
分布式数据库下基于剪枝的并行合并连接策略∗
2019-12-11 04:27高锦涛李战怀杜洪涛刘文洁
软件学报 2019年11期
高锦涛, 李战怀, 杜洪涛, 刘文洁
(西北工业大学 计算机学院,陕西 西安 710129)
排序合并连接是数据库系统的一种重要的连接实现方式[1,2],比哈希连接有着更广泛的应用.分布式环境下,数据量巨大,数据分片、分布存储,导致连接过程中存在大量网络代价,因此,高效地进行大数据量排序合并连接,挑战巨大.根据经验及实验可得出,通常情况下,连接数据都可能存在无用数据块,即不需要进行连接的数据.随着数据量增大,无用数据块比例可能越来越高,增加额外开销,比如分布式环境下的网络开销,降低连接效率.
排序合并连接过程涉及取数据、排序、连接等步骤,集中式架构下执行这些步骤涉及CPU 和IO 代价,分布式环境下由于数据分片、跨域存储,需要额外考虑网络传输代价.以OceanBase 数据库[3]为例,介绍分布式环境下集中式处理排序合并连接过程.OceanBase 中,连接数据分布在不同存储节点,连接之前,将分散的数据全部拉取到查询节点本地进行排序,排序完毕后进行合并连接,这种排序合并连接策略存在如下问题:(1)没有对连接数据中无用数据块进行剪枝;(2)在查询节点进行集中式排序;(3)在查询节点进行集中式全局合并连接.在处理大数据量连接情况下,这些问题造成大量网络代价以及本地CPU 和IO 代价.一些文献[4-7]针对问题2 和问题3 提出了并行排序策略,将连接数据进行分区,分别迁移到多个进程上进行并行排序以及局部连接,最后全局合并连接的策略.但并没有针对第1 个问题给出很好的解决策略.
排序合并连接需要连接数据有序,通过比较两边连接数据是否符合连接条件决定输出结果.在数据量大的情况下,两边连接数据大概率存在多个无效数据块,这些数据块不会产生输出结果,但会产生大量额外代价.如两个有序序列A(-1000000,...-1,0,1,2,...,1000)和B(-2000000,...,-1000001,0,1,2,...,1000)进行等值合并连接,按照传统策略,需要至少比较1000000+1000×2 次.但A的子区间[-1000000,0]和B的子区间[-2000000,-1000001]无连接结果输出,为无用数据块,因此对于此区间内的比较完全没有必要,并且分布式环境下会增加额外昂贵的网络代价.如果能够将这些无用数据提前进行预处理,将其剪枝掉,将会大大减少连接代价.图1 为在OceanBase 中进行排序合并连接实验时未剪枝(normal)和人工剪枝(prune)前后性能对比,连接对象为两个数据量为1 000 000的字符串序列.其中,重复度指匹配连接的数据占原始数据的百分比.
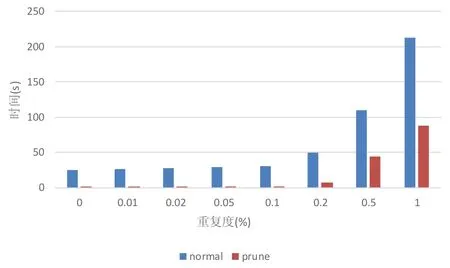
Fig.1 Performance comparation of merge-join between prune and non-prune图1 未剪枝与剪枝前后合并连接性能对比
可以看出,将无用数据剪枝后的连接性能远远优于剪枝前的连接性能.而面对复杂的数据特征,需要成熟的剪枝策略.目前,排序合并连接优化策略主要包括将取数据和排序过程由串行变为并行,或者连接阶段将搜索范围缩小等措施.这些优化手段基于参与连接的原始数据进行后续处理,并没有对原始数据进行预处理.本文提出一种分布式数据库下基于剪枝的并行排序合并连接策略(Pr_PSMJ),针对数据分布信息以及分区数据统计信息,构造一种双边邻接表(bilateral adjacency list,简称BAL),用来对连接数据中无用数据块进行剪枝,并保证最终连接结果的正确性.面对分布式环境,为了避免剪枝阶段的数据迁移,剪枝不能以整体连接数据为单位,而是以连接数据涉及的分片为单位;剪枝完成后,利用BAL 计算出各个最佳本地连接执行点,指导分区数据的迁移,使数据移动量最小;在连接阶段,通过BAL 保证各个本地连接执行节点的独立性,可以轻松并行执行整个连接过程,并且连接点内部能够利用多核环境进行局部并行排序合并连接.在分布式大数据量合并连接情况下,Pr_PSMJ策略能够有效减少网络开销,并提高连接效率.
本文的主要贡献如下.
1)给出一种分布式环境下基于剪枝的并行排序合并连接策略(Pr_PSMJ),能够对连接数据中无用数据块提前剪枝,并以最小数据迁移量完成本地并行合并连接,提高整体连接效率.
2)给出Pr_PSMJ 内容,并给出剪枝功能、本地连接中心以及切分因子构造方式.
3)给出基于Pr_PSMJ 的合并连接算法,并与经典算法在时间和空间上进行对比,给出算法正确性、效率性以及适应性分析,并结合实例给出Pr_PSMJ 算法工作过程.
4)在淘宝开源分布式数据库OceanBase 中实现Pr_PSMJ 策略,并给出实验评估,验证Pr_PSMJ 策略的高效性.
本文第1 节介绍排序合并连接相关工作.第2 节给出并行排序合并的通用框架以及相关定义.第3 节给出Pr_PSMJ 策略的内容,包括剪枝功能、本地连接中心以及切分因子构造.第4 节给出基于Pr_PSMJ 策略的合并连接算法以及其他两个算法.第5 节给出算法正确性、效率性以及适应性的分析,并给出示例.第6 节给出实验评估.第7 节给出本文的结论和未来工作.
1 相关工作
目前,针对排序合并连接的研究主要分为非阻塞式合并排序连接、多核环境下排序合并连接、分布式环境下排序合并连接.下面给出具体阐述以及相关讨论.
•非阻塞式合并排序连接
排序合并连接是传统关系型数据库,如Oracle、Sql Server、DB2 等的一项重要连接实现方式,其在真正执行连接前,需要保证连接数据有序,但排序阻塞连接执行.一些策略[8-10]假设连接数据已经准备好,假设前提是连接数据和连接执行都在本地,但面对大数据量或者网络应用,连接数据可能需要耗费较多代价得到.为了提高连接效率,一些文献提出非阻塞式合并排序连接[11-15].文献[13]提出一种PMJ(progressive merge join)策略,保证快速给出连接的前几条数据,其他数据异步排序.文献[16]提出一种HMJ(hash-merge join)算法,分为两个步骤:哈希和合并,哈希阶段对已经获得的数据利用内存哈希连接算法快速得到连接结果,如果连接数据出现阻塞,利用合并连接产生结果.其他合并连接策略包括流水线技术[17]、并行非阻塞连接[18]等.虽然这些策略能够提高发生阻塞时的连接效率,但并没有对连接原始数据进行剪枝.
•多核环境下排序合并连接
随着硬件的快速发展,多核机器越来越普遍.为了充分利用多核环境下并行的执行优点,一系列并行执行策略[4-7]被提出来.文献[4]提出使用多核(4 096 个核),利用MPI 进行合并连接的实施环境,通过合理规划网络资源,将排序和连接分离提高连接效率.文献[5]提出一种P-MPSM 算法,利用多核对连接数据并行排序,并对左侧连接数据分区,并利用直方图进行重分区,处理数据倾斜问题,利用插补搜索[19,20],缩小连接范围,但插补搜索假设搜索的对象数据分布均匀.
•分布式环境下排序合并连接
大数据时代,分布式数据库是处理和管理海量数据的利器,如Google 的spanner[21]、淘宝的OceanBase 数据库[3]等.分布式环境下,数据分片、分布存储,排序合并连接在取数据、排序、连接各个阶段涉及的数据量可能都较大,并且存在昂贵的网络传输代价,对于进行高效排序合并连接提出更大挑战.淘宝的OceanBase 数据库中,排序合并连接过程为:并行获取连接对象的分区数据,并将分区数据发送到查询节点.虽然采用流水线执行方式,但存在单点内存全量排序的缺点,导致对于大数据量表的等值连接,效率较差(图1).文献[22]针对OceanBase读写分离引起的数据合并代价,提出一种基线与增量数据分离架构下的排序归并连接优化算法,通过数据迁移达到连接数据的本地排序和连接.
•讨论
非阻塞式并行连接能够减少连接时等待时间,但分布式环境下,网络传输代价为主宰代价,因此这些策略本质上并没有太多提高排序、连接效率.虽然多核环境和分布式环境下能够利用并行策略提高排序合并连接效率,但没有对无用数据块进行预处理,造成额外代价.本文提出的Pr_PSMJ 策略能够预先对无用数据进行剪枝,减少局部连接和全局连接代价,并能够以最小数据移动量完成本地并行合并连接,提高整体的执行效率.
2 预备知识
为了针对分布式环境阐述本文提出的Pr_PSMJ 策略,总结出一种通用的分布式框架,如图2 所示.
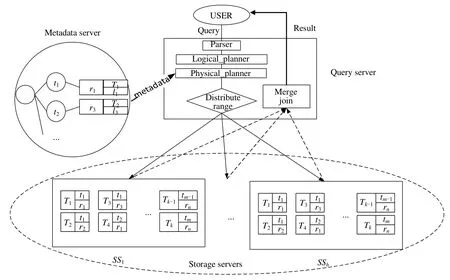
Fig.2 General distributed architecture图2 通用分布式框架
对各部分解释如下.
•Query server(QS):负责接收用户输入的SQL 语句,并进行语法解析(parser)、逻辑计划生成(logical_planner)、物理计划生成(physical_planner)、范围分发(distribute range)、合并连接(merge join)等功能.合并连接的最终执行发生在QS.
•Metadata server(MS):负责提供数据分片存储位置等元数据信息.
•Storage servers(SS):负责存储、操作(如查询)数据.存储模式为分布式,类似于BigTable[23],每一个分布
式节点存储一个表的部分或全部信息,并部署一个线程池{Wi},动态地分配所需线程,完成对应任务.以下内容针对连接语义(1)进行阐述,即R和S两个关系在连接属性x上进行等值连接.

