
多尺度局部特征选择的行人重识别算法
2020-01-17 01:42徐家臻
计算机工程与应用 2020年2期
徐家臻,李 婷,杨 巍
1.华中师范大学 教育信息技术学院,武汉430079
2.武汉船舶通信研究所,武汉430070
1 引言
行人重识别技术是指给定某摄像头拍摄到的某行人图片,在资料库中检索该行人被其他摄像头拍到的图片。由于摄像头位置、角度和参数设置不同,行人姿态频繁变化,以及背景干扰、遮挡和成像质量不稳定等原因,同一行人在不同时刻不同摄像头拍摄的图片中存在较大差异(如图1所示),这使得行人重识别问题具有相当的难度。研究行人重识别问题,对于社会安全和智能交通等领域具有重要的应用价值。

图1 Market1501数据集中的部分行人识别数据(每列图像为同一行人)
行人重识别早期的研究重在寻找更好的距离度量算法[1],其中最具代表性的方法为KISSME算法[2]。该算法通过似然比检验测量样本对的差异程度,假定样本对相似及不相似的概率分布均符合均值为0的正态分布,从而得到反映对数似然比检验属性的马氏度量。近年来,随着深度学习神经网络在图像识别和计算机视觉领域的广泛成功应用[3],行人重识别的研究也集中到利用深度神经网络寻找更好的特征描述上。受到深度学习在人脸识别应用的启发[4],除了使用图片分类问题中经常使用的基于softmax的交叉熵来衡量识别损失(identification loss)外,这些算法还进一步构造了孪生神经网络结构,同时输入2幅、3幅或3幅以上属于/不属于同一行人的图片计算验证损失(verification loss)[5-8]。
为了进一步解决行人在不同图像中的对齐问题,Zheng 等人[9]提出了一种空间变换网络的方法,利用识别损失训练最优变换参数,尽可能将所有行人缩放和旋转到统一大小。Wei等人[10-11]运用人体姿态识别领域近期的研究成果,定位人体关键点并将人体划分为头部、上肢和下肢三部分,分别提取局部特征并与整体特征融合作为行人特征。虽然融合局部特征能够在一定程度上提高识别准确率,但现有的姿态定位算法本身存在一定误差,尤其是遮挡和背景干扰较大的情况下,该误差造成的错误划分反而会影响识别准确率。由此Sun 等人[12]提出了更为简练的PCB模型,将行人图像经过卷积神经网络后的特征从上到下直接等分N份,分别提取各区域的特征同步训练,以该简单划分得到的局部特征识别准确率反而比关键点定位更好。
相对于物体识别、人脸识别问题,当前的行人重识别数据集普遍较小,因此也有研究从扩大训练数据着手,利用对抗神经网络[13]自动生成大量人工合成的行人图像,并以此为补充训练得到更好的识别网络。由于合成数据与真实数据相比仍存在较明显的差异,Zheng等人[14]将所有合成数据的标记为1/C,C 为训练集中的不同行人总数。Qian 等人[15]利用姿态定位算法自动获取到的关键点,以及训练集和测试集中手工标注的行人属性信息(如性别、是否戴帽子、是否背包、是否穿靴子等),为每幅不同姿态和环境的行人图像生成K 幅“标准”图像,并以行人标准图像间的差异进行识别判断。针对摄像头型号、环境和拍摄季节等因素造成的不同行人数据集图像的系统性差异。Wei等人[16]构造了用于不同数据集互相转换的对抗生成网络,训练得到的模型识别准确率低于单个数据集训练的结果,但优于直接合并不同数据集后的训练结果。
本文为解决局部区域划分和特征提取的有效性问题,提出了一种基于局部特征选择的行人重识别算法。该算法采用多尺度滑动窗口方法对局部特征进行多尺度多覆盖的划分,以平均池化和最大池化两种机制分别获取局部平均特征和局部显著特征,自适应选择其中K项最优特征作为局部识别特征,与全局识别特征共同构成最终识别特征。实验结果表明,使用本文提出方法的特征在目前行人识别数据量最大的两个数据集Market1501[17]和DukeMTMC-reID[14,18]上都取得了更好的识别准确率。
2 基于深度学习的多尺度局部特征选择算法
2.1 网络结构
如图2 所示,本文采用残差卷积神经网络结构ResNet-50[19]作 为 初 始 网 络NI(Initial Network),从ResNet 的第4 个残差block 后的激励信号开始,去掉原有的全连接层,增加两个分支网络NG(Global Network)和NL(Local Network),分别获取全局特征和局部特征。获取到的全局特征fg 和m 组局部特征{flm}再分别经过同构的识别网络NC(Classificaion Network)。每个NC网络的结构均包含以下层次:d1×d2 维的全连接层FC1,Batch Normalize 层,ReLU 层,Dropout 层和d1×c 维全连接层FC2,通过最优局部特征选择,对输出计算softmax 损失函数。其中d1 为ResNet 的激励信号维度,d2 为嵌入特征表示层的维度,c 为不同行人的个数。在全局特征分支网络NG中,用平均池化层获取全局特征fg 。在局部特征分支网络NL 中,首先对上层ResNet输入的激励型号进行多尺度滑动窗口划分,然后将其中对每组获取到的特征,送入平均池化层和最大池化层分别获取局部特征{fli|i=1,2,…,m},其中m 为所有划分数×2。
2.2 多尺度滑动窗口划分

