
基于DPI及人工智能的业务识别系统研究
2019-12-05 02:48王璐
无线互联科技 2019年16期
王璐

摘 要:文章综合分析了已有的网络业务识别技术的特点并进行综合对比,同时结合DPI和机器学习技术,提出了基于DPI以及人工智能的业务识别系统,并通过实验结果验证此系统在识别业务的正确性上优于现有的业务识别系统。
关键词:深度报文监测技术;机器学习;人工智能;业务识别
在互联网飞速发展的背景下,根据网络流量识别网络业务,逐渐成为网络技术研究的重要课题。为了提供更好的网络服务,识别互联网中各种业务流量,也成了互联网中运营商和服务商面临的新挑战。通过业务识别系统,互联网中的运营商以及服务提供商能够采集与分析互联网中各种应用产生的流量,识别不同的业务流量类型并进行分类,进而根据不同的业务类型提供不同的业务和服务保障。
随着互联网的发展,网络业务的种类多种多样,特别是近10年移动互联网的发展日新月异,随之海量的移动APP业务应用遍地而生,于是对于网络流量协议的识别近几年备受关注,原因如下:(1)网络业务的识别,有助于网络管理者对网络进行监控管理,企业可以借助流量识别来控制用户对相关应用的访问。(2)网络安全状况的复杂性使得互联网急需管理和维护,防火墙以及防御入侵系统非常迫切地需要识别网络上的恶意流量。(3)运营商以及相关网络服务商可以通过网络流量分析识别和推测用户信息与行为,为精准营销做市场准备。因此,通过流量识别技术去识别业务在网络监控管理、用户行为分析、网络信息安全方面有着重大的意义。
本文对目前国内外已有的业务识别方法进行了综合对比和分析,总结传统识别方法的优劣,并结合大部分企业正在应用的基于深度报文监测技术(Deep Packet Inspection,DPI)的业务识别技术以及少量企业初步实践的基于机器学习的业务识别技术,提出了一种综合的业务识别方法,该方法结合了两种技术的优点,目前在运营商中已经有了很好的推广和应用。
1 传统业务识别方法
传统的业务识别方法主要包括3种:(1)基于端口号的业务识别。(2)基于DPI的业务识别。(3)新兴的基于机器学习的业务识别。目前,基于端口号的流量识别系统在传统的网络环境中得到了广泛的应用,随着互联网的发展,逐渐被基于DPI的业务识别系统所替代,基于机器学习的人工智能系统已经逐渐在行业中占据一席之地,在识别准确率以及识别效率上都有所提高。
1.1 通过端口号进行业务识别
在流量识别技术发展的初期,使用端口约定的方法对网络上的各种应用和协议进行分类,因此研究者也同样可以使用端口映射的方法对网络流量进行识别分类。
所谓端口映射,就是假设存在一个映射,定义域为网络端口号的集合,值域为网络应用软件或网络协议所组成的类型的集合,这个映射就是网络端口与网络应用协议的映射,可以看作是基于网络端口的识别方法的定义[1]。
互联网地址编码分配机构IANA[2]例如基于HTTP协议的Web应用,使用的服务器端口号是80,基于文件传输协议(File Transfer Protocol,FTP)协议的文件传输应用则是使用20与21端口,telnet远程访问终端协议使用23端口。
通过端口号进行业务识别采用的规则简单且易于实现,在传统网络中识别率和准确率都较高。但是随着互联网的发展,各种层出不穷的应用越来越多,大多数应用为了躲避网络拥堵或绕过防火墙检测,逐渐采用动态端口或端口伪装技术,例如一些Web服务器和FTP服务器在搭建过程中均可以手工指定服务器端口,而不是使用传统的80和20,21端口。这样做提高了服务器的灵活性,而且也为服务器的多用途和单应用复用提供了可能,但这使得这种原始的流量识别技术逐渐失效。
1.2 通过DPI進行业务识别
DPI是一种对应用层的数据包进行流量监测及控制的技术,主要包括业务识别、业务控制和业务统计3大功能[3]。
