
一种应用于KBQA关系检测的多视角层次匹配网络
2020-01-08 02:00:14朱雅凤
小型微型计算机系统 2020年1期
朱雅凤,邵 清
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
知识库问答(KBQA,Knowledge Base Question Answer)任务是指利用知识库中的一个或多个知识三元组〈Sub,Re,Obj〉来回答自然语言问题.例如,问题“Who created the character Harry Potter” 可以用一组事实
为了检测给定输入问题的知识库关系,现有的方案通常在实体链接生成多个候选关系的基础上,将问题句子和候选关系名称分别映射到向量,然后计算向量之间的相似性作为它们之间的相关性.关系检测作为一个问题-关系匹配任务,大都遵循编码比较范式(encoder-compare framework)[1-9]——这种方案存在两个显著的问题:
1)匹配视角单一:大多数方法只关注〈问题句子,候选关系名称〉一个视角,没有过多地关注问题句子中隐含的主体类型和客体类型信息,而不同的知识库元素可以与问题的不同部分相匹配(例如问题词通常更可能表示答案(客体)类型);
2)编码比较框架存在信息瓶颈:一种常用的方案直接使用最大或平均池操作将序列压缩成固定向量进行语义相似度的比较(Encoding-comparing mode),但导致了信息丢失,另一种对两个序列先使用双向注意力机制进行简单的信息交互再进行聚合操作(Encoding-comparing model with bi-directional attention)来缓解上述问题,但是由于输入信息有限,效果仍然不够理想.此外,现有的关系检测方法通常没有考虑到KBQA的最终任务,而KBQA最终任务既需正确检测关系也需正确检测实体.
基于编码比较范式的关系检测存在两个显著的问题:
1)匹配视角单一;
2)编码比较框架存在信息瓶颈.
本文对每个候选对象构造多个匹配单元,补充构造〈问题模式,主体类型〉匹配单元作为网络的输入,解决匹配视角单一问题.提出一种多视角层次匹配网络M-HMN,使用问题-关系的双向匹配层来来挖掘问题-候选关系之间的深层匹配信息,收集多个分散的证据,通过自匹配注意力层聚合不同重要程度的多个匹配单元的输入,改善信息瓶颈问题.
表1 纯实体链接无法区分同名实体的例子在上面
Table 1 Examples where pure entity links do not distinguish between entities of the same name
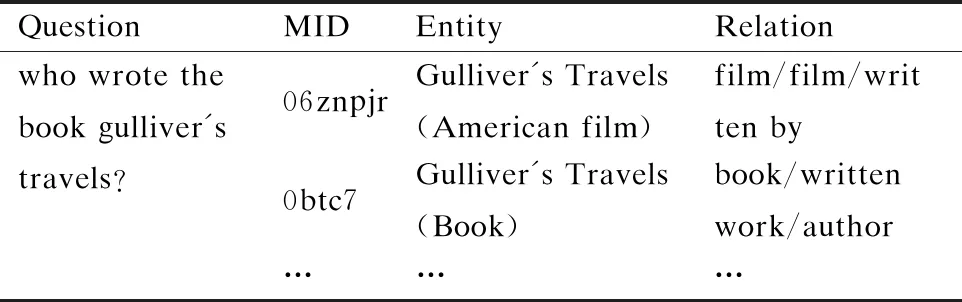
QuestionMIDEntityRelationwhowrotethebookgulliver'stravels?06znpjrGulliver'sTravels(Americanfilm)film/film/writtenby0btc7Gulliver'sTravels(Book)book/writtenwork/author………
关系检测通常运行在实体链接的结果之上,然而我们观察到现有的实体链接器往往无法区分同名实体.例如对于表1中的问题Who wrote the book gulliver′s travels,现有的实体链接器[4]无法区分问题提及的是Gulliver′s Travels(American film),还是Gulliver′s Travels(Book),而误识实体的错误会在后续的关系检测任务中继续传播,因为不同的实体候选对象通常连接到不同的关系,从而使实体链接成为KBQA系统的瓶颈.因此,我们在KBQA最终任务的评估中,使用一种简易的实体重排序算法,利用M-HMN网络进行实体消歧,使正确实体获得比初始更高的排名,然后在一个更小、更为精准的候选实体集中,进行关系检测.
本文的结构安排如下:第2节介绍了KBQA关系检测的系统框架,第3节详细介绍系统框架中的匹配模块,即M-HMN网络,第4节介绍我们的实体重排序算法,第5节介绍了实验设置并分析结果,第6节介绍了该领域的相关工作,第7节总结全文.
