
基于RandomForest与SVM算法的流量识别系统
2019-12-13 07:22王璐
数字技术与应用 2019年9期


摘要:随着互联网的飞速发展,根据网络流量识别网络业务的类型,逐渐成为网络技术研究的重要课题。本文将SVM和Random Forest算法应用于流量识别系统的机器学习过程中,首先通过Random Forest算法对采集的数据特征信息进行分析选择,提取出在SVM算法中用来识别流量类型的8个主要特征,进而对数据进行预处理、训练学习,最終完成网络流量的分类识别。通过实验验证,该系统对流量识别准确率达96.7%,对当前的互联网应用的数据流量具有较高的识别准确率。
关键词:SVM;Random Forest;随机森林;流量识别;支持向量机
中图分类号:TP393 文献标识码:A 文章编号:1007-9416(2019)09-0117-03
0 引言
互联网的发展导致了网络业务的种类多种多样,通过流量识别技术去识别网络业务在网络监控管理、用户行为分析、网络信息安全等方面有着非常重大的意义。
在当前的网络环境下,基于端口识别的流量识别方法因为网络隐藏技术的出现已经逐渐失效[1],基于DPI的业务识别技术由于依赖于人工对知识特征库的维护也大大降低了业务识别系统的准确率与有效性[2],相当部分企业已经逐渐开始实践基于机器学习的业务识别系统,因为基于机器学习的网络流量识别方法表现出了较高的准确率,因此也得到越来越多研究者的关注[3-4]。
基于机器学习的流量识别方法就是在生成一个分类器的基础上,利用训练的样本数据先创建一个分类的模型,然后对未知的流量数据进行分类,通过相似性并根据流量的其他特征信息将网络流量划分成不同的聚类。当前的机器学习方法之一贝叶斯法,依赖于样本数据的分布,分类准确性取决于特性和冗余度,而另一种方法神经网络法存在过度拟合和计算量大、复杂的问题。但是另一种SVM方法可以有效减少样本分布,只对某些相关性能存在依赖,因此可以降低冗余度,避免过度拟合现象的发生。
本文的数据来源于测试用户在使用Whatsapp手机软件产生的流量数据,数据特征表现为高维度数据,且数据分布不均。目前针对高维数据的特征简化方案主要分为特征提取与特征选择,由于特征提取方法在简化特征的同时也丢失了原始特征的物理意义,因此采用特征选择的方法对原始数据特征进行降维。研究证明,Random Forest算法在特征选择过程中取得了较好的成果[5]。
基于以上观点,以及数据样本的高维及分布不均特性,本文提出一种基于Random Forest与SVM算法的流量识别系统,与传统的流量识别系统相比,能够对数据特征进行选择简化,大大减少了特征值模块进行特征匹配的工作量,也提升了业务识别的准确率。
1 基本概念
1.1 随机森林技术(Random Forest)
在机器学习中,随机森林是一个包含多个决策树的分类器,其输出的类别是由个别树输出的类别的众数而定。随机森林法是可以用来解决很多实际问题的一种数学方法,尤其在处理大数据和分类问题时性能优越[6]。
对于传统的随机森林分类器模型,决策树的每个节点分裂时,从全部属性中等概率随机抽取属性子集,选择一个最优属性将该节点的样本分裂至左孩子节点和右孩子节点[7]。常用信息熵计算信息增益,采用信息增益度量每个属性划分的纯度,从而选择最优分裂属性。随机森林的训练停止的条件就是训练样本已分裂至树的最大层数,或信息增益低于设定值,或训练样本的数目少于设定值。
1.2 支持向量机技术(SVM)
支持向量机(Support Vector Machine)是由VAPNIK与其领导的贝尔实验室的研究小组开发的一种新的机器学习技术[8]。支持向量机SVM算法支持线性分类和非线性分类的分类应用。相关概念如下:
(1)线性可分:在数据集中,如果可以找出一个超平面,将两组数据分开,那么这个数据集叫做线性可分数据。(2)线性不可分:在数据集中,没法找出一个超平面,能够将两组数据分开,那么这个数据集就叫做线性不可分数据。(3)分割超平面:将数据集分割开来的直线/平面叫做分割超平面。(4)间隔:数据点到分割超平面的距离称为间隔。(5)支持向量:离分割超平面最近的那些点叫做支持向量。