定义1(数据模式).数据逻辑上以表为单位,物理上将表进行分片,分布存储在各个SS上.定义为公式(2).
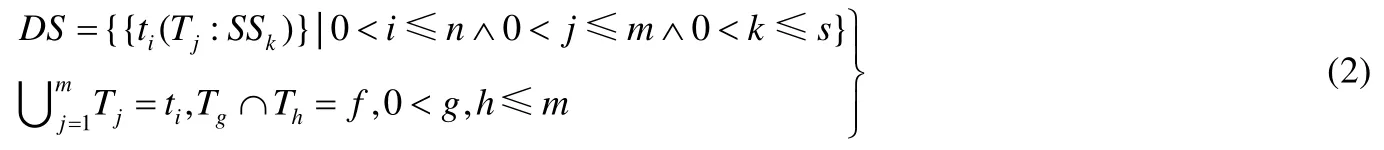
其中,DS表示数据模式;ti表示表;Tj表示表ti的一个分区,通常,Tj大小固定(Hbase 默认64MB);SSk表示Tj的存储位置;Tj所有数据的并集为ti;f表示两个分区的交集,如果按照主键进行分区,则f为空集.
定义2(排序合并连接[24]).数据库的一种连接实现方式,适合自然连接和等值连接.针对公式(1)中的两个关系R(y,x)和S(x,z),其中,x为两关系的连接属性,y和z分别为其他属性,形式化定义排序合并连接见公式(3).

