
用于燃煤锅炉热效率在线计算的虚拟煤质数据库的建立
2020-01-15 02:54:16杨东伟顾晨恺郁鸿凌
上海理工大学学报 2019年6期
陈 雪, 杨东伟, 顾晨恺, 管 坚, 郁鸿凌
(1. 上海理工大学 能源与动力工程学院,上海 200093;2. 中国特种设备检测研究院,北京 100029)
燃煤成分对锅炉效率、大气污染物排放浓度有着重要的影响。一般情况下,锅炉运行实际煤种特性应与设计煤种相接近,以确保燃烧稳定及各参数在正常范围内运行。但近年来,随着碳煤价格日益高涨,锅炉用煤的来源与成分复杂多变,供煤质量波动幅度增大,使得锅炉负荷的调节控制难度加大,从而对燃煤的燃烧效率和锅炉安全稳定运行造成了很大的影响[1-2]。而且,目前煤质成分的实时测量技术尚不成熟,常采用的离线取样分析方法存在结果滞后、误差大等问题,煤质数据的实时性得不到满足[3],不利于实时调节燃烧,对锅炉运行效率难以预测。所以,建立可实时调用的虚拟煤质数据库,对于锅炉热效率计算并及时调整燃烧优化锅炉运行具有重要的意义。
李洋[4]以云南某电厂的化验煤质为例,运用模糊聚类算法建立了以发热量为索引的煤质数据库,忽略了燃煤挥发分对煤燃烧效率的影响,且单以发热量为索引的煤质在线辨识,其可信度仍有待加强。王洋等[3]和赵明等[5]则采用PAM(partitioning around medoid)算法建立煤质数据库,以电厂某天化验的发热量与数据库发热量作对比,验证数据库的合理性,但化验数据来源不可靠且不稳定,未考虑挥发分成分,数据库不完善。
本文针对工业锅炉常用煤,根据煤在不同地域的特性,建立以煤类型为第一索引,煤产地以及燃煤发热量分别为第二和第三索引的可在线调用的煤质数据库,可实现锅炉变工况时的热效率实时测算。
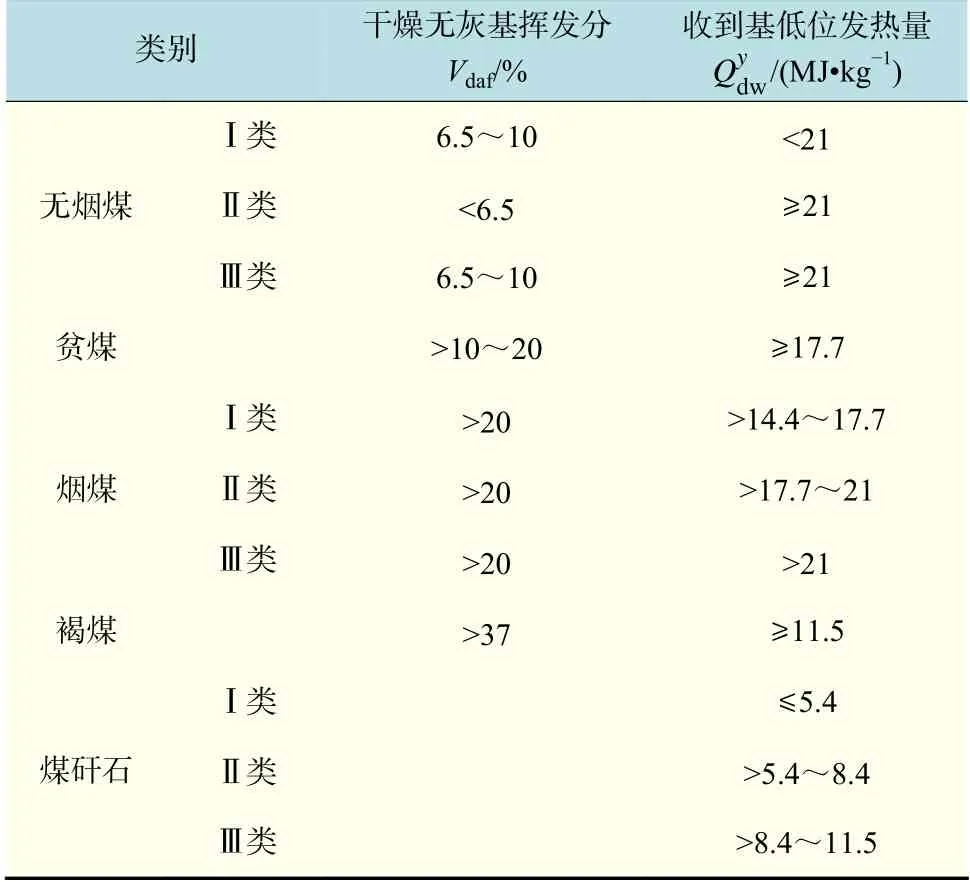
表 1 工业锅炉行业煤的分类标准Tab.1 Classification standards for coal in industrial boilers
1 工业锅炉用煤
1.1 工业锅炉用煤分类标准
