
基于卷积神经网络的堆肥腐熟度预测
2019-12-13 05:55:16胡雪娇梅新兰陈行健徐阳春
植物营养与肥料学报 2019年11期
薛 卫,胡雪娇,韦 中,梅新兰,陈行健,徐阳春*
(1 南京农业大学信息科学技术学院,江苏 210095;2 南京农业大学资源环境与科学学院/江苏省固体有机废弃物资源化高技术研究重点实验室,江苏 210095)
农业废弃物堆肥化利用,不仅能解决其随意弃置造成的环境污染,而且可以为农业生产提供大量的有机肥料,减少化学肥料的使用量,是保护生态环境、节约资源、发展可持续农业的重要途径[1]。在农业生产中,使用未腐熟的有机肥不仅会影响作物生长,而且还会招来地下害虫腐蚀作物根系,微生物的大量繁殖也会造成土壤缺氧增加病原体、寄生虫传播的风险[2]。堆肥生产上常采用腐熟度[3]来表示堆肥化的稳定程度。目前评价堆肥腐熟度的方法有:表观分析法、化学分析法、植物生长分析法及光谱分析法等方法[4],采用这些方法分析堆肥的腐熟状态往往时间长,实验步骤繁琐,堆肥生产上尚缺乏快速、直接的堆肥腐熟度判断方法。因此,亟需研发一种快速有效的堆肥腐熟度的评价方法,为生产实践中堆肥腐熟度的判断提供决策支持。
农业废弃物在堆肥腐熟过程中发生了复杂的生物化学反应,这些反应导致各种物理和化学性质的变化,如堆肥颜色、纹理结构、温度、含水量、C/N、腐殖质含量等[5]。在腐熟过程中,堆肥的纹理和颜色通常发生显著变化,研究表明堆肥的物理形态及颜色的改变可作为判别腐熟度的标准之一[6]。计算机图像分析法能够有效地提取纹理和颜色特征,支持分类和评估不同生物材料的状态[7-8],是农业工程问题中广泛使用的工具[9-12]。近年来,这些方法也被用于堆肥的研究与分析[13-14]。Boiecki 等[15]和Kujawa 等[16]使用神经图像分析法,在多光源的条件下评价堆肥腐熟质量。李治宇等[17]用木醋液对堆肥颜色进行干预,通过HSI 颜色模型判断堆肥腐熟度。现有的研究方法需要多光源、化学试剂等对堆肥进行干预,且研究堆肥种类单一、数据量小。总之,当前国内外鲜有研究者直接将机器视觉方法应用到堆肥现场腐熟度预测中。
随着大数据、人工智能时代的到来,分布式计算以及GPU 计算性能的大幅提升,深度学习在图像识别、文本处理、语音识别等领域掀起了巨大的热潮。Krizhevsky 等[18]运用深卷积神经网络在2012 年ImageNet 挑战赛中获得冠军,从此卷积神经网络在图像识别领域得到了广泛关注。多隐层的深度学习网络能够提取多尺度的图像特征,具有权值共享、尺度不变性和强鲁棒性等特点。卷积神经网络已在作物病虫害图像分割[19]、奶牛个体识别[20]等问题中取得了较好的识别预测的效果。鉴于卷积神经网络图像分析所提供的强大分类潜力,使用卷积神经网络学习堆肥图像的形态、纹理、颜色特征,建立堆肥腐熟度预测模型,并通过大量的堆肥图像样本数据验证模型有效性,实现在可见光条件下快速、准确地识别堆肥腐熟度。
1 材料与方法
1.1 堆肥图像采集
