
Keyphrase Generation Based on Self-Attention Mechanism
2019-11-26 06:46KehuaYangYaodongWangWeiZhangJiqingYaoandYuquanLe
Computers Materials&Continua 2019年11期
Kehua Yang Yaodong WangWei ZhangJiqing Yao and Yuquan Le
Abstract:Keyphrase greatly provides summarized and valuable information.This information can help us not only understand text semantics,but also organize and retrieve text content effectively.The task of automatically generating it has received considerable attention in recent decades.From the previous studies,we can see many workable solutions for obtaining keyphrases.One method is to divide the content to be summarized into multiple blocks of text,then we rank and select the most important content.The disadvantage of this method is that it cannot identify keyphrase that does not include in the text,let alone get the real semantic meaning hidden in the text.Another approach uses recurrent neural networks to generate keyphrases from the semantic aspects of the text,but the inherently sequential nature precludes parallelization within training examples,and distances have limitations on context dependencies.Previous works have demonstrated the benefits of the self-attention mechanism,which can learn global text dependency features and can be parallelized.Inspired by the above observation,we propose a keyphrase generation model,which is based entirely on the self-attention mechanism.It is an encoder-decoder model that can make up the above disadvantage effectively.In addition,we also consider the semantic similarity between keyphrases,and add semantic similarity processing module into the model.This proposed model,which is demonstrated by empirical analysis on five datasets,can achieve competitive performance compared to baseline methods.
Keywords:Keyphrase generation,self-attention mechanism,encoder-decoder framework.
1 Introduction
With the explosive growth of text information in recent years,people can access a large amount of text information every day,such as news,web pages,chat records,papers and so on.Extracting important content from a large amount of text has become an urgent need.Automatically extracting keyphrase provides an efficient solution.Keyphrase can provide users with highly condensed and valuable information that summarizes the major semantic meaning of longer texts.According to keyphrases,users can easily and accurately grasp the main content of the text,which not only saves time,but also improves the efficiency of reading.Keyphrase extraction has been used in lots of fields,such as,text categorization [Hulth and Megyesi (2006)],text summarization [Zhang,Zincir-Heywood and Milios (2004)],information retrieval [Jones and Staveley (1999)],opinion mining [Berend (2011)],and retrieving encrypted data in cloud server [Tang,Lian,Zhao et al.(2018)].Here,we think that both “keyword” and “keyphrase” mean the same thing,and there is no difference between them.In addition,we have to pay attention that “keyphrase” and “keyword” can be made of multiple words.There are enormous usefulness of keyphrases,therefore,lots of studies have been done on the generation or automatic extraction of keyphrases,including supervised classification-based methods [Wang,Peng and Hu (2006)],ranking-based methods [Jiang,Hu and Li (2009)],clustering-based methods [Danilevsky,Wang,Desai et al.(2014)] and recurrent neural networks-based encoder-decoder methods [Meng,Zhao,Han et al.(2017);Zhang and Xiao (2018)].The first three methods do not extract Keywords from the semantic layer,which are extraction methods.They can only obtain keyphrases appearing in the source text,but they cannot obtain absent keyphrases [Meng,Zhao,Han et al.(2017)].The last method uses recurrent neural networks as its encoder and decoder,which can generate present and absent keyphrases from text semantics and is a generation method.However,recurrent neural networks rely on the state of current and previous time steps.This essentially sequential nature excludes parallelism,and it takes a number of time steps to accumulate dependency features information between long-distance words,and the longer distance,the less possibility it is to capture dependency features information effectively.In order to overcome these shortcomings,we propose an encoder-decoder model that abandons the recurrent neural network and entirely relies on attention mechanism.The model creates global dependencies between input and output and can generate present and absent keyphrases.It solves the problem of weakening dependence caused by the long distance between words,has the property of parallelization,and considers the semantic correlation between keyphrases.To summarize,the main contributions of our research are as below:
1)A keyphrase generation model is proposed,which is entirely based on self-attention mechanism.As far as we know,this is the first time that self-attention mechanism applies to a keyphrase generation task.
2)We consider the semantic similarity between keyphrases and add semantic similarity processing module into the model.
3)We compare six important supervised and unsupervised models,and the results show that our model performs better.
In the rest part of the article,firstly,the related work will be shown in Section 2.Afterwards,we introduce our model in detail in Section 3.Then,we experimentally demonstrate the performance of our model in Section 4.At last,in Section 5,conclusions and future work will be given.
2 Related work
Due to the important role of keyphrases,there are many methods to extract Keywords,and they usually have two steps for extracting keyphrases.The first step is to extract keyword candidates from the source text and form a list.The longer length of the list,the greater the probability of getting the correct keyphrases.The methods for extracting candidates mainly include sequence matching [Le,Le Nguyen and Shimazu (2016)] and extract important n-gram phrases [Medelyan,Witten and Milne (2008)].The second step is to sort keyword candidates according to the significance of the source text.The final result is the top keyphrases in the list of candidates.There are two main methods to rank the list of candidates:unsupervised and supervised.The former methods include finding the central nodes of text graph [Grineva,Grinev and Lizorkin (2009)],topical clusters[Liu,Huang,Zheng et al.(2010)] and so on.The latter takes it as a binary classification problem based on positive fractional ranking [Gollapalli and Caragea (2014)].However,in scientific publications,instead of following the written content,authors usually assign keyphrases based on their semantics.Therefore,the above methods only judge the importance of the candidate keyphrases to the text according to the number of occurrences,and cannot reveal the complete semantics of the document content.
In addition to the above extraction methods,some scholars use a completely different way to generate keyphrases.Liu et al.[Liu,Chen,Zheng et al.(2011)] adopted a word alignment model,which translates the documents to the keyphrases.To a certain degree,this model reduces the vocabulary gaps between source and target.Zhang et al.[Zhang,Wang,Gong et al.(2016)] built a sequence labeling model,which extracted Keywords by recurrent neural network from tweets.However,this model cannot fully understand the semantics behind the source text.Meng et al.[Meng,Zhao,Han et al.(2017)] proposed an encoder-decoder model,which combines attention mechanism and copy mechanism to generate keyphrases.However,this approach does not consider the semantic similarity between keyphrases,and when the sequence length is too long,it is difficult to capture the dependency features between words.The longer the distance,the less the possibility of effective capture.On the basis of Meng et al.[Meng,Zhao,Han et al.(2017)],Zhang et al.[Zhang and Xiao (2018)] used the coverage mechanism to solve the semantic similarity between keyphrases.However,the problem of weak dependence between long distance words and the inability to parallelize training still exist.
To overcome the shortcomings above,a keyphrase generation model is proposed,which is entirely based on self-attention mechanism.It abandons the recurrent neural network and takes into account the semantic similarity between keyphrases.
3 Methodology
Our keyword generation model includes an encoder,a decoder and a semantic similarity processing module.The encoder and decoder are shown in the upper and lower halves of Fig.1,respectively.Given a source text,the encoder is used to learn the global dependency information between the words,the decoder combines the dependency information to generate the corresponding keyphrase,and the semantic similarity module handles the semantic similarity between the keyphrases.