2 关系检测网络系统框架
本节介绍我们的 KBQA关系检测的系统框架,首先明确文中概念的形式化定义,接着分别介绍输入模块、编码模块和匹配模块.其中的匹配模块即M-HMN网络,将在第3节重点介绍.图1描述了关系检测的整个系统框架.
2.1 概念的形式化定义
知识库:一种大规模的语义网络图.形式上表达为一个二元组G=(E,R),其中结点e∈E代表实体,边r∈R代表实体之间的各种语义关系.三元组〈esub,r,eobj〉∈G代表知识库中的一条知识.
候选关系池:给定G=(E,R)和问题q提及的知识库实体eq_sub,对于G中任意以eq_sub作为头结点的三元组〈eq_sub,r,eobj〉∈G,Req_sub={r}刻画问题以q以eq_sub为主体实体的候选关系池.
实体链接:给定原始问题q={q1,…,q|Nq|},实体链接将q中的实体提及eq_mention(其中emention⊂q)映射到给定的知识库G的主体实体eq_sub.
关系检测:给定一个问题模式Q,主体实体eq_sub和KB中的候选关系(链)池Req_sub={r1,r2…rk…r|R|},其中,主体实体eq_sub由实体链接标识.关系检测计算rk与问题模式Q的匹配分数S(Q,rk),最终选取得分最高的关系(链)作为关系检测的结果,形式如下:
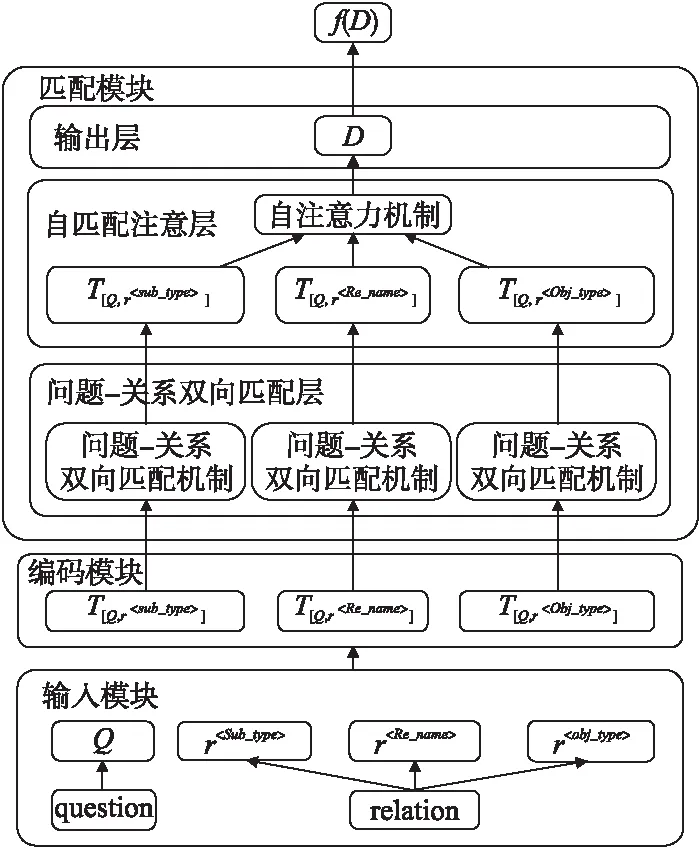
图1 关系检测网络系统框架Fig.1 Relation detection network system framework
(1)
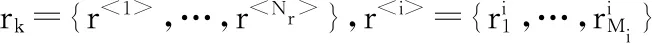
匹配向量:给定任意匹配单元U=[Q,r],匹配层将其转换为相互融合的双向匹配向量T[Q,r].
2.2 输入模块
输入模块对数据进行预处理,通过生成问题模式和生成多个匹配单元得到多对输入视角.
生成问题模式:通过Q=f(q,e)得到原始问题q的问题模式Q,避免q中多余的实体单词e干扰问题和正确候选关系之间的匹配.
生成多个匹配单元:知识库元素(实体或关系)中蕴含的信息可以与问题的不同部分相匹配,我们生成以下三对匹配单元,并在模型中使用这三对输入.
1)[Q,r
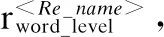
3)[Q,r
2.3 编码模块
编码模块将输入模块的文本转化为计算机可以处理的向量表示,包含编码层和上下文表示层.
