
智能制造及其关键技术∗
2019-12-04 06:11孙文磊张学东熊宗慧刘怡君
新疆大学学报(自然科学版)(中英文) 2019年4期
孙文磊,张学东,熊宗慧,刘怡君
(新疆大学机械工程学院,新疆 乌鲁木齐 830047)
0 引言
智能制造定义为高度集成的、协同制造的系统.它能对不同工况下的各种问题实时响应,以满足不同工厂、不同客户的多样性需求.智能制造是基于新一代信息通信技术与先进制造技术深度融合,贯穿于设计、生产、管理、服务等制造活动的各个环节,具有自感知、自学习、自决策、自执行、自适应等功能的新型生产方式[1−4].当前智能制造领域的热点是制造业的数字化、网络化、智能化的研究和应用,主要集中在信息感知、智能控制、智能决策、工业大数据分析等核心关键环节[5,6],工业物联网技术、工业大数据技术、数字孪生模型技术等成为主要的研究和应用内容.周光辉和张红洲[7]采用RFID技术解决了物料配送小车路径优化和实时导航的难题,周光辉和王杰等人[8]提出了RFID技术在车间刀具自动识别中的应用方案,对车间刀具进行精准地追踪和控制;王伟驎和张嘉宝[9]构建了车间的RFID模具管理系统,有效提高车间模具管理水平;李志明和李扬[10]利用RS485和CAN总线设计了一种基于分层组网的车间漆包机实时监控系统;吴瑾等[11]提出了基于ZigBee的车间设备组网策略,并设计了车间设备组网的软硬件方案;陆百川等[12]建立了基于数据驱动的故障诊断模型并应用于实际工程,取得良好效果;汪俊亮等[13]基于大量历史数据对圆晶制造交货期进行预测;杨俊刚等[14]建立了半导体制造大数据分析平台,对半导体制造过程进行预测和控制.智能制造基础日益增强,智能制造关键技术逐渐完善,智能制造为大势所趋,是确保新的经济增长的关键,是世界制造业未来发展的重要方向之一.
1 工业物联网技术
1.1 智能感知技术
信息感知是信息物理系统(CPS)的构成基础,通过智能设备采集物理对象实时动态的信息,为数据的存储、分析乃至决策提供数据来源.目前工业领域主要包括条形码、二维码、RFID 等标志识别技术和各类传感器技术.其中RFID技术是一种无线射频识别技术,具有高效、快速、可靠、非视距读取、多目标识别和可工作于恶劣环境等优点,因此被广泛应用在各场景[15−17].一般RFID系统由阅读器、电子标签以及后台服务器组成,利用电感藕合或电磁反响散射耦合原理来实现电子标签和读写器之间的通信.RFID系统工作原理如图1.
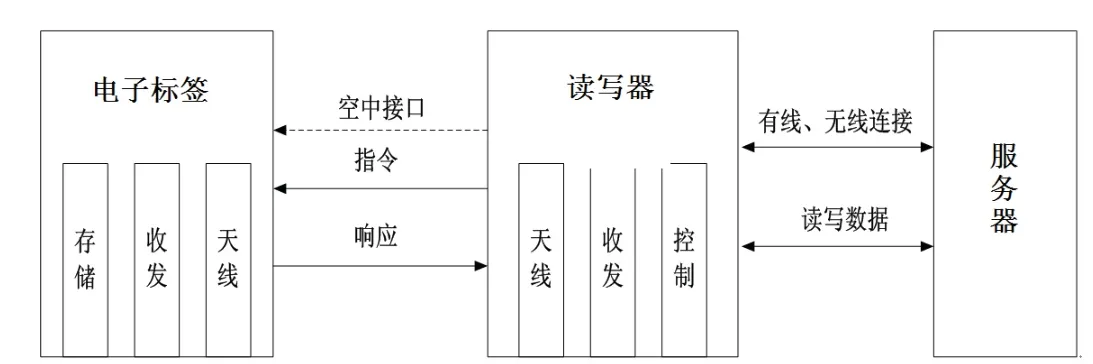
图1 RFID系统工作原理Fig 1 Working principle of RFID system
标识与识别的前提和基础是资源的编码和寻址标准的制定.只有实现了寻址规则和资源编码的标准化、通用化,才能够保证带编码物体被高效、安全地识别和解读.现国际上主要采用EPC进行编码,它为物理对象提供了全球独一无二的编码,为编码方案、通信协议等做了标准化,方便任何被编码物体接入网络.EPC编码结构及字段长度如表1.