为了使试验材料更加丰富且具有代表性,实验数据采集历时近两年,采集了不同地区、不同季节、白天夜间、多批次的堆肥图像样本。供试堆肥样本采集自江苏、山东、浙江三省,堆肥方式为厂棚内槽式堆肥,采用定期翻堆方式通风供氧。采集自江苏省南京市某有机堆肥厂的堆肥样本原料以秸秆为主,堆肥周期近50 天;在山东省潍坊市某有机堆肥厂采集到的堆肥样本原料为以尾菜为主,堆肥周期近45 天;采集自浙江省杭州市某有机堆肥厂的堆肥原料以畜禽粪便为主,堆肥周期近60 天。在堆肥现场的厂棚内,使用海康威视摄像头监控拍摄,型号为C3W,焦段为广角,焦距2.8 mm,清晰度1080 p,具有夜间自动补光功能,摄像头距堆肥表面约1 m,图像格式为JPEG。白天在自然光条件下拍摄,夜间在摄像头自动感应补光条件下拍摄。采集到的堆肥图像样本均为不同批次生产过程中不同腐熟时期的堆肥图像。
1.2 样本数据集构建及试验方法
按照堆肥原料的不同,构建四组堆肥样本数据集,将采集到的图片切割为分辨率为300 × 300 的堆肥图像样本。第一组堆肥数据集原料为尾菜,由8320 张堆肥图像组成,其中早、中、晚期的未腐熟堆肥图像6720 张,腐熟堆肥图像1600 张。第二组堆肥数据集原料为秸秆,共7760 张图片,其中早、中、晚期未腐熟图片6560 张,腐熟图片1200 张。第三组堆肥数据集原料为畜禽粪便,共6379 张图片,其中早、中、晚未腐熟图片4699 张,腐熟图片1680 张。为了验证模型对不同产地和原料堆肥腐熟度预测效果,分别取三种不同原料的堆肥图像样本按照原料比例约为尾菜∶秸秆∶畜禽粪便 = 1∶1∶1 构成第四组数据集,共9404 张图片,其中未腐熟的图像7428 张,腐熟图像1976 张。不同原料的堆肥图像纹理及颜色存在明显差异,用于实验的堆肥原料为尾菜、秸秆、畜禽粪便的堆肥图像样本示例如图1 所示。不同光照条件采集的堆肥图像样本如图2 所示,夜间图像颜色特征不明显。
堆肥图像数据集分为腐熟和未腐熟两类,腐熟堆肥样本标记为正样本,未腐熟堆肥样本标记为负样本。在每种堆肥数据集中随机取80%的数据作为训练集,将剩下20%的堆肥图像数据单独预留出来作为测试集。测试集不参与模型的训练,用于模型预测效果的检测。在模型验证中,计算测试集的单类精确率和平均识别准确率,并以此作为堆肥腐熟度预测模型效果的评价指标。
1.3 基于卷积神经网络的堆肥腐熟度预测模型构建与训练
1.3.1 卷积神经网络 卷积神经网络模仿人类视觉原理,具有逐层抽象、边缘形状敏感、形状扭曲不变性等特点,是一种权值共享、局部感知的前馈多层神经网络。卷积神经网络不同于一般的神经网络,卷积神经网络中特有的卷积层和池化层组成一组图像特征提取器,能够提取多级图像特征。CNN的卷积层由多个特征平面 (feature map) 组成,特征平面中的神经元通过卷积核与上一层特征平面局部连接[21],卷积核中数据为权值,卷积核按照一定步长在特征平面上滑动计算,实现权值共享。在未训练时,一般以随机小数对卷积核参数进行初始化,在网络的训练过程中通过反向传播算法和优化函数卷积核中的值逐步更新,最终学习到最优参数。CNN共享权值的特点降低了网络的复杂度,并且减少网络过拟合的风险。池化层的作用是在保留数据特征的前提下,缩小数据体尺寸,以减少网络计算量,堆肥腐熟度预测网络模型中采用最大值池化(max pooling)[22]的方式,提取每一个池化窗口的最大值,然后不断滑动池化窗口得到输出图像。全连接层采用线性结构将上一层输出的特征参数连接成一条向量,经过线性变换输出最终的图像特征送入线性分类器输出最终的分类结果。
