
智能电网非结构化数据安全技术研究
2019-12-06 06:22王林何映军向华伟吕垚
中国科技纵横 2019年19期
王林 何映军 向华伟 吕垚

摘 要:随着社会的发展和用户的需求多样化,电网的开放性和交互性和网导致电网的各种应用系统越来越多,从而使智能电网数据量增长速度很快,尤其是非结构化数据,存在数据量大、存储空间占用率高、數据安全风险高等特点,进而对非结构化数据安全提出了更高的要求。本文重点从数据加密和解密两方面对非结构化数据处理,实现电网非结构化数据安全的目标。
关键词:非结构化数据;数据安全;k近邻算法;聚类算法
中图分类号:TM76 文献标识码:A 文章编号:1671-2064(2019)19-0143-02
0 引言
随着社会的快速发展,加速了大数据发展的步伐,据IDC和EMC估计,到了2020年,数据会突破40000EB。且以两年翻倍的速度快速增长,而企业约80%是非结构化数据。尤其在电力行业,非结构化数据增加速度越来越快。各种新技术的引入以及电网的开放性和交互性和网络通讯更加复杂,增加了电网内部的安全风险。非结构化数据安全在电力企业中变得非常重要,虽然在结构化数据加密方面取得了进步,但是非结构化数据安全满足不了用户和电力部门的实际需求,因此在非结构化数据加密的的基础上实现检索效率的优化已经成为一个研究课题,本文利用中科院ICTCLA分词技术和开源hadoop体系结构中的HDFS文件系统和HBASE等开源技术对非结构化数据进行分词和存储,引入以下算法提高非结构化数据的安全性和检索效率。本文采用多层聚类的多分类SVM方法对数据进行聚类[1],利用线性同态加密算法对非结构化数据进行加密,利用HBASE对非结构化数据进行列式存储,运用k近邻查询算法实现查询效率的提高。
1 相关算法
本文改进了同态加密算法,文献5提出了基于ECC的同态加密算法,本文为了提高检索效率,提出线性同态加密方法。引入多层聚类svm算法先对数据聚类,利用改进的同态加密算法对数据的进行加密,运用k近邻算法实现查询效率的提高[2,3]。
1.1 线性相关加密算法
同态加密是一类具有特殊自然属性的加密方法,此概念是Rivest等人在20世纪70年代首先提出的,与一般加密算法相比,同态加密除了能实现基本的加密操作之外,还能实现密文间的多种计算功能,即先计算后解密可等价于先解密后计算。同态加密算法的缺点只能进行加运算和乘运算,容易被窃取,造成数据泄露。直到2009年,IBM的研究人员Gentry首次设计出一个真正的全同态加密体制,即可以在不解密的条件下对加密数据进行任何可以在明文上进行的运算,使得对加密信息仍能进行深入和无限的分析,而不会影响其保密性。但是由于全同态加密算法非常耗时,只适应理论研究,不适应大数据领域。鉴于同态加密算法的和全同态加密算法的不足之处,提出了线性加密算法:
步骤1:甲用户在直角坐标系任选一点A(x,y),确定一个私钥k,并生成对应公钥y=kx+b,并将A发送到乙。
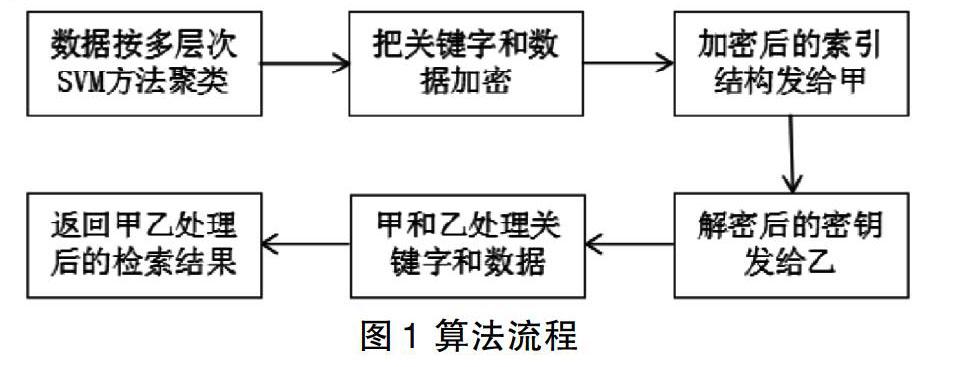
步骤2:乙收到A(x,y),产生随机数z(z 步骤3:乙收到密文传给甲,甲收到密文C后,用k解密C。 1.2 k近邻算法 K近邻(k-Nearest Neighbor,KNN)分类算法,是一个机器学习算法。该方法的思路是:如果一个样本在特征空间中的k个很类似的样本中的绝大多数样本属于某一个类别,那么该样本也属于这个类别。k的选取,距离和分类决策规则是该算法的三个基本要素:k的选取会影响算法的结果,如果k值选取小,发生过拟合的概率比较大;如果k值设定大,优点是缩小学习的误差,缺陷是学习的误差会扩大,使预测不准确。本文中k值一般选取比较小的数值,通常采用验证的方法来查找最佳的k值。如果训练实例数目趋向于无穷和k等于1时,该误差率不会超过贝叶斯误差率的2倍,如果k趋向于无穷大,则误差率趋向于贝叶斯误差率。该算法中的分类决策规则:即由输入实例的k个最临近的训练实例中的多数类。决定输入实例的类别距离度量,设定Lp距离,当p=2时,即为欧氏距离,在度量以前,本文将每个属性的值规范化,防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大。 