表1 EPC编码结构及字段长度Tab 1 EPC Coding Structure and Field Length
在EPC标准的基础上,RFID、二维码等标志识别技术为工业生产中的物理对象提供了标准和自动化的标志和识别,可以实现车间、工厂的数字化监控和管理.无线射频识别技术(RFID)具有高效、快速、可靠、非视距读取、多目标识别和可工作于恶劣环境等优点.将RFID技术应用于车间,对车间刀具、物料、在制品、操作人员等的精确标识和识别,能够非常有效地提高车间信息化管理水平和生产效率.尤其是对物料实时统计、对零部件随产线流动的追踪以及对操作人员的实时定位和管理,能够有效地改善传统车间手动统计、管理混乱、丢件缺件等缺陷,提高车间透明程度和信息化水平.基于RFID的智能车间体系结构如图2.
利用RFID定位技术,结合相关定位理论,从智能车间的感知定位出发,将车间生产的全面感知和精细化管理融入人-机-料-法-环五大质量管理理论要素,对车间生产过程中的物料、在制品和操作人员进行实时的感知和定位,提供给管理者和操作人员及时高效的信息捕捉传递和动态交互,以达到提升质量和效率的目的.根据RFID定位原理,可分为场景感知和三角测量两种形式,由于车间环境复杂,定位难度大,因此必须选择合适的方案才能达到预期效果.综合考虑实际车间环境、具体布置成本以及目标定位精度,一般采用基于到达时间差(TDOA)的定位方式和基于参考标签的定位方式,或者这两种方式的混合应用[18,19].RFID定位系统标签之间的碰撞问题、阅读器之间的碰撞问题是核心痛点,因此,研究RFID系统的防冲突技术和算法具有重要意义,基于空分多址、码分多址、频分多址、时分多址算法可解决此类问题,实际应用中多采用ALOHA算法和二进制搜索算法来解决碰撞问题.
各类传感器更大程度地丰富了底层的信息感知和数据采集.根据传感器的原理不同,主要分为物理传感器和化学传感器.将各类智能传感器应用于工业生产,比如压力、速度、加速度、温度、电压电流、视觉传感器等,对车间的各类对象(设备、环境等)的各类物理、化学等信号不断采集和汇总,实时传入后台进行存储和分析,即时监控设备运行状态,并结合目前先进的人工智能技术进行故障预判等.由大量的传感器和网关组成了多跳自组织的无线传感网络,传感网负责对传感器采集数据的汇聚和发送.无线传感网的工作原理如图3.

图2 基于RFID的智能车间体系结构Fig 2 Intelligent workshop architecture based on RFID
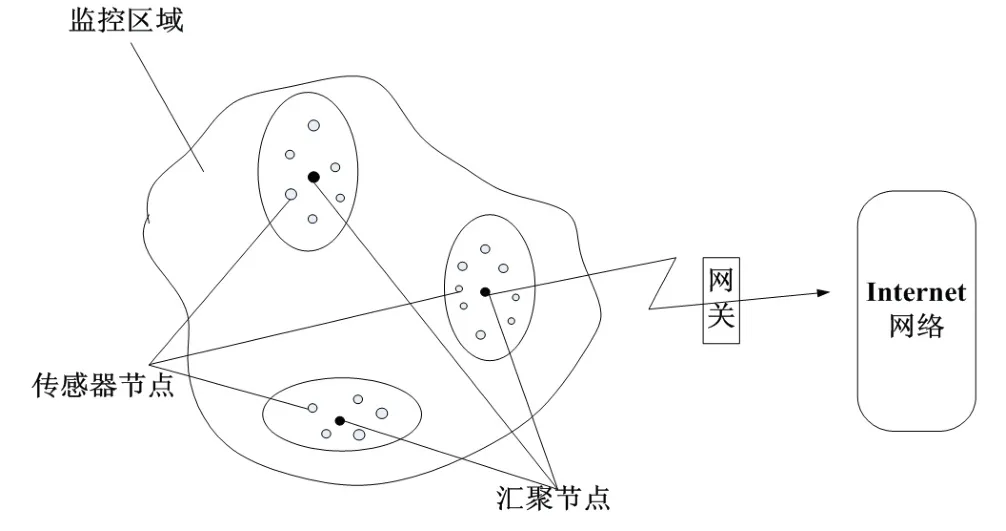
图3 无线传感网络结构Fig 3 Wireless Sensor Network Architecture
1.2 汇聚传输技术
汇聚传输技术主要目的是解决网络布置和数据传输高度可靠的问题.实际生产环境错综复杂,有线传输网络布线困难,不易实现和维护,无线传输网络布置灵活、成本较低,但是存在信号遮挡的问题.简单易行、可靠性高的组网方式是解决数据高效传输的关键,因此,要根据实际情况灵活选择组网方案.为应对集中时段的大规模资源请求、公共模块的同步、标准文档管理、服务器并行处理等问题,组网工作需要解决大规模并行下载、多服务器数据同步、数据的分布与集中、多线程编程等核心技术问题.在工业生产环境中,如何高效地汇聚多个RFID阅读器、各类大量传感器采集的数据是保证工业环境下通信质量的关键.实际生产环境错综复杂,有线传输网络布线困难,不易实现和维护.因此,在保证传输质量的前提下,应该尽量考虑使用无线传输的方式.