本文主要研究业务识别功能,基于DPI的业务识别主要对业务类型、业务分布及业务流量流向进行深度分析,通过查找特征字段判断业务流的具体应用类型,其基本原理如下:
在分析数据包报文头部信息的基础上,也对数据包的应用层协议进行分析,当数据流经过基于DPI技术的网络系统时,系统检测引擎通过读取IP数据包载荷的内容来对报文应用层信息进行识别,从而区分出具体应用层协议并执行相应的控制策略。在这个过程中,数据包载荷的内容识别,主要应用了特征分析与提取方法,分析数据流经过网络通信时,数据包负载内容的特征,将其提取为特征码。这些特征码可以是负载中某些特定位的二进制数据,可以是某些特征字符串,也可以是负载通过哈希变换后的数字签名[4]。系统开发时,基于各种类型的特征码建立一个特征规则库,并随着网络数据流的变化逐渐进行人工维护与更新。当流量产生的数据包通过识别系统检查数据包中是否携带知识库中的特征码,如果是则表示该流量与该特征码匹配,根据匹配的特征码即可识别流量类型。
基于特征码的DPI业务识别方法,对互联网绝大部分流量识别的准确度相对较高,是一种有效的流量识别方法。但是DPI知识特征库的维护与更新对人工操作依赖较强,新特征码的提取以及纳库是否及时,直接决定了该方法对于新的网络流量类型的识别准确性与有效性。
1.3 通过机器学习进行业务识别
机器学习(Machine Learning,ML)是近年来兴起的一门融合多个领域的交叉学科,其目标是通过学习已有的先验知识构建学习模型,同时,使用该学习模型对未知的数据进行分类或者预测,并在这一过程中通过自我学习不断完善已构建的学习模型,进而提高学习模型的分类性能。
机器学习方法的原理:首先,系统提取网络流量统计特征,构建多样本数据集(包含流量类别标签);其次,作为机器学习的先验知识,机器学习通过学习这一先验知识构建出一个分类模型,使用已构建的分类模型达到对未知类型流量的分类。
機器学习的流量识别方法如下:
第一步,需要获取大量的流量数据。当前使用的数据集有两种来源:(1)使用各种抓包工具本地收集流量。(2)使用相关组织或研究公开的数据集[5]。
第二步,特征提取与处理。Moore等[6](2005)总结出248种流量统计特征。Shi等[7](2017)提出基于wavelet leaders的多重分形建模技术提取流量的非线性特征。无论是哪种特征提取方法,都是基于流量特征的统计工作进行的,只是分类的对象和角度不同。
第三步,建立机器学习模型。卷积神经网络(Convolutional Neural Network,CNN)是基于深度学习理论的人工神经网络,提供了一种端到端的学习模型,模型中的参数可通过传统梯度下降方法进行训练。经过训练的卷积神经网络能够学习原始数据中的特征,并且完成对数据特征的提取与分类[8]。卷积神经网络算法能自动提取原始数据中的特征,从而有效解决了识别率依赖于人为特征选择的不足。
1.4 传统业务识别方法对比
综合上文分析的已有业务识别方法,从不同角度对各种方法进行对比,具体如表1所示。
可见,DPI和机器学习方法在识别业务的准确率有很大的优势,但是从其他角度对比却各有利弊,所以可以结合两种业务识别方法优点,提出一种综合业务识别方案。
2 基于DPI及人工智能的智能业务识别方法
基于DPI及机器学习的智能业务识别系统主要由业务识别服务器、深度学习训练服务器、DPI服务器3部分组成。
2.1 业务识别服务器
业务识别服务器与DPI服务器和模型训练器相连接,负责接收按照接口要求初步预处理的数据,根据DPI的规则库进行模式匹配,以及根据机器学习训练模型进行匹配,最终返回业务识别结果。
2.2 DPI服务器
DPI服务器负责根据网络报文数据包中载荷的报文特征,定期维护特征规则库,对于简单报文数据,提取报文特征值根据规则进行匹配,进行高效的业务识别。
2.3 深度学习训练服务器