1.3.2 堆肥腐熟度预测模型搭建 堆肥腐熟前与腐熟后物料的物理形态有较大的改变,利用深度学习强大的特征表达能力提取堆肥纹理特征进行分类,实现堆肥腐熟预测。预测模型的网络结构是由输入层、3 层卷积层、3 层池化层、2 层全连接层和输出层构成。输入图片采用RGB 三色图像,大小为80 ×80 × 3。
卷积层conv1 采用3 × 3 大小的卷积核,步长(stride) 为1,步长较小能够保留更多的图片信息,采用零填充 (padding) 保留图像的边缘信息,经卷积之后生成16 维80 × 80 的特征图。卷积层conv2 输入为16 维40 × 40 的图像,输出为32 维40 × 40 的特征图。卷积层conv3 输入为32 维20 × 20 的图像,输出为64 维20 × 20 的特征图。
池化层采用最大池化,池化窗口大小设为2 ×2,步长为2,池化后生成特征图大小为原图的一半,去掉图片中的冗余信息。池化层pooling1 输入为conv1 输出的16 维80 × 80 图像,输出为16 维40 ×40 的特征图。pooling2 输入为conv2 输出的32 维40 ×40 图像,输出为32 维20 × 20 的特征图。pooling3输入为conv3 输出的64 维20 × 20 图像,输出为64 维10 × 10 的特征图。

图 1 试验中不同原料堆肥不同腐熟时期的图像样本示例Fig. 1 Example images of composts made different raw materials at different maturing periods
全连接层将池化层pooling3 的输出连接成为一个6400 维向量作为该层的输入。全连接层fully_connected1输入为6400 维向量,输出为1024 维的向量。全连接层fully_connected2 输入为1024 维的数据,输出为128 维。输出层的输入为128 维数据,输出为2 维数据,代表两类分类结果。基于卷积神经网络的堆肥腐熟度预测训练网络结构图如图3 所示。
1.3.3 预测模型的优化设计 采用批量归一化法[23](batch normalize,BN) 使图片数据变为均值为0、标准差为1 的分布,在卷积层conv1、conv2、conv3 后添加BN 层,方便数据处理,加快模型收敛,提高网络预测精度。BN 层计算方法如下:

在腐熟预测模型中的批量归一化后加入ReLU作为网络神经元激活函数,可避免梯度消失,卷积层优化过程如图4 所示。
在全连接层中加入dropout 策略[24],增强堆肥腐熟度预测模型的泛化能力,使全连接层具有稀疏性,降低过拟合风险,这里dropout 参数值设为0.5。1.3.4 堆肥腐熟度预测模型训练 将堆肥腐熟度预测模型在四种不同原料的数据集上分别进行训练,在堆肥腐熟度预测模型训练过程中,batchsize 设置为30,最大迭代次数设置为2000,动量因子设为0.9。首先进行前向传播,将RGB3 通道的堆肥图片输入第一层卷积做卷积运算,卷积核初始参数为随机小数,卷积层计算公式为:

图 2 白天和夜间拍摄的不同腐熟状态的堆肥图像Fig. 2 Compost images of different maturity stages taken in the day and night