2.3.1 编码层
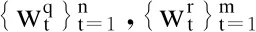
2.3.2 上下文表示层
为了进一步利用周围单词的上下文线索来改进单词嵌入,在编码层的嵌入之上对所有匹配单元使用一个相同的BiLSTM网络来进行序列建模.

(2)
(3)
(4)
(5)
(6)
(7)
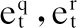
(8)
(9)

2.4 匹配模块
关系检测的核心任务是计算候选关系与给定问题之间的信息交互,为此,我们设计了能够封装并聚合多个匹配单元交互信息的M-HMN网络,其具体实现在第3节描述.
3 多视角层次匹配网络
多视角层次匹配网络M-HMN由问题-关系双向匹配层、自匹配注意力层以及输出层构成.
3.1 问题-关系双向匹配层
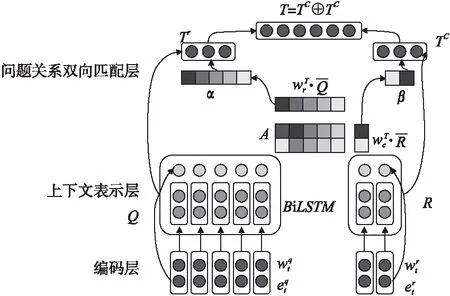
图2 双向匹配机制模型图Fig.2 Bidirectional matching mechanism model diagram
首先对每一对输入的匹配单元U=[Q,r]计算其对齐矩阵:
A=QT·R
(10)
其中A∈Rn×m,A中的每个元素度量Q中每个单词与R中每个单词的语义相似度.在双向匹配矩阵A之上,利用注意力机制[14,15]分别从两个方向挖掘问题和关系之间的匹配信息,可以将其看作是问题关于关系的注意力R-to-Q和关系关于问题的注意力Q-to-R.
·R-to-Q利用点积来计算问题Q的注意力权重向量α:
(11)
(12)
其中向量α∈Rn表示R对于Q的注意力分布,Wr∈Rd×m和wr∈Rd是权重矩阵.接着利用问题的注意力权重向量α,得到关系-问题的匹配向量:Tr∈Rd
Tr=Q·α
(13)
·Q-to-R:采用相似的操作得到问题-关系匹配向量Tc∈Rd:
(14)
(15)
Tc=R·β
(16)
然后将关系-问题匹配向量和问题-关系匹配向量结合起来表示匹配单元U=[Q,r]最终的双向匹配向量:
T[Q,r]=Tr⊕Tc
(17)
3.2 自匹配注意力层
对于关系检测任务,不同匹配单元的匹配向量具有不同的重要性.为了更好地收集这些向量的证据来进行关系检测,使用一个自匹配注意力机制,该将这些信息向量与他们自身匹配,通过捕捉数据的内部相关性来细化向量的表示.该层的输入是来自多个匹配单元的匹配向量,输出是聚合后的问题-关系对表示向量.具体实现如下:
在问题-关系双向匹配层获得各匹配单元的双向匹配向量之后,我们计算该向量的注意力分布:
T=[T[Q,r
(18)
V=tanh(Wh·T)
(19)
(20)
其中γ是注意力权重向量,衡量这些匹配向量的重要性,Wh和wh是权重矩阵.通过自匹配注意力层,最后得到问题-关系对表示D如下:
D=T·γ
(21)
3.3 输出层
最后我们将自匹配注意力层的输出通过一个多感知层转换为最终预测.训练的目的是使训练集中的正例获得比反例更高的匹配分数,因此两两的排序损失定义为:
Loss=max (0,λ+S(Q,r-)-S(Q,r+))
(22)
4 利用M-HMN网络优化候选实体集
在KBQA系统中既要正确检测关系,也要正确检测实体.本节利用M-HMN对初始的候选实体重新排序,实现从一个更小的候选实体集中确定回答问题的知识库核心关系(链),以提高关系检测的准确度.表2详述了该实体重排序算法.
