
机器学习AdaBoost.M2算法在砂砾岩流体识别中的应用
2019-12-06 03:35:40陈钢花梁莎莎祗淑华诸葛月英刘有基
石油地球物理勘探 2019年6期
陈钢花 梁莎莎*② 王 军 祗淑华 诸葛月英 刘有基
(①中国石油大学(华东)地球科学与技术学院,山东青岛 266580; ②嘉兴市佳安燃气技术服务有限公司,浙江嘉兴 314000; ③中国石化胜利油田分公司勘探开发研究院,山东东营257015;④中国石油集团测井有限公司华北分公司,河北任丘 062550)
0 引言
利用常规测井曲线难以准确识别复杂砂砾岩储层[1]中的流体类型,并且效率较低,主要是因为常规测井资料受岩性影响大,岩石骨架对测井响应特征的影响大于流体。另外,地层水矿化度低、岩石矿物成分多样等因素也会造成油、水层差异不明显,利用常规测井曲线判断流体时误差较大[2]。核磁共振测井技术的应用提高了复杂储层的识别精度,但是限于成本尚不能广泛应用于生产[3]。常规测井技术成本低、应用数据量大,利用机器学习研究常规测井资料在流体识别中的应用具有重要意义。
机器学习是利用计算机、概率论、统计学等通过数据输入,让计算机学会新知识,从而实现人工智能。机器学习的过程就是通过训练数据寻找目标函数,常用算法主要有决策树[4]、随机森林算法[5]、逻辑回归、支持向量机[6]、神经网络[7]、聚类分析[8]等。近年来,机器学习逐渐成为储层评价研究的热点[9],其以常规测井数据为基础,能大幅度提高流体识别精度。因此,机器学习技术的研究对于油气开发具有重要意义[10]。刘得芳等[11]应用决策树方法提高了利用单一信息判别的准确性。张银德等[12]结合测井资料和试采资料,利用支持向量机方法准确识别了油、气、水层。王少龙等[13]实现了BP神经网络在储层流体中的信息自动化识别。陈钢花等[14]构建声—电测井联合流体识别因子应用于川东碳酸盐岩气藏研究中,解释结果与试采结果吻合较好。但是,诸多算法中神经网络算法较为复杂,如果学习样本数量较少,容易出现过拟合问题,导致准确率下降。同时,神经网络“黑盒”过程导致无法观察中间结果,学习时间长,容易陷入局部极小值。在分类较多时,决策树法错误率较高。如果所用测井曲线数量以及标准样本数量不大时,应用聚类算法难以获得较为准确的结果。
针对以上问题,本文将AdaBoost(Adaptive Boosting,自适应增强)算法应用于砂砾岩储层流体识别中,以提高流体识别精度。
1 方法原理