目前,主要的局域通信技术有ZigBee、蓝牙、UWB等.ZigBee和蓝牙技术具有低功耗、低速率的特点,因此适合应用于对数据传输要求相对较低的情况,而UWB技术对信号的衰减不敏感、传输速率非常高,具有抗多径能力强、保密性好、容量大、成本低等特点,解决了工业环境下高速、安全的无线接入.基于UWB的无线传输网络结构如图4.

图4 UWB无线传输方案Fig 4 Wireless transmission scheme of UWB

图5 数据融合的结构Fig 5 Structure of data fusion
1.3 异构数据的融合技术
数据融合技术是一种对数据进行整合和处理的技术.一般包括基于统计方法的融合和基于信息论的融合,贝叶斯法、模板法、聚类分析法、自适应神经网络融合法等都有一定的应用.其中,基于神经网络理论的数据融合方法性能优异,处理质量较高.在实际的工业生产中,信息来源多种多样、数据体量庞大、数据结构千差万别,使得对数据的关联、维护、使用都非常困难.因此,海量异构数据的传输与融合是对信息资源整合的关键.对来自众多不同种类传感器、阅读器等的数据进行拼接、相关性分析、重新组织数据结构,用于对目标进行精确分析,做出正确判断.一般将数据融合分为三个层次:数据级融合、特征级融合、决策级融合.数据融合结构如图5.
数据级别融合:数据级别融合又称像素级融合,是最底层的数据融合.对各个传感器采集的原始信息进行综合分析.数据级融合处理的信息量大、消耗时间长,但保持了较多的原始信息.
特征级别融合:处于数据融合和决策级融合的中间层,是对传感器获得数据的特征提取、对特征向量的分类、聚合等操作.
决策级别融合:是最高层次的融合,包括趋势估计、故障预判等,旨在为控制和决策提供参考依据.
2 工业大数据技术
工业大数据是指在工业领域的信息化应用产生的和各类传感器采集的海量数据,是为决策问题服务的大数据集、大数据技术和大数据应用的总称,它的价值主要体现在对异常状况的诊断和预测上[20].它提供了海量生产数据的分布式存储和计算.以设备故障预警为例,系统运行过程中,准确实时地采集、传输、存储设备的运行状况数据,并进行归一化处理后输入设备预警模型,从而判断设备的健康状况.诊断模式包括神经网络、逻辑回归、感知机、决策树、支持向量机等机器学习和深度学习模型.设备的运行状况判别准确率有了大幅提升.现主要分析工业大数据技术中的分布式存储和分布式计算.
2.1 工业大数据存储与并行化计算
Hadoop是分布式系统的基础架构,主要包括HD FS(分布式文件系统)和Mapreduce.HDFS可以在多台廉价机器组成的集群上构成可容错的大数据分布式存储系统,它将大文件按实际要求分割为多个数据块,分发到集群各节点,从而实现高吞吐量的数据存储和访问.HBase和Hive也是基于Hadoop之上的两个重要组件.HBase是一个分布式的、列式的非关系型数据库,非常适合实时的、随机的大数据存储和访问.Hive是一个数据仓库工具,可以通过HQL语句完成ETL(数据提取、转化、加载)操作,由于其实时性差,适合做离线分析.HDFS原理架构如图6.