其中,MJ表示排序合并连接;Me表示合并操作,即将两个有序的序列按照连接条件合并成一个有序序列;So表示对连接属性上的数据进行排序操作,其输出为有序数据,θ为连接条件.
定义3(并行排序合并连接).将定义2 中的So操作以并行方式实现,为图1 中的{Wi}分配排序任务以及执行排序任务的线程数.将Me操作改造为并行操作PMe,即首先进行局部Me,然后进行全局Me.形式化定义为公式(4).
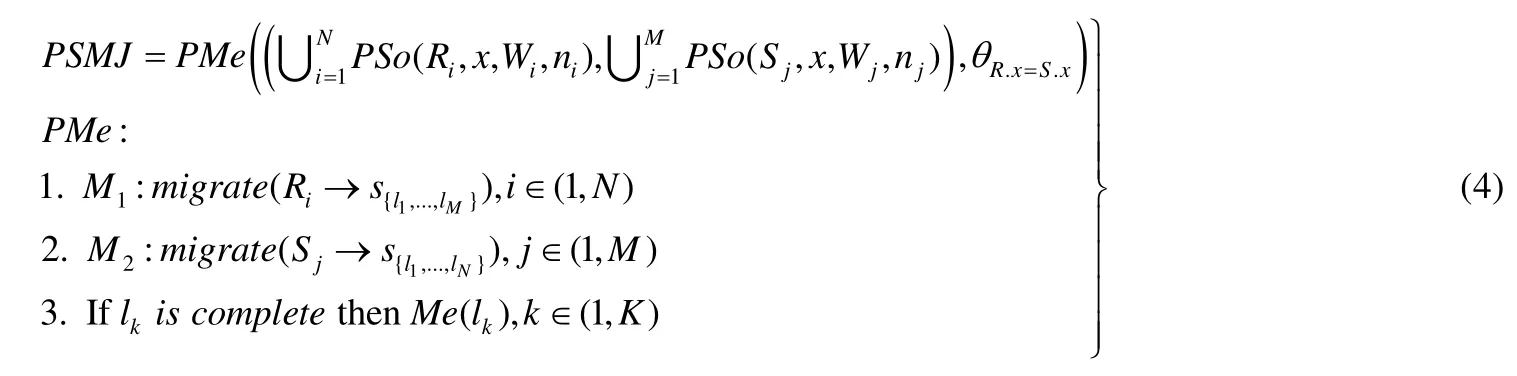
其中,PSo表示将关系R和关系S相关的分区数据中连接属性x上的排序任务分别分配ni和nj个工作线程进行并行排序,其中,Wi和Wj分别表示分布式节点上的线程池,N和M表示R和S相关分区数据所在的分布式节点的个数,Ri和Sj分别表示第i个节点和第j个节点上R和S的分区个数,且num(Ri)=ni,num(Sj)=nj.执行PMe的步骤包括:
(1)M1表示将各个Ri包含的分片迁移到合适的Si所在节点.
(2)M2表示将各个Sj包含的分片迁移到合适的Ri所在的节点.
(3)如果迁移后的节点完备(lkis complete),即可开始本地合并连接,完备的节点之间执行不阻塞.
问题定义.公式(4)中,PSo操作涉及CPU、IO 代价,PMe操作涉及CPU、IO 以及网络代价.这两部分代价与参与PSo和PMe操作的数据量直接相关,并且决定PSMJ的效率.因此,本文需要解决的问题为:减少PSo和PMe操作中涉及到的不必要数据,最小化数据移动,提升PSMJ效率.形式化定义见公式(5).

其中,prune功能将R和S中以块为单位进行无用数据块剪枝,剪枝后,最小化公式(4)中的M1和M2.
3 基于剪枝的并行排序合并连接策略
分布式数据库中,数据分片、分布存储,在进行并行排序合并连接过程中,首先对分散的数据进行局部排序[5]或者全局排序[14],如果数据量巨大,将涉及大量网络开销.为充分利用分散数据局部排序得到的有序数据范围,进行无用数据块的剪枝处理,本文提出高效的基于剪枝的并行排序合并连接策略(Pr_PSMJ),目的是解决公式(5)中给出的问题.中心思想是,高效构造双边邻接表(BAL),实现对连接数据的剪枝处理(公式(5)中的prune功能),提前去除无用数据,并通过BAL 实现本地并行合并连接过程中数据迁移量最小(min(M1)和min(M2)).下面就Pr_PSMJ 策略内容以及双边邻接表(BAL)进行详细阐述.
图3 为基于Pr_PSMJ 策略改造后的处理框架,标红的模块为新添加部分.改造点包括:(1)添加剪枝(prune)功能模块,在范围分发之前,将多余的范围剪枝掉,即去除连接执行时多余的数据块;(2)将图2 中的distribute range 改造为distribute BAL,功能从分发数据范围改为分发双边邻接表(BAL);(3)在每一个SS上构建一个本地连接中心(local_join_center,简称LJC),作用是以最小代价完成一部分连接任务,LJC 的计算详见第3.2 节.LJC 包括两个子模块:collector 模块,根据prune 模块生成的双边邻接表收集需要在此SS完成的连接任务中包括的数据块;allocator 模块,为需要连接的数据块分配合适的资源以供并行执行.