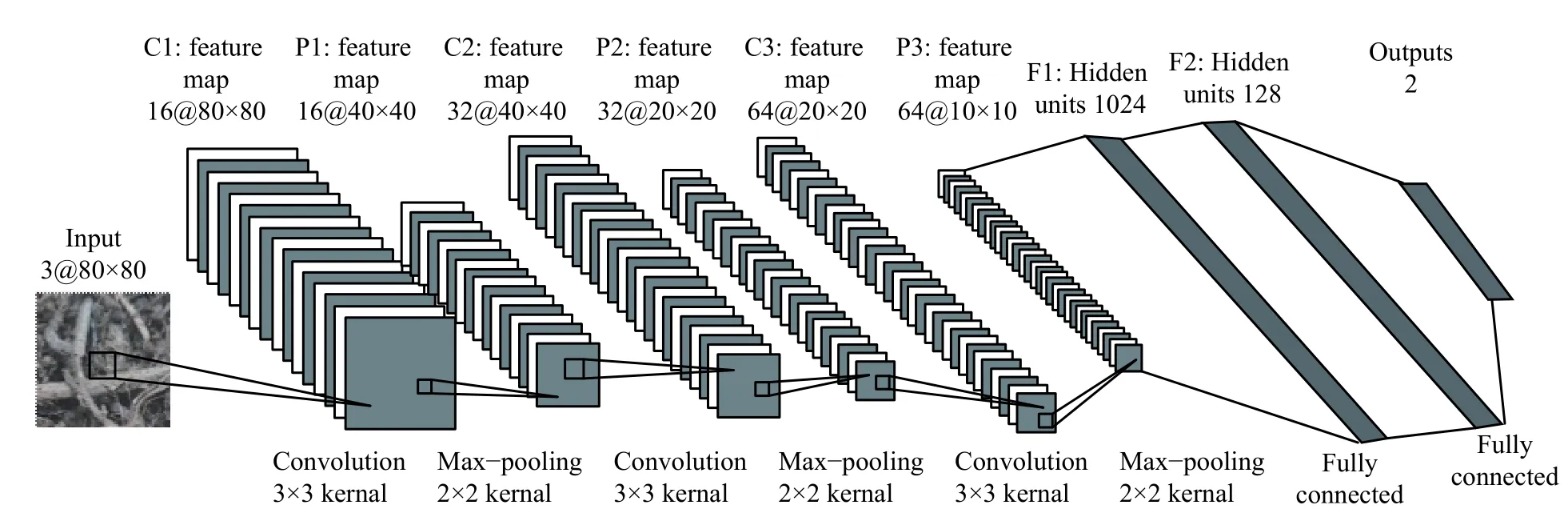
图 3 基于卷积神经网络的堆肥腐熟度预测模型网络结构图Fig. 3 Network structure of compost maturity prediction model based on CNN

图 4 卷积层优化结构图Fig. 4 Optimized structure of convolution layer

式中,l 代表当前层数;x 代表输入图像矩阵;W 为卷积核;b 表示偏置项。然后将sl送入BN 层进行归一化,再将结果送入ReLU 激活函数,将结果送入max_pooling 函数进行最大池化。经过3 层卷积池化后,将结果映射到列向量送入全连接层进行线性变换,最终得到输出结果。
堆肥腐熟度预测模型训练过程中采用交叉熵损失函数(cross entropy loss function)[25]评估模型的损失率。假设有m 个样本组成预测模型训练集,其中,样本xi∈Rn+1,n 为样本维数, yi表示第i 个样本的腐熟类别标记,,0 代表未腐熟类,1 代表腐熟类,表示样本 xi经网络函数hθ计算得到预测值,θ 为网络参数θ ∈Rn+1。其损失函数如下:
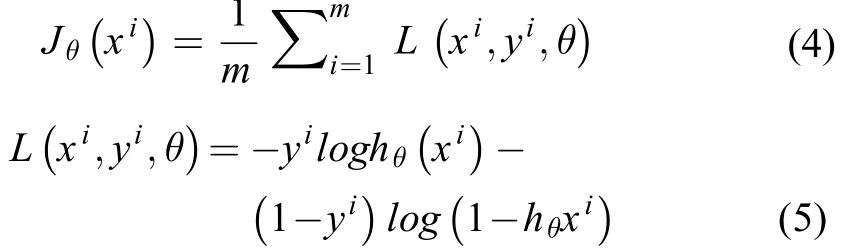
使用批量随机梯度下降算法(Batch Stochastic Gradient Descent algorithm,BSGD)[26]更新模型权值和偏置。假设从训练集中抽取一批 (Batch) 堆肥图像样本是一个相对m 较小的数,在训练过程当中通常为固定值,梯度计算公式如下:
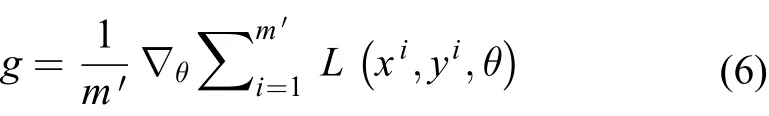
遍历一次批处理样本网络参数则更新一次,θi表示当前参数, θi+1表示更新后的参数,∈ 表示学习率,网络模型参数值更新公式如下:

学习率的选取对模型训练收敛和预测效果有较大影响,这里使用线性衰减学习率,公式如下:
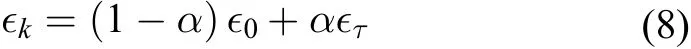
其中,k 为当前迭代次数,τ 被设为一个较大的迭代次数这里设定为2000 次, α=,∈τ通常设为∈0的1%。
制作数据集,每一张堆肥图像对应一个label值,label 值为0 代表未腐熟,label 值为1 代表腐熟。将数据集分为训练集和测试集,数据集中80%的数据为训练集,20%的数据为测试集。使用CUDA 并行计算架构,利用GPU 加速运算,提高模型训练效率。堆肥腐熟度预测模型训练流程如图5所示。
随着训练次数的增加,堆肥腐熟度预测模型的损失值逐渐减少,如图6 所示,训练次数在0 到250 次时误差值下降最快,当训练次数大于750 次时Loss 值近似为0。误差率越小则表明堆肥腐熟预测模型的预测值越逼近真值,由此可见,堆肥腐熟度预测模型取得了良好训练效果。
2 结果与分析
2.1 堆肥腐熟度预测模型训练环境
模型构建使用Pytorch 深度学习框架,CUDA 计算架构;试验环境,Windows10 操作系统、Anaconda-Spyder 开发平台;硬件设施,Intel Core E5-2650 v4 CPU(主频2.2 GHz)、GTX 1080Ti 显卡×2、1 T 硬盘、16 G 内存。
2.2 特征图可视化分析

