然选择到该服务商处维修保养,增加企业利润。
本文以保修期内的车辆用户(以下简称“客户”)为研究对象,根据该时期内客户对车辆的保养情况来细分客户。对于细分到不同簇的客户群,根据簇内群体的不同特征推荐与其特征相符的产品和服务,比如向追求高品质的客户群体推荐中高档车辆保养产品,而向不太注重品质且购买能力不高的客户推荐中档及以下的保养产品;对于细分为同一簇的客户,可以为其推荐簇内其他客户购买或使用过的产品和服务,比如某一簇内客户A除了常规保养外还对车辆进行了漆面护理,那么推测该簇内的客户B 也倾向做漆面护理,因此,可以尝试向客户B推荐漆面护理的保养。
2.2 客户细分指标选择
客户细分的关键任务是选择适当的细分指标。由2.1 节的分析,本文在RFM 模型基础上,总结如下与车辆保养属性相关的影响因素,并从中选择合适的细分指标。
(1)最近一次保养的时间R:从上次保养到当前日期的天数。如果R 大于一定期限,比如半年,则推断客户保养习惯较随性,或不注重保养,需给予其一定提醒。
(2)保养的频率F:从购车到当前日期内的保养频率(次数/天数)。F越大,客户潜在价值越大。
(3)保养的总金额M:这里修正为从购车到当前日期内,每次保养的平均消费金额(总金额/次数)。M 一定程度上反映了客户的消费习惯和购买能力,M 越大,客户潜在价值越大。
(4)日均行驶里程D:从购车到最近一次保养日期内,客户的日均行驶里程(总行驶里程/天数)。日均行驶里程大,预示车辆磨损老化快,需要客户经常保养来保证车辆的正常使用。因此,D越大,客户潜在价值越大。
(5)车辆行驶的外部环境E:外部环境包括温度、湿度和道路状况等。温度高,橡胶制品易老化;湿度大,金属易锈蚀;道路状况差,轮胎易磨损;等等。
(6)客户驾驶技术S:驾驶技术好,则车辆不易被剐蹭,刹车片、轮胎等易损件也不易被损耗,因此车辆不需要经常保养;反之,车辆需要经常保养。
其中,(4)(5)(6)因素均可通过保养频率即因素(2)来体现,然而(4)因素对保养属性影响较大,并且(5)(6)因素难以量化。综合考虑,选择(4)因素与(1)(2)(3)因素一起作为本文的客户细分指标,即RFMD 细分指标模型。
3 半监督谱聚类集成
3.1 半监督聚类集成问题描述
假定有对象集O={o1,o2,…,on} ,以及这n 个对象的基聚类划分数目r 。一致函数Γ 被定义为这样一个映射Nn×r→Nn,将一组聚类的集合映射为一个集成聚类,即Γ:{λ(q)|q ∈{1 ,2,…,r }}→λ ,其中{1 ,2,…,k} }表示将对象集O 聚成K 类的一个划分。聚类集成的目标是从r 个λ(q)中寻找一个一致性划分,使其能够更好地代表所有划分的特性。