Figure1:Our model architecture
3.1 Problem definition
For the keyphrase generation model,the task is to generate multiple keyphrases to summarize the source text by machine automatically.We suppose that dataset consists of N different samples,and therepresents thei-th sample,which is composed of a source textandtarget keyphrases.We describe these target keyphrases asAlso both source textand keyphraseare regarded as word sequences as below:

We should pay attention that the keyphrase sequences only contain a few words and are relatively short.
As mentioned above,each sample contains a source textand multiple keyphrases.
We use an encoder and a decoder to generalize the hidden rules and learn the mapping relationship between the target keyphrases and source text.The source text sequenceis used as input,and the dependencies between each word are learned by the multiattention mechanism in the encoder to obtain the global structure information of the source text.The previous one keyphrasethat has been obtained is used as an additional input to the decoder,and then the decoder outputs the next keyphraseaccording to the global dependency information learnt by the encoder.
3.2 Encoder
Our encoder is basically the same as Vaswani et al.[Vaswani,Shazeer,Parmar et al.(2017)].First,the input source text is transformed into vector matrix through input embedding.Because our keyphrase generation model consists of no convolution and no recurrence,in order to making use of the sequence order,we must inject some information about the absolute position or the relative of the words into the sequence.The same as Vaswani et al.[Vaswani,Shazeer,Parmar et al.(2017)],the “positional encoding” is added to the input embedding at the bottom of the encoder.Then,the results of their summation are input into the multi-layer multi-head attention mechanism and feed-forward network which is fully connected,and a sequence of consecutive representations is finally obtained.In order to preserve the original input information as much as possible,a residual connection [He,Zhang,Ren et al.(2016)] is adopted by every multi-head attention mechanism and feed-forward network,and then perform layer standardization [Ba,Kiros and Hinton (2016)].
3.2.1 Positional encoding
The self-attention mechanism is unable to distinguish different locations.To take advantage of the position information of the sequence,it is very significant to encode the position of every input word.There are many ways to encode the position.The simplest way is to use additional position embedding.In this work,we try the positional encoding approach proposed by Vaswani et al.[Vaswani,Shazeer,Parmar et al.(2017)],which is formulated as follows:

whereposis the position andiis the dimension.The positional encoding is simply added to the input embedding.Unlike the positional embedding approach,this approach does not introduce additional parameters.
After input embedding and positional encoding,our input source text is transformed into a matrixwhereis the length of the input text,andis the dimension of the embedding.
3.2.2 Multi-head attention
The attention mechanism has been widely applied to various tasks of natural language processing based on deep learning.We think a mapping of a query to a series of key,valuedata pairs can best describe the nature of the attention mechanism.Given a certain elementQueryin the target,we calculate the similarity or correlation between it and theKeyof each data pair in theSourceto obtain the weight coefficient of the correspondingValue,and then weight and sum theValueaccording to the weight coefficient respectively,and the result of the summation is the attention value.