为了便于使产品系列化,工业锅炉行业将煤分为11 类,各类代表性煤种如表1 所示。
首先根据挥发分含量由小到大分为无烟煤、贫煤、烟煤和褐煤这4 种,再根据发热量将无烟煤和烟煤分别细分为Ⅰ类、Ⅱ类和Ⅲ类。可见,燃煤挥发分和发热量是表征煤特性的2 个重要因素。
1.2 煤的分布特点
我国动力煤储量丰富,分布广泛,煤种齐全。从全国分布情况看,尤以三西(山西、内蒙西部、陕西)储量最多,占全国的60%[6]。研究发现,褐煤与无烟煤具有较强的地域性。
无烟煤是我国储量最多的煤,约占动力煤的37.57%[6],以山西省最为显著,山西阳泉和晋城最多,除此之外还包括四川芙蓉矿区、湖北西塞山及内蒙古太西等。
褐煤约占动力煤的8.03%,是我国的第二大煤种,主要存在于内蒙古东北部,矿区有霍林河、宝日希勒等。
烟煤一般含水分略高,约10%。多分布于我国开滦、抚顺等。
贫煤一般含水分较少,主要以山东淄博、兖州、新泰为主,还有贵州六盘水和吉林通化等地都有一定的储量。
通过收集全国各地工业锅炉常用煤,根据表1和煤的储量分布特点对各种煤进行分类,在此基础上,通过数据提取,分析特定地区的某一煤种特性以及煤中各元素之间的耦合关系。
2 煤质特性分析研究
煤炭种类的多样性和结构的复杂性是由成煤原始物质、年代等因素造成的[7]。煤的合理利用对节约能源具有重要的意义。
2.1 煤的元素分析
煤是由复杂的高分子碳氢化合物组成的有机燃料,其主要成分是:碳、氢、氧、氮、硫、灰分和水分。煤的元素成分通常用收到基质量分数来表示。
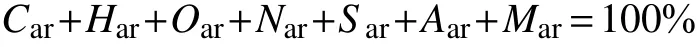
式 中:Car,Har,Oar,Nar,Sar,Aar和Mar分 别 表示燃料的碳、氢、氧、氮、硫、灰分和水分的质量分数。
煤中的水分和灰分含量常随开采、运输、贮存及气候条件的变化而变化。即使对同一种煤,由于水分和灰分的变化,其他成分的含量也将随之发生变化。因此,为了实际应用的需要和理论研究的方便,通常用干燥无灰基表示煤质特性,即
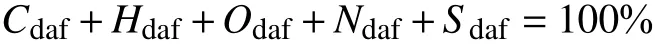