Mapreduce是大数据批处理计算的编程模型,其思想是将批处理任务分为两个阶段: Map阶段和Reduce阶段,Map阶段负责把数据生成键值对,并提供了多种排序方式进行排序,Reduce阶段做聚合结算后把结果输出到HDFS上.MapReduce工作流程如图7.
Spark是一个基于内存的并行大数据框架,其计算效率高、速度快、容错性好.Spark平台建立在RDD之上(弹性分布式数据集),提供了很多算子,可以方便地进行多种Transformation 操作和Action 操作.Spark Streaming 是建立在Spark 之上的流式计算框架,在实时大数据分析场景中优势显著.Spark SQL 是处理结构化数据的内嵌模块,在Spark 程序中可以方便地使用SQL语句和Data-Frame API操作多种数据源.Spark体系的框架如图8.

图6 分布式文件系统HDFS的原理架构Fig 6 Principle architecture of distributed File System

图7 MapReduce的工作流程Fig 7 Workflow of MapReduce
由于Spark是基于内存的框架,因此在数据计算方面性能远远优于Hadoop的Mapreduce框架,因此,在实际应用中应扬长避短,一般多用Hadoop的分布式文件系统做数据存储,Spark做实时地数据处理和分析.

图8 Spark框架Fig 8 Framework of Spark
基于上述对大数据生态圈相关核心组件的分析,结合机器学习、深度学习、Web技术以及传感器技术,提出了完整的大数据驱动的工业大数据总体架构,如图9所示.
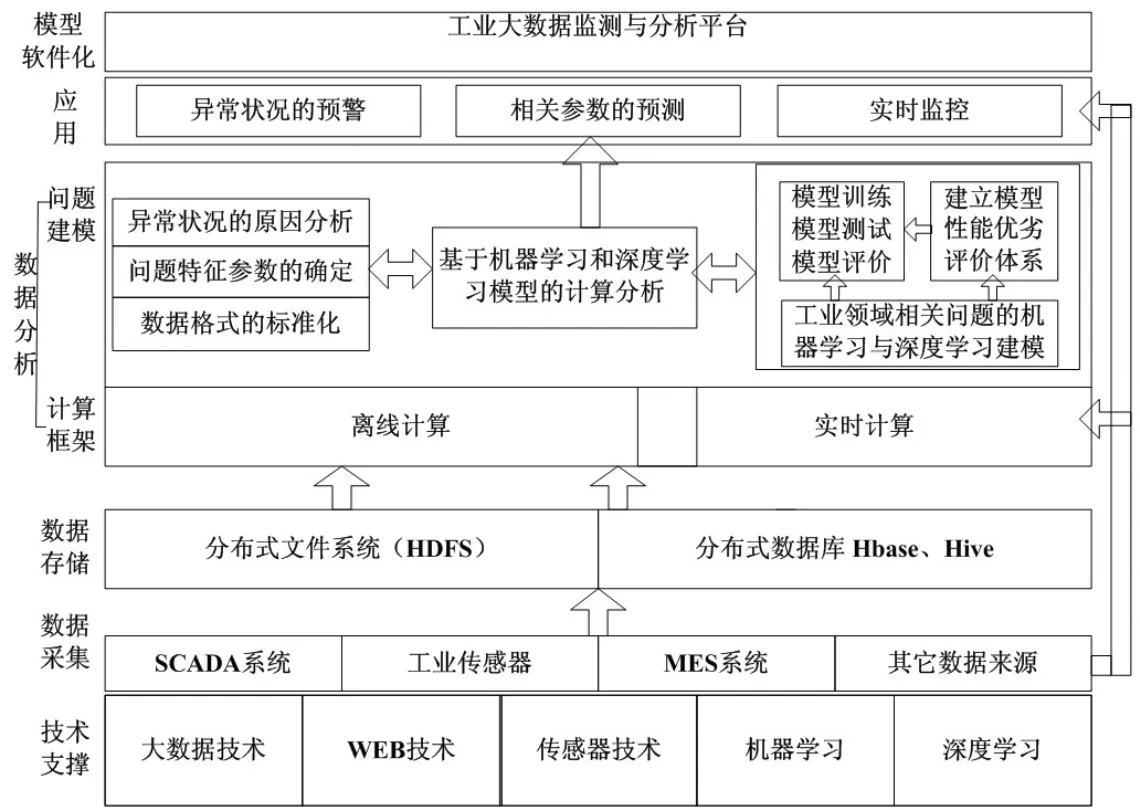
图9 工业大数据总体架构Fig 9 Overall architecture of industrial big data
架构详情阐述如下:
技术支撑是构建工业大数据的骨架,包含软件层面、硬件层面和算法层面.软件层面包括WEB技术、大数据生态组件及数据采集传输中间件;硬件层面包括传感器、大数据集群、Web服务器;算法层面包括机器学习、深入学习及其他数值分析理论.其中,硬件布置搭接是基础,软件开发优化是灵魂,算法建模是智能预警的核心.三者有机结合,协调完成高效复杂的计算工作.
