
MIMIC数据库智能挖掘研究概述
2020-01-10 06:49张家艳郑建立郑西川
计算机技术与发展 2020年1期
张家艳,郑建立,郑西川,夏 涛
(1.上海理工大学,上海 200093;2.上海交通大学,上海 200233)
0 引 言
数据挖掘也称作数据库的知识发现(knowledge discovery in databases,KDD)[1],目的是从大量的数据中抽取出有价值的知识。医院数字系统普及产生大量医疗数据,挖掘分析这些医疗数据能够发现相关规律。Ghassemi[2]等使用数据挖掘发现在入院前服用血清素摄取抑制剂或血清去甲状腺素摄取抑制剂的ICU住院病人比一般病人有更高的住院死亡率。
近年来,随着机器学习、深度学习的兴起,将这些算法用到医学领域,能改善挖掘结果。Wu C运用决策树可视化方法发现了老年焦虑病人的影响因素[3]。但数据集过少时,用人工智能技术挖掘结果有时并不理想。深度学习适合数据量和数据维度比较大的情况[4],以至于业界流传一句话为得数据者得天下。而医疗领域,由于医学数据的私密性,研究人员更难获取大量的医学数据。为解决数据量少的问题,文中研究的数据集为由贝斯以色列女执事医疗中心和麻省理工大学计算生理实验室和飞利浦共同支持的重症监护医学信息集(MIMIC-III)。MIMIC包含了在2001年到2012年间53 423个进入重症监护病房的成年病人(年龄在16岁以上),以及在2001年到2008年间的7 870名新生儿的数据[5]。
对拥有庞大数据集的MIMIC数据库进行挖掘,人工智能技术便能发挥巨大的优势。文中旨在介绍围绕MIMIC数据库的内容和研究、深度学习及机器学习在MIMIC数据库挖掘研究的应用领域和不足。
1 MIMIC数据库简介
最近发布的MIMIC版本是MIMIC-III(medical information mart for intensive care),version1.4,它是在MIMIC-II基础上的扩展。MIMIC-II包括在2001到2008年之前几乎所有进入贝斯以色列女执事医疗中心重症监护病房的成年患者[6]。在数据库数据整合进MIMIC数据库之前,需依据美国的HIPAA标准进行去身份化处理[7],进行结构化数据清洗和数据转换。每个病人的住院日期随机转换成了2100年到2200年期间。在HIPAA规则下,这些病人出现在数据库中的年龄都超过了300年。
MIMIC-III是一个由26张表组成的关系数据库。表通过标识符连接,通常会有ID后缀。例如:SUBJECT_ID是指一个单独的病人。像备注、实验室测试和液平衡等事件信息都存储在事件表中,例如OUTPUTEVENTS表包含了与患者输出相关的所有测量值,而LABEVENTS表中包含了一个患者实验室测量结果。前缀有‘D_’的表是字典表,包含标识符的定义。具体可查看http://mimic.physionet.org/mimictables。
MIMIC数据库免费开放给大众,但在获取数据库之前需签署数据使用协议,完成相应题目。在2012年末,已经超过500个用户得到批准使用。获取MIMIC关系数据库的两个工具为:基于网上的QueryBuilder和可下载的虚拟机(VM)镜像[8]。QueryBuilder可以让使用者使用结构化查询语句(sql)在电脑或者移动端的web浏览器查询自己想要的数据,查询后的结果数据集以CSV的形式输出。但为了防止用户过度消耗QueryBuilder上的共享资源,MIMIC-III,v1.4数据库系统设置每次查询仅返回前5 000行数据,查询中运行时间不得超过15分钟,超过了将显示超时,且不返回结果。具体可查看官方文档[9]。由于MIMIC数据库使用者的增多和QueryBuilder的一些限制,官网提供了可供下载的虚拟机(VM),让用户在自己的计算机上运行关系数据库副本。
