
一种低成本语音识别解决方案*
2019-12-11 02:23张鹤鸣
通信技术 2019年12期
张鹤鸣,邓 军
(中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引 言
语音识别技术,又称为自动语音识别(Automatic Speech Recognition,ASR),它是以语音为研究对象,通过语音信号处理和模式识别让机器理解人类语言,并将其转换为计算机可输入的数字信号的一门技术。语音识别技术将繁琐的输入劳动交给机器处理,在解放人类双手的同时,还可以有效提高人机交互效率,在信息化高度发达的今天,已经成为信息社会不可或缺的组成部分。
语音识别引擎是ASR技术的核心模块,它可以工作在识别模式和命令模式。在识别模式下,引擎系统在后台提供词库和识别模板,用户无需对识别语法进行改动,根据引擎提供的语法模式即可完成既定的人机交互操作;但在命令模式下,用户需要构建自己的语法词典,引擎系统根据用户构建的语法词典,将匹配度最高的识别结果提供给用户。
今天,ASR技术已经被应用到各种智能终端,为人们提供了一种崭新的人机交互体验,但多数都是基于在线引擎实现。本文针对离线网络环境,结合特定领域内的应用场景,提出了一套实用性强,成本较低的语音识别解决方案,实现非特定人连续语音识别功能。第二章本文从方案的主要功能模块入手,对涉及到的关键要素进行详细的分析描述,同时对实现过程中的关键事项进行具体分析,并提出应对措施。第三章根据方案设计语音拨号软件,并对语音拨号软件的功能进行科学的测试验证。最后一章对全文进行总结。
1 低成本的语音识别解决方案
(1)主要功能划分
在特定领域内的语音识别,主要以命令发布为主,以快捷实现人机交互为目的。比如在电话通信领域,我们常以“呼叫某某某”、“帮我查找某某某电话”为语音输入,这些输入语音语法结构单一,目的明确,场景性较强,本方案决定采用命令模式实现语音识别功能。方案主要包括四个功能模块:语音控制模块、音频采集模块、语音识别离线引擎和应用数据库模块,各模块的主要功能及要求如图1所示。
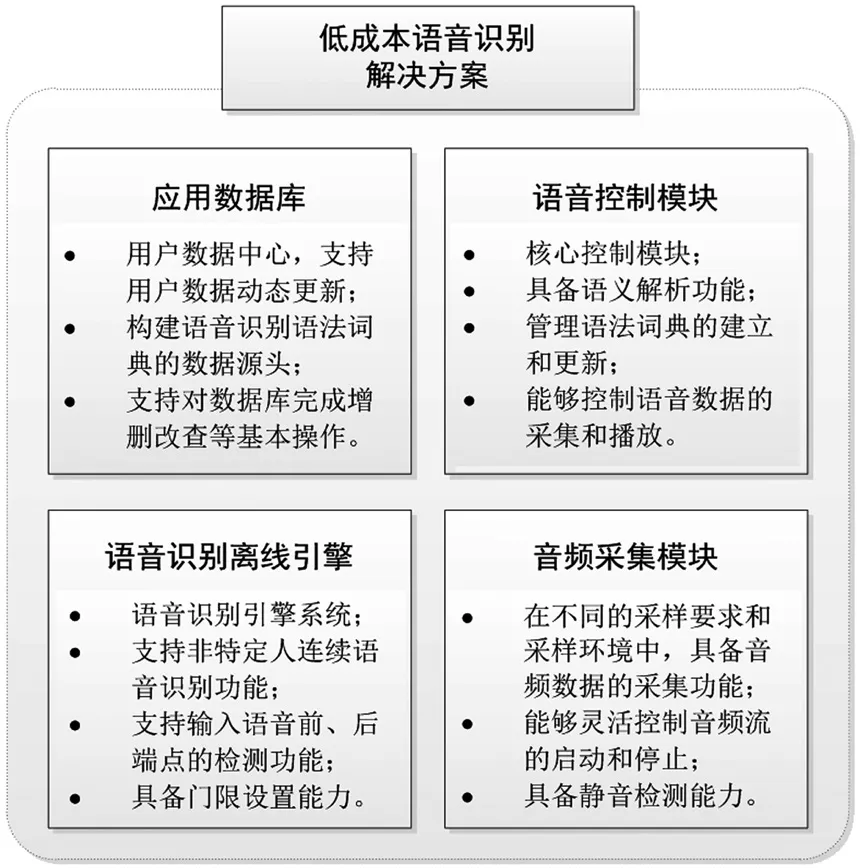
图1 低成本语音识别解决方案功能模块
语音控制模块作为方案实现的核心模块,主要用于实现语音识别的控制管理功能,包括语法词典的构建、语音识别引擎的初始化配置、音频数据的采集控制和基本语义的解析等;应用数据库是用户的数据中心,作为语音识别数据的源头,语音控制模块从中提取用户关键数据,并以此为基础构建本地语法词典;语音识别离线引擎是语音转换为文字的关键模块,支持在离线的情况下,根据本地构建的语法网络,完成非特定人连续语音识别功能,同时具备语音数据前、后端点检测、声音除噪处理、识别门限设置等基本功能;音频采集在本方案中属于辅助模块,具备灵活、便捷的语音控制接口,支持在不同采样要求和采样环境中,对实时音频数据的采集。
(2)关键要素分析