数据采集是数据分析的前提,数据来源主要包括工业现场的数据采集与监控(SCADA)系统,制造执行系统(MES),传感器实时采集系统,以及其它各种形式的数据来源等.
数据存储是数据分析的基础,为数据提供了持久化操作.数据存储主要采用以下三种形式:1)分布式文件系统(HDFS),将数据按指定时间或大小存入指定文件夹下;2)分布式数据库,通常采用HBase列式数据库和Hive数据仓库,HBase可以提供高效地实时存取,而Hive存取延时高、效率低,通常做离线分析;3)关系型数据库,主要指Redis和MySQL.Redis是基于内存的缓存型数据库,在实时计算框架中,通常采用Redis缓存分析结果,然后持久化存储到MySQL数据库中.大数据可视化的数据来源就是保存在Redis和MySQL数据库中的最终分析结果.
数据计算与分析是整个项目架构的核心,该模块主要分为计算框架和问题建模两个层面.计算框架是指针对具体计算任务所采用的大数据软件框架,主要包含离线分析和实时计算两种方式.而问题建模作为数据分析的关键环节,过程相对复杂.涉及到建模前期的问题分析、数据清洗、特征提取、数据标准化和建模实时的算法选择、模型训练、模型测试以及建模后的模型评价体系的建立、模型的验证和评估等.其中,异常原因分析是针对异常问题,根据实际情况详细剖析各种异常问题的形成原因及其特点;特征提取是工业现场采集的许多数据并不能直接用来计算和表征解决问题所需要的信息,因此必须根据问题和数据的特点先进行特征的提取,然后再利用特征向量作为输入去计算;数据标准化是学习模型对输入的数据具有严格的要求,为了保证计算顺利进行,必须对输入数据的格式进行严格规定;算法建模是分析此类问题的特点,选择合适的深度学习算法训练模型、测试集测试模型;性能评价体系是建立适合问题特点的模型评价体系,对模型好坏性能进行评价.
应用层是利用建立的计算模型进行异常状况的预警、参数的预测、实时监控,为工业生产活动提供丰富的服务.
模型软件化是将智能模型程序化、系统化,作为工业生产的智慧大脑,实现真正的知识→模型化→软件化.为工业生产提供可靠、高效的监控后台.
2.2 工业问题大数据建模
人工智能技术和大数据技术的发展为工业大数据的智能分析和工业生产的智能决策带来了新的发展思路.基于解析模型和知识经验的传统建模方法推理过程比较困难,模型结构不宜随着外在条件的变化而改变,建模成本高、效果难以保证.随着大数据技术的发展,基于机器学习和深度学习的建模算法日益丰富和实用.不需要分析和理解数据与结果之间的具体内在关系,只要建立了适合该问题的学习模型,利用大量历史数据进行训练,就可以得到准确率较高的预测或决策模型.
机器学习和深度学习包括分类、回归、聚类、关联规则、推荐、神经网络及深度神经网络等算法,常用的有支持向量机、朴素贝叶斯、BP神经网络、卷积神经网络等性能优良的算法.工业问题的机器学习系统建模方法如图10.
分析问题与模型选择:针对特定的问题,分析其特点,选择合适的机器学习算法.