Fig.3 Modified distributed architecture based on Pr_PSMJ strategy图3 基于Pr_PSMJ 策略改造后的分布式架构
定义4.基于定义3 给出基于Pr_PSMJ 的排序合并连接定义,见公式(6).

添加剪枝(prune,简称Pr)操作提取R和S对应分区数据的有序序列范围,建立BAL,利用剪枝策略将无用数据块预先去除.并将BAL 中各个项分发给对应SS.进行本地合并后,由QS完成全局合并.
3.1 剪枝功能
如图3 所示,剪枝功能(prune)作用为预先将无用数据块去除,功能包括双边邻接表(BAL)的构造(第3.1.1节)、边界处理(第3.1.2 节)以及负载均衡(第3.1.3 节).
3.1.1 BAL 构造
双边邻接表(BAL)的作用是完成剪枝功能,并利用BAL 的结构特点,以每一个BAL 项为单位,将整个分布式排序合并连接分割成独立的可并行执行的单元,结构如图4 所示.BAL 分成3 部分:左部、中部、右部.其中,左部关联左连接关系R相关的全部数据块范围集合{r1,...,rm},中部为边界范围集合{ra1,...,ran},右部为剪枝后剩余的左连接关系R和右连接关系S对应的数据块范围.BAL 以中部各个元素作为候选本地连接中心(LJC),剪枝完成后,以中部对应的不为空的右部元素作为分发BAL 的内容.{ra1,...,ran}为边界范围集合,{r1,...,rm}为经过定义4 中PSo操作后得到的关系R中有序数据块的范围集合.{s1,...,sn}为经过PSo操作后得到的关系S中的有序数据块范围集合.{SS1,...,SSk}为图2 中的存储节点集合.{size1,...,sizep}为数据块范围集合对应的大小.BAL 左部表示关系R相关全部数据块的范围、该范围所在的位置以及对应数据量(根据直方图[12]或者样本估计[25]等策略得出的估计值),用三元组(r,l,size)表示.右部表示经过剪枝操作后剩余的集合{r}和集合{s}的部分,用四元组(s,SS,sub({r}),size)表示,其中sub({r})表示与s完成本地连接所需的{r}的子集.注意,每一个{ra}元素并不一定有左部或者右部.

Fig.4 Architecture of BAL图4 BAL 架构
BAL 构造包括{ra}构造、左部构造和右部构造这3 个部分,构造完成后的BAL 架构如图4.具体内容如下.
•构造{ra}:首先获得R对应的数据块范围.做法为:在R相关的SS节点中进行PSo操作后得到有序数据块,同时获取其范围,形成集合{r},根据{r}得出{r}的超集Sr,设置切分因子q(设定方法详见第3.3 节),将Sr切分成{ra}集合.经过以上处理,形成图4 中{ra}.
•构造左部:将已经获得的{r}映射到{ra}中,即将{r}中的每一个元素与{ra}元素取交集,如果交集不为空,则说明这个元素属于当前的ra元素.需要满足{r}中的每一个元素的全部或者部分(r跨越{ra}某个元素的边界)只属于{ra}中的一个元素.经过以上处理,形成图4 的左部,用{l_r}表示,其中每个元素为由(ri,SSj,sizek)组成的链表,每个{l_r}元素隶属于一个{ra}元素.
•构造右部:使用和获取{r}同样的方法获取右连接关系对应的数据块范围{s},利用{s}中的每一个元素s探测当前形成的BAL,形成两阶段探测:
➢首次探测{ra},s与{ra}的对应关系为1 对多或者1 对1:如果为前者,则将s进行拆分,拆分后的子集映射到对应{ra}元素,这个过程中会将s的一部分无用数据舍弃;如果为后者,则直接映射到当前ra元素.
➢再次探测s或者其子集在当前ra元素中对应的{l_r}中是否有对应的{r}与之相交:如果没有,则将这个s的全部或部分舍弃;如果有,则形成(s,SS,sub({r}),size)四元组;如果有多个,则形成链表.整个右部用{r_s}表示.
构造完成的BAL 已经对无用的{r}和{s}数据块进行了剪枝,并且形成了以{r_s}中元素为单位的本地连接执行单元.
3.1.2 边界处理
由于{ra}是对{r}的超集进行切割形成的,因此在构造左部和右部时,可能存在{r}和{s}的元素跨越{ra}中多个元素,因此需要处理这种跨边界问题.处理策略为:以{ra}为基准,如果{r}或者{s}中的元素r或者s跨越了某个或多个{ra},则用{ra}的被跨越元素的边界值对r或者s进行切分,切分后,各个部分归属于其就近的较小{ra}.
3.1.3 负载均衡
负载均衡对于分布式数据库连接操作的并行执行效率至关重要,如文献[16,26,27]提出的并行环境下的负载均衡策略,能够有效处理某些情况,但并不适应分布式环境下的排序合并连接操作.Pr_PSMJ 策略通过BAL 达到负载均衡目的.BAL 右部{r_s}中每一个元素对应一个连接执行点,多个元素之间并行执行,需要保证每个执行点的负载均衡.策略为选择合适的切分因子(详见第3.3 节),并考虑BAL 的每一个右部涉及到的数据量分布尽量均匀,达到各个执行节点的负载均衡以及降低本地连接时数据移动的网络代价.
3.2 本地连接中心
对连接关系完成剪枝操作后,需要根据形成的BAL 的右部,执行图3 中的BAL 分发功能(distribute BAL),将右部各个元素发送到对应的存储节点(SS)上执行本地连接.为了保证连接的完备性,需要消耗网络代价将一部分数据块迁移到执行本地连接的SS节点上,这个节点称为LJC.被选择为LJC 的SS节点通过collector 模块,根据接收到的BAL 右部元素对应的各个四元组,将不属于这个LJC 的四元组对应的R和S的数据块收集到本地,然后利用allocator 模块为收集完备的项分配对应的资源完成本地连接.为最小化迁移代价,提出公式(7)来计算LJC.