本方案工作于离线的网络环境中,语音数据的采集、识别和语义的解析等功能都在终端完成,因此设备性能的优化和语音识别的精准度尤为重要。在具体的实现过程中,存在以下要素需要重点关注。
1)用户构建的语法文档在引擎系统初始化时,编译成语法网络送往语音识别器,语音识别器根据语音数据的特征信息,在识别网络上进行路径匹配,识别并提取用户语音数据的真实信息,因此语法文档的语法结构是否合理,直接关系到识别准确率的高低;
2)应用数据库是作为语音识别数据的源头,其中的关键数据如果有变化,需要及时同步更新本地语法词典,以保证离线语音识别的精准度;
3)音频数据在离线引擎中的解析占用CPU资源,因此音频采集模块在数据采集时,需要开启静音检测功能,将首端的静音切除,不仅可以为语音识别排除干扰,同时能有效降低离线引擎对处理器的占用率;
4)为保证功能的实用性和语音识别的精准度,需要在语音采集过程中增加异常处理操作。首先在离线引擎中需要开启后端静音检测功能,若在规定时间内,未收到有效语音数据,则自动停止本次语音识别;其次,需要在离线引擎中开启识别门限控制,如果识别结果未能达到所设定的门限,则本次语音识别失败;
5)通过语音识别接口,向引擎系统获取语音识别结果时,需要反复调用以取得引擎系统的识别状态,在这个过程中,应适当降低接口的调用频率,以防止CPU资源的浪费。
2 语音呼叫软件的实现
语音呼叫软件广泛应用于电话通信领域,是一款典型的在特定领域内,实现非特定人连续语音识别功能的应用软件。由于其部署场景较多,部分场景处于离线的网络环境中,适合采用本方案进行软件设计。
2.1 软件实现
在语音呼叫软件中,语音识别准确率的高低是影响方案可行性的关键要素,离线引擎作为语音识别的核心,它的工作性能直接关系到软件的可用性。本软件在实现过程中,选用业界口碑较好的讯飞离线语音识别库,该库采用巴科斯范式语言描述语音识别的语法,可以支持的离线命令词的集合,满足语音拨号软件的工作需求。其中,编写的语法文档[1]主要部分如下:
!start <callstart>;
<callstart>:[<want>]<dial>;
<want>:我想 |我要 |请 |帮我 ;
<dial>:<dialpre><contact>[<dialsuf>];
<dialpre>:给 !id(10001)|打给 !id(10001)|打电话给!id(10001)|拨打!id(10001)|呼叫!id(10001);
<dialsuf>:打电话!id(10001)|打个电话 !id(10001)|拨打电话!id(10001)|拨电话!id(10001)|拨个电话!id(10001)|的电话!id(10001);
<contact>:丁伟 |李平 ;
本文件覆盖了电话呼叫过程中的基本语法,其中<contact>中的数据,需要根据用户数据库进行补充,其它 <want>、<dialpre>、<dialsuf> 中的内容,用户根据自己的生活习惯和工作需要进行完善。另外,语音拨号软件的应用数据库为电话薄数据库,电话薄中的用户姓名是构建语法文档的关键数据;音频采集模块采用增强型Linux声音架构ALSA库实现。