图 5 模型训练流程图Fig. 5 Flow chart of model training

图 6 堆肥腐熟度预测模型训练误差曲线Fig. 6 Training error curve of compost prediction model
根据图3 中搭建的堆肥腐熟度预测卷积神经网络模型,把图片输入到模型中,输出卷积池化层处理得到的图像。卷积池化层构成的特征提取器能够提取图像的边缘、轮廓、线条、颜色等特征信息。图7、图8 以原料为尾菜的堆肥样本图为例,分别给出了卷积神经网络提取未腐熟和腐熟图像的特征图。从图7、图8 可以看出,未腐熟的堆肥枝干线条较为明显,提取到的纹理特征为线条状,腐熟堆肥纹理类似于砂砾,图像纹理较为细致。这里只给出尾菜堆肥的特征图,而总体上不同种类的堆肥在不同腐熟时期的图像特征具有共性,未腐熟堆肥纹理粗糙,粒度大,原材料物质形态明显,腐熟堆肥纹理纹理细致,粒度小。卷积神经网络能够敏锐地感知到不同时期堆肥图像的粒度差异,准确地提取到堆肥外观特征。这里由于不同拍摄环境光照对图片的颜色有很大影响,仅仅通过堆肥图像颜色区分堆肥腐熟度误差较大。然而,堆肥的纹理特征不受光照的影响。因此,与颜色特征相比,堆肥的纹理特征更稳定。在判断堆肥腐熟度时,堆肥纹理特征更加重要。堆肥过程中的水分变化对图像特征影响不大。卷积神经网络模拟人类视觉特点,既保留了图像的颜色信息,也提取了轮廓、线条、粒度等具有代表性的特征,从而避免了因光照条件对图像识别能力的影响。从特征图中可以看出,模型不同程度地提取了堆肥的颜色、纹理特征。深层网络结构学习能力强,提取到的部分特征图较抽象,提取到的堆肥特征更加丰富。卷积过程中的提取到的特征图像不仅保留了整体堆肥图片的颜色纹理特征,也得到了局部具有代表性特征,体现了卷积神经网络局部感知的特点。网络层数越高,感受野就更广,参与运算信息就更多,提取到的特征就更加全面。
2.3 堆肥腐熟预测结果与分析
为了检验堆肥腐熟度预测模型的预测效果,使用单类精确率和平均识别准确率对堆肥腐熟预测模型进行评价[27],公式如下:
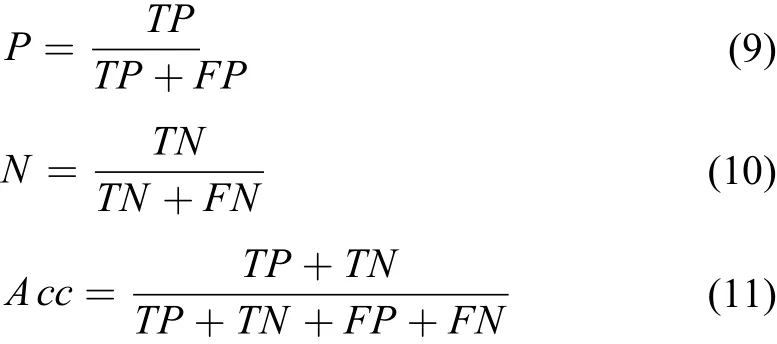
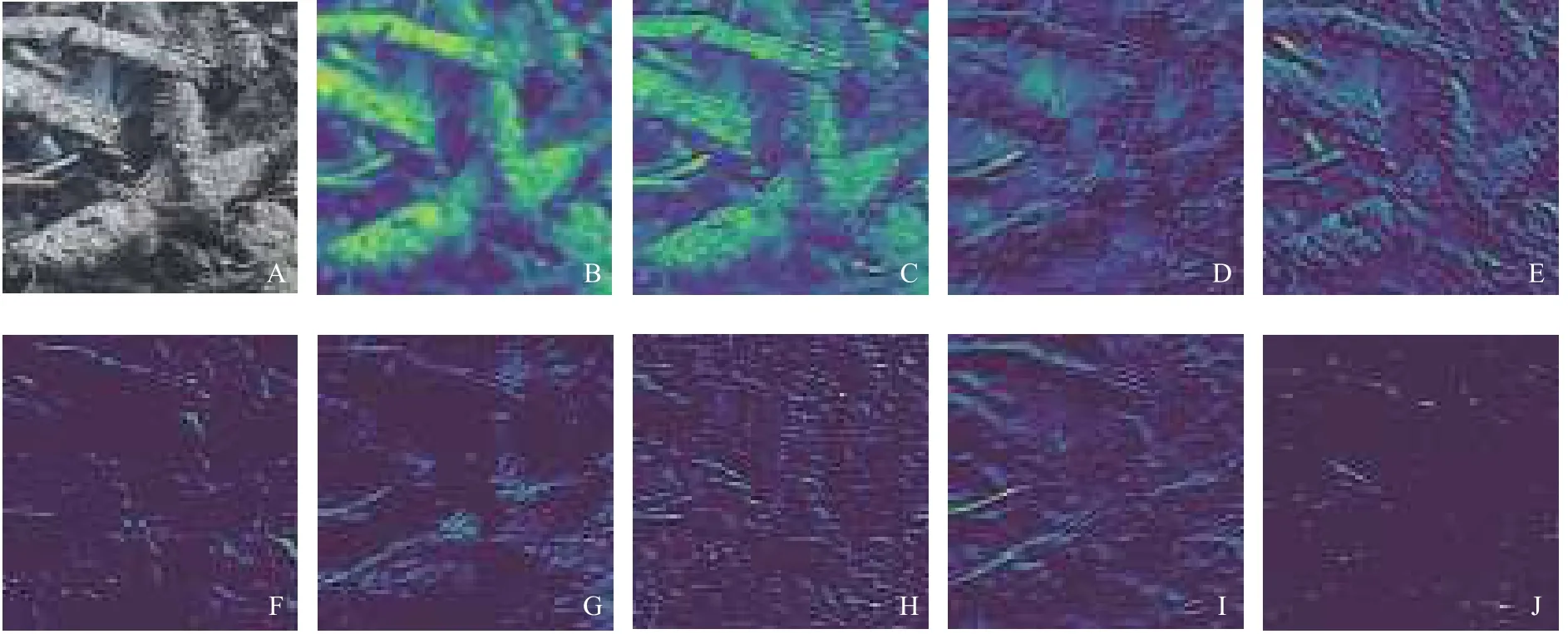
图 7 卷积池化层提取的未腐熟堆肥图像特征可视化图Fig. 7 Visualization of immature compost image features extracted by convolution and pooling layer
图 8 卷积池化层提取的腐熟堆肥图像特征可视化图Fig. 8 Visualization of mature compost image features extracted by convolution and pooling layer
式中,TP 为正确识别腐熟类个数,FP 为错误识别腐熟类个数,TN 为正确识别未腐熟类个数,FN 为错误识别未腐熟类个数,P 为腐熟类识别精确率,N 为未腐熟类识别精确率计算公式,Acc 为平均识别准确率公式。
将四组堆肥原料分别为尾菜、秸秆、畜禽粪便和3 种原料混合数据集中的测试集分别送入堆肥腐熟度预测模型中进行检验,预测结果如下表所示:
