
基于微博文本的用户人格分析模型研究
2020-01-05 07:00舒晓敏马晓宁
软件导刊 2020年11期
舒晓敏 马晓宁


摘 要:传统的微博用户人格分析将人格分为五类,但未考虑人格类别之间潜在的关联性。为此基于多标签集成分类方法(RAkEL)进行改进,构建RAkEL-PA模型。RAkEL-PA模型使用标签集合中不同的随机子集训练相应的Label Powerset(LP)分类器,然后集成所有分类结果作为最终分类结果。在微博用户文本消息数据上进行实验,结果表明,RAkEL-PA模型的两个不同策略对用户人格分类准确率较高。RAkEL-PA模型充分考虑多个人格之间的相关性,以提高用户人格分类鲁棒性。
关键词:大五人格;人格分析;多标签学习;RAkEL-PA;微博文本
DOI:10. 11907/rjdk. 201356 开放科学(资源服务)标识码(OSID):
中图分类号:TP303 文献标识码:A 文章编号:1672-7800(2020)011-0025-04
Research on User Personality Analysis Model Based on Weibo Text
SHU Xiao-min,MA Xiao-ning
(College of Computer Science and Technology, Civil Aviation University of China, Tianjin 300300, China)
Abstract:Traditional personality analysis of Weibo users divides personality into five categories without considering the potential correlation among personality categories. The multi-label ensemble classification method (RAkEL) is improved to construct the RAkEL-PA model. The RAkEL-PA model uses different random subsets in the label set to train the corresponding Label Powerset (LP) classifier, and then ensembles all the classification results as the final classification result. The effectiveness of RAkEL-PA in personality analysis has been verified experimentally on Weibo users text messages. The experimental results show that the accuracies of the two different strategies of RAkEL-PA are higher for user personality classification. RAkEL-PA fully considers the correlation between multiple personalities and improves the robustness of user personality classification.
Key Words: big-five personality; personality analysis; multi-label learning; RAkEL-PA; Weibo text
0 引言
心理学把个体人格研究与社交网络结合,用社交网络中用户行为数据对用户人格进行分析与预测[1],如工作绩效预测[2]、青少年网络成瘾诱因分析[3]、抑郁症预测[4]、人格与情绪表达关系[5]等,价值巨大。
文献[6]统计地理位置、发布频率等移动互联网用户特征,将人格分类看作三分类和五分类问题实验;文献[6,7,8]分别采用新浪微博、Facebook、Twitter和YouTube数据集进行人格识别;文献[9,10]采用二进制粒子群算法和半监督算法建立社交网络用户人格分析模型;文献[11]将人格分类问题转化为二分类问题;Rosen等[12]针对用户个体网站内容分析用户人格;Ross等 [13]通过研究用户数据得出外向型与组成成员个数关系密切。
以上方法都是将五维人格看作不相干任务执行,而事实上五个维度之间有一定关联[1,6-8,11,14]。本文通过对多标签集成方法—随机k标签集(Random k-LabELsets,RAkEL)[10]进行改进,构建基于微博文本的RAkEL-PA(RAkEL-Personality Analysis)模型,综合考虑五维人格相关性,弥补前人工作的空白。
1 研究流程
人格模型泛指大五人格模型(Big-Five Model),包括外向性(Extraversion,E)、神经质(Neuroticism,N)、宜人性(Agreeableness,A)、责任型(Conscientiousness,C)和開放性(Openness,O)五个维度[1]。
本文研究流程:①获取数据:在微博上发放大五人格量表问卷,志愿者填写问卷以及微博userID,采用userID通过爬虫获取志愿者微博文本数据;②特征提取:从微博文本中提取与人格相关度高的特征,创建人格分析模型的特征属性;③建立模型:构建RAkEL-PA模型;④评估模型:采用分类准确率Accuracy和损失函数Hammingloss两个指标进行评估。
2 RAkEL-PA模型构建
2.1 数据获取
2.1.1 获取用户五维人格得分
在问卷星网站上制作大五人格量表[1]作为调查问卷。制作5个分量表,每个分量表包括5个选项(非常不符合、不太符合、不确定、比较符合、非常符合)12个题目,分别记2、4、6、8和10分,其中有题目反向计分,满分为100分。将问卷发放到微博,志愿者填写问卷,根据得分标注用户五维人格标签。
