
基于HDFS的大数据文件传输实验设计
2020-01-13 09:48刘文杰
实验室研究与探索 2019年12期
刘 文 杰
(大连理工大学 软件学院,辽宁 大连 116621)
0 引 言
云计算已经成为互联网服务的重要支撑。通过对软件即服务(Software as a Service,SaaS)概念的扩展和延伸,使云计算能够提供移动化的超级计算服务,以及大型数据中心的数据处理服务[1]。云计算的应用已经成为计算机技术发展的重要方向。
Hadoop是Apache开源组织的分布式开源云计算编程平台,已经成为主流网络应用的重要组成部分,其扩展功能也在不断增强[2]。该平台依靠其在扩展性、经济性、可靠性、高效性等方面的绝对优势,成为海量数据中心、搜索引擎、分布式集群计算等重要应用领域的核心处理平台[3]。由于其开放式框架的特点,Hadoop平台能够在集群平台上处理大型数据库应用,通过HDFS和MapReduce实现备份恢复机制和人物监控,这一理念已经在很多大型网站上得到了应用,可以说是目前最为广泛应用的开源云计算软件平台[4]。Hadoop平台为项目开发过程带来了新的理念,通过并行计算方式发实现分布式计算框架中海量数据的分割,程序设计人员可以在不改变开发方式的情况下,实现云计算应用系统的并行化[5]。Hadoop平台的开放性和可延续性,其优缺点需要在长期的使用过程中加以验证和修正。
1 HDFS体系结构
Hadoop分布式文件系统(Hadoop Distgributed File System,HDFS)主要运行在通用硬件(commodity hardware)上,为分布式计算存储提供底层应用支持[6]。该系统具有高容错性、高吞吐量等特点,使其在较低的硬件资源平台中提供大规模数据及应用,并通过降低POSIX约束,实现流失读取文件系统数据功能。在HDFS的发展初期,主要作为Apache Nutch搜索引擎的基础架构,现在已发展为Apache Hadoop Core项目的一部分[7]。
HDFS采用master/slave架构。通常HDFS集群,配备1个中心服务器节点NameNode,以及多个DataNode代表的存储节点[8]。NameNode主要负责文件系统的namespace管理,包括文件目录和名字的打开、关闭、重命名,同时提供slave端发起的文件访问服务。DataNode主要负责管理其对应的存储节点,使用户通过数据块的方式将文件存储到节点中,及时处理客户端的读写请求,并在NameNode的统一调度下进行数据块的创建、删除、复制和映射。
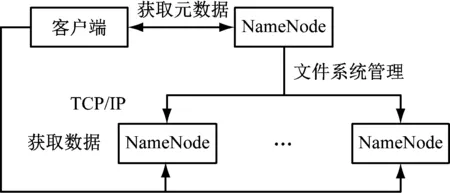
图1 HDFS结构
HDFS采用Java语言进行主体开发,这使得该系统能够运行在通用硬件上,其NameNode和DataNode能够在GNU/Linux系统中正常运行,从而最大限度的扩展该系统的适用性[9]。由于Java语言的可移植性,支持HDFS在不同配置的服务器上部署,从而实现一个实体服务器的NameNode,管理集群中的多个DataNode。该特性高度简化了系统架构,使NameNode成为HDFS元数据的仲裁者和管理者,并且可以通过NameNode备份的方式(Secondery NameNode),提高系统稳定性[10]。
2 HDFS文件传输分析实验设计
(1) HDFS文件读取分析。
步骤1调用HDFS的FileSystem实例的open()方法,实现文件读取;
步骤2HDFS通过RPC调用NameNode,确定开头部分数据块的位置;
步骤3客户端对DFSInputStream调用read()方法;
步骤4通过重复调用read()方法,将数据从各个DataNode传送到客户端;
步骤5当上一步的调用过程达到数据块末端时,DFSInputStream会关闭与DataNode间的连接,然后依据就近原则寻找下一个数据块的DataNode;
步骤6客户端接收到输入流的数据时,按照DFSInputStream传送DataNode顺序进行读取,当读取完成后,则调用close()方法;
当客户端读取数据出现错误的时候,会尝试最近的数据块,并记录发生故障的DataNode,从而避免时间损耗,客户端会确认从数据节点发来的数据的校验和[11]。
以上方法通过NameNode指引客户端对最佳的DataNode进行数据读取,大幅提高并发客户量,从而发挥了DataNode分散部署的优势。同时,也减轻了NameNode的数据流量压力[12]。
(2) HDFS文件写入分析。
步骤1首先使用DistributedFilesystem对象的create()方法,由客户端新建一个文件。
步骤2DistributedFilesystem对象通过RPC访问NameNode,在文件系统的namespace中创建一个新文件。NameNode将会对照namespace中的所有文件,确保新建文件没有重名,并得到客户端创建文件的许可。如果对照过程中未发现重名,NameNode会产生一个新的文件记录[13]。如果对照过程中发现重名,则文件创建失败,并向客户端返回IOException异常,重新执行步骤1。
步骤3新建文件成功后,HDFS会向客户端发送数据输出流DFSOutPutstream对象,客户端接到后开始写入操作。写入的数据会被DFSOutPutstream分解成数据包,写入内部数据队列[14]。