公式(7)目的为选择本地参与连接的R和S数据块大小之和最大,其中,x为第k个右部元素中所有四元组中涉及的执行节点的个数,subi({s})和subi({r})分别表示第k个右部元素中关联的执行节点中关于关系R和S本地的的数据块个数.利用公式(7)依次计算出所有{ra}相关的执行节点,并由图3 中BAL 分发功能从QS分发到各个执行节点执行本地连接,发送过程和执行过程异步进行.
3.3 切分因子构造
切分因子作用为构造BAL 中的{ra}部分进而限制{r}在BAL 左部的分布({l_r})以及BAL 右部{r_s}的形成,一定程度上决定了并行执行合并连接的节点数、负载均衡以及数据迁移量.图5 阐述切分因子(q)在BAL 关联的限制链(即链中前驱元素决定后继元素)中的位置,其作用范围为{ra}和{l_r}两个节点,但间接作用于其他后继节点.下面详细阐述切分因子的构造方法.

Fig.5 Restriction chain in BAL图5 BAL 限制链
构造切分因子所需参数包括{r}:{SSr}:{r_size},{s}:{SSs}:{s_size},其中,{SSr},{SSs}分别表示{r}和{s}对应的存储位置,{r_size}和{s_size}分别表示{r}和{s}中的每一个元素对应的数据量大小.这些参数在构造q之前已经具备.图5 可以看出,q的选择最终决定了{r_s}的构造,并且在使用BAL 指导数据迁移时,根据公式(7),选择的是{r_s}中每一个元素所包含的所有{r}和{s}子集中在某一个执行节点里数据量最多的一个.由于构造{r_s}是在选择q之后进行的,因此为尽量最大化公式(7)并减少数据迁移,进行如下步骤选择q.
•提取{SSr}和{SSs}中每一个存储位置涉及的{r}和{s}子集以及对应的子集个数,形成{loc:num:range}.
•根据{r}和{s}以及{r_size}和{s_size}计算出range对应的数据量之和,形成{loc:num:sum}.
•计算avgnum=avg(num)以及avgsum=avg(sum).
•由于针对分布式环境,因此以减少网络传输代价为首要目标,得出如下q计算公式.
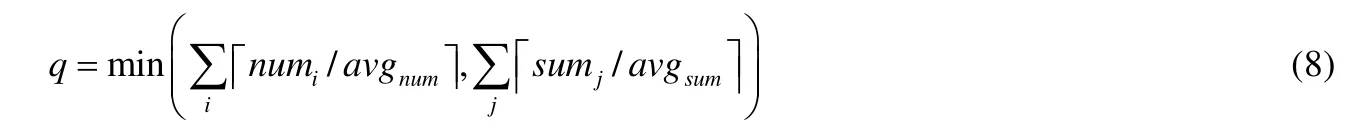
从公式(8)可以看出,如果连接数据分布不均匀,则得出的q会相对较大,使{ra}粒度相对较小,能够将负载不均衡的节点关联的负载分摊到其他节点,较好地解决数据倾斜问题.
4 算 法
传统的排序合并连接优化策略基于连接对象关联的原始连接数据进行取数据、排序、连接等操作的优化,而忽略原始连接数据本身存在的无用数据块.在分布式环境下进行大数据量排序合并连接时,这些无用数据块将造成大量额外不必要代价.本文提出的基于剪枝的并行排序合并连接策略(Pr_PSMJ)通过构造双边邻接表(BAL),能够对原始连接数据进行高效剪枝,提前去除无用数据块,并通过公式(7)选择合适的LJC,最小化数据迁移代价.为了显示Pr_PSMJ 算法的优势,阐述3 种算法进行对比,包括:uPr_uLJ(无剪枝无本地连接)算法,如OceanBase[3]中的排序合并连接算法;uPr_LJ(无剪枝有本地连接),如文献[5]提出的B-MPSM 算法以及本文提出的Pr_LJC(有剪枝基于LJC 的本地连接)算法.下面分别进行介绍.
uPr_uLJ 算法.

uPr_uLJ 算法首先获取连接关系R和S对应的元数据信息(第1 行),然后根据元数据信息并行的获取到对应的数据块(第2 行),并将获取到的数据块全部发送到查询节点(第3 行)完成全局排序(第4 行),最后在查询节点完成全局合并连接,将结果返回(第5 行、第6 行).
uPr_LJ 算法.

uPr_LJ 算法的第1 行、第2 行与uPr_uLJ 算法相同.为完成本地连接,在并行获取到数据块后,为关系R对应的每一个数据块分配一个工作线程(第3 行),个数取决于较大的数据块个数,然后将关系S中的每一个数据块依次发送到工作线程中(第4 行).对于每一个工作线程,为完成其本地连接,需要将此线程内DR需要连接的所有SR数据块迁移到本地完成本地连接(第5 行~第7 行).第8 行、第9 行与uPr_uLJ 算法的第5 行、第6 行相同.
Pr_LJC 算法.