wherelxrepresents the length of theSource,where the similarity or correlation ofQueryandKeycan be calculated by dot-product.
In this article,Q,KandVall represent the matrix of theafter input embedding and positional encoding.In order to better learn the global dependency information within the text,we use the multi-head attention proposed by Vaswani et al.[Vaswani,Shazeer,Parmar et al.(2017)].It proved to be useful to project theQ,KandVmatrices linearlyhtimes with different,which respectively learned different linear projection toandmatrices.We perform the attention function parallel on each of these matrices ofQ,KandV,resultingoutput matrix.Then we connect the matrices and project them once again,yielding the final results,as presented in Fig.2.
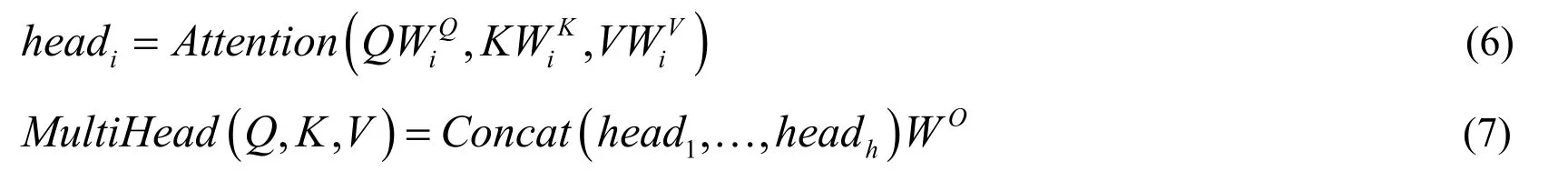
where the projections are parameter matricesand

Figure2:Multi-head attention
After projectingQ,KandVto subspaces of lower dimension,and then performing attention calculations in different subspaces,the subspace’s dimension is lower without increasing the computational amount,which is conducive to parallelizing and capturing features of different subspaces.
IfQandKafter linear projection are directly subjected to dot product operations,and the operation result is used as a weighting coefficient,there may be a problem that the dot product is too large and the gradient is too small.We try the method of Vaswani et al.
[Vaswani,Shazeer,Parmar et al.(2017)],scaling the dot product bywhich is expressed as follows:

The self-attention mechanism can be expressed asX=Q=K=V,which means that attention mechanism works inside the sequence to find internal interdependencies.The self-attention mechanism solves the problem of weak dependence caused by the text being too long.So our multi-head attention can be simply described as:

whereYis the final value after connection and projection,.
3.2.3 Feed forward
In order to fit the training data better,we add a fully connected feed forward neural network layer to the encoder.It contains two linear layers and an intermediate nonlinear ReLU hidden layer.Formally,we have the following equation:

3.3 Decoder
Since the model of Vaswani et al.[Vaswani,Shazeer,Parmar et al.(2017)] is used to solve translation problem,they use the “Masked Multi-Head Attention” sublayer in the decoder to prevent future output words from being used during training,ensuring that the prediction of positionidepends only on all known outputs less thani.However,our decoder part is different from them.Because the keyphrases we generated are short and independent,and there is no interdependence between them,our decoder only uses the keyphrase from the last time output,and then embedding it as theQinput of multi-head attention.
When we make predictions,we enter the source textxiconsisting of an Abstract and a title at the encoder.After a series of processing by the encoder,we get a matrixZ,Z∈Rdn×dmodelwhich is used as theKandVinput of the multi-head attention in the decoder,ieZ=K=V.In the decoder,the keyphrasek(i,j)outputted by the previous layer is processed by embedding to obtain a matrix which is used as another inputQof the multi-head attention layer in the decoder,Q∈Rdm×dmodel,dmis the length of the keyphrasek(i,j).QcombinesK,Vto perform the multi-head attention and feedforward neural network.Similar to the encoder,each sub-layer uses a residual connection[He,Zhang,Ren et al.(2016)],and then performs layer standardization [Ba,Kiros and Hinton (2016)].Using the multi-head attention and feed-forward neural network stackNxtimes to get the matrixS,S∈Rdm×dmodel,and then through the linear layer and the softmax layer,predict the next most probable keyphrasek(i,j+1).
The linear layer is a neural network,which is simple and fully connected.It projects the matrix S,which is produced by the stack of decoder,into a very much larger vector.This vector is called logits vector.We suppose that our model could learn from its training dataset and know 10,000 unique keyphrases,which turns the logits vector into 10,000 cells wide.These cells are corresponding to the score of a keyphrase respectively.Then the softmax layer makes those scores probabilities,all of which are positive and have a sum of 1.0.The next keyphrase be produced,which is associated with the cell with the highest possibility.
Since the multi-head attention and the feed-forward neural network that used in our decoder have already been introduced in the encoder,we don’t repeat them here.
3.4 Semantic similarity of keyphrases
In order to consider the semantic information between generated keyphrases,we add a semantic similarity module behind the encoder-decoder.
Firstly,we segment each keyphrase,then use Word2vec [Mikolov,Chen,Corrado et al.(2013)] to calculate the word vector of each word,and then add the word vectors in each keyphrase to get the average word vector as the current keyphrase.indicates the word vector of thei-th keyphrase.We use the method of cosine similarity to calculate the similarity between keyphrases.