2.1.2 微博用户数据获取及数据预处理
利用userID使用Python语言编写微博爬虫程序,爬取用户3个月微博文本数据。删除仅含图片、表情等无用数据。
2.2 特征提取
本文使用CCPL开发的中文心理分析系统TextMind[14],产生已验证的76个微博文本特征[14],如表1所示。另外,表情符号更能反应用户情绪,所以本文统计微博消息中含有的表情符号,并统计每条消息的影响力,如表2所示。
由于特征量化为数值后差异巨大,必须对其先归一化[11]。将每个特征进行[0,1]区间归一化,如公式(1)所示。
其中,[f]和[f*]分别为文本特征的原始值和归一化值,[fmin]和[fmax]分别为所有用户相应特征的最小值和最大值。
2.3 RAkEL-PA模型构建
2.3.1 多标签分类方法
多标签学习方法主要有算法自适应和问题转换方法两种[15]。前者主要包括支持向量机[7]和多标签[k]近邻算法(ML-kNN)[16];后者主要有Binary Relevance(BR)[5]和Label Powerset(LP)。
2.3.2 基于微博文本的RAkEL-PA模型构建
LP方法优点是考虑标签相关性,但也存在不足[17],因此将大量标签的集合随机分成很多小的标签集,采用LP为每个小标签集训练多标签分类器,将所有LP分类器决策集成得到RAkEL的最后结果。本文基于微博文本的用户人格分析模型,构建基于人格分析的不相交子集策略RAkELd-PA和基于人格分析的重叠子集策略RAkELo-PA。
确定RAkELd-PA标签集[k]的大小,将标签集合[L]随机分成[m=Mk]个不相交的[k]标签集[Rj],[j=1,2…m]。用LP学习[m]个多标签分类器[hj],[j=1,2…m]。每个分类器[hj]学习一个单标签分类任务,包含训练集中所有[Rj]的子集类值。该策略中不同标签集中的标签不相交,所以标签数越多性能越好[18]。
RAkELd-PA模型训练过程和分类过程分别如图1和图2所示。
RAkELo-PA中[Lk]表示[L]中所有不同[k]标签集的集合。[Lk]大小由二项式系数[Lk=Mk]决定。与RAkELd-PA不同的是,已知标签集[k]的大小以及期望的分类器数量[m≤Lk],RAkELo-PA通过从[Lk]随机采样选择[m]个[k]标签集[Ri],[i=1,2…m]。当[mk>M]时标签集会重叠。
在RAkELo-PA模型上训练过程和分类过程分别如图3和图4所示。
3 实验
3.1 实验数据集和特征提取
本文共收到258份问卷,经过筛选(如:每个问题答案相同)得到有效问卷169份。使用爬虫得到用户在微博上的文本消息。利用文心软件提取文本特征,如表1和表2所示,并进行归一化处理。标签数[M]为人格的五个维度。因此标签集界限是[25]=32,而实际标签集数量范围为此边界的5%~44%[17]。本文标注的标签集中有8种标签集出现次数最多,将集中60%的数据作为训练集,其余作为测试集。
3.2 模型评价指标
本文使用分类准确度Accuracy(A)和Hammingloss(H)评估多标签分类效果。
用[D]表示一个多标签数据集,[D]表示样本个数,[xi]表示第[i]个样本,[yi?L]表示[xi]的标签集,[i=1,2…D]。本文通过学习一个多标签分类器[h]预测实例[xi]的标签集[zi],即[zi=h(xi)]。
分类准确度(A)[18]定义如下:
3.3 实验结果与分析
3.3.1 RAkELd-PA模型实验结果分析
在RAkELd-PA实验中,标签集[k]取2、3和4。[k]值不同模型数[m]也不同。
如图5所示:k=2时,模型的A值最高;k=3和k=4时,A值略低于k=2时,而LP的A值保持不变。原因是同时具有两种人格特质的人较多。随着[k]值增大,[m]变小,参与训练的分类器个数变少,导致RAkELd-PA性能变差。
如图6所示:k=2时,模型H值最小;k=3和k=4时,H值略高,可见随着[k]值增大,H值也在变大,而LP的H值不变。该模型的H最大值和LP的H值接近,说明随着[k]值接近M,模型性能与LP性能相当。
3.3.2 RAkELo-PA模型实验结果分析
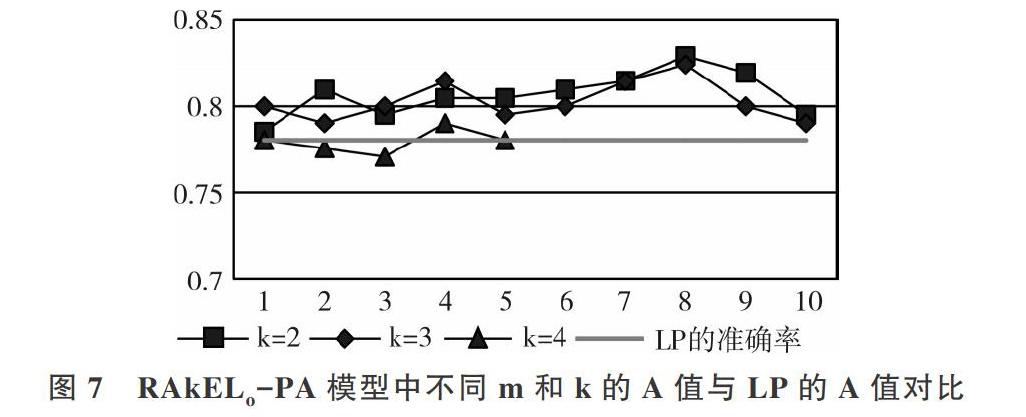
RAkELo-PA模型使用[k](2~4)的所有有意义值进行实验。在k=2和k=3时,[m]范围为1~10,k=4时,[m]范围为1~5。RAkELo-PA模型的分类决策计算方式采用多数投票规则。
如图7所示:①k=2(同时具有两种人格特质)时,A值在m=8时最高,与文献[9]得出的结论一致,即A和C、C和E、C和O、O和E分别具有很强的相关性;②k=3时,A值在m=8时最高,文献[11]也表明,C、A、E,E、C、O,O、A、C分别有强相关性;③k=4时,A值在m=4时最高,与k=2和k=3相比,同时具有4种人格特质的人相对较少,所以A值略低于k=2和k=3時的A值,而LP的A值不随[m]和[k]的改变而改变。
如图8所示:随着[m]值增大,模型的H值在减小。k=2,m=7、8、9时,H值最小;k=3,m=8时,H值最小;k=4,m=3时,H值最小。LP分类器的H值不随[m]和[k]的改变而改变。可以看出,模型的H值均比LP小,说明该模型性能比LP好。
4 结语
针对传统人格分析方法未考虑五个人格维度之间的潜在相关性导致个体人格分类准确率较低问题,提出RAkEL的改进模型RAkEL-PA实现个体人格分类。实验结果表明,具有双重人格特质和三重人格特质的人较多,说明五维人格之间存在依赖性。该模型考虑了五维人格之间的相关性,提高了微博用户人格分类的准确率,从而验证了RAkEL-PA模型对人格分类的有效性。后续考虑获取更多微博用户数据,在更大数据集上进行实验,以进一步验证该模型的有效性。
参考文献:
[1] 张磊,陈贞翔,杨波. 社交网络用户的人格分析与预测[J]. 计算机学报,2014,37(8):1877-1894.