图2 语音拨号软件工作流程
2.2 软件工作流程
语音拨号软件的工作流程如图2所示,电话薄数据库、语音识别控制模块、讯飞离线识别引擎和ALSA库相互配合,共同完成语音识别的启动、识别和结束。具体流程如下:
(1)构建BNF文档:控制模块搜索本地电话薄数据库,导出用户数据信息,按照巴科斯范式语法,生成基于本地数据库的语法文档;
(2)初始化离线引擎:初始化讯飞离线语音库,根据本地生成的语法文档,构建语法网络,输入语音识别器中;
(3)初始化声音驱动:根据离线引擎的要求,初始化ALSA库;
(4)启动数据采集:如果有用户有语音识别请求,语音控制模块启动实时语音采集程序;
(5)静音切除:在语音数据的前端,可能存在部分静音数据,ALSA库开启静音检测功能,将静音数据切除后传送至语音识别引擎;
(6)语音识别状态检测:语音控制模块定时检测引擎系统的语音识别状态,当离线引擎有结果输出时,提取语音识别结果;
(7)结束语音采集:语音控制模块通知ALSA,终止实时语音数据的采集;
(8)语义解析:语音控制模块根据语音识别的结果,完成语义解析,根据<dialpre>和<dialsuf>的内容,确定用户需求,根据<contact>的内容,确认用户信息;
(9)语音识别结束:语音控制模块将语义解析的结果上传至用户模块,同时结束本次语音识别。
2.3 测试验证
语音识别准确率的高低是影响方案可行性的关键要素,根据项目需求,分别在中等、低等噪音的办公室环境中,对语音拨号软件功能进行科学的测试验证。测试人员共20人,主要来自四川、陕西、河南等地,以正常交流的语速进行测试。测试数据中包括90组电话薄数据库中存在的数据,10组数据库中不存在的数据[2],测试结果如表1所示。
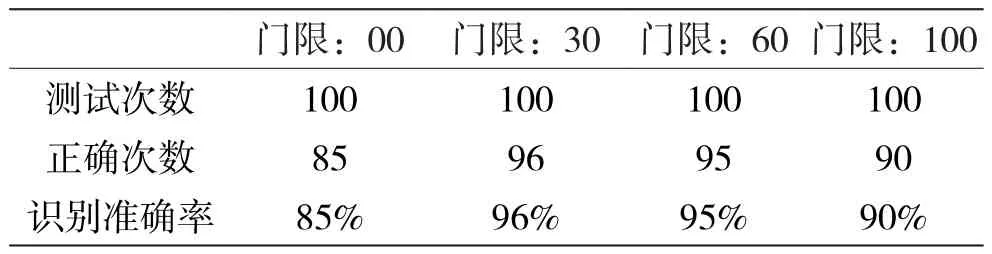
表1 语音拨号软件测试结果
3 结 语
本文提出的语音识别解决方案,可以在离线的环境中实现连续语音识别功能,不仅适应性较强,而且能够降低使用成本。根据表1的测试结果表明,本方案语音识别正确率较高,可以满足项目需求并达到实用的程度。
猜你喜欢
防爆电机(2021年4期)2021-07-28
房地产导刊(2020年12期)2021-01-14
铁道通信信号(2020年6期)2020-09-21
人民交通(2020年4期)2020-04-16
铁道通信信号(2020年11期)2020-02-07
时代英语·高一(2019年1期)2019-03-13
商周刊(2017年22期)2017-11-09
时代英语·高三(2017年1期)2017-03-01
海军航空大学学报(2015年3期)2015-11-11
中学生英语·外语教学与研究(2008年4期)2008-03-18