由表1 可知,尾菜堆肥、秸秆堆肥、畜禽粪便堆肥数据集平均准确率为98.7%、98.7%、98.8%,腐熟类及未腐熟类的识别精确率均在98.1% 以上,证明了模型的可靠性。为了提升模型的鲁棒性,将3 种堆肥图像等比例混合进行试验,结果如表1 混合原料列所示,未腐熟类识别精确率为98.3%,腐熟类识别精确率为97.7%,平均准确率达到了98.2%。实验结果表明,搭建的基于卷积神经网络的堆肥腐熟度预测模型对不同原料、颜色、纹理的堆肥腐熟程度判别均有优异的效果。数据集中包括白天和夜间采集到的堆肥图像样本,以及不同堆肥原料其颜色差异较大。从结果可以看出,堆肥纹理特征在腐熟度判断中更加有效。
卷积神经网络多隐层的特点,使其能够表达高层次的抽象特征,预测模型中层数越高,提取到的特征就更加全局化。深度网络模型能够提取多尺度、多层次的堆肥图像特征,这包括了堆肥的形态、纹理、颜色等全方位信息。因此,基于卷积神经网络的堆肥腐熟预测模型有如此高的识别率。卷积之后连接的池化层能够实现对堆肥图像进行聚合特征、降维来减少网络的计算量。实验中用了大量的堆肥图像进行训练预测,验证了模型的有效性和普适性,这得益于深度学习模型庞大的吞吐量。
不同来源的同种堆肥原料在原料形态及颜色上略有差异,但是依旧遵循未腐熟堆肥纹理粒度大,腐熟堆肥纹理细致的特点。下面我们分析基于CNN的腐熟度预测模型对不同来源的同种原料的堆肥图像的敏感性。
取三种堆肥原料的堆肥数据集中的不同批次的堆肥图像,送入文中搭建的CNN 腐熟度预测模型,取出网络模型的全连接层的倒数第二层的输出共128 维的特征向量来描述网络提取到的堆肥图像特征,计算不同来源的同种堆肥原料图像特征的差异性。实验堆肥图像如图9 所示。采用欧氏距离和偏差均值作为差异性的度量,其公式如下:
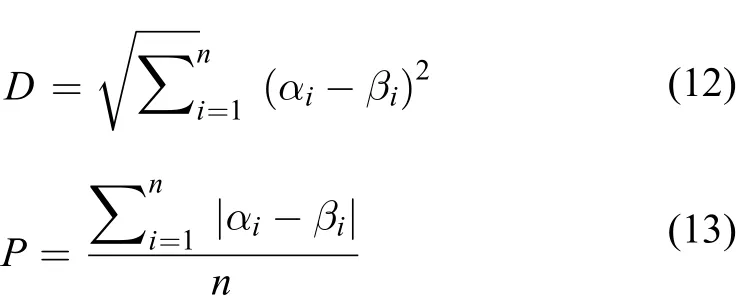
式中,n 为特征向量的维数,α、β 为两种不同的特征向量,αi代表α 特征向量的第的i 个值,βi代表β 特征向量的第的i 个值,D 代表欧氏距离,P 代表偏差均值。
根据表2 可得,同种类别的两种不同来源的堆肥图像的特征向量的欧氏距离在2.24~3.45,偏差均值在0.12~0.24,差异较小;腐熟与未腐熟堆肥图像的特征向量的欧氏距离在8.02~18.51,偏差均值在0.51~1.04,差异较大。同种原料的不同来源的堆肥图像,经过卷积神经网络训练学习,能够缩小其差异提取其共性特征。可以得出结论,同种类别不同来源的堆肥图像的微小差异不会对基于CNN 的堆肥腐熟度预测模型提取特征及分类产生影响。
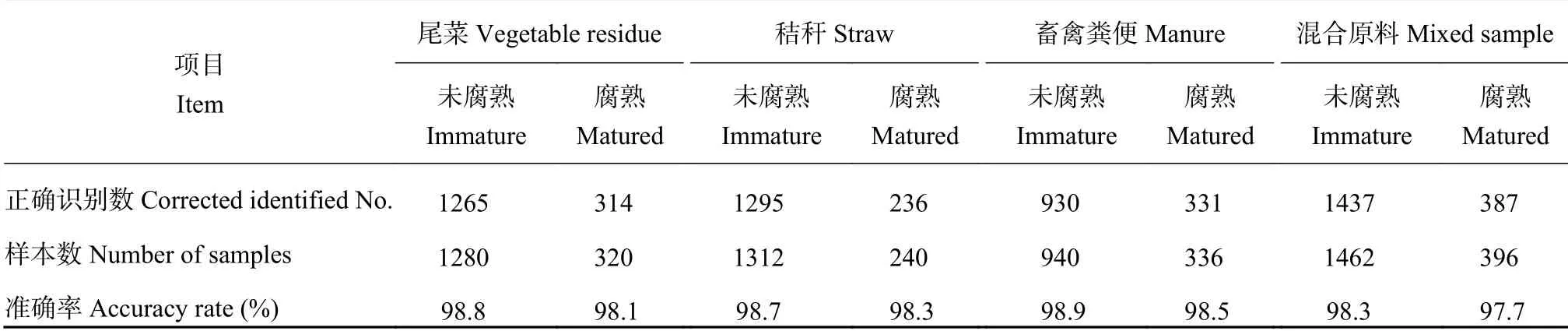
表 1 各原料堆肥腐熟度正确识别数量及准确率Table 1 Correctly predicted number and robust of the maturity of compost e samples predicted by the prediction model

图 9 不同来源、批次的不同腐熟程度的堆肥图像Fig. 9 Compost images of different sources and batches with different maturity

表 2 不同来源、批次和腐熟度的堆肥间的特征差异Table 2 Differences in features of compost from different sourcesbatches and mature degrees
