
基于LightGBM算法的信用风险评估模型研究
2019-12-04 01:47王思宇陈建平
软件导刊 2019年10期
关键词:信用风险
王思宇 陈建平


摘要:对于银行、P2P等金融机构而言,如何在扩大业务规模的同时,有效控制并合理防范信用风险尤为重要。基于LightGBM算法,根据借款申请人提供的相关个人信息,建立分类预测模型,对借款人是否会逾期、是否该发放贷款进行预测研究。实验结果表明,相较于普通决策树算法,LightGBM预测精度提升了40.8%,且具有较好的鲁棒性,可满足信用评估要求。基于LightGBM的信用评估模型不仅拥有更快的训练速度和更高的训练效率,同时还占用更少的內存,具有支持数据并行处理能力。利用该模型可对用户信用风险进行较为准确的预测,对贷款机构风险管理有重要参考价值。
关键词:信用风险;LightGBM;分类预测
DOI:10.11907/rjdk.191157开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2019)010-0019-04
0引言
近年来,我国经济一直保持高速发展,居民的信贷意识日益提高,个人信贷业务也获得蓬勃发展,在金融信贷机构贷款业务中的占比持续增多。然而,品类繁多的信贷业务在为人们提供便利的同时,其潜在风险也不容忽视。每年由于资金链断裂、违约、骗贷等因素导致停业的金融信贷机构就有上千家。由此可见,信用风险评估对金融信贷机构的平稳运行具有重要意义。
随着大数据时代的来临,信用风险评估理论及方法不断涌现。刘铮铮、康为勋运用层次分析法对企业信用评级进行研究;李昕、蒋志旺基于BP神经网络研究信用风险预测模型;孙同阳、王雅静则认为利用决策树方法进行信用评估预测更为有效;Chen等通过朴素贝叶斯对申请人进行信用评级;Bellotti等提出借款人违约的离散时间生存模型,通过模拟极端经济条件,展示了如何使用该模型对申请人进行测试。上述方法都是基于传统评估指标,结合机器学习知识构建的评估方法,仍存在一定的局限性,例如人工神经网络在训练时,若训练次数不足则会过拟合,同时算法本身的收敛速度较慢,时常会陷入局部最优解。因此,选择一种精度高、运算速度快、不易过拟合的算法做评估模型尤为必要。
LiChtGBM算法具有速度快、效率高、占用资源少、支持并行处理等优点。本文选用基于LightGBM的梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法,以某金融信贷机构经过脱敏处理后的数据为基础,探索不同类别数据中的隐藏联系,从而建立一个更为准确的信用评估模型。如此既能减少人为因素导致的主观性和盲目性,又能减轻因个别数据缺失对评估结果造成的影响,从而促进个人信贷业务快速、安全发展。
1理论基础
梯度提升决策树(Gradient Boosting Decision 7ree,GB-DT)是一种迭代决策树算法。该算法采用最速下降法,把损失函数的负梯度在当前的值当作残差的近似值,然后利用残差近似值拟合出一个回归树。该算法在决策过程中生成另外的决策树,最后将所有树的运行结果进行累加得出最终结果。
GBDT算法在训练时,要对样本进行多次遍历。若要减少训练耗时,需将训练数据全部加载到内存中,这样每次输入的样本数量就会受到限制,不能超过内存容量。如果将样本载人外存储器中,应采用决策树算法,在I/O频繁时,速度又会相应降低。LightGBM则可以很好地改善上述情况。
1.1LightGBM