图2 本文采用的卷积神经网络结构示意图
根据行人图片的实际采集环境,相当一部分图片存在对齐和遮挡问题,由于图片本身的质量较低,使用流行的姿态定位算法如OpenPose 等存在一定误差,而该误差会影响下一步的识别正确率。本文提出一种不同的对齐方法,即不显式对行人关键点进行定位,采用多尺度的滑动窗口自适应地寻找最佳划分方式,训练该滑动窗口的依据仅来自识别损失。如图2所示,设ResNet输出的激励信号a 的维度为ha×wa×d ,构造s 个不同尺度的hi×wi×d 滑动窗口{WNi|i=1,2,…,s} ,滑动窗口共构造特征ha-hi+1)×(wa-wi+1)组。
2.3 最优局部特征选择
如图2所示,将ResNet输出的激励信号a 从上至下等分成p 个部分{Pi|i=1,2,…,p},所有覆盖Pi的滑动窗口{WNPi}被分成一组,每组滑动窗口的特征经过属于自己的NC网络后,只保留识别损失函数最小的一项。于是,整个网络的损失函数为:

其中:
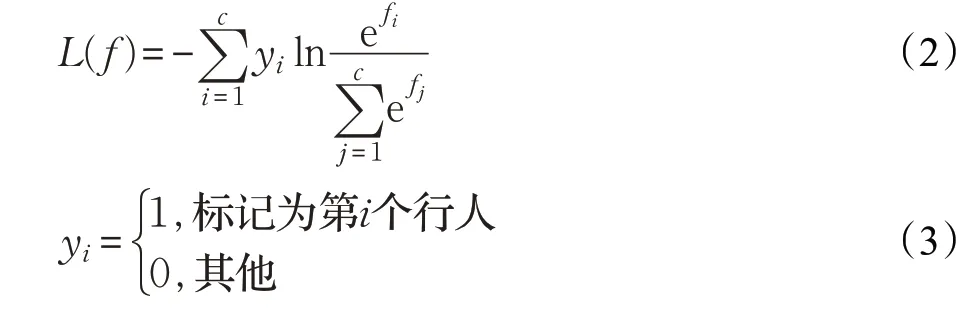
λ 为权重调节函数,控制全局特征fg 和局部特征fl 在损失函数中所占的比例。
2.4 标签平滑
与物体识别、人脸识别不同,行人重识别的图片的来源一般是截取自摄像头全景拍摄视频中的一小块区域,因此一部分行人重识别图片质量较差,或者遮挡严重,其所能提供的信息量非常有限,即使由人工来进行识别,其成功率也不及人类在物体识别和人脸识别问题上的表现[20],因此部分标记数据存在标注错误或疑似错误的情况。为避免分类器对错误标注过拟合,本文进一步对所有标签数据进行了平滑处理,假定每个行人标签都有一定的标错概率ϵ,而实际正确标注的可能性服从正态分布。即若行人图片被标注为属于行人i,则实际标注向量为:

3 实验结果及分析
3.1 实验数据及评价标准
本文所采用的实验数据主要来自目前行人重识别数据量最大的两个数据集:Market1501和DukeMTMC-reID。
Market1501 中包含了从6 个不同的摄像头中拍摄的共1 501 个不同行人的图片,分为训练集和测试集。训练集包括751 人的图片共12 936 张。测试集包括另外750 人,又分为两部分:查询集包括3 368 幅图片;图库集包括与查询集相同行人的其他图片13 056幅,以及用于干扰项的不在查询集中的行人图片6 676幅。
DukeMTMC-reID 包含了从8 个不同摄像头中拍摄的共1 404 个不同行人的图片,分为训练集和测试集。训练集包括702 人的图片共16 522 张。测试集包括另外702人,又分为查询集和图库集,查询集包括2 228幅图片,图库集包括17 661幅图片。
图3为Market1501和DukeMTMC-reID数据集中的部分示例。

