
基于Stacking模型融合的工程机械核心部件寿命预测研究
2019-12-24 01:13梁超
软件工程 2019年12期
梁超

摘 要:预测性维护是工业互联网应用的重点,实现预测性维护的关键是对设备系统或核心部件的寿命进行有效预测。随着近年来机器学习的发展,机械设备海量数据已成为工业互联网分析核心部件剩余寿命的关键指标,也成为设备健康管理决策性数据。基于工程机械设备大数据,结合XGBoost、随机森林、LightGBM等多种机器学习模型,多维度探究影响机械核心部件寿命的机器学习模型效果,建立Stacking算法模型融合的部件寿命预测模型,并在核心部件数据上验证模型预测有效性,从而减少设备非计划停机时间,推进智能制造和预测性维护的进步。
关键词:工程机械;寿命预测;机器学习;Stacking
中图分类号:TP181 文献标识码:A
Life Prediction of Construction Machinery Core Components
Based on Stacking Model Fusion
LIANG Chao
(School of Information Science and Technology,Zhejiang SCI-TECH University,Hangzhou 310018,China)
Life Prediction of Construction Machinery Core Components
Based on Stacking Model Fusion
LIANG Chao
(School of Information Science and Technology,Zhejiang SCI-TECH University,Hangzhou 310018,China)
1 引言(Introduction)
在工業4.0的环境下,工程机械设备自动化发展高速,设备部件在传统机械行业运行通信环境恶劣,为工程机械设备监控管理带来了新的挑战。设备部件长期运行,零部件寿命减少,可靠性降低将大大影响工程设备使用,甚至威胁人类生命财产安全。那么及时维护更换工程设备核心部件成为设备健康管理的关键。寿命预测是工程机械设备安全运行的重要基础[1]。早期部件寿命研究指的是基于理论物理学和统计学,计算部件寿命,探索其电压、电流、转速、工作时长、温度等数据挖掘出指标之间的规律[2]。统计学模型则选择合适的寿命分布模型,建立统计学可靠性高的概率性公式研究零部件特征分布,如正态分布、指数分布等[3]。物理学寿命预测模型则是根据零部件运行过程物理感应失效模型,损伤力学,能量等方法对零部件失效类型进行了定义分析,对各类零部件退化机能对应物理模型定义,均偏重理论研究[4,5]。目前已经广泛运用在汽车零部件等制造业中,但是在工程机械使用过程中,存在着数据非线性、不等长、维度多等波动,众多参数甚至是传感器无法及时传播的,导致理论寿命计算出现较大误差。
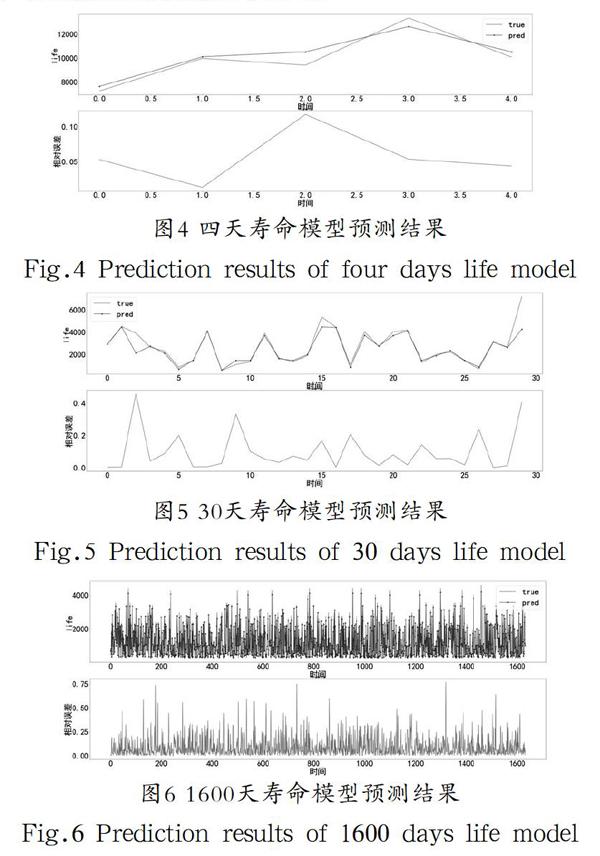
本文运用大数据分析机器学习的方法评估零部件运行中晚期健康状态,数据挖掘分析核心部件电动机在相同情况下历史数据,探究影响机械核心部件寿命指标关联关系,如电流电压、振动、噪声、转速、温度等,结合机器学习K-means聚类分析、线性回归算法、随机森林、LightGBM和XGBoost等方法,构建与寿命相关的高质量特征Stacking集成算法预测模型,可预先知晓设备零部件结果,及时检测更换,有利于在机械设备使用中期发现设备零部件异常状态,增强零部件健康质量把控。
2 工程机械核心部件寿命预测数据处理(Processing of life prediction data for core components of construction machinery)
中期寿命预测是工程设备监控管理的重要内容,主要针对机械设备运行过程中出现的状态把控,防止运行过程中发生意外[6]。很多设备零部件在未充分使用到设计寿命规定年限时,就已经损耗严重需要报废。如果不能及时发现,将会造成很大的影响,设备不合理使用也将会造成极大的浪费[7]。通常在实际使用环境中预测存在较大偏差。因为现实采集到的数据数量庞大,复杂多变,基础数据质量差,能都对大量数据探索性分析研究,从中挖掘出与寿命相关隐藏的信息非常重要。
针对工程机械设备耗损性部件电动机,获取到数据集包含训练集和测试集两部分。训练集中涵盖电动机全寿命物联网采样数据,即从安装后一直到更换之间的对应数据,形式为多维时间序列[8]。字段“部件工作时长”的最大值,即为该部件实例的实际寿命。测试集中包含部件一段时间内的电动机物联网采样数据,基于该段数据,预测电动机此后的剩余寿命。数据集中样本EDA后特征数据字段如表1所示。
数据标准化(归一化)处理,将消除指标之间的量纲影响,解决数据指标之间的可比性,使各指标处于同一数量级,适合进行综合对比评价[9]。采用Min-Max Normalization如公式(1),对数据进行归一化构造量化[0,1]区间,特征缩放后梯度下降过程会更加笔直,收敛可以得到更快的提升,得到数据归一化处理结果如表2所示。
3 工程机械核心部件寿命预测模型构造(Construction of life prediction model for core components of construction machinery)
3.1 K-Means聚类
使用K-Means聚类无须进行模型的训练,无监督学习效率高,处理大数据集,算法保持可伸缩性和高效性当簇接近高斯分布时,效果较好[10]。本文利用优秀的特征进行聚类,使用最小距离分类器MDC进行测试获得最佳K均值聚类k值为5,结果得分如表所示。
猜你喜欢
商品与质量(2021年43期)2022-01-18
铜业工程(2021年2期)2021-06-27
铜业工程(2021年1期)2021-04-23
表面工程与再制造(2019年1期)2019-12-04
汽车观察(2018年9期)2018-10-23
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
科教导刊·电子版(2016年10期)2016-06-02