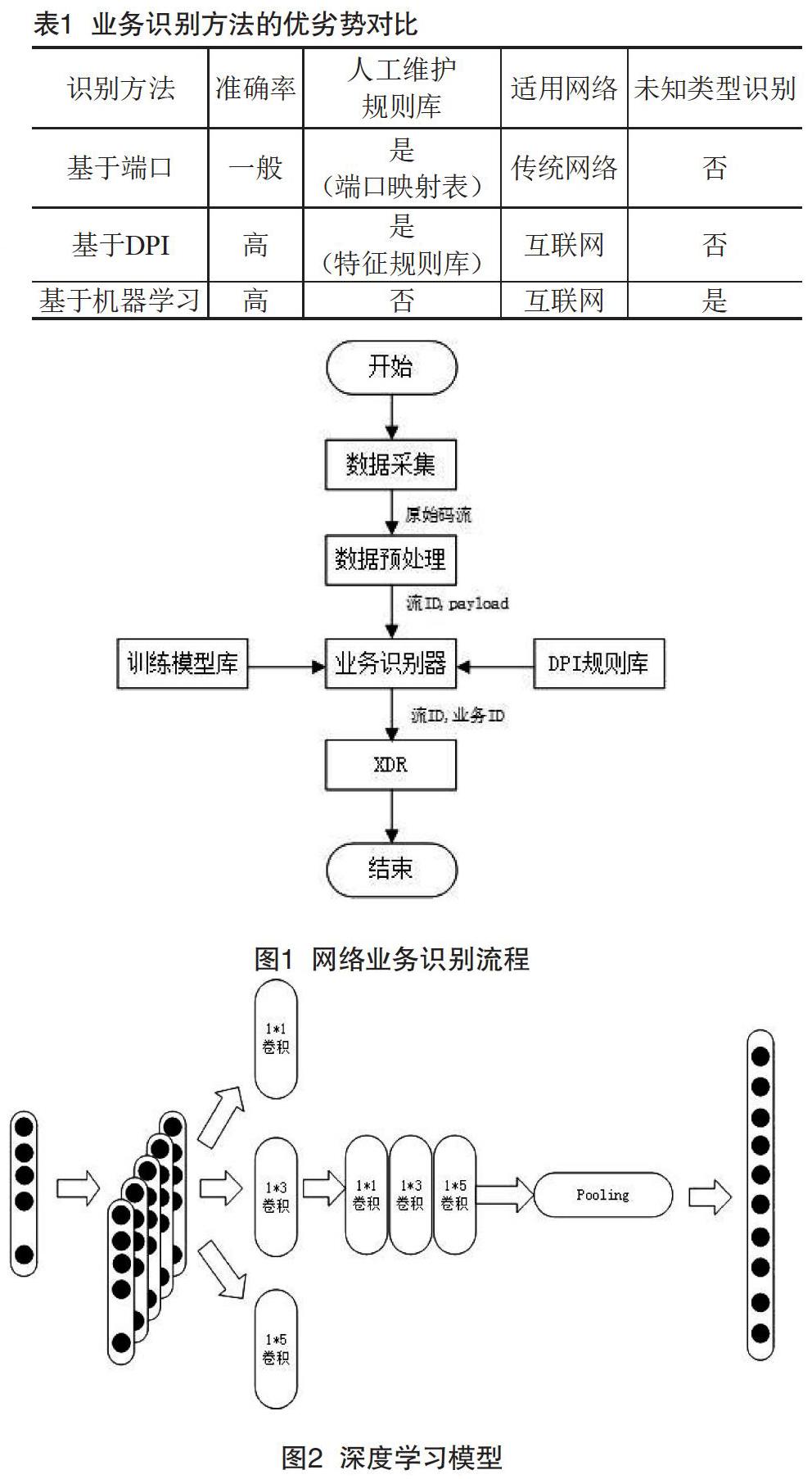
深度学习训练服务器负责每周训练新的业务识别深度学习模型,每周可以及时自动更新最新的训练模型。网络业务识别的流程如图1所示。
通过爬虫和自动点击系统,获得带有业务真实类别标签的PCAP包作为训练数据。将目前确定的500余种热门应用加入APP列表,APP爬虫系统可以自动根据APP列表的应用名称,下载安装包并自动安装,自动点击系统模拟人的点击操作在后台进行抓包,即可得到客户端与服务器交互的PCAP包文件。深度学习模型以APP名称以及PCAP数据包为输入,即可进入模型训练。
人工智能的机器学习模块是以卷积神经网络为核心的深度学习模型,如图2所示。
3 对比分析
与传统的DPI业务识别模式以及单独的机器学习模式相比,基于DPI及人工智能的业务识别系统在业务识别的准确性、模型更新周期以及人力成本上有很大的优势,如表2所示。
在互联网中测试90款主流APP,将业务识别系统生成的外部数据表示法与真实的答案进行对比寻求业务识别的正确率,基于IDP+人工智能方案的整体正确率达到81.3%(机器学习达79.7%),对于热点业务的预测正确率达74.3%(与机器学习持平),新业务预测的正确率达88.4%(机器学习达82.5%)。总体来说,基于IDP+人工智能方案的识别正确率优于机器学习的业务识别方案。
4 结语
本文综合分析了当前国内外已有的业务识别方法,总结传统的几种识别方法的优劣,并结合基于DPI以及机器学习的业务识别技术,提出了一种综合的业务识别方法,该方法结合了两种技术的优点,对90款主流APP的网络流量进行采集测试,其业务识别的整体正确率、对热点业务预测的正确率,以及对新业务预测的正确率均优于现有的传统业务识别方案。
[参考文献]
[1]陈乾熙.网络流量识别方法及比较研究[J].今日科苑,2015(8):106.
[2]彭立志.基于机器学习的流量识别关键技术研究[D].哈尔滨:哈尔滨工业大学,2015.
[3]杨扬.浅谈DPI技术在IP城域网中的应用实践[J].信息通信,2018(9):268-269.
[4]彭立志.互联网流量识别研究综述[J].济南大学学报(自然科学版),2016(2):95-104.
[5]SALGARELI L,GRINGOLI F,KARAGIANNIS T.Comparing trafic clasifiers[J].Computer Communication Review,2007(3):65-68.
[6]MOORE A,ZUEV D,CROGAN M.Discriminators for use in flow-based clasification[C].Cambridge:Intel Research,2005.
[7]SHI H T,LI H P,ZHANG D,et al.Eficient and robust feature extraction and selection for trafic clasification[J].Computer Networks,2017(C):1-16.
[8]PHAMTH,NGUYEN H H.Payload and power consumption analysis of IEEE 802.15.6 based WBAN with CSMA/CA[C].Nanjing:In-ternational Conference on Advanced Technologies for Communica-tion,2014.
猜你喜欢
西安航空学院学报(2022年2期)2022-07-04
IT经理世界(2018年20期)2018-10-24
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