研究表明[8-10],煤埋藏年代越久,碳化程度越深,含碳量也越高。随着碳化程度的加深,煤中的碳含量不断增加,泥煤的干燥无灰基碳含量一般为55%~62%;褐煤为60%~76.5%,烟煤为77%~92.7%;无烟煤为88.98%~98%。而氢、氧的成分由于挥发而逐渐减少。随着变质程度的不断加深,全硫含量呈上升趋势。但是,全硫含量的增高与煤的变质程度之间并没有直接关系,主要由不同成煤时期沉积环境的影响所造成[11]。在内陆、滨海三角和海陆交替环境下形成的煤的含硫量比较高。
入炉煤含碳量的确定原则:一般根据煤产地的统计含碳量以及燃煤种类,配合该地区的燃煤含硫量特点获得。
通过对收集的全国各地405 组煤质回归分析发现,煤中氢含量相对稳定,并且氢和碳含量之间有良好的线性关系[3],如式(1)所示。表2 为收集的部分煤质数据,同理,煤中的氮与氢、氢与氧含量之间也存在线性关系,如式(2)和式(3)所示。
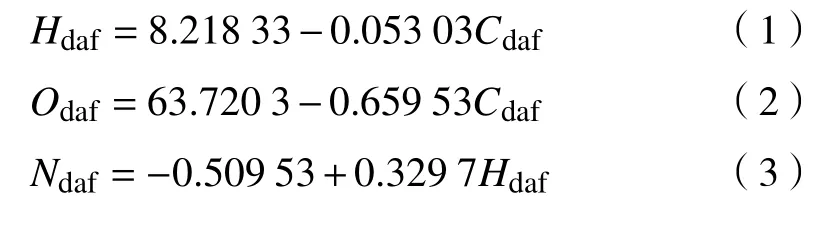
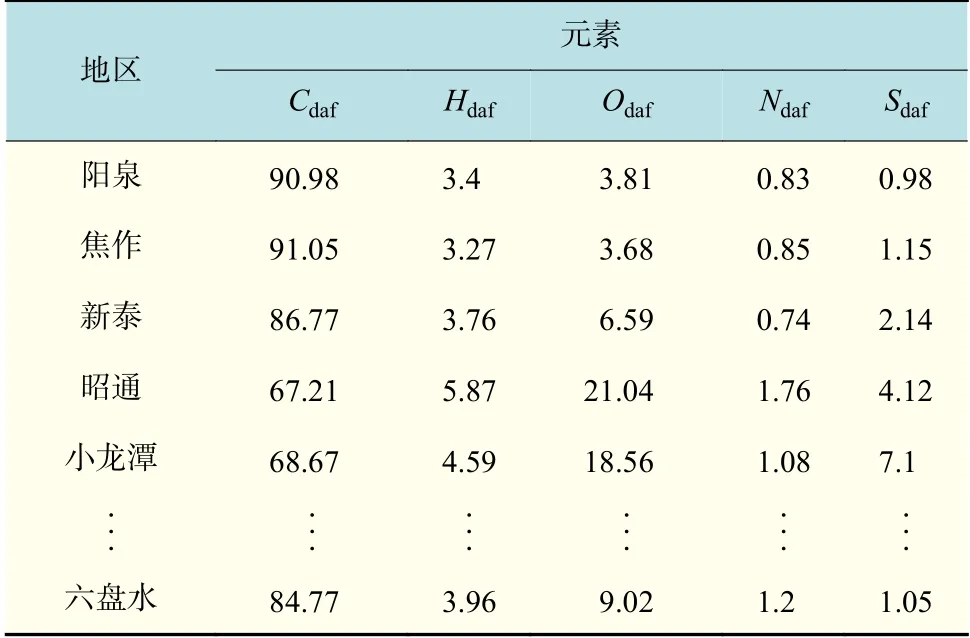
表 2 部分地区的煤质参数Tab.2 Coal quality parameters in some areas
2.2 煤的工业分析
煤的工业分析是评价煤质和了解煤质特性的重要依据[12]。通常由水分、灰分、挥发分以及固定碳组成。
煤的挥发分是表征煤的燃烧特性的重要指标,是影响煤燃烧效率与排放的重要因素。挥发分的燃烧可以很快点燃固定碳,所以,煤中挥发分越高,煤越易着火,固定碳也越易燃尽。使用发热量相同的煤,如其挥发分较高,热效率也会较高。挥发分与煤的生成年代有关,随着煤的碳化程度的加深,挥发分的含量逐渐减少。挥发分与干燥无灰基氢含量具有良好的拟合关系[13]。
煤中的水分和灰分均为不可燃物质。煤中水分对于锅炉燃烧既有利,也有弊。适当的水分能提高煤的利用率,但是,水分过多,发热量必然降低,且炉内温度降低,影响煤着火。同理,煤灰分高,其发热量就低。燃用高灰分的煤,锅炉热效率普遍降低,且灰分越高,锅炉热效率降低的幅度越大[14]。
