
基于Stacking集成学习的水稻表型组学实体分类研究
2019-12-06 03:04袁培森杨承林宋玉红翟肇裕徐焕良
农业机械学报 2019年11期
袁培森 杨承林 宋玉红 翟肇裕 徐焕良
(1.南京农业大学信息科学技术学院, 南京 210095; 2.马德里理工大学技术工程和电信系统高级学院, 马德里 28040)
0 引言
中国是世界第二大水稻种植国家,水稻总产量占全球30%以上[1]。培育优良的水稻品种、提高水稻产量成为我国重要的战略目标。植物表型是植物在一定环境下表现的可观察形态特征,在植物保护、育种等领域具有重要的应用价值,其研究涉及植物学、数据科学、机器学习等领域[2]。其中,水稻表型组学的研究发展迅速。水稻的表型组学文献数量占第2位,进而出现了大量的水稻表型组学相关的知识[3],为水稻表型组学研究提供大量的数据支持。目前,水稻表型组学研究正在成为水稻基因组功能分析、分子育种和农业应用中的重要技术支撑[4-7],其知识图谱的研究非常迫切。
知识图谱技术可将农业领域中的水稻表型组学相关信息表达为更贴近人类认知的形式,提供一种更好地组织、管理和理解水稻表型组学海量信息的能力[8]。近年来,国外的知识图谱研究比较注重对一些社会热点进行分析,而国内利用知识图谱处理农业信息化数据从2012年开始[9-11]。国内外学者已在农业领域知识图谱的构建方面进行了相关研究,但对于水稻表型组学知识图谱的构建和分析甚少。
知识图谱的关键技术包括知识抽取、知识表示、知识融合,以及知识推理技术。实体是知识图谱中最基本的元素,其抽取和分类的准确率、召回率等将直接影响到后续知识库的品质和知识获取效率[12]。传统的分类器学习系统使用已有的学习器(如支持向量机)对给定的训练样本集进行训练产生一个模型,用产生的模型预测新的样例后,再根据模型的预测结果对其分类性能进行分析[13]。由于现实中数据量的不断增加和数据的多元化,尤其是水稻表型组学数据的复杂性和专业性,使传统的分类算法已经无法满足现有数据的处理以及实际问题的解决需求。对单一分类器的组合学习模型在分类问题上显示出了极大的优势,使得组合分类模型在分类问题中得到更多的关注。现最流行的组合分类算法有 Boosting[14]和Bagging[15]方法。对于不稳定性的分类算法,Bagging方法分类效果较好(如决策树[16]),但对于稳定的分类器集成效果不是很理想。Boosting方法的基分类器训练集取决前一个基分类器,其分错的样例按较大的概率出现在下一个基分类器的训练集中,虽然提高了组合分类算法的泛化性能,但会过分偏向于一些很难分的样例,从而导致算法性能的降低。
针对Bagging和Boosting两种组合算法的分类器集成效果并不理想,且改善效果均十分有限的问题,本文利用基于Stacking[17]集成学习策略的两层式叠加框架,提出一种基于Stacking集成学习的分类器组合模型。通过爬虫框架获取国家水稻数据中心的水稻表型组学数据,利用TF-IDF技术和LSI模型结合的方法对水稻表型组学数据进行预处理,消除冗余特征,然后在基于Stacking 集成学习算法的多分类器组合方法上,将支持向量机(SVM)、K-近邻(K-NN)、梯度提升决策树(GBDT)和随机森林(RF)4种学习算法作为初级分类器进行组合学习,进而采用随机森林算法作为次级分类器提升分类效果。