半监督聚类利用先验知识(成对约束或少量标签信息)指导聚类过程,减少了搜索的盲目性,提高聚类结果的质量。本文算法利用成对约束先验信息,mustlinks:M={(oi,oj)|oi和oj属于同一个 }簇,cannot-links:C={(oi,oj)|oi和oj属于不同的 }簇,指导聚类集成过程,即半监督聚类集成。
半监督聚类集成不仅要实现聚类集成的目标,而且还要达成一个目标,即:利用成对约束信息学习一个相似度矩阵S,使C 中样本点间的距离尽可能得大,而M中样本点间的距离尽可能得小。
3.2 半监督谱聚类集成框架
图1 为本文提出的半监督谱聚类集成(SSSCE)框架。具体来讲,SSSCE 首先随机初始化k-means 算法,生成多样性的基聚类结果{λq|q ∈{1 ,2,…,r }};然后,用基聚类结果标签向量生成相似度矩阵S,并用成对约束信息修正S。最后,采用谱聚类算法作为一致性函数生成最终聚类结果。
3.3 半监督谱聚类集成算法
半监督谱聚类集成算法实现步骤如下。
输入:对象集O={o1,o2,…,on} ,聚类结果的簇数K ,基聚类器数目r ,必连约束样本点集M ,不连约束样本点集C
步骤1 生成基聚类器,为聚类集成做准备;
for q=1:r
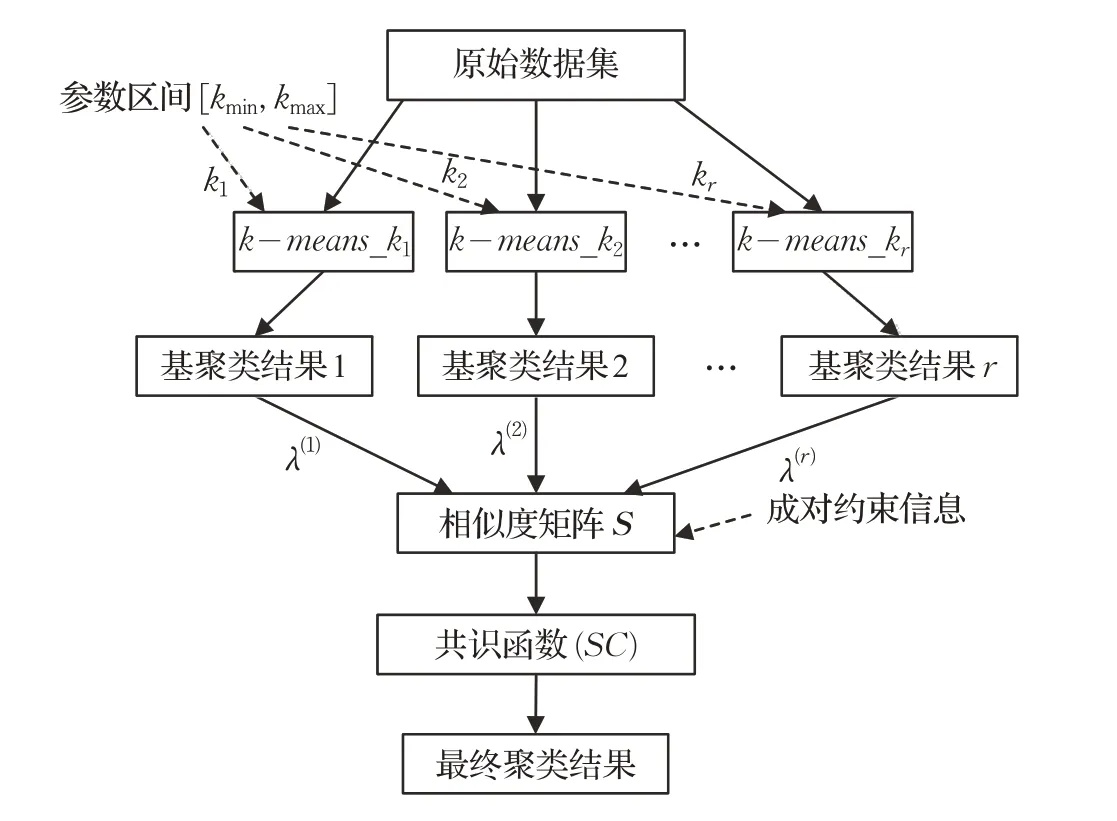
图1 半监督谱聚类集成(SSSCE)框架
kq:从中随机选取
λq=kmeans(O,kq)
end for
步骤2 将基聚类结果的标签向量转换成超图H ;
步骤3 构建相似度矩阵S=HHT,且S ∈Rn×n,H ∈Rn×d;
步骤4 用成对约束信息修正相似度矩阵S:
(1)如果样本点对(oi,oj)∈M ,则Sij=1;
(2)如果样本点对(oi,oj)∈C,则Sij=0;
步骤5 以相似度矩阵S 为输入,运行标准的谱聚类算法;
输出:对象集O 的K 个簇
4 实验研究
在文献[14]中,通过选取UCI机器学习库中的16个数据集,已经验证SSSCE 在MP[19]和ARI[20]指标的衡量下均优于CSPA、HGPA、MCLA、SCE 等聚类集成算法。以下分析SSSCE在汽车售后服务客户细分中的实验结果,并与谱聚类算法(SC)和谱聚类集成算法(SCE)的客户细分结果比较。
4.1 数据来源
西南交通大学和四川省现代服务科技研究院等单位创建的汽车售后服务供应链云平台,自搭建以来,受到了各整车及零配件制造厂的青睐,目前已经为全国5 000 多家与汽车生产相关的上下游企业提供服务,本文依托于该平台,以某汽车售后服务供应链中的售后服务商为实例,以2018 年5 月1 日为当前日期,选取该服务商F12 型汽车在保修期内的357 位客户的2 623 条历史保养记录作为样本数据。将样本数据按RFMD 细分指标模型计算整理,形成357×4的矩阵,如表1所示。