通过分析煤的成分发现,煤质典型的多变性不在于它的干燥无灰基成分,而在于它所含的水分和灰分。对于特定地区的煤种,煤质的干燥无灰基成分具有一定的稳定性和规律性[3]。
3 煤质数据库的建立
3.1 模型建立
从收集到的405 组数据中找出所有山西阳泉的原始燃煤数据,共25 组,以此为例,通过聚类分析,获取该地区的较稳定的干燥无灰基成分,并与统计处理后的收到基水分和灰分组合,建立该地区的虚拟煤质数据库。煤质数据库建立的流程图如图1 所示,并用燃煤的计算发热量与燃煤的化验发热量作对比,验证数据库的可靠性并剔除误差大的数据,精简煤质数据库。

图 1 煤质数据库建立流程图Fig.1 Flow chart of coal database establishment
3.2 K-means 聚类算法
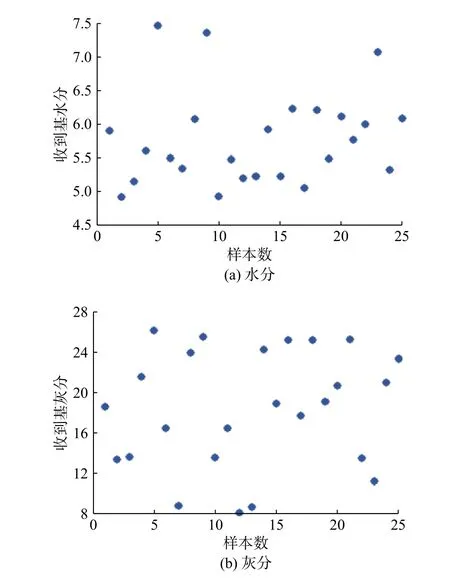
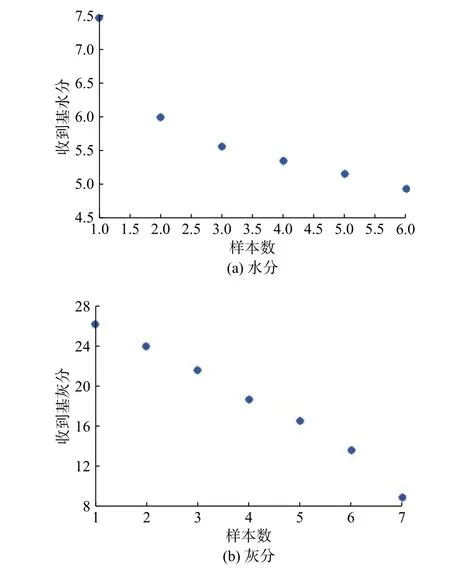
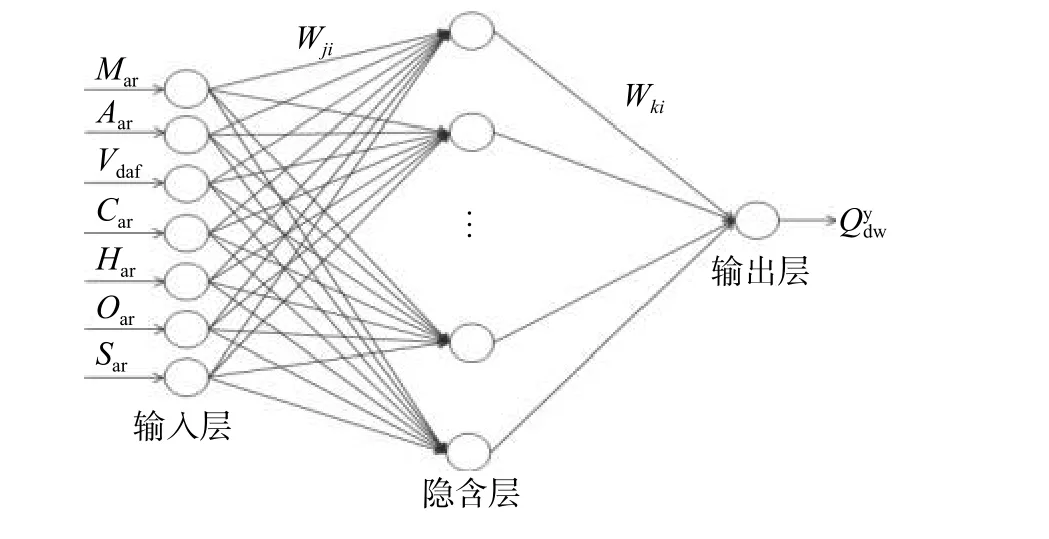
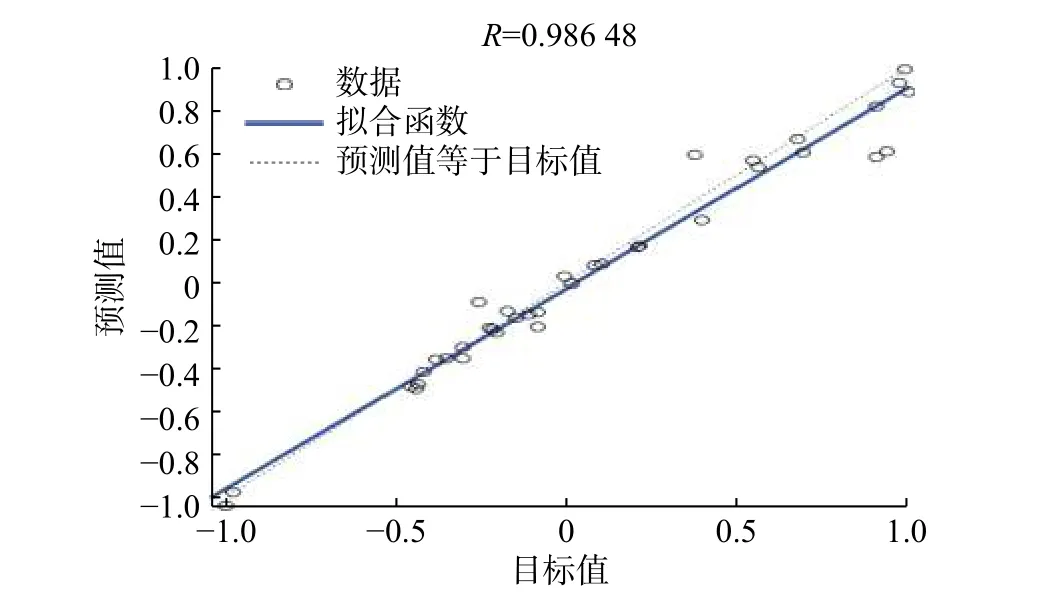
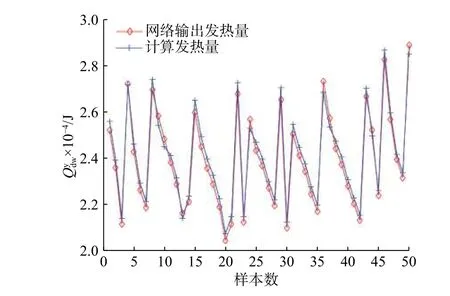
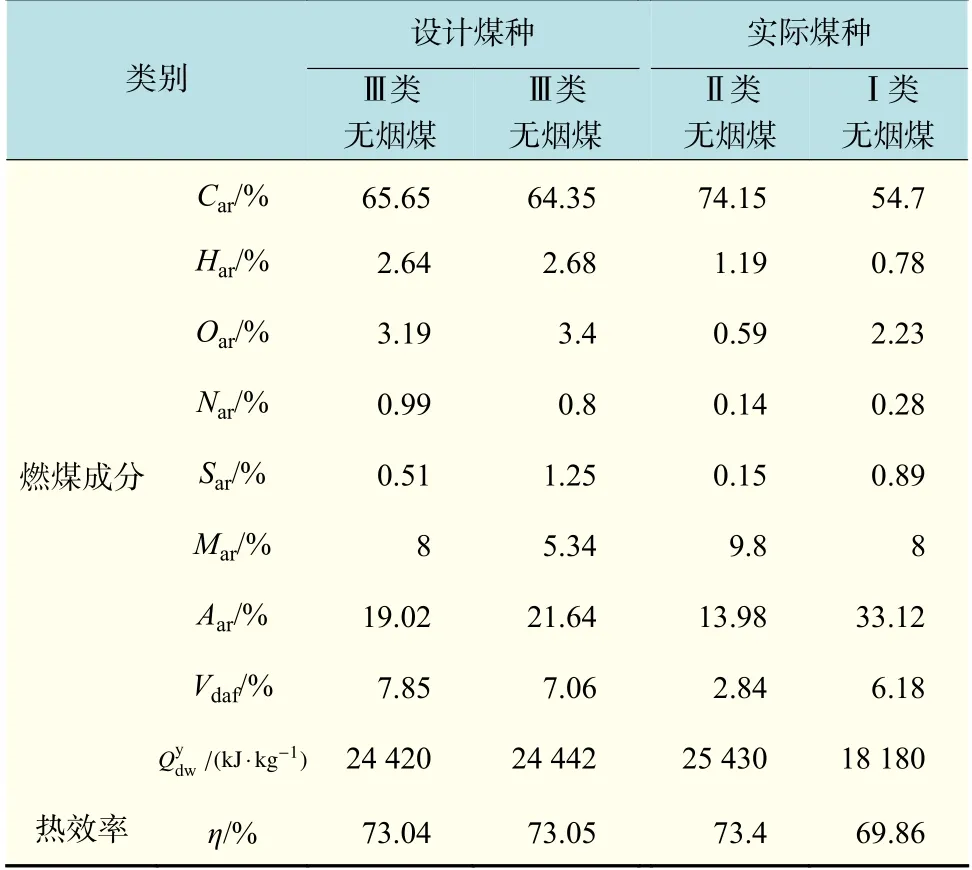
K-均值(也称K-means)聚类算法是著名的划分聚类分割方法。划分方法的基本思想是:给定一个有N 个元或者记录的数据集,分类法将构造K 个簇,每一个簇就代表一个聚类,K 3.3.1 水分和灰分的处理 图2(a)和2(b)为燃煤收到基水分和灰分的散点分布图。从图2(a)和2(b)可以看出,收到基水分的分布范围为4.92%~7.47%,收到基灰分的分布范围为8.16%~26.22%。 为了更直观地观察原始数据的分布特性,首先对数据进行排序,然后将数据导入Matlab 软件,调用K-means 算法对水分和灰分分别进行处理。 