图3 实验采用的数据集示例
目前评价识别准确率的标准主要有两种,一种是Rank-n 标准,即给定查询集中的一幅图片,计算它与图库集中所有图片的相似度,从高到低排序,如果前n 项中有相同行人即为识别正确。这种评价方式一般以Rank-1结果最为重要,Rank-5或Rank-10辅助参考。另一种标准成为mAP 标准,它更加强调查准率和查全率之间的平衡,也是先对相似度排序,然后从高到低统计从第一项到最后一项相同行人图片之间正确识别的比率。本文同时比较了两种标准的识别准确率情况。需要说明的是,同一摄像头连续拍摄的两幅图像中同一行人往往是比较相似的,评价标准中排除了所有这些情况,只统计一个摄像头中的行人在其他摄像头拍摄的图像中查询到的结果,一定程度抑制了数据本身不平衡可能对结果造成的影响。
3.2 实验环境及参数设置
本文算法采用深度学习工具包pytorch 实现,在一台安装GTX 1080 GPU加速卡的工作站上对实验数据进行模型训练和测试评估。主干网络采用ImageNet预训练过的ResNet50模型,行人图片被调整为384×128分辨率输入。全局特征嵌入层维度为256,局部特征嵌入层维度为128。权重函数λ 设置为1,ϵ 设置为0.1。
滑动窗口初始大小和尺度数的设定对实验结果存在一些影响如图4 和图5。可以看到,当滑动窗口控制在合适大小可以更好地提取局部特征,尺度数越多则候选区域特征越充分,但超过3个尺度后对准确率的实际影响很小,考虑到增加尺度会增加相应的运算量,根据实际需要采用2~3个尺度是比较合适的。

图4 不同尺度下Market1501数据集Rank-1准确率变化情况

图5 不同滑动窗口大小下Market1501数据集Rank-1准确率变化情况
为验证网络结构的有效性,实验在Market1051数据集上比较了只是用全局特征(NG),添加了局部特征(+NL),添加了多窗口划分和局部最优特征选择(+MS),以及添加标签平滑(+LS)后的效果,详细实验数据见表1。

表1 不同网络结构和损失函数在Market1501数据集上的测试结果 %
3.3 方法比较
为验证方法的有效性,把本文提出的方法与只使用全局特征的方法(BASELINE)利用空间变换网络对齐特征的方法(PAN)、利用GAN 网络对齐特征的方法(PN-GAN)和等比例划分局部特征的方法(PCB)进行了对比,在Market1501 和DukeMTMC 数据集上的对比测试结果如表2 和表3。实验表明,本文提出的方法确实可以提高行人重识别的准确度。
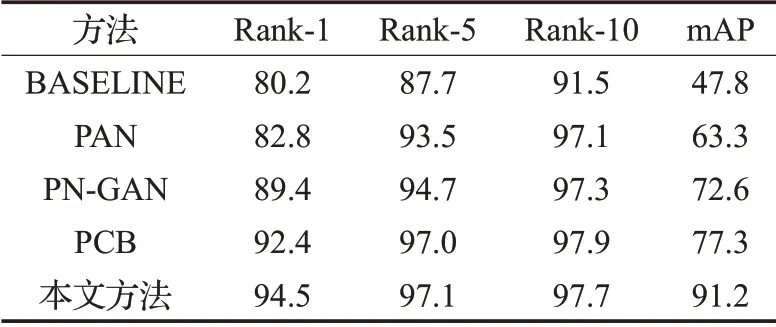
表2 Market1501数据集测试结果 %
图6 显示了实验的部分查询结果,每行第1 列为查询图片,后10列为前10名的查询结果,绿色边框为正确结果,黄色边框为错误结果。可以看出,本文方法对于行人重识别问题中姿态变化和遮挡均具有较好的适应能力。

图6 部分行人重识别结果(绿色边框为正确结果,黄色边框为错误结果)

表3 DukeMTMC数据集测试结果 %
4 结束语
行人重识别问题中姿态变化、对齐、遮挡等情况对识别效果影响很大,这就要求算法能够更好地选择局部区域、提取局部特征和匹配局部特征。本文通过多尺度的滑动窗口创建充足的候选局部特征区域,并通过卷积神经网络自适应地选择合适的局部特征,与全局特征一起组成行人图像特征表达,从而达到更好的识别效果。在接下来的工作中将进一步研究更为有效的局部特征提取和选择方法。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
汽车工程师(2021年12期)2022-01-18
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
制造技术与机床(2018年11期)2018-11-23
意林(绘英语)(2018年1期)2018-04-28
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
汽车维修与保养(2015年8期)2015-04-17
城市轨道交通研究(2015年11期)2015-02-27