LiChtGBM(LiCbt Gradient Boosting Machine)是一个基于决策树算法的提升框架,其优点是训练速度快、准确率高、内存占用率低且支持并行计算,能够处理规模庞大的数据集。
LiRhtGBM的特点之一是采用基于Histogram的决策树算法,它首先将连续型的特征值离散成k个值,然后生成一个宽为k的直方图。当遍历样本时,将经过离散的值当作索引。在经过一次遍历后,直方图累积了需要的统计量,然后通过直方图的离散值,遍历寻找最优分割点。采用这种方式既能显著降低内存占用,又可降低时间复杂度。
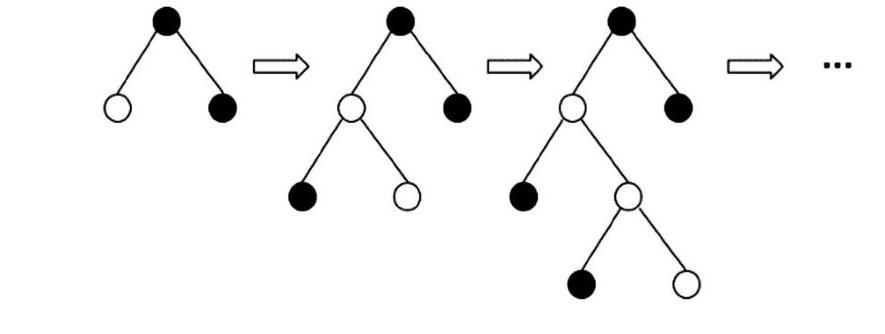
LightGBM的另一个特点是采用效率更高的叶子生长策略,即带深度限制的叶子生长策略(Lear-wise)。该策略在分裂前会首先遍历树中全部叶子,接着找到分裂增益最大的叶子进行再分裂,并重复这一操作。实验证明,同样分裂次数下,Leaf-wise可以得到更高的精度,并在Leaf-wise中加入了防止过拟合的最大深度限制。Leaf-wise叶子生长策略如图1所示,其中白点和黑点分别代表分裂增益最大和非最大的叶子。
LightGBM的一大优点是Histogram作差加速。一般而言,构造一个叶子直方图,父节点和兄弟节点直方图的宽度都為K,因此作差过程只需计算K次,从而提高了运行速度。
1.2改进后的GBDT算法流程
2实证分析
本文基于某金融信贷机构的数据集进行实证研究,并与其它常见分类算法作对比分析。
2.1数据描述与预处理
该数据集共有约30万条个人信贷记录,每一条信贷记录都包含顾客个人情况属性变量和顾客“好”、“坏”标签变量。“好”顾客的定义为按时还款,用标签0代替;“坏”顾客的定义则是没有按时还款,用标签1代替。个人情况属性变量包含了有关顾客社会人口、个人金融、债权人财产和贷款明细4个方面的共121项指标,其数据集格式如表1所示。
由表2可知,与逻辑回归、决策树、朴素贝叶斯、随机森林、集成树、XGBT等算法相比较,LightGBM的ROC_AUC得分最高,相较于普通决策树算法提升了40.8%,准确率也在70%以上,且具有较好的鲁棒性,可满足信用评估要求。
模型输出结果如表3所示,信贷机构可根据用户得分,划分不同的区间,并为每个区间制定相应的评判等级,例如“优秀”、“良好”、“一般”、“较差”等。
3结语
本文利用互联网数据进行个人信用风险评估研究与实现。对比分析不同算法模型表现,提出了基于LightGBM算法的信用风险评估模型。相较于其它主流算法模型,LightGBM算法拥有速度快、效率高、占用内存少及并行计算等优点,而金融借贷平台的数据集往往具有指标多、噪声复杂等特点,使用基于LightGBM算法的评估模型,对实际应用具有重要参考价值。
本文不足之处在于数据涵盖范围具有一定局限性,相较于类型繁多的信用数据集仅是冰山一角;并且,虽然基于LightGBM算法的信用风险评估模型在分类预测效果上有一定提升,但准确率及精度还有进一步提升的空间,可考虑将LightGBM与其它算法融合,使模型有更好的表现。
猜你喜欢
化工管理(2022年13期)2022-12-02
经济技术协作信息(2018年4期)2019-01-23
辽宁经济(2017年6期)2017-07-12
当代经济(2016年26期)2016-06-15
项目管理技术(2016年9期)2016-05-17
管理现代化(2016年2期)2016-01-23
管理现代化(2016年2期)2016-01-23
新疆财经大学学报(2015年3期)2015-12-10
系统工程学报(2015年5期)2015-02-28
系统工程学报(2015年2期)2015-02-28