2 围绕MIMIC数据库的数据挖掘
自MIMIC开始发布至今,人们围绕数据库做了不同主题的挖掘研究,也采用了各种挖掘方法对MIMIC数据库进行研究,下面分别对这些方法进行介绍。
2.1 传统的数据库挖掘研究方法
开始人们采用统计分析的方法对MIMIC数据库的数据进行挖掘研究。采用像Simplified Acute Physiology Score (SAPS)[10]、Acute Physiology and Chronic Health Evaluation (APACHE)[11]、Sequential Organ Failure Assessment (SOFA)[12]等重大疾病计分系统和它们的改进版本来预测结果。SAPS和SOFA的AUROCs能达到0.658(±0.1)和0.633(±0.09)[13]。相对于未加处理的ICU数据,SAPS和SOFA达到的效果还是比较可取的。
2.2 采用机器学习方法对MIMIC数据库挖掘的研究
随着机器学习的出现,机器学习被用于挖掘研究。机器学习是计算机科学的人工智能领域,该方法能够让计算机自己学习相关特征[14]。在机器学习模型中,每个模型都有其适合的场合。支持向量机最原始的目的就是用于二分类,在二分类问题中,K. M. D. M. Karunarathna[15]比较了几种机器学习模型的优劣,结果支持向量机比其他模型有更高的精度。G. Khalili-Zadeh-Mahani等[16]对五种分类技术进行比较,发现在下消化道出血患者中,支持向量机方法有较好的灵敏度和类别加权精确度。Aya Awad等[17]引入集成学习方法,使用了集成学习随机森林、预测决策树、概率贝叶斯和基于规则的射影自适应共振理论模型,发现随机森林具有更高的精确率。这些机器学习模型的表现都要优于传统方法。Joshua Parreco等[18]将梯度提升决策树与传统方法进行比较,发现机器学习方法的AUCs最大。Aya Awad等[17]提出方法的结果优于如SOFA等标准计分系统。表1对上述研究人员所推崇的模型的挖掘结果进行了详细的展示。
2.3 采用深度学习方法对MIMIC数据库挖掘的研究
随着信息时代来临,数据量变得越来越大,传统的浅层机器学习方法已无法更好地处理大数据,深度学习就此产生。深度学习模仿了生物神经系统间的信息交流,利用人工神经网络来抽取简单的特征。
与现有的机器学习模型相比,大多数深度学习得到的结果都比较好。文献[4]将自归一化神经网络(SNN)、SAPS、SOFA、LR计分、随机森林、广义加性模型、贝叶斯自适应回归树、超学习方法的预测结果进行比较,最后发现SNN的AUROC是所有模型中最高的。文献[19]引进一个新的深度学习模型叫做GRU-D,最后得到的AUC分数是所有模型中最高的。Gehrmann等[20]研究人员比较了卷积神经网络(CNNs)和其他常用模型的概念抽取方法。在大多数任务中,CNN表现都优于概念抽取方法,在F1-score中上升了26,在ROC曲线中上升了7%。S. Nemati等[21]采用了深度强化学习的方法,从回顾性数据学习到的序列模型算法的结果比临床指南期望的结果更好。表2对每个模型的预测任务和结果进行了展示。