2.4 与传统特征算法的比较
将几种经典高效的特征提取算法与卷积神经网络进行对比。第一组对比试验用SIFT(尺度不变特征变换,scale-invariant feature transform) 特征提取算法提取在堆肥图像提取50 个128 维的SIFT 特征点,采用K-means 聚类方法将得到的SIFT 特征点进行聚类构建视觉词袋模型词典[28],k 类别设为100 类,统计每一张堆肥图片的SIFT 特征点在每一个类别中的分布频率,构成堆肥图像的视觉词袋特征。第二组试验使用稀疏编码 (sparse coding,SC) 构建堆肥图像特征,首先提取堆肥图像块,使用K-SVD 字典学习算法构建120 维稀疏字典,使用最大池化方法降维得到堆肥图像最终的稀疏编码特征[29]。第三组对比试验采用LBP(局部二值模式,local binary pattern) 算法对堆肥纹理特征进行提取,将堆肥图像分成3 × 3 的小窗口,计算每个小窗口中心像素的LBP 值,统计堆肥图像的直方图作为LBP 特征。前三组对比实验中,均采用SVM(支持向量机,support vector machine)做分类器。第四组对比试验与Kujawa 等[16]提出的经典堆肥腐熟度评价方法,即使用灰度共生矩阵 (graylevel co-occurrence matrix,GLCM) 和颜色矩方法提取堆肥的纹理和颜色特征,BP 神经网络作为分类器实现堆肥腐熟度的预测。第五组对比试验提取图像的颜色矩[30]特征,使用SVM 进行分类。计算五组方法在四组数据集中测试集的平均准确率,试验结果如表3 所示。
从表3 可以看出,在SIFT、SC、LBP 和GLCM这四种经典的图像特征提取方法中,SIFT 特征和SC 特征提取算法表现一般,LBP 特征算法在三种数据集和混合数据集上的预测结果为分别为84.2%、89.2%、87.8%和88.6%,LBP 特征在尾菜和秸秆数据集上表现较好,LBP 是一种经典的图像局部纹理特征提取算法,具有灰度尺度不变、旋转不变等特点,它描述的是中心像素值与邻域像素值的相对关系,局部的二值化在颜色变化明显的区域会出现明显的边缘能够突出图像的纹理特征。在畜禽粪便数据集上颜色矩特征表现较好,在该类堆肥数据集中堆肥腐熟前后颜色变化大于纹理特征变化。
基于文中搭建的卷积神经网络的堆肥腐熟预测模型在三种数据集和混合数据集上的预测结果分别为98.7%、98.7%、98.8%和98.2%,较每类结果最优的经典特征提取算法预测准确率提升了3 至14 个百分点。LBP 只能够提取单层的纹理特征,而文中搭建的卷积神经网络模型在每层用一组级联的卷积加权滤波器和激活函数对数据进行映射,从低层到高层、多角度地描述不同腐熟程度堆肥图像的纹理特征。卷积神经网络中的池化层能够去掉图像中的冗余信息,精准地描述图像特征。LBP 算法中的参数是固定的,而卷积神经网络中的反向传播网络特点使其拥有自学习能力,通过不断地根据腐熟情况训练堆肥图片样本进行网络调参,使输出结果尽可能地逼近真值,最终实现较好的堆肥腐熟度的预测识别效果。
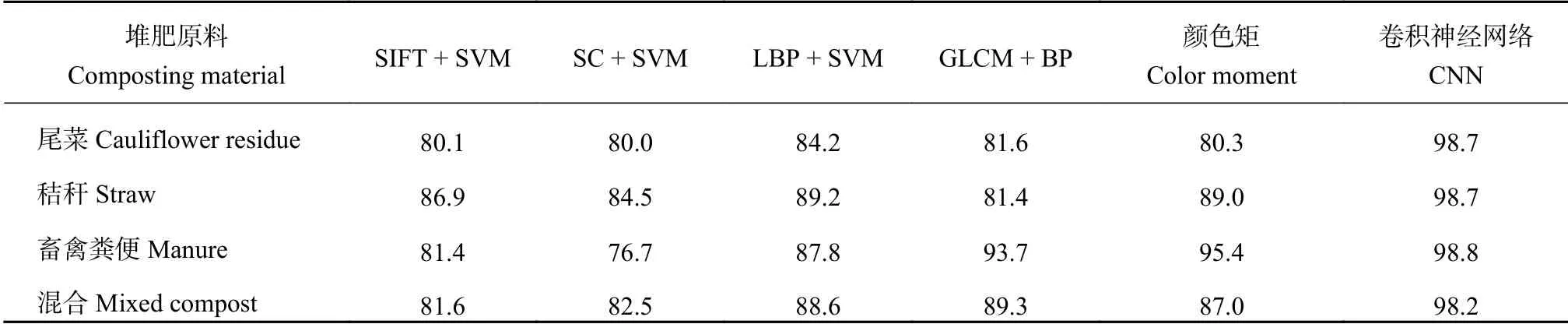