Boosting算法也称为提升法或者增强学习,是一类常用的机器学习算法[15]。它是将弱学习器(Weak Learners)集成提升为一个预测(分类)精度高的强学习器(Strong Learner)。AdaBoost算法是Boosting算法族中最有影响的一种迭代算法[16],其预测精准、算法简单,在诸多领域都有着成功应用,尤其在处理分类问题和模式识别领域更为突出,例如人脸识别、语音识别、文本识别、遥感分类等[17]。AdaBoost算法迭代是通过改变训练集中样本数据各自的权重实现的,实现过程如图1所示:
(1)对于二分类问题,在初始化时对训练集中的每一个样本数据赋予同样的权重,并训练出一个弱学习器1(图1a左);
(2)根据弱学习器1对样本数据的训练误差率更新样本数据的训练权重,使之前弱学习器1分类错误的训练样本点的权重增加,并使错误数据点被下一个弱学习器选中的概率增加(图1a右);
(3)基于调整权重后的训练样本训练弱学习器2(图1b左);
(4)重复上述(2)和(3)的步骤直至弱学习器数目达到事先指定的数目(图1b右、图1c左);
(5)将各个训练得到的弱学习器组合得到最终的强分类器(图1c右)。
最初的AdaBoost算法只适用于二分类问题,而在实际中常常会遇到多分类问题。关于二分类问题,要求弱学习器的分类正确率比随机猜测略好,即正确率大于1/2。关于类别数目为K的多分类问题,弱学习器的分类正确率比随机猜测正确率1/K略大这一条件过弱,很难集成出一个精度高的强学习器。而弱学习器的分类正确率大于1/2这一条件又过强,可能导致在实际应用中难以找到足够多个正确率大于1/2的弱学习器[18]。
AdaBoost.M2算法作为AdaBoost算法的推广,适用于解决多分类问题。对于K类多分类问题,AdaBoost.M2算法将其拆解为K-1个二分类问题加以解决。
AdaBoost.M2算法反复调用给定的弱学习器算法,主要是在训练集中维护一套权重分布。在第t轮迭代时,样本(xi,yi)(i为样本编号,xi为样本数据,yi为该样本的标签)的分布权值记为Dt(i)。初始所有样本权重相等,但进行迭代时,每一轮错误分类的样本权重都将会增加。弱学习器的任务就是根据分布Dt(i)找到合适的分类器。对于给定样本数据xi,有正确分类yi和非正确分类y(除yi之外的K-1类)[19]。调用弱学习算法自动得到分类器ht,并假设ht从[0,1]取值。对于样本(xi,yi),ht会进行K-1次判别,每一次判别都有三种情况: 当ht(xi,yi)=1、ht(xi,y)=0时,则分类正确,xi的类别是yi; 当ht(xi,yi)=0、ht(xi,y)=1时,则分类错误,xi的类别是y; 当ht(xi,yi)=ht(xi,y)时,则xi的类别随机从yi和y中选取一个。
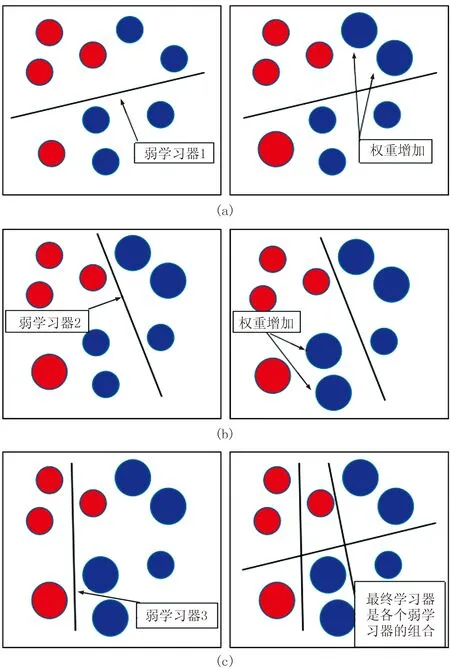
图1 AdaBoost算法原理示意图 左为弱学习器训练过程,右为训练结果