1 水稻表型组学知识库的构建
1.1 水稻表型组学数据获取
水稻表型组学数据主要从“国家水稻数据中心”网站(http:∥www.ricedata.cn/)获取,并以互动百科网站作为辅助数据源。Scrapy[18]爬虫框架作为本文数据获取的工具,其充分利用处理器资源,快速抓取结构化数据;支持分布式爬虫,适合大规模水稻表型组学数据的获取。
1.2 水稻表型组学知识图谱示例
存储水稻表型组学数据的数据库使用专用于图存储的图数据库Neo4j[19],图数据库利用结点和边的方式表示实体、属性与关系,使得数据表示更为直观清晰,适用于存储水稻表型组学实体、属性及关系。本文使用RDF三元组的数据表示形式,存放实体-属性或实体-关系,共存储4 853个数据结点,5 438条关系,每个结点包括ID、title、detail等属性。Neo4j图数据库使用的专门图形查询语言Cypher,简单快捷,便于操作,且能够以图、表、文本的形式展示数据。实例如图1所示。
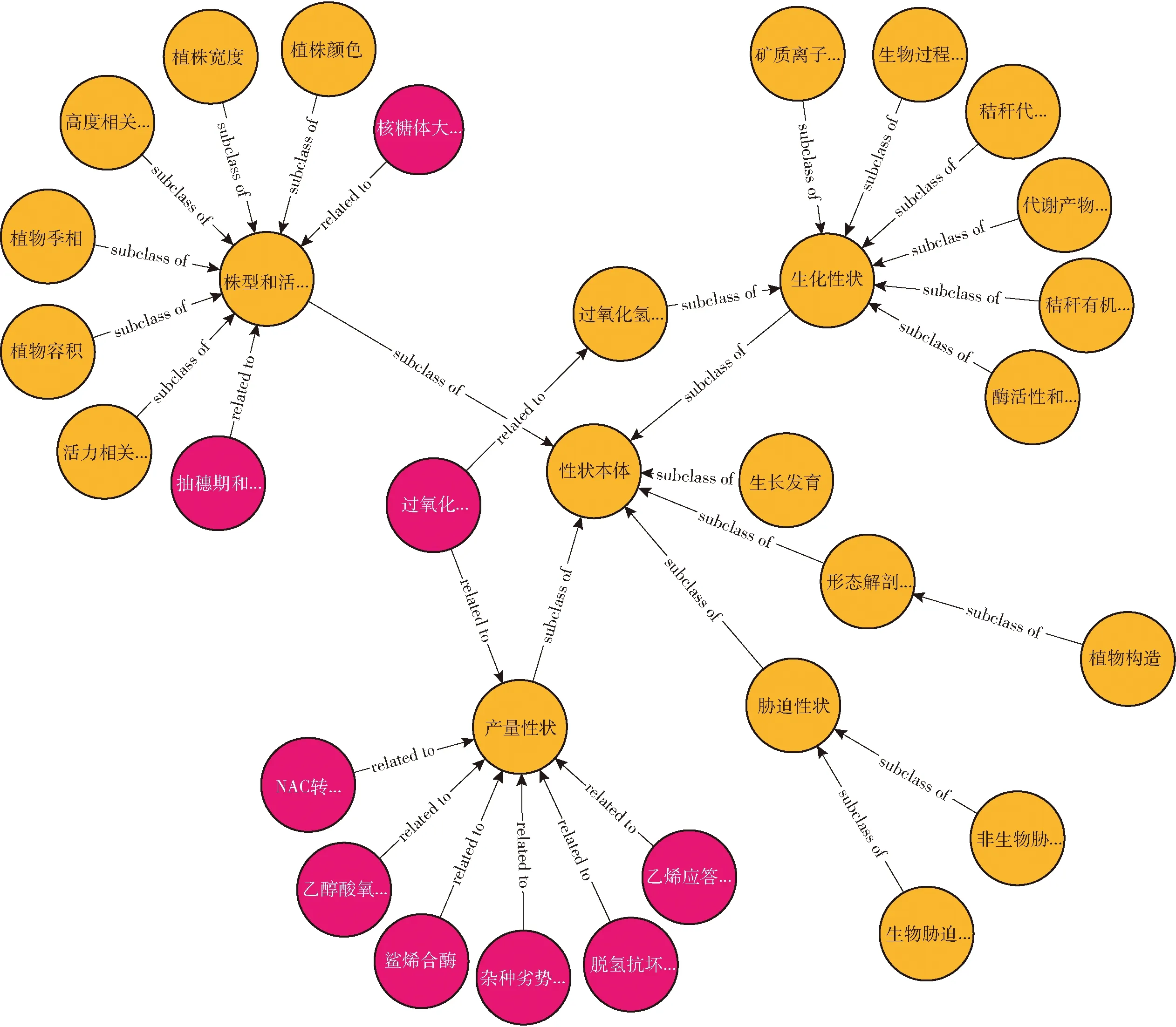
图1 水稻表型组学实体-关系实例Fig.1 Entity-relationship instances of rice phenomics
1.3 水稻表型组学实体识别
水稻表型组学实体识别是指识别水稻表型组学文本数据中具有特定实际意义的水稻表型组学实体,包括表型、基因、蛋白质、环境等专有名词。本文从国家水稻数据中心获取的大量非结构化水稻表型组学数据中抽取实体,针对收集的语料库进行分词及词性标注,根据词性标注结果基于一定的启发式规则进行词语组合,从文本中提取具有实际意义的实体。图2所示为水稻表型组学实体识别过程。

图2 水稻表型组学实体识别过程Fig.2 Rice phenomics entities recognition process
为实现水稻表型组学实体识别,本文借助THULAC分词工具进行分词及词性标注。THULAC是一套中文词法分析工具包,集成了世界上最大规模的中文语料库,中文分词及词性标注能力强、准确率高、速度快[20]。
启发式规则是指在解决问题时根据以往经验而制定的一系列规则,重点在于根据经验选择行之有效的方法[21]。本文水稻表型组学实体启发式规则如图3所示。

图3 水稻表型组学实体判断的启发式规则Fig.3 Heuristic rules for determination of rice phenomics entities
水稻表型组学实体识别中,根据已有经验,表型组学实体词性只能为名词,因此除了名词之外的其他词性应被丢弃。在名词基础之上应该检验该词的前一词是否为修饰性词性,是则与该词组成名词性短语。
图4为本文所列实体识别结果的示例,可以看出“小肠”、“叶序”等词属于满足当前词性要求的词语,“镁离子浓度”、“植物细胞长度”等词属于当前词与其前一词的组合词语。由于水稻表型术语与基因组术语是专业性实体名词,因此本文对水稻表型术语及基因组术语不再进行分词及词性标注,直接将这两类词语加入到实体识别结果中,最终共6 445个词。

图4 水稻表型组学实体示例Fig.4 Example of rice phenomics entities