实践表明,对于水分和灰分分别取K=6 和K=7 时,所得的均值能较好地反映原始数据的分布特征,如图3 所示。 3.3.2 燃煤可燃基成分的处理 对燃煤可燃基成分的处理与对水分和灰分的处理相同,取K=7,作为典型的燃煤可燃基成分,将构造的可燃基成分与水分和灰分组合,得到6×7×7=294 种虚拟煤质数据库。 图 2 水分和灰分的散点分布图Fig. 2 Scatter plots of water and ash 图 3 水分和灰分的聚类分布Fig. 3 Clustering distribution of water and ash 煤的发热量是表征煤化程度和煤质特性的主要指标,也是动力用煤计价的主要依据[16]。燃煤发热量与各成分之间存在密切的关系。因此,可以通过比较燃煤的计算发热量与化验发热量来验证数据库的适用性。由于数据库的燃煤化验发热量不可得,因此借用神经网络建立数据库发热量的预测模型,以此作为燃煤的化验发热量,完成数据库的验证。 3.4.1 燃煤计算发热量 煤的发热量可利用元素分析结果近似获得。式(4)是适用于计算中国煤的低位发热量的回归式[7],根据式(4)可计算出虚拟数据库中各煤质的发热量 在式(4)中:当煤Car>95%或Har≤1.5%时,K1=327,其他煤的K1=335;当Cdaf<77%时,K2=1 256,其他煤的K2=1 298。 3.4.2 化验发热量的获得 近年来,人工神经网络由于具有很强的自学习、自组织能力,在理论上能逼近任意非线性函数,适合对具有多变量、非线性等特性的复杂过程建模,已在各工程领域中得到广泛的应用,特别是在数据预测和函数优化等方面[17]。 BP 神经网络是基于误差反向传播学习算法的神经网络[18],通常由三层组成,每层由若干个神经元构成,层与层之间用权值连接,学习过程由正向传播和误差的反向传播两个过程组成。正向传播时,输入样本由输入层逐层传输到输出层。若输出层的网络输出与期望输出不符,则转向误差的反向传播阶段。网络学习训练的过程就是权值不断调整的过程,此过程一直到网络输出的误差减少到可以接受的程度或者达到预先设定的学习次数为止。 