
结合YOLO的ORB双目图像匹配方法研究
2020-01-08 01:59:48张春蕾牛馨苑
小型微型计算机系统 2020年1期
张春蕾,牛馨苑
(兰州交通大学 电子与信息工程学院,兰州 730070)
1 引 言
随着计算机视觉技术的发展,自动驾驶和视频监控等智能化应用愈来愈广泛,双目图像匹配作为双目视觉系统的重要组成部分,已经成为国内外研究热点.在双目测距和三维立体重建[1]等一些任务中需要目标特征点的位置等一些具体信息,因此图像特征点提取和匹配技术在车辆视觉导航等图像处理领域有深刻的研究意义.
随着关注的增加,这些年来新的匹配算法不断被提出,E Rublee等人在SIFT(Scale-invariant feature transform)[1]和SURF(Speeded Up Robust Features)[2]基础上提出ORB[3]算法,该方法利用FAST和BRIEF算法对特征点进行检测和匹配,因具备较好的运算速度和匹配精度被广泛应用.但传统的ORB算法会因为受到环境干扰进而影响匹配精度,造成不同物体之间特征点错误匹配.目前最热门的改进方法是结合深度学习目标识别算法来对图像特征点匹配进行约束,目标检测方法主要分为两种:一种是基于候选区域的方法,例如R-CNN(Regions with CNN features)[4]、Fast R-CNN[5]、Faster R-CNN[6]、R-FCN[7]等;另一种是基于回归思想的SSD(Single Shot MultiBox Detector)[8]、YOLO[9]等方法.在基于深度学习的图像匹配方法上,张博等人先后提出了结合Mask R-CNN[10]和Faster R-CNN两种改进的双目图像匹配方法[11,12],但是因为较复杂的定位分类算法会出现运行速度变慢的情况.因此本文提出基于YOLO的双目图像匹配改进方法,通过目标区域对ORB匹配进行约束.用卷积网络[13]对单目标,双目标和多目标图像提取特征以进行物体检测,采用多尺度预测目标区域坐标和类别信息,使用FAST和BRIEF检测和描述特征点,进行ORB粗匹配,用去误匹配算法比较轮廓信息后去除不同类别和位置信息目标框以外的匹配点,在GPU环境中可以实现基于YOLO的双目图像匹配的实时处理并提升匹配精度.
2 YOLO V3目标检测
不同于其他目标检测算法,YOLO目标识别算法是一种端到端的网络结构,核心是将物体检测任务用回归的方法来处理.使用卷积神经网络直接从整张图像预测物体的类别和坐标位置,还包括预测目标框中包含物体的置信度和分类的可能性,并且使用非极大值抑制方法进行boxes的筛选.为了改善YOLO V2[14]在小目标检测与识别上的不足,Redmon J等人提出了YOLO V3[15]:引入了多个残差网络模块叠加而成的卷积网络Darknet-53,共有53层卷积层,使用了具有良好表现的3×3和1×1的卷积层;采取多尺度预测方式,对不同的数据集都从三个不同大小尺度的预测,提取图像更多特征信息;YOLO V3 继续使用Faster R-CNN中anchor boxes机制作为先验框对图像中的目标进行检测,采用 K-means 聚类算法对数据集的目标框大小进行聚类;类别预测方面对图像中检测到的对象执行多标记分类,损失函数不再使用softmax,而是使用binary cross-entropy loss实现同一个目标物体多个类别的分类.
3 ORB匹配方法
ORB算法是对FAST特征点检测与BRIEF特征描述子的一种结合与改进.兼顾了SIFT方法和SURF方法的准确性和鲁棒性,同时又有较快的运行速度.
3.1 FAST特征点提取
FAST虽然能准确提取特征点、高效且实时性好,但不具备旋转不变性,ORB算法便利用灰度质心法对此进行改进,通过矩的方法计算质心为[4]:
mpq=∑x,yxpyqI(x,y)
(1)
其中 (x,y)为相对特征点的位置,r为圆形邻域半径,其中 (x,y)∈[-r,r],I为图中坐标(x,y)的灰度值,mpq为特征点 (p+q)阶矩,由此得到FAST特征点圆形邻域的质心:
(2)
这里特征点的中心为O,则从特征点的中心到灰度质心C的向量OC的方向为特征点的方向也就是FAST特征点的方向,向量角度即特征点方向:
θ=arctan(m10,m01)
(3)
3.2 BRIEF描述算子
ORB算法采用了BRIEF这种快速的二进制特征描述,通过在图像上的某一点P的邻域内随机选取n对点对,将这些点对的像素值进行比较,然后得到一串二进制结果[4]:

(4)
于是BRIEF描述子可以用二进制向量表示,也就是说可以通过汉明距离进行匹配:
fn(p)=∑1≤i≤π2i-1τ(p;xi,yi)
(5)
4 本文匹配算法
本文提出的匹配算法首先将双目图像经过卷积神经网络处理得到矩形框标注的感兴趣区域和类别标签,然后用FAST和BRIEF算子进行特征点检测和描述,实现双目图像特征点粗匹配;最后根类别和位置信息判断并去除错误特征点匹配,算法实现过程如图1所示.

图1 本文算法流程图Fig.1 Algorithm flow chart
4.1 双目图像YOLO v3目标定位和分类
将左目和右目图像都作为输入传给YOLO网络模型,首先通过特征提取网络对输入图像提取特征,得到一定尺寸的feature map.将输入图像按尺寸划分网格,接着由ground truth目标中心坐标落的网格预测该目标,每个网格都会预测3个目标框,但只用和ground truth的IOU最大那个的来预测目标.输出的特征图提取到的二维特征分别为图片尺寸和3×(5+c),其中c表示类别数,5表示四个坐标信息和一个置信度.tx,ty,tw,th是神经网络的预测输出,下标x,y,w,h表示物体的中心位置相对格子位置的偏移及宽度和高度,均被进行归一化处理.(cx,cy)表示网格坐标,预测边界框的宽和高为(pw,ph),网络的预测值为[16]:
(6)
式中,bx,by,bw和bh是预测出的bounding box的中心坐标和尺寸大小, 坐标的损失采用的是平方误差损失,置信度表述了是否包含物体以及包含物体情况下位置的准确性,预测边界框如图2所示.
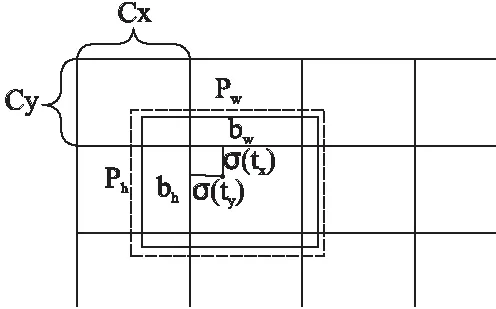
图2 维度先验和位置预测的边界框Fig.2 Boundary box for dimensional prior and position prediction
使用交叉熵损失函数binary cross-entropy loss替换softmax函数实现多标签的分类,因为softmax选择分数最高类别作为当前框类别,分类依赖于互斥假设,即一个对象属于一个类,那么它就不属于另一个类,但是一个目标有可能属于多个类别,比如出现person和women情况时上述假设就失败了.使用逻辑回归预测每个类别的分数,并且用阈值来预测对象的多个标签.分数高于阈值的类别分配给该框.用逻辑回归层对每个类别做二分类,用sigmoid函数将输入约束在0到1的范围内,当一张图像经过特征提取后的某一类输出经过sigmoid函数约束后若大于阈值0.5,就表示属于该类.这样,在双目图像上进行目标检测算法后得出目标预测框和类别,在去除ORB粗匹配的不同目标错误的特征点匹配时,就不会直接认为双目图像中同一位置person和women不是同一目标物体.
4.2 双目图像多尺度预测和特征提取
为了提高双目图像的小目标和多目标识别准确率,YOLO v3对分辨率大小为32×32,16×16,8×8的特征图进行预测,实现了从三种不同尺度的预测,如图3所示.