2 水稻表型组学实体分类
2.1 水稻表型组学数据预处理
对水稻表型组学语料库所做的预处理操作为将文本处理成特征矩阵。文本向量化是将文本特征表示成一系列计算机可以计算和理解的,能够表达文本语义信息的向量形式[22],通过一定的数理统计方法和计算机技术展现文本特征。目前文本向量化大部分是通过词向量化实现。
本文使用TF-IDF技术并结合LSI模型对数据进行预处理,计算文本词频特征,解决文本语义问题,对水稻文本数据进行特征向量化形成语义矩阵。
如图5所示,该过程首先将文本语料字典转换成词袋向量,便于计算其TF-IDF值,将转换成的TF-IDF向量转换成LSI向量,接着将生成的向量转换成稀疏矩阵,稀疏向量最后转换成密集向量,即为机器学习分类器模型接受的输入形式。

图5 水稻表型组学数据预处理过程Fig.5 Preprocessing of rice phenomics data
2.1.1TF-IDF模型
词袋(Bag of word, BOW)[23]模型是最早出现的文本向量化方法,它将词语作为文本的基本组成单元,该模型与每个词语在文本中出现的频率具有一定的相关性,其产生的向量与文本词语出现的顺序无关。该模型原理比较简单,但易出现维度灾难和语义鸿沟等问题。
TF-IDF(Term frequency-inverse document frequency)[24]是一种基于词袋模型改进产生的,以计算词频及逆文本频率来计算词语分类能力,用于文本特征分析挖掘的常用方法。采用字词统计方法,分别统计一个文本中该词出现的频率和整个语料字典中该词出现的频率来综合评估字词的分类能力。TF指词频,即一个字词在文本中出现的频率,出现次数越多,频率越高,TF值就越高。IDF指逆文本频率,若一个字词在某一类文本中出现的频率高,而在其他类别文本中出现的频率低,说明该字词具有良好的类别鉴别能力,对应该字词的IDF值越高。TF、IDF的计算公式为
(1)
式中TF(w)——词w在当前文本中的词频
n(w)——词w在文章中出现的个数
S——文本的总词数
(2)
式中IDF(w)——词w在当前文本的逆文本频率
N——语料库中的文本总数
N(w)——语料库中包含词w的文本总数
TF-IDF值的计算公式为
TF-IDF(w)=TF(w)IDF(w)
(3)
以“半矮秆基因”URL网页(http:∥www.ricedata.cn/gene/list/30.htm)为例,该文有902个词,“水稻”、“半矮秆基因”分别出现13、2次,通过式(1)得出词频(TF)为0.014 4、0.002 2。网页总数为1 966,包含“水稻”的网页数为1 731个,包含“半矮秆基因”的网页数为16个。则它们的逆文本频率IDF和TF-IDF计算示例如表1所示。
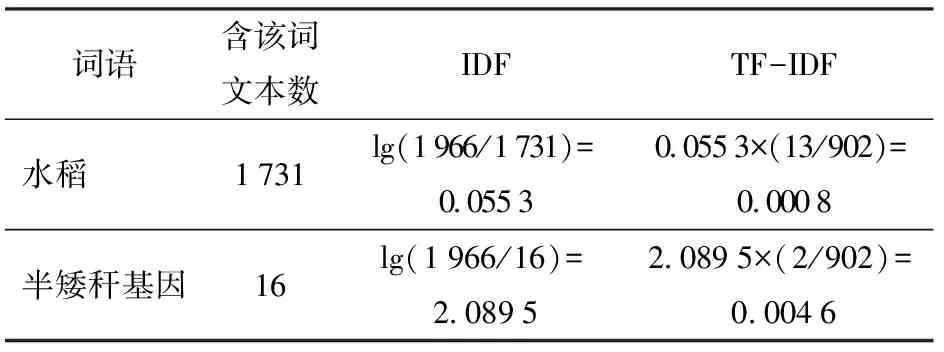
表1 IDF和TF-IDF计算示例Tab.1 Examples of IDF and TF-IDF evaluation
表1中的TF-IDF值表明,常出现的词语“水稻”,应该给予较低权重。对于词语“半矮杆基因”,几乎没有在其他文本中出现,在出现的文本中它对应的IDF值较高,具有较强的类别鉴别能力。