表2 实体重排序算法
Table 2 Entity reranking algorithm

输入:问题q,知识库GG=(EE,R),初始的候选实体列表ELK(q)={e1…ei…e|E|},其中每个实体的得分为Slinker(q,e).输出:重排序的实体列表ELK'rerank(q)初始化q的整个候选关系池Rq=ϕ;fore∈ELK(q)do 利用GG生成e的候选关系池Re={r1…rj…r|R|}; forr∈Redo 利用M-HMN网络计算与q的匹配分数Sr(q,r); 计算e的类型r 实验使用标准数据集—SimpleQuestions(SQ)[16],数据集分为train(79,590)、valid(10,845)和test(21,687),其中的每个问题都已经标注了提及的知识库实体和关系.该数据集只含有单关系问题,即每个问题可用一个知识三元组 实验使用300维预训练Glove[11]词向量表来对单词嵌入进行初始化,对非词汇表的关系和单词进行随机初始化,采样值均匀取[-0.5,0.5],嵌入值在训练过程中更新,LSTM的隐藏层设置为300维,dropout比例为0.2.为了训练模型,在batch为64的小批处理设置中,使用初始学习率为0.001的Adam[18]优化器来更新参数,训练过程中每隔30个epoch进行指数衰减. 所有的实验都在一台使用Nvidia GTX1080 GPU的机器上进行,在Keras2中实现了以Tensorflow3为后台的神经网络.我们选择在开发集上工作的最好的模型,然后在测试集上对其进行评估. 为了探究M-HMN的效果,本文在关系检测和KBQA终端任务两个方面进行消融研究并与几个基线模型进行对比,下面先简要介绍实验步骤. 5.3.1 关系检测效果验证 对于关系检测任务,我们采用Yin等人[4]发布的SimpleQuestions问题关系对集合,基于Freebase子集(FB2M)创建正例和反例,来检验M-HMN模型缓解信息瓶颈的效果.使用参数设置中的数据,对M-HMN、去掉自匹配注意层的M-HMN模型、将QR双向匹配层替换为encoding-comparing model或 encoding-comparing model with bi-directional attention的M-HMN模型进行训练.几个模型的网络参数均为模型学习最好的一组,即获取准确率最高、代价最小的一组参数数值. 5.3.2 KBQA评估效果验证 对于一个好的关系检测模型,它应该能够在KBQA最终任务上也展现出强大的效果.对于KBQA评估,我们的方法从Yin等人[4]发布的实体链接的结果开始,首先利用第4节提出的排序算法对初始实体链接结果进行重排序,排序后的正确的实体应当具有比初始更高的排名,然后综合实体重排序和关系检测得到KBQA的结果.为了探究我们的方法对KBQA终端任务的贡献,实验对使用重排序(Yin[4]的实体链接结果+实体重排序+M-HMN关系检测)和不使用重排序的模型及已有基线相比较,在相同环境下获取其准确率. 5.4.1 关系检测评估结果 表3展示的是不同消融设置下的M-HMN(第5-10行)以及几个基线AMPCNN[4]、HR-BiLSTM[5]、ABWIM[9]、BiMPM[8]模型在关系检测任务上输出的准确率.首先,7-10行中多匹配单元输入的效果总优于单一输入,这表明多对特征输入可以为模型提供丰富的匹配信息以备处理,从输入源头缓解了信息瓶颈.第6行去掉M-HMN的自匹配注意层后,只简单将前一层得到的多个匹配向量串联,比起M-HMN(第5行)准确率下降0.75%,表明了有效聚合多个匹配向量对于关系检测的重要性.正是由于自注意力擅长捕捉稀疏数据的内部相关性,使重要区域的观察精细度更高,才能使聚合得到的最终向量对于重要信息的表达质量更高.第5、7-10行表明,我们的QR双向匹配层比起传统的Encoding-comparing model及Encoding-comparing model with bi-directional attention,对于序列之间重要匹配信息的学习能力更强.我们的关于构造多个匹配单元的思想和整个模型架构与基线BiMPM[8]最接近,但在匹配模块上有所不同.总的来说,多对特征输入提供丰富匹配信息,QR双向匹配层分别编码学得序列对的匹配向量,自注意力层有效聚合多个向量,使得我们的M-HMN能够有效缓解信息瓶颈,呈现出比其他几个优秀基线模型(1-5行)更高的准确率. 