图3 darknet-53网络结构图Fig.3 Darknet-53 network structure
在darknet-53得到的特征图谱上,经过七个卷积得到第一个特征图谱,在这个特征图谱上做第一次预测;然后从后向前获得倒数第三个卷积层的输出,进行一次卷积和一次上采样,将上采样特征与第四十三个卷积特征连接,经过七个卷积得到第二个特征图谱,在这个特征上进行第二次预测;然后从后向前获得倒数第三个卷积层的输出,进行一次卷积和一次上采样,将上采样特征与第二十六个卷积特征连接,经过七个卷积得到第三个特征图谱,在这个特征上进行第三次预测.
使用K-means聚类方法确定bounding box的初始尺寸,设置先验框是为了使得预测框与ground truth的IOU更好.欧氏距离会让大的bounding boxes比小的bounding boxes 产生更多的错误,本文使用的距离为[16]:
D(box,centroid)=1-IOU(box,centroid)
(7)
式中centroid和box表示中心框和聚类框,IOU(box,centroid)是两者交并比,表示预测框的准确程度,bbgt为真实框,bbdt为预测框,由此得到IOU的值为:
(8)
4.3 目标去误匹配
本文提出的方法将YOLO目标识别算法得到的预测区域坐标和物体类别信息用pickle库进行序列化处理为二进制数据流,然后以文件形式保存,经FAST算子检测特征点和BRIEF算子描述特征点,进行ORB粗匹配,且通过OpenCV提取双目图像中的特征点坐标信息和匹配点数目.设双目图像中特征点的坐标为(xin,yin),其中n=1表示左目图片,n=2表示右目图像,不同i代表不同特征点,第n张图中第m类轮廓区域为snm.遍历左目图像特征点,判断特征点坐标是否在图像中识别出的某一类别的轮廓内[12]:
(9)
若在则继续对这个点在右目图像中匹配点的坐标进行判定,如果满足同一类目标框条件,则通过 OpenCV 保留特征点匹配并且将匹配线画出来;若左目图像中的特征点所属的轮廓区域,与右目图像中特征点配准类别的轮廓区域类别不同,则去除误匹配特征点:
(10)
5 实验结果与分析
为验证本文提出的改进方法的有效性,在基于python语言、PyCharm以及OpenCV实验平台上进行实验.实验所用操作系统为:1)Ubuntu 16.04LTS(GPU:NVIDIA GeForce GTX 1070Ti);2)Win10(CPU:Intel(R)Core(TM)i5-7200 CPU @ 2.50GHz 2.71GHz).实验用到的深度学习框架为Darknet.实验数据一部分来自KITTI双目数据集,原始图像大小为1242×375,另一部分来自海康双目摄像头在实验室中的自采集数据,原始图像大小为1280×720,以下为多组实验中的三组.
图4和图5所示为第一组实验结果图,均是KITTI双目图像数据集中单目标图像,其中图4是采用传统ORB匹配方法的实验结果图,可以观察出有明显的错误匹配,图5采用本文改进方法的匹配图,去除了误匹配,有效提升了匹配精度且汽车单目标匹配准确率较高.

图4 单目标ORB算法匹配图Fig.4 Single target ORB algorithm matching graph

图5 单目标本文算法匹配图Fig.5 Single target algorithm matching graph
图6和图7是第二组实验结果图,为KITTI双目图像数据集中背景环境复杂的双目标图像,其中图6是传统ORB匹配效果图,存在特征点不同物体之间的错误匹配和目标物体以外的冗余匹配点,图7是本文所提算法的效果图,从实验结果可以看出,本文算法能准确识别出人和自行车两类目标的匹配点,实现了双目标匹配精度提高.

图6 双目标ORB算法匹配图Fig.6 Double target ORB algorithm matching graph

图7 双目标本文算法匹配图Fig.7 Double target algorithm matching graph
图8和图9是第三组自采集数据中实验室场景下的多目标双目图像,其中图8是常见的ORB匹配效果图,在复杂图像中的错误匹配率较高,图9是本文所提算法的匹配效果图,从实验结果可以看出,本文去除了不同物体之间的错误匹配点,有效提高了匹配精度,实现了人、椅子、显示器等多目标类别的特征点匹配.