Pr_LJC 算法的第1 行、第2 行与uPr_LJ 算法的第1 行、第2 行相同.不同的是,需要通过本地并行排序的结果获取对应数据块的范围,并将它们发送到查询节点(第3 行、第4 行).在查询节点,根据第3.1.1 节的内容生成BAL(第5 行),根据第3.2 节的内容获得BAL 右部对应的最佳本地执行点(LJC)(第6 行).将BAL 的右部分发到对应的LJC(第7 行),对于每一个LJC,根据接收到的BAL 右部内容将对应的数据块拉取到本地,完成本地连接任务(第8 行~第10 行).第11 行、第12 行与uPr_LJ 算法的第9 行、第10 行相同.
5 算法分析
5.1 算法正确性
对于非剪枝、非局部连接算法(uPr_uLJ)以及非剪枝局部连接算法(uPr_LJ),其连接策略为:将连接的两表根据连接属性将参与连接的数据全部拉取到QS 本地或者部分SS 本地,进行全局或者局部排序,然后进行全局或者局部合并连接,最后由QS 进行合并连接.两种算法涉及的数据来自原始连接数据,能够保证连接正确性.对于基于Pr_PSMJ 策略的Pr_LJC 算法,为了保证连接效率,通过剪枝去除连接数据中无用数据块,通过基于LJC 的本地并行连接提高连接效率.在这个过程中,算法通过如下的细节保证连接的正确性.
•保证对原始连接数据进行剪枝不影响最终结果的正确性.
两表原始连接数据分片范围分别为{r}和{s},通过各自范围内数据的并集能够得到原始连接数据.根据构造的BAL(构造过程见第3.1.1 节)对{r}和{s}进行剪枝操作,剪枝过程为:首先将{r}合并后得到的范围根据切分因子(见第3.3 节)进行划分,得到{ra};然后将{r}中的元素映射到对应{ra}内,用{s}中的某个元素s首先对{ra}进行匹配,如果匹配到,则进一步匹配其中的{r}元素,如果也匹配到,则保留s.如果这两次匹配中任何一个不成立,则舍弃s.当某一个BAL 右部不再增长时,说明此右部对应的范围内的数据已经完备,剩余的{r}和{s}为该范围内进行局部连接的数据.基于公式(9),其中N为{ra}内元素个数,可以得到在每一个{ra}元素内进行的利用{s}中的元素对{ra}元素内的{r}元素进行剪枝是互相独立的;同理,对于每一个{ra}元素内的剪枝活动,去除的{r}元素和{s}元素相对于其他{ra}元素也是独立的,并且每一个{ra}内的{r}元素是完全的且独立的,剪枝掉的数据块确实为无用数据块,因此整个剪枝活动对于排序连接的正确性没有影响.

•保证剪枝后的本地并行连接的正确性.
由于每个非空BAL 的连接是独立且完备的,并且对应的连接数据完全来自基于公式(9)已经证明正确的数据基础上进行的,并且最终由QS完成全局连接,因此能够保证在实行本地并行连接后最终连接结果的正确性.
5.2 算法效率性
针对3 种算法进行计算和存储方面的效率评估.uPr_uLJ 算法涉及的连接步骤包括取数据(fetch data,简称fd)、全局排序(global sort,简称gs)以及全局合并连接(global merge join,简称gmj),uPr_LJ 算法涉及的连接步骤包括取数据(fd)、局部并行排序(local parallel sort,简称lps)、本地连接(local merge join,简称lmj)、全局结果合并(global result merge,简称grm),Pr_LJC 算法涉及的连接步骤包括取数据(fd)、局部并行排序(lps)、剪枝(prune,简称pr)、基于LJC 的本地连接(local merge join based on LJC,简称lmjLJC)、全局结果合并(grm).3 种算法涉及的执行场地包括QS和SS,涉及的资源包括QS本地CPU(QS_CPU)、内存(QS_Mem)、IO(QS_IO)、SS本地CPU(SS_CPU)、内存(SS_Mem)、IO(SS_IO)以及QS和SS之间的一次网络通信代价(C_Net).下面分别给出3 种算法对应的代价计算公式.
•uPr_uLJ 算法相关的计算代价和存储代价的计算见公式(10).
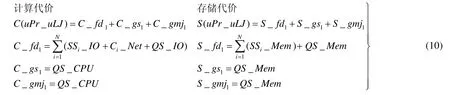
•uPr_LJ 算法相关的计算代价和存储代价的计算见公式(11).

•Pr_LJC 算法相关的计算代价和存储代价的计算见公式(12).