本文使用的SVM方法是从线性可分情况下的最优分类超平面提出的,其基本思想为:首先通过非线性变换将输入空间变换到一个高维空间,然后在这个新空间中求取最优线性分类超平面。
线性可分的支持向量机的特点如图1所示。SVM对不平衡本身并不十分敏感,SVM的超平面只与支持向量有关,因此原离决策超平面的数据的多少并不重要。
使用SVM算法对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是Gap的一半,如图1所示。
2 基于Random Forest与SVM算法的流量识别系统
本文首先通过流量特征提取模块,提取适合在支持向量机中识别的网络流量的8个主要特征,接着对数据进行清洗和预处理,通过对数据进行训练和学习,从而实现整个基于Random Forest与SVM算法的流量识别系统。
2.1 流量识别基本流程
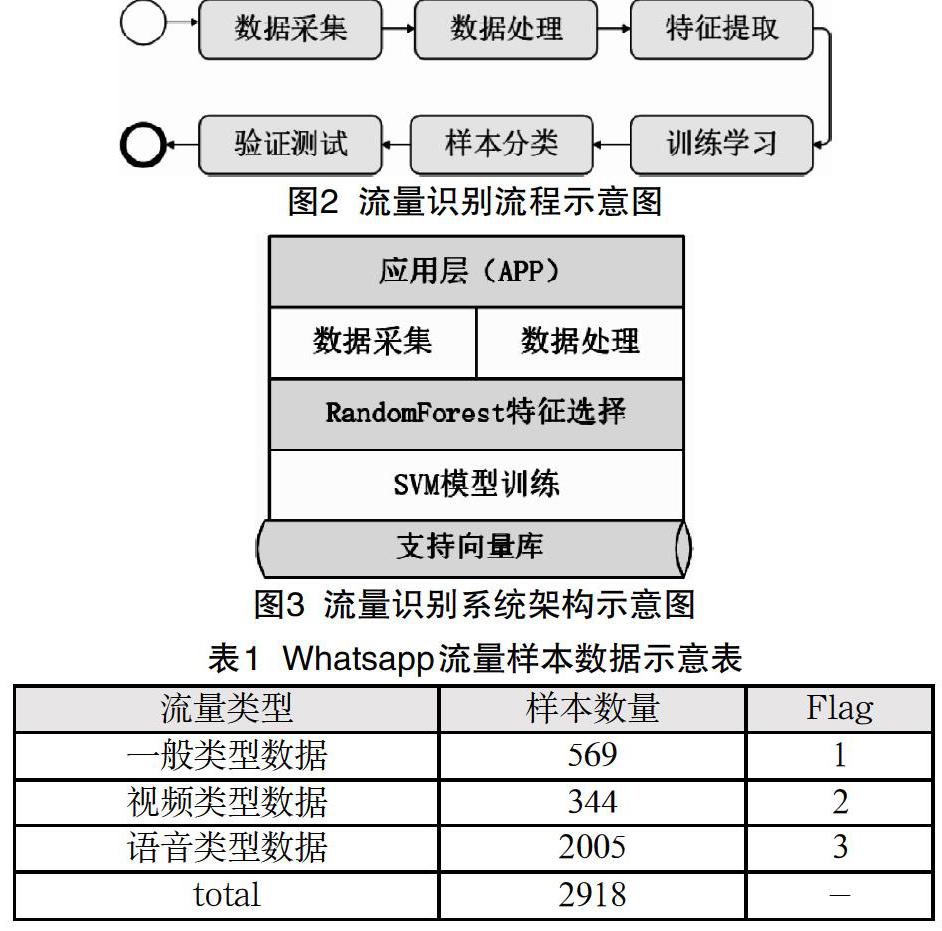
流量识别系统的处理流程如图2所示。第一步,使用Wireshark工具进行用户使用APP的流量数据采集;第二步,对采集到的原始数据进行处理,区分数据的初始维度和初始类型;第三步,使用随机森林的算法构建特征提取模块,对流量数据进行特征选择;第四步,将特征选择后的数据使用SVM算法构建的流量分类识别模块进行分类;第五步,形成训练样本后对数据进行分类;第六步,使用剩余数据进行测试。
2.2 流量识别系统架构
系统的基本功能构建于对采集的流量统计特征信息进行整理,剔除冗余数据,并将其转换为特征向量形式,采用支持向量机的方法将其交给SVM进行训练,训练后得到一组支持向量,即今后的预测模型。将预测模型与预处理过的待预测特征向量数据共同代入SVM的决策函数中,从而判别出该网络流量的类型,如图3所示。
3 实验过程
3.1 实验目的
通过对Whatsapp应用中会话的上下行流量,上下行包数,上下行包流量, 會话时间等维度分析,通过基于Random Forest与SVM算法的流量识别系统实现Whatsapp流量数据中的视频、语音、一般类型(如消息)等流量类型的识别区分。
3.2 实验数据准备与处理
使用Wireshark工具获取到经过Whatsapp的样本数据如表1所示。
样本数据的原始特征维度包含:(源端口,目的端口,开始时间,上行流量,下行流量,上行包数,下行包数,上行平均包流量,下行平均包流量,会话时间,平均包数,平均包间隔)。经过分析,由于源端口、目的端口,开始时间,结束时间跟Whatsapp程序密切相关,故不作为统计维度。
最终选取九个维度的特征进行随机森林分析,分别为:(上行流量,下行流量,上行包数,下行包数,上行平均流量,下行平均流量,回话时间,平均包数,平均包间隔)。
3.3 实验过程
对流量数据的9个特征维度,使用随机森林的算法,得到每个维度的信息熵如表2所示。
根据随机森林特征选择结果可以看出,会话时间所包含的信息熵值最小,因此只选取(上行流量,下行流量,上行包数,下行包数,上行平均包流量,下行平均包流量,平均包数,平均包间隔)这8个数据维度进行SVM算法分析。
由于训练数据样本包含3种类型的数据,且数据样本分布不均匀,其中语音类型数据包含最多,为2005条,是视频类数据的5倍多,样本数据不均衡,根据这一的样本分布特性,使用SVM算法进行分类。
3.4 实验结果
本次实验使用的2918条数据,其中80%用于模型训练,20%用于分类验证测试,测试输入584条数据,系统正确识别类型,共命中正确类型566条,流量类型识别正确率达96.7%,结果矩阵如图4所示。
4 结语
本文将随机森林与支持向量机应用于网络流量类型的识别检测,构建了一种基于Random Forest与SVM算法的流量识别系统,从数据包捕获、预处理、特征选择,识别、学习和训练等流程进行了系统功能的介绍,并且最终证明,此流量识别系统对流量分类具有较高的识别率,说明采用随机森林以及支持向量机对流量识别是十分有效的。
参考文献
[1] 彭立志.基于机器学习的流量识别关键技术研究[D].哈尔滨工业大学,2015.