图8 多目标ORB算法匹配图Fig.8 Multi-target ORB algorithm matching graph

图9 多目标本文算法匹配图Fig.9 Multi-objective algorithm matching graph
通过对所有实验数据的匹配准确率结果进行统计(匹配正确率为正确匹配数除以所有匹配数),由表1可以看出本文的算法对匹配准确率的提升效果.
在目标清晰状况下,对多目标双目图像50个特征点的匹配准确率在92.8%,100个特征点的匹配准确率在89.9%,200个特征点匹配准确率在87.2%以上,改进后的算法相比原ORB匹配算法准确率均有大幅提高,证明了本文所提算法的有效性,使用NVIDIA GeForce GTX 1070Ti显卡时处理速度可达22FPS.
本文改进方法与目前主流的结合深度学习Fast R-CNN和ORB匹配方法相比,都是类似于通过区域推荐网络给出的目标区域对ORB匹配进行约束,在对匹配精度的同样提升效果下,本文方法在算法的时间复杂度上表现了更大的优势.ORB粗匹配和去误算法部分的运行时间基本一致,差距体现在目标区域的检测部分,运行速度提高了许多.这是因为YOLO将检测问题转化为了回归问题,直接通过regression同时产生坐标和每种类别的概率,而Fast R-CNN是分步提取region proposal,先判断前景还是背景后再分类.
表1 ORB算法与本文算法准确率比较
Table 1 Comparison between ORB algorithm and accuracy of this algorithm
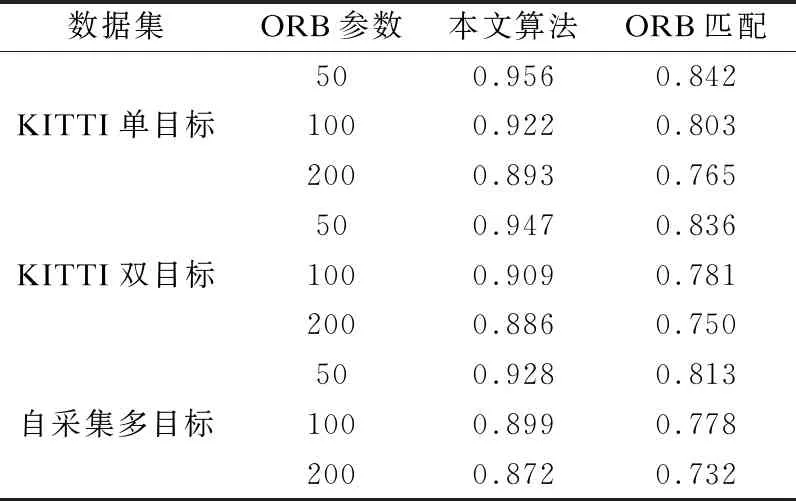
数据集ORB参数本文算法ORB匹配500.9560.842KITTI单目标1000.9220.8032000.8930.765500.9470.836KITTI双目标1000.9090.7812000.8860.750500.9280.813自采集多目标1000.8990.7782000.8720.732
6 小 结
本文根据双目图像应用场景的复杂性导致传统ORB算法匹配准确率下降问题,为提高匹配精度和去除不同物体之间误匹配,提出一种基于YOLO的改进ORB双目图像匹配方法,介绍了一般ORB匹配算法和卷积神经网络实现的目标检测原理和过程,采用多尺度预测方式提升小目标与多目标的识别准确率,研究了KITTI双目数据集和自采集双目图像的特征点匹配,并通过YOLO目标检测方法用Darknet深度学习框架实现多尺度预测以及目标分类和定位,实现了去除不同类别物体之间的错误匹配.
实验结果表明,本文方法较改进前方法在单目标、双目标和多目标双目图像上的匹配精度提高了11.4%以上,匹配精度均在87%以上,在GPU环境下处理速度可达22FPS,较结合其他目标检测改进匹配算法的时间复杂度大大降低且匹配精度有效提升.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年20期)2019-12-04 03:51:38
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
现代计算机(2016年11期)2016-02-28 18:35:20
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电视技术(2014年19期)2014-03-11 15:38:20
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
机械与电子(2014年2期)2014-02-28 02:07:46