表1 机器学习模型应用评估
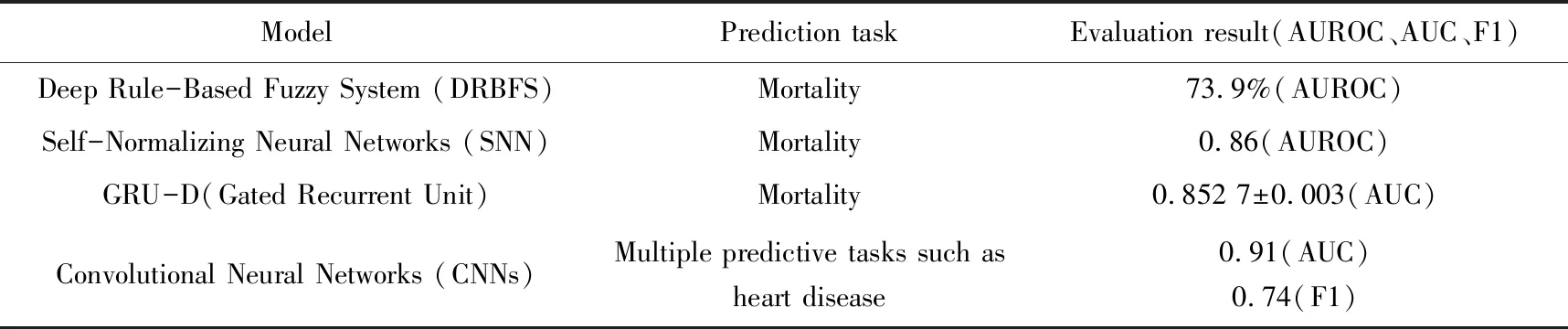
表2 深度学习模型评估
2.4 采用结合模型的方法对MIMIC数据库挖掘的研究
单个模型都有各自的缺点,结合模型综合了这些模型的优点来避免模型的缺点。Sanjay Purushotham等[22]将multilayer feedforward network (FNN)和recurrent neural networks (RNN)两种深度模型相结合,该方法比其他方法的预测结果要好。J.Venugopalan等[23]结合了逻辑回归和前馈神经网络模型的静态模型和条件随机域的暂态模型,组合模型的结果比单个模型的表现要好。表3展示了这些组合模型的评估结果和任务。

表3 组合模型应用评估
2.5 其 他
目前,除了采用上述方法对数据库数据进行挖掘分析之外,还有一些其他的方法。Alharbi等[24]通过过程挖掘模型得到比较好的结果。文献[25]引进存活主题模型更好地显示了病人状况。文献[26]提出了一种暂态数据挖掘方法,运用SW-MATFD挖掘者挖掘重症监护领域的临床数据。Z. He等[27]采用ICD-9-CM编码算法,对老年人口进行分类。关联规则能够在大量的数据中发现有趣的关联关系,转化成供人决策的知识。C. Cheng等[28]首次在ICU中将关联规则运用到CDSS(clinical decision support system)中。
3 围绕MIMIC数据库的挖掘应用
3.1 死亡率预测
现存文献中,对MIMIC进行数据挖掘的一个常见应用领域就是预测死亡率,包括住院死亡率、入院初期死亡率等。
预测ICU病人死亡率能够改善医生治疗效果。文献[15]中通过识别病人死亡的独立因子来预测ICU病人的死亡率。文献[17]预测了入院初期的24小时内的死亡率。J. Venugopalan[23]也通过处理混合的暂态数据和静态数据来预测ICU病人死亡率。
3.2 优化药物用量
在临床中,有些药物的用量有着严格的要求,一旦取量不精确,将会导致无法预计的后果。一些研究人员挖掘研究MIMIC数据库数据得到优化的推荐用量。S. Nemati等[21]通过对大量电子病历数据中样品剂量试验和相关结果进行学习,得到一个优化的肝素剂量策略。该推荐肝素用量的结果比临床指南期望的结果更好。
3.3 电子病历提取语义分析
将MIMIC出院小结里的语义信息提取出来,有利于下一步的临床决策。Gehrmann等[20]对和医疗状况相关的各种短语进行识别和突出。Sanjay Purushotham[22]也采用了其他方法进行ICD-9code分类预测。文献[29]对病例信息进行分析,发现病人积极情感,从而监控病人心理健康状况。Alharbi等[24]对病例信息进行处理,发现一些不易发现的隐藏过程。
3.4 其 他
除了上述应用方面,还有一些方面会围绕MIMIC挖掘研究。文献[23]对ICU病人进行了再入院预测。文献[19]引入了一个新的学习模型来处理多元时间序列缺失值的问题。医生关注的不只是患者的死亡率,还有出院率,文献[25]采用了一种模型来预测病人的出院率。M. Dunitz等[30]开发一种实时的算法将感染性病人分成不同的风险类别来进行感染性休克研究。Z. He[27]研究发现老年人口患的并发症和现在临床研究相对较少的矛盾,从而指导人们花更多的精力开展这方面的研究。