2.1.2LSI模型
潜在语义模型(Latent semantic index,LSI)[25]为解决文本语义问题,如果文本中的某个词与其他词的相关性不大,则很可能是一词多义的问题。LSI模型使用奇异值分解方法来分解词语-文本矩阵,将原始矩阵映射到语义空间内,形成语义矩阵。
利用奇异值分解方法降低矩阵维度,计算公式为
(4)
式中Ar×c——第r个文本第c个词的特征值
Ur×j——第r个文本第j个主题的相关度
Σj×j——第j个主题第j个词义相关度
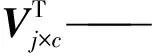
这里使用的特征值是基于预处理后的标准化TF-IDF值。j是设定的特征维度,也称为主题数,一般比文本要少,一般设定在100~200之间,本文j设定维度为150维。经过一次奇异值分解,可以得到r个文本与c个词的关联程度。
2.2 水稻表型组学实体分类算法
2.2.1Stacking集成学习模型
基于Stacking[26]集成学习策略是一种异构分类器集合的技术,被认为是实现集合中基分类器多样性的工具,以此提高组合分类的准确性。它采用两层框架的结构,如图6所示。具体的训练过程为:首先是Stacking集成学习方法调用不同类型的分类器对数据集进行训练学习,然后将各分类器得到的训练结果组成一个新的训练样例作为元分类器的输入,最终第2层模型中元分类器的输出结果为最终的结果输出[27]。
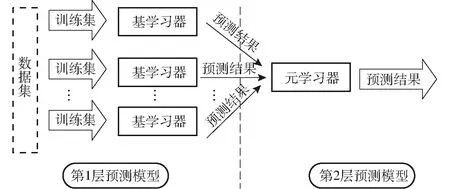
图6 基于Stacking的集成学习方式Fig.6 Ensemble learning method based on Stacking
在组合模型中,对基分类器的选取有两种选择:一种是选取同种类型的基分类器,另一种是选取不同类型的基分类器,或者说是异质的。本文采用第2种选择方法,基于Stacking集成学习的两层结构框架对几种不同的分类器组合学习。具体使用SVM、K-NN、GBDT和RF作为第1层的分类器,即基分类器,RF作为第2层的元分类器。针对这4种常见的单一分类器,具有性能优异且训练机理差距大的特点,提出了将这4种算法进行组合学习,从而进一步提高分类器的分类性能。
2.2.2SVM算法
SVM[28-29]是指一系列以支持向量机算法为基础的传统机器学习方法,可以用于文本的回归和分类问题。SVM的主要原理是找到一个能够将所有数据样本划分开的超平面,使得样本集中的所有数据到这个超平面的距离最短。
使用SVM做分类问题主要分为线性分类和非线性分类。当一个分类问题是线性可分时,可以直接用一条直线将不同类别的数据进行区分,这条分类直线称为决策面。为求得最优的分类效果和性能,只需要计算数据与决策面的最大距离即可,寻找这个最大间隔的过程就叫最优化。但是,随着数据量的增多,数据分布不均衡,数据变成线性不可分的,这时就需要核函数将数据映射到特征空间,利用超平面对数据进行分类分割。
2.2.3K-NN算法
K-NN算法[30]是一种通过计算不同数据之间特征值的距离进行分类的方法,是文本分类和回归常用的分类算法之一,目前对K-NN算法的理论研究已经非常充足。K-NN算法的主要原理是,如果一个预测样本在特征空间内存在K个最近邻,那么预测样本的类别通常由K个近邻的多数类别决定。K-NN算法中通过选择K值、距离度量方法,以及分类决策规则来优化算法的效果和性能。