本文借助Matlab 神经网络工具箱,从收集的405 组数据中,选出含有燃煤化验发热量的50 组原始煤质数据(其中,38 组数据作为训练数据,其余12 组作为测试数据),建立燃煤各成分与燃煤化验发热量的关系模型。网络输入层神经元个数i=7,分别为Car,Har,Oar,Vdaf,Sar,Aar和Mar,输出层神经元个数k=1,为 Qydw,隐含层神经元目前没有确定的解析式,常采用经验公式(5)。 k 值的选取依据:依据式(5)选取一个初始值,然后在此值的基础上上下波动,比较每次网络的预测性能,选择性能最好的对应值作为隐含层神经元数。 经反复调试,最终确定隐含层神经元个数j=6。建立的神经网络结构图如图4 所示。Wji,Wki为权重。 图 4 燃煤发热量神经网络结构图Fig. 4 Structure diagram of neural network for coal-fired calorific values 如图5 所示,38 组训练样本的回归系数R=0.986 48,R 越接近于1,拟合效果越好。经计算发现,煤质化验发热量与网络输出发热量相对误差最大值为−3.831%,最小值为0.001%,平均值为2.7%。考虑到煤质现场化验的允许误差,应用神经网络预测的燃煤发热量可作为燃煤的化验发热量。 图 5 燃煤发热量回归系数Fig. 5 Regression of coal-fired calorific values 3.4.3 结果分析 用建立的模型预测煤质数据库的燃煤发热量,并与式(4)计算的发热量作对比。图6 为两种方法获得的部分燃煤发热量对比图。 由图6 可知,网络预测的燃煤发热量与计算发热量在趋势上保持了高度的一致性,两者的最大差值为709 kJ/kg,理论上能够满足工业锅炉用煤的要求。 图 6 数据库煤质网络输出与计算发热量的对比Fig. 6 Comparison between the output of database coal quality network and the calculated calorific value 以型号为SHL10--WⅢ的蒸汽锅炉为例,选用虚拟煤质数据库的煤质,在其他工况、燃烧条件不变的情况下,分析当入炉煤与设计煤种不同时,锅炉热效率[6]的变化。