表1 F12型汽车客户的保养相关样本数据
将样本数据分别按四个指标由大到小或由小到大排序;根据企业管理中的“二八法则”,每次排序后,分别取各序列中前20%的数据组成四个样本集合,选取该四个集合中均存在的样本,组成样本集M_set1;同理,从各指标序列的后20%中选出样本集M_set2;设定M_set1中的样本对和M_set2 中的样本对均属于must-links,而同时由M_set1 和M_set2 中的样本构成的样本对属于cannot-links,由此生成成对约束集M 和C。
4.2 数据预处理
由于样本数据存在较大波动,且四个指标的意义、量纲和数值范围各不相同,需要在聚类前对数据进行归一化处理[21],归一化公式如下,归一化后的数据如表2所示。

式中,xi为样本数据实际值,xmax=max(xi),xmin=min(xi)。

表2 归一化后的样本数据
4.3 评价指标
在汽车售后服务客户细分等实际应用中,样本数据的真实标签无法或很难事先获知,因此,基于已知标签的聚类效果评价指标(比如MP、ARI、NMI 等),将不能通过计算得出。故实验需要选用不依据已知标签的评价指标,比如Silhouette Coefficient[22]、Calinski-Harabasz Index[23]、Davies-Bouldin Index[24],这三个指标一定程度上均是从簇内的密集程度和簇间的离散程度来评估聚类效果。与Calinski-Harabasz Index 相比,Silhouette Coefficient计算稍显复杂,Davies-Bouldin Index使用质心距离限制了欧几里德空间的距离度量,因此,实验选用Calinski-Harabasz Index 作为评价指标。另外,本文自定义一个损失函数来评估聚类效果,以及估计聚类的簇数。
(1)Calinski-Harabasz Index

其中,n 为样本数,K 为簇数,BK为簇间的协方差矩阵,WK为簇内数据的协方差矩阵,tr 为矩阵的迹。CH( K )值越大,则聚类效果越好。
(2)损失函数
设c1,c2,…,cK为K 个聚类中心,yik∈{ }0,1 表示样本oi是否属于聚类k(0代表“否”,1代表“是”),则损失函数J(c,y)定义如下:

在K 取值一定的情况下,J(c,y)的值越小,表示算法的聚类效果越好。
4.4 参数设置
对于参数r(基聚类器数目)的设置,r 越大,基聚类结果越多样化,最终聚类结果也将越准确,但考虑到实验运行效率,r 不能过大,文中实验设置r 为10;而各基聚类k -means 算法中k(即kq)的取值范围设置为:。谱聚类算法中参数σ 设置为1。
4.5 结果与分析
分别使K 取2、3、4、5、6,依次进行聚类,运行20次取平均值。
(1)SC 算法、SCE 算法和SSSCE 算法的Calinski-Harabasz Index如图2所示。