K值的选择一般根据样本的分布,通过交叉验证的方式选择一个最优的K值。若选择较小的K值,训练误差会减小,但容易使得训练的泛化误差增大,使模型复杂且容易过拟合。若选择较大的K值,可以减小泛化误差,模型预测结果一般不会出现过拟合现象,但会使训练误差增大,造成预测发生错误。因此,需要选择合适的K值训练模型,本文算法参数优化选择使用GridSearch进行验证。
2.2.4GBDT算法
GBDT算法[31-32]提升分类器性能的方式不是为错分数据分配更高权重,而是直接修改残差计算的方式,原始的Adaboost[33]限定了损失函数为平方损失函数,所以可直接进行残差计算。GBDT通过定义更多种类的损失函数,采用负梯度的方式近似求解,这也是称其为梯度提升树的原因。由于这个改进,GBDT不仅可以用于分类,也可以用于回归,有着更好的适应性。并且GBDT的非线性变换较多,所以其表达能力很强。
2.2.5RF算法
RF算法[34]是一种集成算法,通过训练多个弱分类器集成一个强分类器,预测结果通过多个弱分类器的投票或取平均值决定,使得整体模型的结果具有较高的精确度和泛化性能。随机森林算法的主要原理是,通过随机采样方式构建一个随机森林,随机森林的组成单元是决策树,当进行预测时,森林中的每一棵决策树均参与分类预测,最终通过决策树投票选取得票数最高的分类作为预测分类。
2.3 水稻表型组学实体分类组合模型
考虑基学习器的预测能力,本文在Stacking集成学习的分类器组合模型第1层选择学习能力较强和差异度较大的模型作为基学习器,有助于模型整体的预测效果提升。其中,随机森林和梯度提升决策树分别采用Bagging和Boosting的集成学习方式,具有出色的学习能力和严谨的数学理论,在各个领域得到广泛应用。支持向量机对于解决小样本和非线性以及高纬度的回归问题具有优势。K-NN算法因其理论成熟和训练高效等特点,有着良好的实际应用效果。第2层元学习器选择泛化能力较强的模型,用于纠正多个学习算法对于训练集的偏置情况,并通过集合方式防止过拟合效应出现。综上所述,Stacking集成学习的分类器组合模型选择第1层基学习器分别为SVM、K-NN、GBDT、RF,第2层元学习器选择RF。Stacking集成学习的分类器组合模型如图7所示。
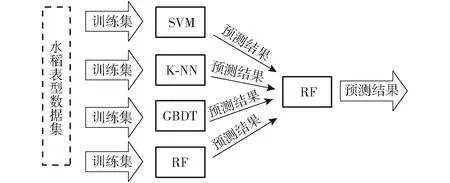
图7 基于Stacking集成学习的水稻表型组学实体分类器组合模型Fig.7 Combination model of Stacking ensemble learning classification algorithm for rice phenomics entities
在水稻表型组学实体分类组合模型框架中,过程分为5步,处理过程总结为:
输入:训练集D={(yi,xi);i=1,2,…,m},基分类器,测试集T。
输出:测试集上的分类结果。
(1)使用TF-IDF技术结合LSI模型进行数据预处理。
(2)第1层预测算法的K个基学习器Mk。
fork=1 toK
基于数据集D-k训练第1层的基学习器Mk
end
(3)构成新数据集
