
河南有线的创新应用
——日报数据的自动抓取与填报
2020-01-14 01:03:24苏本国张卫云
中国传媒科技 2019年12期
文/苏本国 张卫云
1.背景
麦肯锡称:数据,已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。在这个时代,公司的决策者、经营者都需要通过数据观察企业运作状态以及规律,没有数据,我们举步维艰。
系统报表能为我们提供各种基础数据,但数据维度和格式固化,不能灵活满足我们的临时需求。所以,手工填报定制的、多变的经营日报(周报月报)是所有经营单位都必须持续开展的日常工作。
Excel灵活而强大,能处理工作中大部分的数据。使用Excel可以方便地制作包含原数据、计算过程和最终展现结果的日报(周报月报)模板。
河南有线信息支撑部在日常工作中,常根据公司领导要求,临时制作各种Excel模板,并根据当时需求,有选择地将各系统平台上的报表数据手工填入临时模板。该工作难度低,重复性强,尤其月初,需要填报的模板在30份左右,每份需要打开的报表页面基本都在10个以上,仅月初就需要6人一天的工作量。
为此,我们尝试寻找一种自动获取数据并填报的方法,最终找到目前排行第一的开源开发工具Python,经过一段时间的学习和研究,我们利用该工具编写了网页爬取、Excel数据填写的可执行程序,成功实现了数据的自动填报工作目标。
2.思路和过程概述
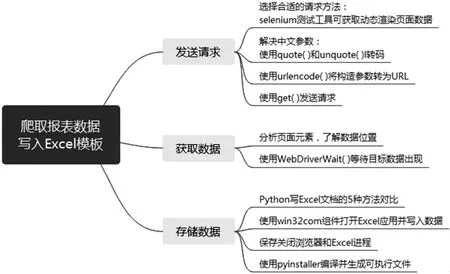
图1
使用python编写网页爬虫的步骤,可分为:发送请求、获取数据、解析数据和存储数据四步。但在实际操作中,因爬取方法不同,我们直接获取到了数据的列表,所以省去了数据解析环节,只保留了三步:发送请求、获取数据和存储数据。每个过程处理细节详情如图1所示:
下面按图示步骤,分步说明在应用程序的编写过程中,每一步遇到的问题及相应的解决方案。
3.编制过程详解
3.1 发送请求
3.1.1 请求页面的三种方法选择
爬取数据,第一步操作就是模拟浏览器向网页所在的服务器发出请求。我们需要抓取的页面是公司内部CRM客户关系管理系统的报表数据,无需身份验证,但请求参数较多,报表数据由JavaScript动态加载。
3.1.1.1 基础的用法,使用 urllib 的 request模块
该模块中的urlopen()方法,可以实现简单的请求发送操作,并得到响应。但该方法在构造带参数的请求时较为复杂。
3.1.1.2 高级用法,使用 requests库
requests库中的方法可轻松实现带参数、cookies、登录验证和代理设置等网页请求,但得到的结果和在浏览器中看到的不一样:在浏览器中可以看到的显示数据,但requests得到的结果中并没有。这是因为requests获取的都是原始HTML文档,而浏览器中的数据则是经过JavaScript处理数据后生成的结果。
云南积极融入服务长江经济带发展战略,有利于云南充分发挥比较优势,把特色资源转化为经济优势,把云南打造成为烟草、能源、冶金、化工、特色轻工基地和承接产业转移基地。
3.1.1.3 模拟浏览器法,使用 selenium 库
为了解决获取JavaScript生成的动态页面数据问题,我们查阅相关资料后最终选择使用模拟浏览器库——Selenium处理。
Selenium是一个自动测试工具,利用它可驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面源代码,做到可见即可爬。注:在使用该方法前,除安装Selenium库外,还需要正确安装好使用的浏览器,如Chrome,并配置好ChromeDriver。
3.1.2 页面分析与构造请求
分析请求参数,打开报表页面,按F12打开“开发者工具”,从Query String Parameters发现URL中所带参数较多,且含有中文参数(地市信息)。针对这样的复杂参数信息,我们采用了“基础地址+参数信息”的方法重新构造URL,然后再使用Selenium库发送请求。在此过程中,遇到了不少细节问题,详情及解决方法如表1所示:

表1
3.1.3 发送请求
根据“分析请求参数”时所获信息,使用selenium库模拟谷歌浏览器向服务器发出请求。获取各地市现金流的脚本编写如下:

3.2 获取数据
打开报表页面,按F12打开“开发者工具”,选中要提取的元素,右键选择“审查元素”,可找到该元素所在的节点位置。由于该元素没有较明确的节点ID,且有较多同类节点,因此采用逐级上查,找到离其最近的有明确节点ID的节点“__bookmark2__”,以便CSS选择器定位待查数据。获取数据脚本如下:

3.2.2 关于延时等待
在调测过程中,发现报表页面自动打开后很快关闭,并没有获得目标数据。资料显示selenium的get()方法会在网页的框架加载结束后结束执行,此时,服务器给浏览器的响应中可能也没有目标数据。因此,这里需要增加延时等待。延时等待分显示和隐式,在本应用中,我们采用了显示等待的方法,在控制语句中增加了WebDriverWait()函数。即:在规定时间内加载指定节点,如果加载完成,则正常返回查找的节点,否则,抛出超时异常。控制脚本如下:


3.3 存储数据
3.3.1 Python 往 Excel中写数据的 5 种方法
Python拥有一个强大的标准库,同时,Python社区提供了大量的第三方模块。完成一项任务可有多种方法,只有选择合适的方法才能达到自己的目标。将所获数据写入Excel时,我们尝试了多种方法,但都无法实现“无损模板地更新”的目标。网上有文章整理了Python写入Excel的4种方法及其优缺点,增加我们自己的一种方法,归纳如下:

表2
其中,使用OpenPyXL修改模板时,只可追加sheet页,但不能更新单元格,会影响表中原有公式;但使用Microsoft Excel则可修改部分单元格数据,且不会影响原公式。因为本应用中既需要读,又需要更新Excel文档中的部分数据,且不能修改原文档中的公式,所以,在此只能使用Microsoft Excel API,即引用win32com组件。
3.3.2 使用win32com组件,修改Excel表中部分数据
写入Excel文档的全过程:调用win32com组件,启动独立的Excel进程,并打开Excel模板文件,使用sheet.Cells(i, j).Value实现给“第i行第j列”单元格赋值。相关脚本如下:


图2

图3
4.成果展现
经过以上三步操作,一个完整的数据抓取和填报程序就完成了,加上友好的参数录入及进度提示住处,再使用pyinstaller将程序编译成可执行文件。将可执行文件和模板一起移置到应用环境中,按周期执行该文件,输入统计需要的参数,即可以直观地看到页面打开过程和Excel数据刷新过程。图2为目标页面逐一打开的过程,图3为Excel文档自动打开的过程,此后,随着Excel数据的刷新,文档中原有计算公式会自动计算,待数据写入完毕,目标数据即为可发布数据。
结语
使用python的扩展库和模块实现获取和使用数据较为简单,本应用使用的扩展库和模块有:selenium、urllib、win32com和datetime等。方便快捷地实现了目标功能,解决常用报表的自动填报问题,在节约人力成本的同时,提高了工作效率和数据准确度。
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
电子制作(2019年10期)2019-06-17 11:45:14
测控技术(2018年8期)2018-11-25 07:42:28
河南畜牧兽医(2017年12期)2017-11-13 04:05:10
环境与生活(2016年6期)2016-02-27 13:46:37
英语学习(2015年6期)2016-01-30 00:37:23
电脑爱好者(2011年11期)2011-06-22 08:20:18
河北软件职业技术学院学报(2010年3期)2010-06-06 07:18:42
中国纺织(2009年7期)2009-08-07 06:56:16
网络传播(2009年5期)2009-05-26 06:47:12