[2] JUDGE T A, ZAPATA C P. The person–situation debate revisited: effect of situation strength and trait activation on the validity of the big five personality traits in predicting job performance[J]. Academy of Management Journal, 2015, 58(4): 1149-1179.
[3] ZHOU Y, LI D, LI X, et al. Big five personality and adolescent internet addiction: the mediating role of coping style[J]. Addictive behaviors, 2017, 64(8): 42-48.
[4] ALLEN T A, CAREY B E, MCBRIDE C, et al. Big five aspects of personality interact to predict depression[J]. Journal of personality, 2018, 86(4): 714-725.
[5] 刘真亦. 不同人格倾向微博用户的情绪表达分析[D]. 杭州:浙江大学,2019.
[6] 孙启翔. 基于移动互联网社交行为的用户性格分析和预测[D]. 北京:北京理工大学,2016.
[7] FARNADI G,SITARAMAN G,SUSHMITA S,et al. Computational personality recognition in social media[J]. User Modeling and User-Adapted Interaction, 2016, 26(2-3): 109-142.
[8] 杨洁. 基于用户情感和网络关系分析的人格预测模型[D]. 上海:东华大学,2016.
[9] 毛雨. 基于社交网络的用户人格分析研究与实现[D]. 北京:北京邮电大学,2019.
[10] 郑赫慈. 网络空间中人格分析的研究与实现[D]. 北京:北京邮电大学,2019.
[11] XUE D, HONG Z, GUO S, et al. Personality recognition on social media with label distribution learning[J]. IEEE Access, 2017, 5(142): 13478-13488.
[12] ROSEN P A, KLUEMEPER D H. The impact of the big five personality traits on the acceptance of social networking website[C]. AMCIS 2008 proceedings: AMCIS, 2008: 223-229.
[13] ROSS C, ORR E S, SISIC M, et al. Personality and motivations associated with facebook use [J]. Computers in Human Behavior, 2009, 25(2): 578-586.
[14] LIMA A C E S, DE CASTRO L N. A multi-label, semi-supervised classification approach applied to personality prediction in social media[J]. Neural Networks, 2014, 58(12): 122-130.
[15] BAI S, HAO B, LI A, et al. Predicting big five personality traits of microblog users[C]. Proceedings of the 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT)-Volume 01. IEEE Computer Society, 2013: 501-508.
[16] ZHANG M L, ZHOU Z H. ML-KNN: a lazy learning approach to multi-label learning[J]. Pattern Recognition, 2007, 40(7): 2038-2048.
[17] TSOUMAKAS G,KATAKIS I, VLAHAVAS I. Random k-labelsets for multilabel classification[J]. IEEE Transactions on Knowledge & Data Engineering, 2011, 23(7): 1079-1089.
[18] TSOUMAKAS G, VLAHAVAS I. Random k-labelsets: an ensemble method for multilabel classification[C]. European conference on machine learning, Springer, Berlin, Heidelberg, 2007: 406-417.
(責任编辑:杜能钢)
收稿日期:2020-04-11
基金项目:中央高校基本科研业务费专项资金项目(3122014C018);中国民航大学科研启动基金项目(09QD02X)
作者简介:舒晓敏(1992-),女,中国民航大学计算机科学与技术学院硕士研究生,研究方向为舆情分析、文本分析、机器学习;马晓宁(1979-),男,博士,中国民航大学计算机科学与技术学院副教授、硕士生导师,研究方向为信息安全、网络舆情分析、机器学习、文本分析。本文通讯作者:舒晓敏。