Dnew={(yi,z1i,z2i,…,zki);i=1,2,…,m}
(4)第2层使用随机森林算法Mnew预测模型训练。
基于Dnew训练模型Mnew。
(5)使用测试集T分类,评价分类结果。
首先利用TF-IDF技术结合LSI模型的方法对获取的水稻表型组学数据进行文本预处理,预处理后的水稻表型组学数据D={(yi,xi);i=1,2,…,m},xi为第i个样本的特征向量,yi为第i个样本对应的预测值,将数据集切分为训练集和测试集,随机将数据划分成K个大小基本相等的子集D1,D2,…,Dk。D-k=D-Dk,定义Dk和D-k分别为K折交叉验证中的第k折测试集与训练集。第1层包含K个基学习器,基学习器包括SVM、GBDT、RF、K-NN。对训练集D-k用第k个算法训练得到基模型Mk,k=1,2,…,K。对于K折交叉验证中的第k折测试集Dk中的每一个样本xi,基学习器Mk对它的预测表示为zki。
在完成交叉验证过程后,将每个基学习器的各自预测结果构成新的数据样本,即:Dnew={(yi,z1i,z2i,…,zki),i=1,2,…,m},重构特征,将第1层基学习器的输出结果作为第2层学习器Mnew的输入,本文选择随机森林算法作为第2层预测模型的元学习器进行训练,再由第2层的元学习器模型输出最终预测结果,基于Stacking集成学习的分类器组合模型通过多个学习器的输出结果提升模型的分类能力,以获得整体预测精度的提升。
3 分类结果与分析
3.1 实验环境
本文实验环境:Intel(R) Core(TM) i5-8250U 1.6 GHz处理器,8 GB内存,500 GB硬盘,64位Windows 10操作系统。
3.2 参数设置
Stacking集成学习通过将K-NN、RF、SVM、GBDT模型作为初级学习器,4个验证集的输出组合成次学习器的一个输入特征,进行再次训练。各算法的参数设置如下:SVC算法模型使用RBF核函数,gamma参数设置为0.1,惩罚系数C设置为3;K-NN算法模型近邻个数设置为6,用L2距离来标识每个样本的近邻样本权重,权重与距离成反比;RF算法模型计算属性的信息增益值来选择合适的结点,选择划分的属性值最大值为9,叶子结点的最少样本数为2,决策树的个数为81;GBDT算法模型的弱学习数量为100,学习速率设置为0.1,回归树的深度为3。训练集和测试集的大小比例设置为7∶3。
3.3 数据集
基于Stacking集成学习的分类器组合模型,要实现水稻表型组学实体自动分类,需利用人工分类方法制作数据集,数据集的品质直接影响到机器训练的品质。在进行人工分类时,首先对含有明显特定字词的词语进行提取,对不明显的词语通过人工分类的方式逐词进行标注[35]。水稻表型组学实体分类情况参照文献[36],如表2所示。

表2 水稻表型组学实体分类情况Tab.2 Detail of entity classification of rice phenomics
3.4 算法性能评估指标
本文使用的5种机器学习方法:基于Stacking集成学习的分类器组合模型、SVC算法、K-NN算法、RF算法、GBDT算法均使用TF-LSI方法预处理,使用GridSearch进行算法模型参数调优。实验模型的评估使用精确率P(Precision)、召回率R(Recall)、综合评价指标F1(F1-Measure)、准确率A(Accuracy)等指标,计算公式为