分析.从公式(10)可以看出,uPr_uLJ 算法没有经过局部排序以及局部连接提升连接效率以及降低QS的压力,在数据量较大情况下,QS会成为系统瓶颈.uPr_LJ 算法采用了局部排序以及本地连接的策略,从公式(11)可以看出,取数据以及排序所耗费的计算代价和存储代价较uPr_uLJ 算法都有所减少,并且由于采用并行本地连接策略,因此在提升连接效率的同时,减少了在QS合并的数据量,降低了QS的计算和存储的压力.但uPr_LJ 算法在执行本地连接之前并没有将无用的数据块去除,导致增加额外的计算和存储代价.本文提出的Pr_LJC 算法增加了高效剪枝功能,提前将无用数据块去除,并且采用基于LJC 的本地连接策略,最小化数据迁移带来的网络代价,使性能整体上优于uPr_uLJ 算法和uPr_LJ 算法.3 种算法的比较过程见公式(13)、公式(14).
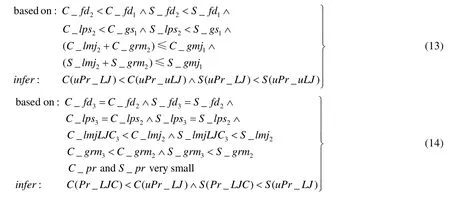
5.3 算法适应性
对于任何排序合并算法,都需要经历取数据、排序、合并的过程.在大数据时代,连接数据通常数据量巨大,并且分片存储(无论是集中式还是分布式).无论采取什么连接策略,处理对象基本都是排序后的原始连接数据,因此通过Pr_PSMJ 对排序后的数据进行剪枝,势必会提高后续的合并效率,进而提高整体的连接效率,这在分布式数据库中尤为明显.由于剪枝策略主要涉及很少数据量的网络传输代价,与其提升的性能相比可忽略不计,即使通过BAL 没有剪枝掉任何数据块或者剪枝掉少量数据块,但BAL 最小化数据迁移量能够节省网络开销,提升整体连接效率,因此适应各种不同的排序合并连接策略.
5.4 基于Pr_PSMJ连接过程举例
为了便于理解基于Pr_PSMJ 策略的排序合并连接过程,以如下过程进行讲解.为叙述方便,将定义1 中的数据模式简化,规定ti包括两表{R,S},两表在各自属性x上进行等值排序合并连接.经过并行本地排序后,得到R和S在x上的{r}和{s},见表1.

Table 1 Instance of {r} and {s}表1 {r}和{s}实例
从{r}和{s}对应的存储位置{SSr}和{SSs}中提取{loc:num},对应的存储位置见表2.其中,k 和w 分别是千行和万行的单位,并且假设每一行大小基本相等.

Table 2 Storage location of {r} and {s}表2 {r}和{s}存储位置
•切分因子q的构造:根据表2 可得出,LJC 分别为(SS1:8:17k),(SS2:6:21k),(SS3:8:44k);依据第3.3 节可得出q=4.
•{ra}构造:根据第3.1.1 节以及切分因子q构造{ra},首先,针对{r}构造其超集Sr=[1,8000];然后,根据切分因子对Sr进行切分,得到{ra}={[1,2000),[2000,4000),[4000,6000),[6000,8000]}.
•BAL 左部构造:根据第3.1.1 节的左部构造策略,利用{r}对{ra}元素进行探测,得到BAL 左部,如图6所示.

Fig.6 Instance of left part of BAL图6 BAL 左部实例
•BAL 右部构造:根据第3.1.1 节BAL 构造策略进行右部的构造.首先,利用获得的右连接关系R的数据范围集合{s},探测{ra},将{s}中的元素映射到{ra}集合中;然后,以{ra}中的元素为单位,在将对应的{s}元素与ra元素对应的{r}元素进行比较,得到BAL 右部,如图7 所示.

Fig.7 Instance of right part of BAL图7 BAL 右部实例
经过BAL 的过滤,可将{r3,r4,r7,r10,r11,r12}和{s1,s5,s7,s9,s10}无用数据过滤掉,节省大量网络代价以及SS和QS的本地IO、CPU 代价和内存空间.再根据BAL 进行局部合并阶段,依据公式(7)确定每一个非空右部对应的{ra}中的每一行所在的执行节点位置,可得{ra1,l1},{ra2,l2},{ra3,l1},根据计算的位置进行数据迁移,保证本地连接的完备性.每个节点在迁移完毕后,由本地节点的线程池分配等于{ra}元素对应的右部中链表个数的线程数以供局部并行连接,线程数分别为(2,1,1).局部连接完成后,将本地合并结果发送到QS,完成全局合并,将合并结果返回给客户端.
6 实验评估
6.1 实验环境
本文实验使用8 个计算节点,每个节点配置为:主频为1400MHz 的AMD Opteron(TM)处理器和16GB 内存,物理CPU 个数为2,物理核数8,逻辑核数16;操作系统为Red Hat 6.2.所有算法均由C++实现,算法实现平台为淘宝的开源分布式数据库OceanBase 0.4 版本[28],系统架构如图8 所示,其中,RootServer 提供元数据服务,主要包括数据分布信息;UpdateServer 提供OceanBase 唯一的更新入口;MergeServer 提供对SQL 语句的解析、逻辑计划生成、物理计划生成、计划分发、结果合并等功能;ChunkServer 提供数据的存储和查询等服务.OceanBase具体描述请参见文献[3].图2 与OceanBase 模块的对应关系为:MetadataServer 对应RootServer,QueryServer 对应MergeServer,StorageServer 对应ChunkServer.