表 3 不同经典特征提取算法腐熟度预测结果准确率 (%)Table 3 Prediction accuracy of the maturity by different classic extraction algorithms
3 讨论与结论
本研究首次提出基于卷积神经网络的堆肥腐熟度预测模型,并对模型进行优化,优化后的模型具有优异的堆肥形态、纹理、颜色特征学习能力,取得了较好的预测效果。根据堆肥的产地和原料的不同,采集了大量的堆肥图像,最终用于实验的堆肥图像样本数量近3 万张,样本呈现多样性和丰富性,避免了前期研究者的选取图像特征不足不具代表性等缺点。试验结果表明,堆肥纹理特征在腐熟度判断中更加有效,并且堆肥过程中的水分变化对图像特征影响不大。腐熟模型在3 种不同原料堆肥上的准确率均在98%以上,在混合堆肥图像数据集上的准确率达到了98.2%,较每类数据集上最优的特征提取算法提升了3~14 个百分点。卷积神经网络中的卷积层和池化层能够准确地提取图像特征,多层网络的结构可以提取多层特征,弥补了经典特征提取算法中只能提取单一层次特征的缺陷。
基于卷积神经网络的堆肥腐熟预测模型实现了在可见光条件下即可通过堆肥图像判别堆肥腐熟度,更加符合实际应用场景中的情况,能够为生产实践中堆肥腐熟度判断提供有力支撑。对于其他的原材料的堆肥,可以通过迁移学习方法在目前已经训练好的堆肥腐熟度预测模型的基础上进一步强化训练,对模型参数进行微调,使模型能够更加适用于其他原材料堆肥的腐熟情况的判断。文中已经训练好的基于CNN 的堆肥腐熟度预测模型,能够准确地提取堆肥纹理及颜色特征。堆肥在生产过程中,不同原材料的堆肥仅是在物料形态上有所差异,其纹理特征均是由粗变细的一个过程,可以通过将待测原材料的堆肥图像送入网络模型中,进一步训练网络。采用迁移学习的方法无需对网络进行重新训练,在模型已经较高的判断某种堆肥腐熟度的“知识储备”及“识别能力”的基础上,用另一组堆肥数据集对模型继续训练,通过学习两种堆肥的差异性,对网络模型中的池化层、卷积层及全连接层的权值和偏置等网络参数进行调整。该方法要比重新训练一个“零基础”的网络模型能够更快地达到较高的识别率。
本文的腐熟预测模型推广较容易,迁移学习的方法使文中的堆肥腐熟度预测模型具有较强的移植性。在堆肥原材料不同的情况下,在现有训练好的腐熟度预测模型基础上通过迁移学习进一步训练,可使用推广堆肥厂的堆肥图像样本对模型的内部参数进行微调,使模型更加适用于推广堆肥厂的生产过程。另外,部分堆肥图像采集现场环境较为恶劣,需要考虑采集设备的稳定性。
在堆肥腐熟过程中,温度和湿度数据也是两个重要的物理指标,在接下来的研究中将在提取堆肥纹理及颜色特征的基础上,融合温湿度数据,进一步提升模型的准确性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
软件(2020年3期)2020-04-20 01:45:18
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
Coco薇(2017年8期)2017-08-03 15:23:38
Coco薇(2015年5期)2016-03-29 23:22:15
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