(5)
(6)
(7)
(8)
式中TP——将实际为正类预测为正类的数量
TN——将实际为正类预测为负类的数量
FP——将实际为负类预测为正类的数量
FN——将实际为负类预测为负类的数量
F1是模型精确率和召回率的一种加权平均值,介于0到1之间,F1越高,代表分类器的综合性能越好。F1是分类问题中的一个常用的衡量指标,能够对模型精确率与召回率进行综合评估。
3.5 Stacking算法分类结果
利用TF-IDF技术结合LSI模型的方法进行水稻表型组学数据预处理,作为Stacking集成学习的分类器组合模型的输入样例。这里以获取的水稻表型组学数据为例,首先对Stacking集成学习的分类器组合模型分类结果进行分析,然后对比单一分类算法,从而验证Stacking集成学习的分类器组合模型分类性能的优异性。
Stacking集成学习吸收融合模型的优点提高准确率和稳定性。通过将K-NN、RF、SVM、GBDT模型作为初级学习器,4个验证集的输出组合成次学习器的一个输入特征,进行再次训练。Stacking集成学习的分类器组合模型实验结果如表3所示。
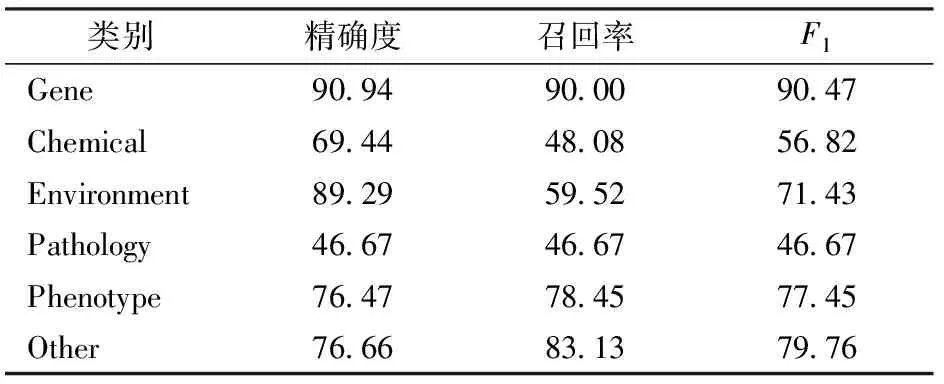
表3 Stacking算法各实体类别实验结果Tab.3 Experimental results of various kinds of rice entities with Stacking algorithm %
从表3结果来看,在水稻表型组学数据中,组合模型对数据量较大的分类如Environment类、Phenotype类和Other类的分类精确度均达到76%以上,最佳的分类是Gene类,达到90.9%以上的分类精确度,多分类结果的召回率和F1值均在90%以上。对于不平衡数据集,Stacking集成学习的分类器组合模型在数据量较大的类别上的表现较为突出,在水稻表型组学数据的多分类问题上具有较强的分类性能。
3.6 分类结果对比
将对单一分类器算法和Stacking集成学习的分类器组合模型的分类结果进行对比分析。各分类算法对水稻表型组学实体的分类精度对比如图8所示。
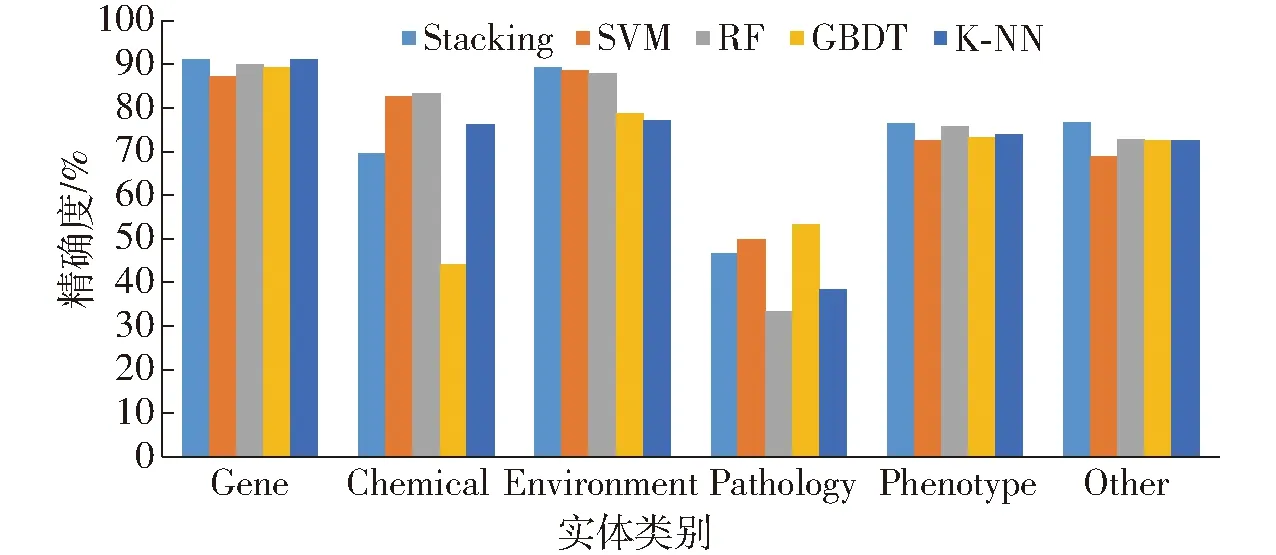
图8 各分类算法精确度对比Fig.8 Comparison of precision of classification algorithms
由图8可以看出,Stacking算法对各类别的分类效果均较好,包括类别数量较少的Chemical类和Environment类,整体上优于其他分类方法,对Gene类的分类精确度达90.9%。
各分类算法对水稻表型组学实体的分类召回率对比如图9所示。
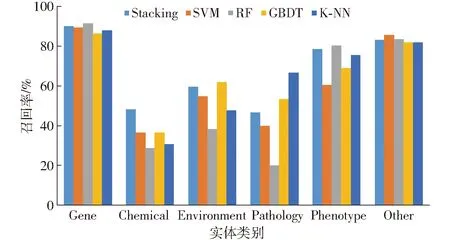
图9 各分类算法召回率对比Fig.9 Comparison of recall rate of classification algorithms