4 工作进展
由于对MIMIC数据库的挖掘研究改善了医疗服务,但这些数据毕竟是国外的,有些并不一定适合国内人群体质,在对MIMIC数据库进行充分的学习研究及参考相关论文之后,采用某三甲医院数据中心的数据参考MIMIC数据库建库的技术手段建立数据仓库。
在建立数据仓库之前,首先需要分析数据仓库的主要用途,确定相应的表结构。目前已经确定了大致的表结构。具体会进行进一步的分析完全确定。确定结构之后,就会对医院的数据进行抽取、清洗、转换,进入数据仓库。
数据抽取的工作难点主要在于医院数据中心数据库比较多,数据库下面的表也比较多,而且有些数据库没有相应的数据字典,对于有些字段的含义就只能靠猜测加验证,从如此庞杂的表中找到所需要的数据是一个费时的过程,还需要将得到的数据抽取转换出来。目前确定的数据抽取工具是kettle,该工具是一款国外开源的etl工具,使用比较方便。
在建好数据仓库之后,会对数据库进行相应的挖掘研究,以期发现一些隐藏的医学信息。
5 结束语
MIMIC数据库包含着丰富的临床信息,对其进行挖掘研究,发现其中隐含的疾病关系,能够改善医疗质量。文中简要介绍了MIMIC数据库,描述了现今对MIMIC数据库进行挖掘研究的方法以及在医学各个领域的应用,其中着重描述了基于人工智能技术机器学习及深度学习对MIMIC数据库进行挖掘研究。
目前机器学习、深度学习对MIMIC数据库信息的挖掘分析研究的领域比较广泛,比如各种疾病的预测、对缺失数据的处理、提取电子病历的语义信息等等。尤其是近年来的论文中,已经很少有研究人员采用传统的计分系统去发现数据库中的医学数据规律。一大批的研究人员都采用人工智能的方法进行挖掘研究,也取得了相对可观的结果,技术手段也相对越来越成熟。
虽然将人工智能技术(机器学习、深度学习等)用于MIMIC数据库挖掘分析已经硕果累累,但是从技术上看,也都存在各自的缺陷。首先机器学习对于小数据集会比较好,对于大规模的数据集,最好使用深度学习。其次由于深度学习对于深层网络的不可解释性,很难调整深层网络来得到一个较好的结果。在文献[26]中,在一些测试数据集中得到的结果反而不如统计机器学习得到的结果好。而且从应用上看,挖掘分析主要集中于死亡率预测和电子病历提取语义分析相关的方面,集中领域比较单一,挖掘应用的广度和深度不够,没有充分应用MIMIC数据库的丰富资源。
然而机器学习和深度学习方法的结合模型能够结合各个模型的优点,得到更好的结果,具有较大的发展潜力。但是现今结合模型在MIMIC数据库挖掘研究应用还较少,研究的领域还比较窄。在将来的工作中,首先可以在MIMIC挖掘研究中更多地使用结合模型。其次应该扩大应用领域,而不仅仅关注死亡率预测那几个方向,大胆应用到医疗的其他领域。最后,应该注重挖掘研究的深度,发现更多的隐含信息。
猜你喜欢
中老年保健(2022年5期)2022-11-25
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
中老年保健(2021年4期)2021-08-22
今日农业(2021年5期)2021-05-22
科学之谜(2020年6期)2020-08-11
电影(2018年8期)2018-09-21
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