图2 三种算法的Calinski-Harabasz Index
从图2可以看出,①在K 的五个取值中,SCE算法的Calinski-Harabasz Index 几乎均大于SC 算法,而SSSCE算法的Calinski-Harabasz Index 也几乎均大于SCE 算法,由此显示出聚类集成算法的优势,以及半监督学习思想的优势。②三种算法的Calinski-Harabasz Index均在K=4 时取得最大值,可以判断4为最佳聚类数目。
(2)SC算法、SCE算法和SSSCE算法的损失函数如图3所示。

图3 三种算法的损失函数
从图3看出,①在K 的五个取值中,SCE算法的损失函数均小于SC 算法的损失函数,且二者的“肘点”值均为4(根据经典的“肘点”法,“肘点”值为最佳K 值)。②SSSCE 算法的损失函数变化不大,且始终处于较低值。图3 印证了由图2 得出的判断,即聚类集成和半监督学习使聚类效果更优,且4为最佳聚类数目。
因此,选择K=4 时SSSCE算法的运行结果为最终聚类结果,四个聚类中心如表3所示。

表3 聚类中心
由表3 和表4 分析各类客户群的特征,并给出以下保养指导建议:
1类客户:这类客户用车多,对车辆保养频繁,每次保养花费较高,刚做过保养;可以推断该类客户对车辆比较依赖,对车辆性能要求高,爱惜车,消费水平较高,对服务商忠诚,对服务商来说是高价值客户;另外,可以判断该类客户的车辆接近保修期,服务商应特别关注该类客户的需求,尽量做到一对一个性化服务,确保客户继续忠诚,保修期过后不流失。
2类客户:这类客户用车时间正常,保养频率正常,每次保养花费也处于中档水平;该类客户占比较大,是服务商盈利的中坚力量,服务商应遵循其保养规律,适时给予相似客户的保养用品推荐,互通该类客户群的保养选择;在保证这类客户忠诚度的同时,适当引导其消费习惯,提高其消费水平,使这类客户的保养消费水平逐渐向1类客户靠拢。

表4 各类的成员数量
3类客户:这类客户用车少,保养频率低,每次保养花费也较低,且已经很久没做过保养;可以推断该类客户对车辆依赖比较低,对车辆性能要求低,不关注也不太爱惜车辆,对车辆消费水平偏低,对服务商来说是低价值客户;服务商需要关注这类客户,向其普及保养常识,引导其形成正确正常的用车和保养意识,增加其忠诚度,使其逐渐形成2 类客户的保养习惯,或者不至于流向竞争企业。
4类客户:这类客户用车多,但保养频率不高,每次保养的花费处于正常偏上水平,已经较长时间没来保养;可以推断该类客户对车辆依赖度高,但不注重保养,这将存在一定的安全隐患;服务商应针对性地提醒其适时保养,规范其保养行为,并适当地给予其保养用品建议,使其形成正确的保养意识,提高其对服务商的依赖度与忠诚度,保修期内外都将对服务商产生较大的潜在价值。
5 结束语
通过分析客户在售后服务商处的历史保养记录,建立了与汽车保养属性相关的RFMD细分指标模型;基于半监督谱聚类集成算法对售后服务客户进行细分,实验结果表明该算法的细分结果优于SC 算法和SCE 算法。对不同客户群进行特征分析,给出与其特征相符的保养建议。依据客户其他属性(比如维修、驾驶等)进行客户细分,以及进一步优化半监督聚类集成算法(比如调整成对约束集的取法)将是下一步研究的方向。
猜你喜欢
军民两用技术与产品(2022年3期)2022-06-05 06:46:38
福建江夏学院学报(2021年6期)2021-08-10 08:21:52
华人时刊(2020年23期)2020-04-13 06:04:12
电子测试(2017年15期)2017-12-18 07:19:27
专用汽车(2016年9期)2016-03-01 04:17:02
智能系统学报(2015年4期)2015-12-27 09:38:39
专用汽车(2015年2期)2015-03-01 04:05:42
电子设计工程(2015年6期)2015-02-27 12:04:53
中国期刊年鉴(2015年0期)2015-01-19 07:17:12
软件和集成电路(2014年7期)2014-12-31 11:11:42