由图9可以看出,水稻表型组学数据的Gene类、Phenotype类、Other类的整体召回率均较高,尤其是Stacking集成学习模型和随机森林算法在其3种分类上表现较优。但无论是针对哪种类型水稻表型组学实体,Stacking集成学习模型分类结果的召回率均较高,显示其较强的分类性能。
各分类算法对水稻表型组学实体的分类F1对比如图10所示。
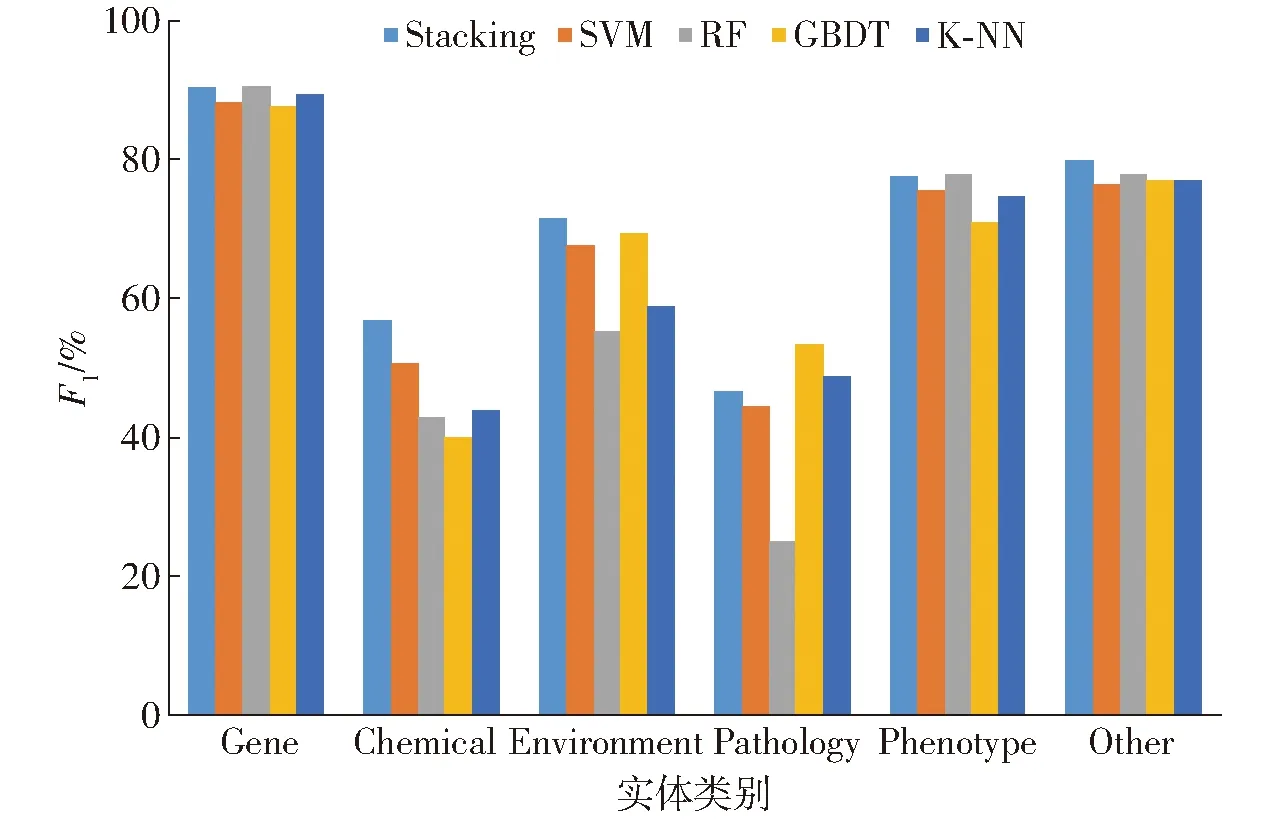
图10 各分类算法F1值对比Fig.10 Comparison of F1-Measure of classification algorithms
由图10整体来看,Gene类、Phenotype类、Other类3类算法整体分类的精确率和召回率的加权平均值F1较高,Chemical类、Environment类和Pathology类的F1相对较低,这是由于各类数据集数量分布不均衡造成的,相对Gene类、Phenotype类和Other类训练数据较多,分类更精确,综合性能较好。
Stacking、RF、K-NN、GBDT、SVM各分类算法准确率分别为80.55%、72.97%、67.51%、76.24%、78.34%,通过对比K-NN、GBDT、RF、SVM 4种算法,Stacking集成学习的分类器组合模型的准确率最高。Stacking集成学习算法集成了其他4种弱分类器,对于准确率有一定的提升。相比单一分类器K-NN算法,基于Stacking集成学习的分类器组合模型的分类准确率高13.04个百分点,性能提升较大,平均比单一分类器提高6.78个百分点。
综上所述,在TF-IDF技术结合LSI模型方法进行水稻表型组学数据预处理的情况下,Stacking集成学习的分类器组合模型在本文水稻表型组学数据集上的整体效果最佳。对于不平衡数据集,Stacking集成学习分类器的组合模型的表现较为突出,整体精确度、召回率和F1值均较高。总体上,Stacking集成学习的分类器组合模型较单一的分类器,在分类性能上有一定的提升,准确率较分类性能较好的SVM算法提高2.21个百分点,较K-NN算法准确率提高13.04个百分点。
4 结束语
针对水稻表型组学数据,采用TF-IDF技术和潜在语义模型进行预处理,基于堆叠式两阶段集成学习的分类器组合模型,结合K-近邻算法、支持向量机、随机森林,梯度提升决策树机器学习方法,提升水稻表型组学实体数据分类的性能,对于不平衡的水稻表型组学数据集和对不同类别的水稻表型组学数据都具有较好的多分类能力,总体准确率为80.55%,相对SVC、K-NN、GBDT、RF单一分类器,表现最佳,分类准确率平均高6.78个百分点。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
昆明医科大学学报(2022年3期)2022-04-19
河北果树(2021年4期)2021-12-02
昆明医科大学学报(2021年4期)2021-07-23
智慧健康(2021年33期)2021-03-16
计算机系统应用(2021年2期)2021-02-23
天津医科大学学报(2021年1期)2021-01-26
天津医科大学学报(2021年1期)2021-01-26
医药前沿(2020年20期)2020-11-10
电子技术与软件工程(2019年18期)2019-11-18