特征选择:特征即用来对问题预测、分类等操作的表征参数,根据实际问题和算法模型合理选择输入的特征参数,实现有效信息的最大化,对模型性能的好坏有着至关重要的作用.
模型建立:将数据分为训练集和测试集.训练集作为输入来获得计算模型,测试集用来测试计算模型的性能.
模型评估:基于准确率、失误率、拟合度、ROC、AUC和Kappa系数等的模型性能评价,评估模型的准确度和泛化能力,对模型的重构和优化进行指导,提高泛化性能.
重构与优化:随着时间的推移和实际应用环境的变化,模型的性能可能会大幅减弱,及时评估、及时对模型进行重构和优化,提高应用性能.
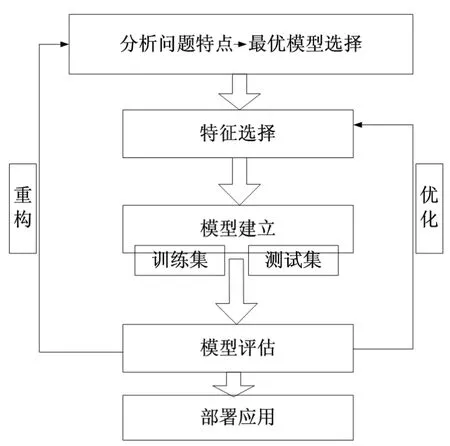
图10 工业问题学习系统的建模方法Fig 10 Modeling method of industrial problem learning system
3 数字孪生模型
在工业生产领域,实体的成本远远高于虚拟数字编码的成本.因此,可以利用数字代码信息代替实体完成工业各环节的生产活动,用预先模拟和仿真来分析系统的性能.基于数字化模拟来改进和预测生产活动的布局方式和工艺方案,从而达到降本增效的目的,数字孪生模型的概念应运而生.数字孪生模型是物理事件或系统的动态软件模型,它依赖传感器数据理解其状态,对变化做出相应改进操作,从而增加价值.“工四100术语”把数字孪生模型定义为:数字孪生模型是充分利用物理模型、传感器更新、运行历史等数据,集成多学科、多物理量、多尺度、多概率的仿真过程,在虚拟空间中完成映射,从而反映相对应的实体装备的全生命周期过程.数字孪生包括一个由元数据(如分类、组成、结构)、条件或状态(如位置、温度)、事件数据(如时间序列)和分析(如算法和规则)形成的组合[21−23],它是对真实物理世界的动态映射,实现了虚拟数字模型与现实物理空间的交互和融合.
通过数字孪生模型,可以实时掌握物理系统的整体状态,捕捉系统内局部细节,更利于构建和理解物理对象系统,从而提出优化建议.将物理对象的空间、时间进行叠加,突破物理对象的数量和空间限制,实现多对象协同.数字孪生模型可以应用在制造业各环节,进行实景建模、Web可视化等.比如在研发阶段,通过数字孪生来降低研发成本,缩短研发周期,优化产品设计;在车间制造阶段,通过数字孪生构建车间孪生模型,将整个车间的生产状态映射于数字孪生模型,实现实时、透明的车间监控和管理;在运营阶段,通过数字孪生来改善运营,并实现全部价值链的闭环反馈和持续改进.数字孪生模型结构如图11.

图11 数字孪生模型结构Fig 11 Structure of digital twin model
4 结论
智能制造是全球制造业未来的发展趋势,是经济发展的新型驱动力.为了更加详细准确地总结智能制造及其关键技术,本文分析了智能制造领域主要研究方向和热点问题;介绍了智能制造关键技术的研究和应用现状;研究了智能感知、可靠组网、海量异构数据的传输与融合、数字孪生模型以及工业大数据等智能制造关键技术,提出了适用于特定工业生产环境下的技术应用架构和部署方案.对智能制造领域的研究和发展有一定借鉴意义.
猜你喜欢
纺织科学研究(2021年1期)2021-12-03
智能制造(2021年4期)2021-11-04
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
电子制作(2019年22期)2020-01-14
传媒评论(2019年5期)2019-08-30
时代英语·高一(2019年1期)2019-03-13
小学生学习指导(中年级)(2018年11期)2018-11-29
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
农村农业农民·B版(2018年11期)2018-01-28