[2] 王璐.基于DPI及人工智能的业务识别系统的分析研究[J].无线互联通信,2019,16(8):30-33.
[3] ZAREI R,MONEMI A,MARSONO M N.Automated dataset generation for training per-to-per machine learning classifiers[J]. Journal of Network and Systems Management,2015,23(1):89-110.
[4] NGUYEN T,ARMITAGE G,BRANCH Petal.Timely and continuous machine-learning-based classification for interactive IP traffic[J].IEEE/ACM Transactions on Networking (TON),2012,20(6):1880-1894.
[5] 朱珏钰,曹亚微,周书仁,等.基于随森林深度特征选择的人体姿态估计[J].计算机工程与应用,2017,53(2):172-176.
[6] Breiman L.Random forests[J].Machine Learning,2001,45(1):5-32.
[7] 马娟娟.基于改进Grassberger熵随机森林分类起的目标检测[J].中国激光,2019,46(7):1-9.
[8] BOSERBE,GUYONIM,VAPNIKVN. A training algorithm for optimal margin classifiers [C]//Proceedings of the 5th Annual ACM Workshop on Computational,NY,1992:144-152.
Abstract:With the rapid development of the Internet, identifying the types of network services according to network traffic has gradually become an important topic of network technology research. In this paper, SVM and Random Forest algorithm are applied to the machine learning process of traffic identification system. Firstly, Random Forest algorithm is used to analyze and select the characteristic information of the collected data. Eight main features used to identify traffic types in SVM algorithm are extracted, and then the data are preprocessed, trained and learned. Finally, the classification and identification of network traffic is completed. The experimental results show that the accuracy of traffic identification reaches 96.7%, and the system has a high accuracy of data traffic identification for current Internet applications.
Key words:SVM; Random Forest; Random Forest; Flow Recognition; Support Vector Machine
猜你喜欢
南水北调与水利科技(2016年6期)2017-01-06
科学与财富(2016年28期)2016-10-14