2 加密技术实现 加密和检索技术实现从平台搭建、检索算法实现和安全性能分析分析三个步骤实现,首先描述了平台环境,其次是检索算法的实现流程,最后从安全性能和检索效率分析验证该技术的可行性[4,5]。 2.1 平台环境 本文的加密和检索系统采用hadoop搭建分布集群,作为本文的云存储平台,存储密文文档,密文索引采用倒排的索引方式,由于apache hadoop是基于java的平台,基于平台更好的兼容性,本文实验环境的分词算法使用中科院ICTCLA分词算是,使用java语言来实现密文全文检索。并对hadoop集群进行了相应的配置。本文实验环境是两台部署hadoop的Linux服务器。本文为了描述方便,其中非结构化加密数据在甲服务器上,另外一台相互协作的服务器称作乙。 2.2 算法实现 非结构化数据按照多层次聚类SVM算法流程进行聚类(聚类的目的为密文检索做准备,目的是方便找出最短距离),然后把聚类后的数据进行加密,其中加密的数据包括在聚类过程中产生的新数据和原数据以及用户提交的查询数据。数据加密的索引项在甲服务器上,数据解密的密钥在乙服务器上,甲与乙配合处理检索内容查询和数据,最终返回查询结果(具体流程参见图1所示)。该算法将所有数据分成m份,设k值设为m,这样聚类后的数据就会产生m份,对于每一份数据,再依次分裂成m份,直到叶子节点不再满足分裂要求则停止,对数据数量的最大值和最小值做限制和规定。当节点中数据数量大于最大值,则节点可以继续分裂。若分裂后数据数量小于预定的值,则将该节点与其同时分裂产生的另外节点进行合并。若节点内的数据数量小于最大预定值,并大于最小预定值,则该节点为叶子末端节点。采用以上规则进行剪枝,剪枝的过程中去掉不满足结果的数据,提高检索效率。 在整个查询过程中用户只进行一次操作,将数据聚类、加密的数据以及将加密用的公钥发送甲。甲服务器上存储的是非结构化加密数据,可以得知甲服务器上的数据无法被解析,即使知道查询数据相对最短距离时也无法获得密钥,达到安全保护的目的。乙服务器作用将数据解密,解密后的数据是经过甲处理过的数据,这些数据在解密后在其原有数据的基础上都加入了随机值,这样乙即使拥有随机值,但也无法还原原始数据值,从而使原数据得到保护。甲只需要把处理方式发送给用户(什么形式的数据),随机生成的数据以及原始真实数据是如何加入随机值的等。用户在收到这些信息以后,就可以确定哪些数据是符合要求,以及下一步如何还原出真实数据,乙在最后解密距离是甲加入扰动值以后的距离,这样可以减少乙接触到关于数据间距离的信息。 2.3 安全性能分析 通过对基于线性的同态加密算法进行实验分析。通过对比RSA/DSA密钥试验效果,在保证安全性的同时,提高了同态加密方法的计算效率如表1所示。 3 结语 本文基于电网环境下提出智能电网非结构化数据安全技术方案。首先,先按照多层聚类SVM的方法对要数据进行聚类,接着对关键字和非结构化数据进行加密,加密算法使用改进的线性加密算法,保证了数据的安全性,利用k近邻算算法实现检索效率的提高。本文的研究只是对密文检索做出了初步尝试,仍有许多问题有待改进。 参考文献 [1] 张春艳,倪世宏,张鹏,查翔.基于多层聚类的多分类SVM快速学习方法[J].计算机工程与设计,2017(2):522-527. [2] 马力.实基于云计算的智能电网数据存储安全研究[D].华北电力大学,2016. [3] 辛立杰.加密数据的k近邻查询算法研究[D].哈尔滨工程大学,2016. [4] 张克君,张国亮,姜琛,杨云松.云环境下基于可搜索加密技术的密文全文检索研究[J].计算机应用与软件,2017(4):35-41. [5] 王全福,宋文爱,杨顺民.云环境中数据安全的同态加密方法[J].计算机工程与设计,2017(1):42-46.
猜你喜欢
电子制作(2019年14期)2019-08-20
当代贵州(2018年21期)2018-08-29
电子制作(2017年20期)2017-04-26
现代电子技术(2016年23期)2017-01-12
通信学报(2016年11期)2016-08-16
信息安全研究(2015年3期)2015-02-28
信息安全研究(2015年3期)2015-02-28