表3 SimpleQuestions上关系检测的准确率 图3展示的是M-HMN中QR双向匹配层注意力热力图,横轴为替换掉实体的问题模式,纵轴为候选关系的不同特 图3 QR双向匹配层注意力热力图Fig.3 Attention thermogram for QR bidirectional matching layer 征(Sub_type,Re_name,Obj_type),与问题模式构成不同的匹配单元.图中颜色越深表示其相关程度越高.可以看到,注意力能够有效对齐两个序列,捕捉到相似词串间的语义相关性(比如问题词与答案类型,问题谓语与关系名称,问题的主题定语与实体类型),这有助于之后计算序列的注意力权重得到高质量的匹配向量. 图4展示了问题who wrote the book gulliver′s travels的几个候选关系利用自匹配注意力层得到的不同匹配向量的权 图4 自匹配注意力层注意力权重分布情况Fig.4 Distribution of attention weight in self-matching attention layer 重分布情况.其中r+表示正确的候选关系,r-表示错误的候选关系.可以看到正确关系中各匹配向量的权重分布较为集中,而错误关系中仅仅表示Sub_type的匹配向量权重较大,这表明正确关系中的各个类型的匹配向量均捕捉到了重要的匹配信息,在贡献程度上相当,而错误关系当依赖于正确的实体链接时,仅仅表示Sub_type的匹配向量捕捉到了匹配信息,因此错误关系中几个匹配向量的权重大小较为悬殊.自匹配注意力层的输出向量即为各匹配向量的加权和,它使得稀疏的匹配向量在不同权重的刻画下变得更为精细,也即自匹配注意力层能够选择信息性单元来预测候选关系的正确与否. 表 4 为不同模型训练一个epoch的平均耗时对比.M-HMN的模型架构和思想与其基线BiMPM[8]最为接近,但与需要对每个匹配单元中的anchor 和target使用复杂的匹配策略函数计算匹配向量的BiMPM[8]相比,M-HMN利用一个简单的双向匹配机制即可得到有效的匹配向量.在计算机硬件配置与模型基本参数相同的情况下,M-HMN不但准确率更高(见表3),而且训练一个epoch的平均耗时也比BiMPM更少,训练速度得到了很大的提高.由表3和表4可知,将QR双向匹配层替换为Encoding-comparing model with bi-directional attention的模型,其准确率比BiMPM[8]高0.25,而训练一个epoch的平均耗时更少,这表明我们的模型在较小的时间复杂度上即可获得与基线模型相当的准确率. 表4 不同模型训练一个epoch的平均耗时对比 RowModelMinutes/eachepoch1BiMPM[8]52.02M-HMN48.73去掉自匹配注意层的M-HMN47.04将QR双向匹配层替换为Encoding-com-paringmodelwithbi-directionalattention46.25将QR双向匹配层替换为Encoding-com-paringmodel40.1 5.4.2 KBQA评估结果 对于KBQA评估,我们将利用M-HMN进行实体重排序的结果与初始实体链接结果进行了比较,图5显示了前K个实体候选项的recall(K∈{1,5,10,20,50,100,400}),其中recall计算为实体候选项前K个包含正确主题实体的问题的百分比.第一行(K=1)可以看作是实体检测的精度.从图5可以看出,从top 1到top 100,重排序后的recall都高于原始的实体链接结果,这证明了利用M-HMN进行实体重排序的有效性——重排序后,在较小的候选集中,就能拥有更多有用的信息,并且正确的实体具有更高的排名. 图5 重排序后TopK实体候选项recall对比Fig.5 Recall comparison of TopK entity candidates after reranking 在KBQA最终任务中,当且仅当预测的实体、关系与事实实体、关系都相符时,问题才算回答正确.表5展示了我们的方法在KBQA最终任务上的结果.由于ABWIM、BiMPM均未发布他们的终端KBQA结果,我们只与两个基线AMPCNN、HR-BiLSTM进行比较.可以看到,我们的方法在FB2M设置下的准确率达到78.9%,比最先进HR-BiLSTM高出1.9%.