Fig.8 Architecture of OceanBase图8 OceanBase 架构
6.2 实验数据
本文实验数据由tpch_2_17_0 工具生成,SF 设置为30,选取PART 表作为实验数据来源,PART 表数据量为600 万行,大小为699 兆.在OceanBase 数据库中建立两张表作为连接测试表,分别为l_part和r_part,并通过设置TABLET_MAX_SIZE参数指定表对应分块大小为20MB.这两张表的结构和tpch 生成的PART 表结构一致.利用OceanBase 的import 工具将生成的数据分别导入到l_part和r_part中.
6.3 评估与结果分析
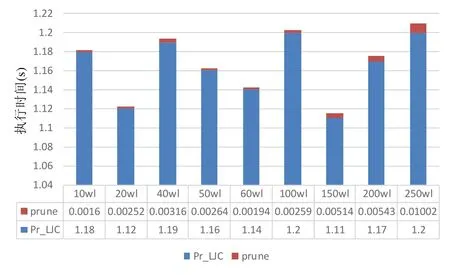
本文设计了4 组实验,分别为:(1)测试在重复率不变的情况下,随着连接数据量的增加,3 种算法的执行效率;(2)测试在连接数据量不变的情况下,随着重复率的增加,3 种算法的执行效率;(3)测试在测试1 中,Pr_LJC算法中剪枝功能的执行效率;(4)测试在测试2 中,Pr_LJC 算法中剪枝功能的执行效率.
测试1.
这里规定重复率为表数据量的0.1%,即6 000 行,采用Query 1 进行测试,其中,谓词A,B,C,D用来控制两表的连接数据量以及保证重复度为0.1%,这里使用如下策略实现(其中,wl 表示单位:万行):
l_part:(A,B)→{(0,10.6wl),(0,20.6wl),(0,50.6wl),…}
r_part:(C,D)→{(10wl,20.6wl),(20wl,40.6wl),(50wl,100.6wl),...}.
上述策略能够保证在重复度为0.1%的前提下,不断增加连接数据量.测试结果如图9 所示.
Query 1:selectcount(*)froml_partinner joinr_partonl_part.P_PARTKEY=r_part.P_PARTKEY
wherel_part.P_PARTKEY>Aandl_part.P_PARTKEY r_part.P_PARTKEY>Candr_part.P_PARTKEY 分析.从图9 中可以看出,在重复度不变的情况下,随着连接数据量的增加,Pr_LJC 算法的执行时间基本不变;而uPr_uLJ 算法和uPr_LJ 算法随数据量增加,执行时间显著增长.原因是:由于Pr_LJC 算法的剪枝(prune)策略,将重复度以外的无用数据块提前去除,其他两种算法完全基于原始数据进行操作. Fig.9 Result of execution efficient comparison of different algorithms under situation of fixing overlap degree and increasing data size图9 固定重复度,随着数据量的增加,不同算法执行效率的对比结果 测试2. 这里规定测试的数据量为250.6wl,限定重复度以步长0.6wl 增长.测试语句采用Query 1,采用与测试1 类似策略,保证在连接数据量不变的情况下,逐渐增加重复度: l_part:(A,B)→{(0,250.6wl),(0.6,251.2wl),(1.2,251.8wl),…} r_part:(C,D)→(250wl,500.6wl). 上述策略能够保证在数据量为250.6wl 的前提下,逐渐增加重复度.测试结果如图10 所示. Fig.10 Result of execution efficient comparison of different algorithms under situation of fixing data size and increasing overlap degree图10 数据量固定,随着重复度的增加,不同算法执行效率的对比结果 分析.从图10 可以看出,在连接数据量固定的情况下,随着重复度的增加,Pr_LJC 算法的执行效率缓慢增加,原因是需要执行连接操作的数据量逐渐增加;uPr_uLJ 算法和uPr_LJ 算法始终保持较高的执行时间,原因是这两种算法的执行时间不仅与重复度相关,而且依赖于原始连接数据量. 测试3 和测试4. 通过在程序中添加时间函数,对Pr_LJC 中的剪枝功能进行执行效率测试.测试结果如图11 和图12 所示. Fig.11 Fixing overlap degree and testing execution efficient of prune in Pr_LJC as the increasing of data size图11 固定重复度,测试Pr_LJC 算法中,prune 功能随数据量增加的执行效率 Fig.12 Fixing data size and testing execution efficient of prune in Pr_LJC as the increasing of overlap degree图12 固定数据量,测试Pr_LJC 算法中,prune 功能随重复度增加的执行效率 分析.从图11 和图12 可以看出,在测试1 和测试2 两种测试环境下,Pr_LJC 中的剪枝(prune)功能的执行效率对于Pr_LJC 策略本身来说可以忽略.原因是剪枝功能的实现(详见第3.1.1 节)完全在内存中进行,并且数据只涉及多个表示区间的数据,因此数据量可以忽略. 排序合并连接是数据库系统的一种重要连接方式,大数据时代,由于连接数据量的巨大,特别是分布式环境下,需要考虑网络代价,造成提升连接效率挑战巨大.本文提出了Pr_PSMJ 策略,在进行实际连接之前,通过构造双边邻接表(BAL)对连接数据进行剪枝,提前去除无用数据块,降低本地代价和网络代价;并通过BAL 指导本地并行合并连接,最小化数据移动量,有效提升整体连接效率.Pr_PSMJ 策略适应目前大多数合并连接策略.未来需要对切分因子(q)进行更细致的求解,并且对合并区间进行细化,做到更彻底的剪枝以及更健壮的负载均衡;同时,对其他连接策略,如非阻塞式合并排序连接方法等方法进行进一步的研究与优化.


7 结论和展望
猜你喜欢
保健医苑(2022年5期)2022-06-10北京大学学报(自然科学版)(2021年3期)2021-07-16成都信息工程大学学报(2021年6期)2021-02-12电脑爱好者(2020年19期)2020-10-20计算机应用(2020年5期)2020-06-07海峡姐妹(2017年12期)2018-01-31语文世界(初中版)(2017年5期)2017-06-22作文与考试·初中版(2017年12期)2017-04-19天津诗人(2017年2期)2017-03-16科技与创新(2014年11期)2014-08-21