步骤4数据流根据上一步产生的数据队列的DataNode列表,依次访问对应的DataNode,取得数据包,并将数据包向下一个DataNode发送[15]。
步骤5由于DFSoutPutstream中有数据包列表的确认机制,只有在列表中对应的所有数据包都被DataNode确认后,该列表才会被移除[16]。所以,数据包写入过程中,如果出现DataNode故障,数据包列表的访问就会停止,已确认数据包会添加到数据队列的最前方,从而确保链接重新建立的时候,数据包的访问能够从当前位置开始。当前的数据块会被赋予新的身份并在NameNode中体现。同时,删除数据包列表中的故障DataNode,NameNode会重新建立副本,而后再开始步骤4的过程。
步骤6客户端完成数据写入后,在DFSoutPutstream中调用close()方法,将所有包放入DataNode列表中,等待确认。
步骤7向NameNode发送完成信息。
3 实验方法
硬件环境:1台NameNode(IP:*.*.*.106),2台DataNode(DataNode1,IP:*.*.*.107;DataNode2,IP:*.*.*.108)。
网络配置:CentOS 7、hadoop-2.7.1。
3.1 基本配置方法
(1) 配置每台主机环境,将对应IP地址写入主机并关闭防火墙和selinux,创建hadoop组和用户。
(2) 配置hadoop用户SSH免密码登陆(用hadoop账号登陆)。
将每个DataNode节点上的公钥汇总到NameNode的.ssh/authorized_keys文件中。
将NameNode的公钥也加入授权文件,设置权限后分发到各个DataNode节点。
(3) 配置每台主机的JDK环境。
(4) 配置任一台主机的Hadoop环境(以NameNode为例)。
下载并安装Hadoop安装包,同时配置Hadoop环境变量,并修改配置文件,将两个DataNode加入slaves文件;在Hadoop-env.sh、mapred-env.sh、yarn-env.sh3个文件中添加JAVA_HOME值;在core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml文件中添加节点信息。
(5) 将NameNode的用户配置文件和Hadoop复制到其它DataNode节点。
(6) 启动Hadoop。
格式化HDFS文件系统,启动HDFS、YARN、JobHistory Server(MR)。
3.2 测试方法
(1) 测试Hadoop样例程序wordcount。
①在本地磁盘建立两个测试文件 file01和file02
$ echo "hello world hello you" > f1.txt
$ echo "hello hadoop hello me" > f2.txt
②在hdfs中创建wcin目录用于保存测试文件
$ hdfs dfs-mkdir /wcin
③将两个测试文件放到wcin目录下
$ hdfs dfs-put f*.txt /wcin //上传文件
$ hdfs dfs-ls /wcin //查看结果
④执行wordcount对测试文件进行统计,统计结果放入/wcout(目录必须不存在,自动生成)
$ hadoop jar ~/hadoop-2.7.1 /share/hadoop /mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /wcin /wcout
⑤查看wcout目录中生成的结果文件
$ hdfs dfs-cat /wcout/part-r-00000 //查看统计结果
(2) 测试hadoop样例程序pi。
hadoop jar ~/hadoop-2.7.1/ share /hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar pi 100 10000
第1个100指的是要运行100次map任务,第2个数字指的是每个map任务,要投掷多少次 ,两个参数的乘积就是总的投掷次数。
4 结 语
通过对云计算基础理论、云计算关键技术、Hadoop的结构框架以及其中的分布式文件系统(HDFS),为Hadoop的云计算系统模型设计和开发奠定了理论基础和技术支撑。在对传统的Hadoop架构改进的基础上进行云计算系统的分析和设计,采用WEB技术,Java开发语言、JDK、MyEclipse、Tomcat等开发工具,实现了系统的基本功能。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
小学生学习指导(中年级)(2021年4期)2021-04-27
民用飞机设计与研究(2020年4期)2021-01-21
课堂内外(初中版)(2020年5期)2020-06-19
商品与质量(2019年34期)2019-11-29
计算机系统应用(2019年3期)2019-03-11
物联网技术(2018年8期)2018-12-06
中学生数理化·中考版(2015年10期)2015-09-10
中国信息化·学术版(2013年1期)2013-05-28
小说月刊(2012年3期)2012-05-08