每一次判别错误分类为y的概率为
(1)
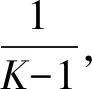
(2)
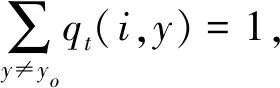
(3)
从而可以得到评估弱学习器好坏的伪损失
(4)
伪损失εt对判别正确率低的弱分类器ht进行惩罚,减少其投票权重。同时,在下一轮迭代中增加错误分类的标签权重,加大对错分样本的训练机会。
AdaBoost.M2算法的实现步骤如下。
(1)输入样本总数为N的训练集S={(x1,y1),…,(xi,yi),…,(xN,yN)},标签yi∈Y={1,2,K},其中i为样本编号,K是类别数。
(5)
(3)循环迭代t=1,…,T。
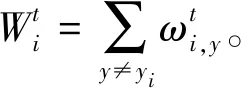
③计算ht的伪损失。
⑤计算新的权重
(6)
式中:i=1,2,…,N;y∈Y-(yi)。
(4)输出T次循环后得到的最终组合分类器
(7)
2 应用实例
A研究区砂砾岩具有近物源、快速堆积、纵向厚度变化大、相变快等特点。砾石成分复杂、孔隙结构多样、非均质性强,存在多油水系统,油水层测井响应特征差异不明显[20]。通常自然电位(SP)异常幅度可以反映储层渗透性、地层水矿化度,电阻率(RT)大小取决于孔隙结构以及孔隙所含流体。但在复杂砂砾岩储层中,地层水矿化度差异大,砂砾岩体岩石骨架对电阻率的的影响远远大于流体,利用常规测井资料难以准确评价油、水层。
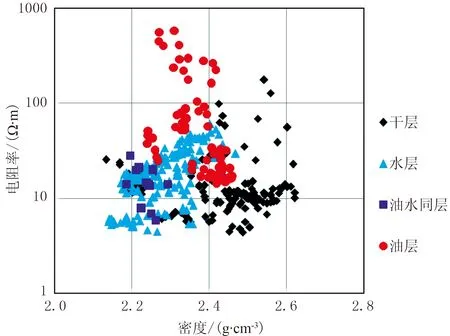
图2 研究区电阻率—密度交会图
由图2可知,利用密度与电阻率难以识别流体。因而,选取反映储层岩性、物性、流体性质的SP、GR(伽马)、RT、AC(声波时差)、CNL(补偿中子)、DEN(密度)等六种测井资料,运用机器学习算法,提取反映流体的信息,多参数结合实现砂砾岩中的流体识别。
首先在关键井中,根据核磁共振、录井油气显示、试油等结果选取多个井段的储层样本,综合考虑岩性、孔隙结构、地层水矿化度等因素,选取上述六种测井资料作为输入,建立研究区干层、水层、油水同层、油层识别模型。
建模前,对输入参数做归一化处理,消除量纲的影响。图3为不同流体类型测井数据归一化后的平行坐标系,从左到右分别为DEN、CNL、GR、AC、SP、RT测井类型。每一个样本为一条曲线,不同颜色的曲线代表不同类型的流体。从图中可以看出,不同类型流体测井响应特征不同,同一种流体各测井响应特征也不完全一致。因此,采用单一测井曲线无法对复杂储层流体类型进行划分,需要多个测井参数进行学习分类,获得学习模型,识别油水层。
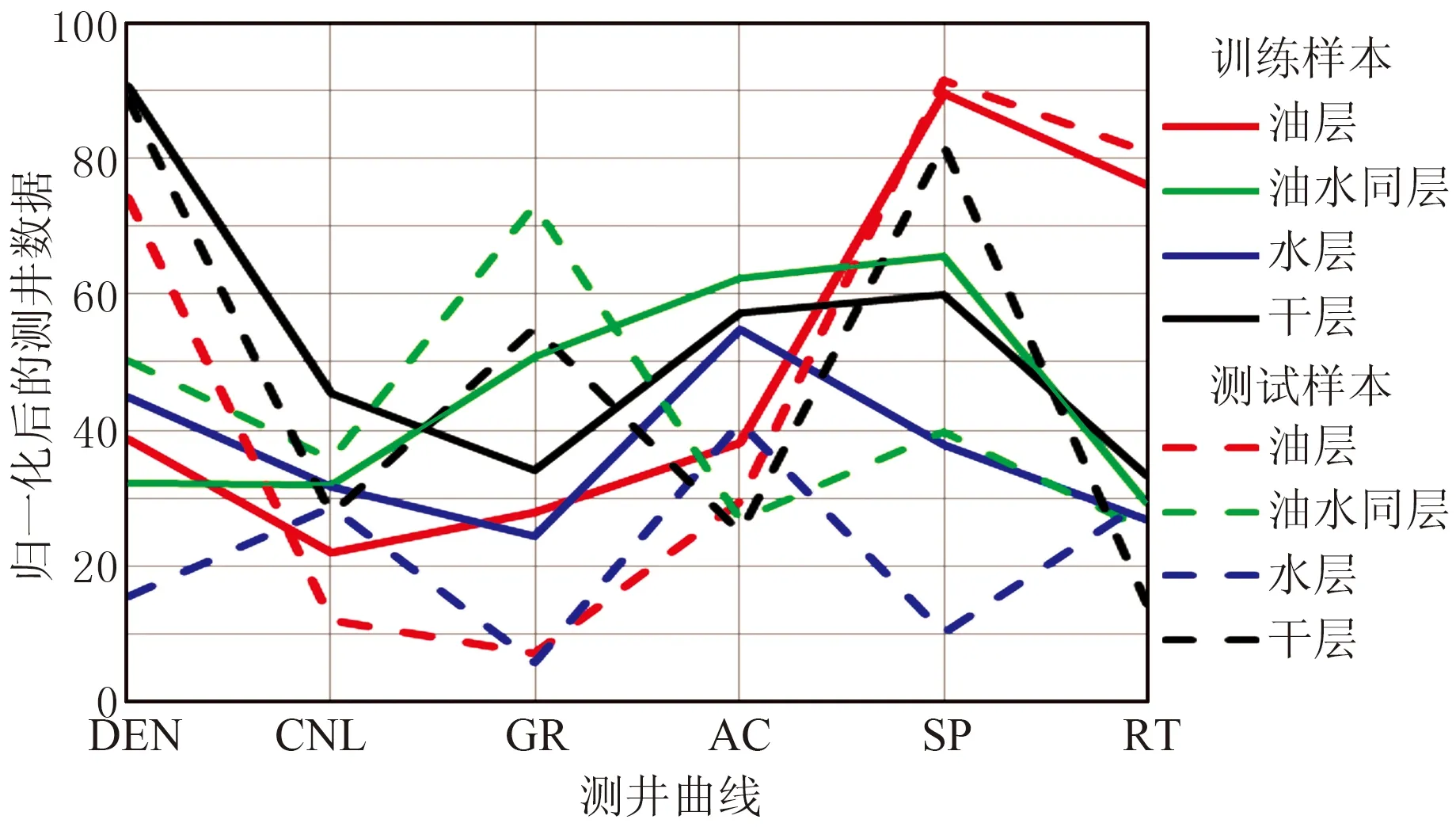