结果如表3 所示。当实际煤种与设计煤种相近时,锅炉燃烧稳定且各参数在正常范围内运行,热效率是随着燃煤发热量的降低而逐步减少的,燃煤发热量越低,热效率降低的速度越大。 表 3 同工况下不同煤种对应的锅炉热效率Tab.3 Boiler thermal efficiency of different coal types under the same working condition 用K-means 聚类算法获取了水分、灰分和煤质干燥无灰基成分的典型值,组合成了虚拟煤质库,并验证了数据库的实用性,分析了锅炉变负荷时燃煤的热效率变化趋势,得出结论: a. 运用神经网络建立的模型能用来预测数据库的发热量,且网络的精度高、泛化能力强; b. 通过比较煤质的计算发热量与预测发热量,发现两者匹配度较好,能满足锅炉实际应用; c. 锅炉热效率是随着燃煤发热量的降低而逐步减少的,燃煤发热量越低,热效率降低的速度越快。3.3 数据预处理
3.4 煤质数据库的验证


3.5 煤质数据库的应用
4 结 论
猜你喜欢
煤化工(2022年5期)2022-11-09 08:34:44
选煤技术(2022年3期)2022-08-20 08:40:10
煤化工(2022年2期)2022-05-06 08:35:56
计量学报(2021年4期)2021-06-04 07:58:22
港口装卸(2020年5期)2020-11-03 09:16:40
Nursing Communications(2019年3期)2019-08-30 08:58:32
电力勘测设计(2017年2期)2017-05-05 06:58:16
中国煤层气(2015年6期)2015-08-22 03:25:30
石油与天然气化工(2015年2期)2015-03-09 03:00:30
现代企业(2015年7期)2015-02-28 18:54:18