第4行的消融实验表明删除实体重新排序步骤会显著降低分数,由于重排序依赖于M-HMN网络,这表明我们的M-HMN模型对KBQA终端任务性能有着显著的提升. 表5 SimpleQuestions上KBQA的准确率 RowModelAccuracy1AMPCNN[4]76.42HR-BiLSTM[5]77.03M-HMNwithentityre-ranking78.94M-HMNwithoutentityre-ranking78.0 KBQA的主要目标是通过从知识库中获得最佳支撑三元组〈主题-谓词-对象〉(SPO)来回答给定的问题. 关系推断任务是整个KBQA任务的核心部分.Bordes[1]首先将深度学习应用于KBQA的关系推断,此后又开发了各种模型.这些方法大都遵循编码比较范式(encoder-compare framework)[1-9],将问题和候选对象分别映射到向量,然后计算向量之间的相似性作为它们的语义相似性.这些方法的主要区别在于编码器模型(RNN或CNN)和输入粒度(词级或字符级和关系级)的不同.Dai等人[2]提出了relation-level RNN-based approach,将关系作为单一token,用TransE学习的预训练向量进行关系初始化,解决了训练数据中未见关系(unseen relation)的学习问题.Golub等人[3]提出了一种基于增强注意力架构的字符处理方法,引入注意力机制来更好地处理较长的序列.此外,字符级的表示方法不仅减小了参数的大小,而且提高了对词汇表外单词的鲁棒性,使用CNN而不是LSTM来嵌入KB条目,提高了计算效率.Yin等人[4]为了更好地匹配谓词,采用传统的CNN层对问题和关系进行编码,提出一种关注最大池机制来总结问题表示,以便关系表示能更有效地与以关系为中心的问题表示相匹配.Yih等人[17]使用字符三元组作为问题和关系方面的输入.Yu等人[5]使用具有不同粒度输入的Bi-LSTM(包括word-level和relation-level表示)来表示关系,问题由具有不同抽象级别的分层残差Bi-LSTM网络来表示,使得问题匹配不同级别的关系信息的质量更高.Zhang等人[9]提出学习问题和关系之间的词级交互,并将注意力机制引入到单词之间的细粒度对齐中,用于KBQA的关系检测. 以上方法虽然效果显著,但存在匹配视角单一和信息瓶颈等问题.受Yu等人的BiMPM[8]的启发,我们利用来自问题句子和KB的辅助信息,构造多个匹配单元,并提出一种多视角层次匹配网络来融合来自多个匹配单元的信息,一定程度上缓解了信息瓶颈. 在本文中,我们提出了一种新颖的多视角层次匹配网络M-HMN,用于知识库问答(KBQA)的关系检测问题.该方法利用来自问题和KB的辅助信息,挖掘问题-关系的深层匹配信息,取得了较好的实验结果.本文还探索了提出的M-HMN关系检测网络对KBQA终端任务的贡献.在未来的工作中,我们将扩展我们的方法来处理更多多关系问题,如GraphQuestions[19]、ComplexQuestions[20],多关系问题有更多接近人类真实世界的问题,并且需要对知识库进行更复杂的推理.5 实验结果分析
5.1 数据集
5.2 参数设置
5.3 实验设计
5.4 实验结果与分析
Table 3 Accuracy of relation detection for SimpleQuestions dataset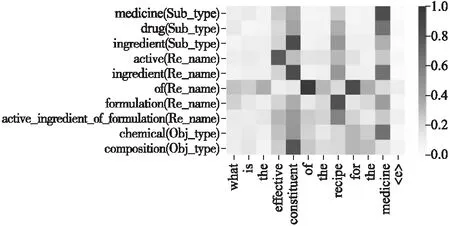

Table 4 Mean time comparison of training an epoch by different models
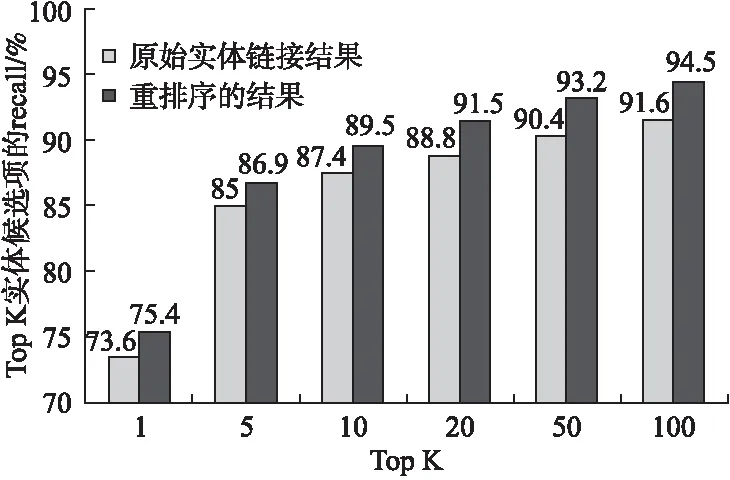
Table 5 Accuracy of KBQA for SimpleQuestions dataset
6 相关工作
7 结 论
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
制造技术与机床(2019年6期)2019-06-25 10:17:46
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国交通信息化(2016年9期)2016-06-06 07:42:23
图书馆研究(2015年5期)2015-12-07 04:05:48