图3 归一化后的参数平行坐标系
在AdaBoost.M2算法中,要求弱学习器的输出为一个在[0,1]内的值。因此,本文采用决策树法作为弱分类器。在建模过程中,将归一化后的数据作为输入,输出为流体类型(判断为该类型响应为1,否则响应为0)。本文以研究区9口井为样本井,将试油、试采资料的层段作为样本层,共选择了反映流体性质的353个样本数据进行训练并建立砂砾岩流体识别模型。其中80%的样本(282个)作为训练数据,20%的样本(71个)作为测试数据,并将测试结果与试油、试采结果做对比分析。
表1为测试结果与试油、试采资料的对比,可以看出代表判别错误的层共有6个,解释符合率为91.5%,证明了该模型的适用性,可用于研究区流体识别。
研究区X井流体识别测井解释成果如图4所示。
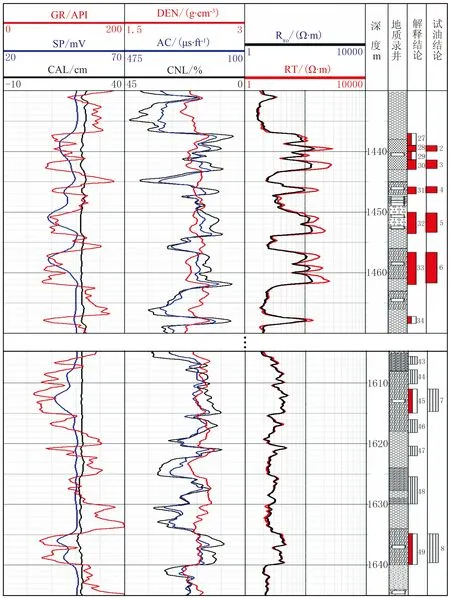
图4 X井试油段解释成果图 Rxo为冲洗带电阻率
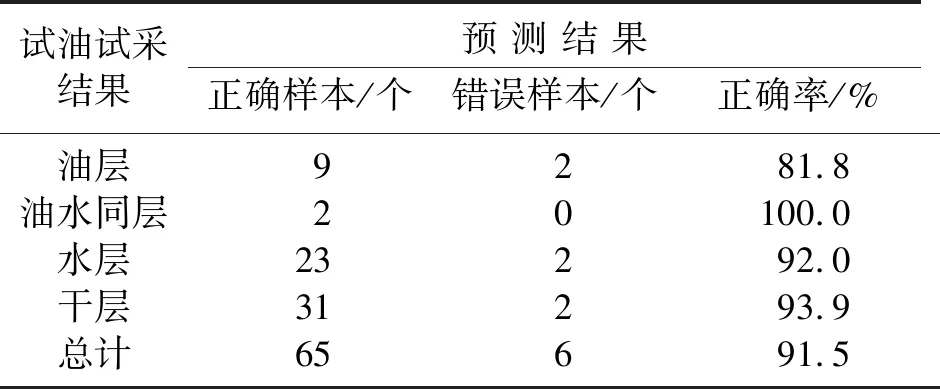
表1 测试结果与试油、试采结果对照表
1437~1462m井段储层特征明显,SP值负异常,GR值低,DEN值偏低,AC值和CNL值均较低,RT值高,具有典型的含油气特征。本方法判定该储层为油层,试油结果日产油68.9×104m3。1611~1614m井段和1635~1640m井段的45、49号层SP值负异常,GR值低,DEN值中等,AC值和CNL值均中等,RT值较高,录井含油性为荧光,解释为差油层。本方法判定为干层。试油结果为干层,2个层段无产量。上述结果表明了本文方法的准确性和适用性。
3 结束语
AdaBoost.M2算法很好地利用了弱分类器进行联级,提高了分类准确度。本文将决策树法作为弱分类器用于砂砾岩流体识别,样本回判准确率为95%,测试准确率达91.5%,精度高且效果好。随着油气藏勘探难度的增加,测井数据复杂程度与人工对比识别难度也在增加,机器学习是解决该问题的有利途径,根据不同地区的特点选取测井数据和弱分类器类型、数目,即可提高流体识别精度,指导油气藏生产与开发。
猜你喜欢
中华养生保健(2020年7期)2020-11-16 01:14:26
电子测试(2018年1期)2018-04-18 11:52:35
化工设计通讯(2017年6期)2017-03-02 18:29:14
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电子制作(2016年11期)2016-11-07 08:43:50
故事会(2016年15期)2016-08-23 13:48:41
当代化工研究(2016年6期)2016-03-20 16:21:40