4 Experiments
We introduce our experimental designs in this section.First,we describe the training dataset and the testing datasets.Then we introduce the baseline models and evaluation metrics.Finally,we give the experimental results and analysis.
4.1 Training dataset
As far,for evaluating keyphrase generation,we have a couple of publicly available datasets.The largest publicly available dataset is provided by Meng et al.[Meng,Zhao,Han et al.(2017)].We use it to train and test our model.We mark it with "KP" in the later description.The KP dataset contains plenty of high-quality computer science articles,including nearly 567,830 articles.We randomly select 40k articles to test and validate our model,and the rest of them were used as training dataset.About this 40k articles,20k articles are used as a testing dataset,we mark it with KP20k,and the remaining 20k articles are regarded as validation dataset to judge the convergence of our model during the training process.
4.2 Testing dataset
In order to comprehensively evaluate the proposed keypharse generation model,we not only use the newly constructed test dataset KP20k to test our model,but also use other four scientific article datasets.The title and Abstract of the article are used as source text.All the testing datasets and details are listed below:
1)Inspec [Hulth (2003)]:The Abstracts of 2,000 articles are provided.We randomly select 500 Abstracts as our testing dataset.
2)Krapivin [Krapivin,Autaeu and Marchese (2009)]:About 2,304 full-text papers and author-assigned keyphrases are provided.The Abstracts of 400 articles among them are used as our testing dataset.
3)NUS [Nguyen and Kan (2007)]:The dataset provides 211 full-text papers and author-assigned keyphrases.We use all of them to test our model.
4)SemEval-2010 [Kim,Medelyan,Kan et al.(2013)]:This dataset consists of 288 articles from the ACM Digital Library.We randomly select 100 papers to test our model.
5)KP20k [Meng,Zhao,Han et al.(2017)]:The dataset provides 20K scientific literatures about computer science with titles,Abstracts and keyphrases.
Since the number of Krapivin,Inspec,SemEval-2010 and NUS is too small to train our powerful model.Therefore,they only are used as testing dataset.
4.3 Baseline models
We use four supervised algorithms (Maui [Medelyan,Frank and Witten (2009)],RNN[Meng,Zhao,Han et al.(2017)],CopyRNN [Meng,Zhao,Han et al.(2017)],CovRNN[Zhang and Xiao (2018)])and two unsupervised algorithms (TextRank [Mihalcea and Tarau (2004)],TF-IDF)as baselines.Zhang et al.[Zhang and Xiao (2018)] have experimentally verified these supervised and unsupervised methods,and we take the results of their experiments as the standard.
4.4 Evaluation metric
To measure the performance of our model,evaluation metrics consist of recall,macroaveraged precision and F-measure (F1).The recall represents a comparison between the quantity of correctly-predicted Keywords and the total quantity of sample Keywords,while precision represents a comparison between the quantity of correctly-predicted Keywords and the total quantity of predicted Keywords.In fact,precision and recall are contradictory in some cases.In order to consider them comprehensively,we use the comprehensive evaluation metricF1to measure the performance of the model when predicting present keyphrases.

whereRrepresents the recall andPrepresents the precision.
4.5 Results and analysis
To evaluate our model,a study on two different tasks is conducted.We classify Keywords into two categories according to whether they appear in the source text:present keyphrase and absent keyphrase.
4.5.1 Predicting present keyphrases
To test the performance of our model on regular tasks,we compared it to six baseline models (TextRank,TF-IDF,RNN,Maui,CovRNN,CopyRNN).To be fair,we only consider models to predict the performance of present keyphrases.We use F1at top 4 and top 8 to measure the performance of each method.We highlight in bold for the best scores among the five benchmark datasets.
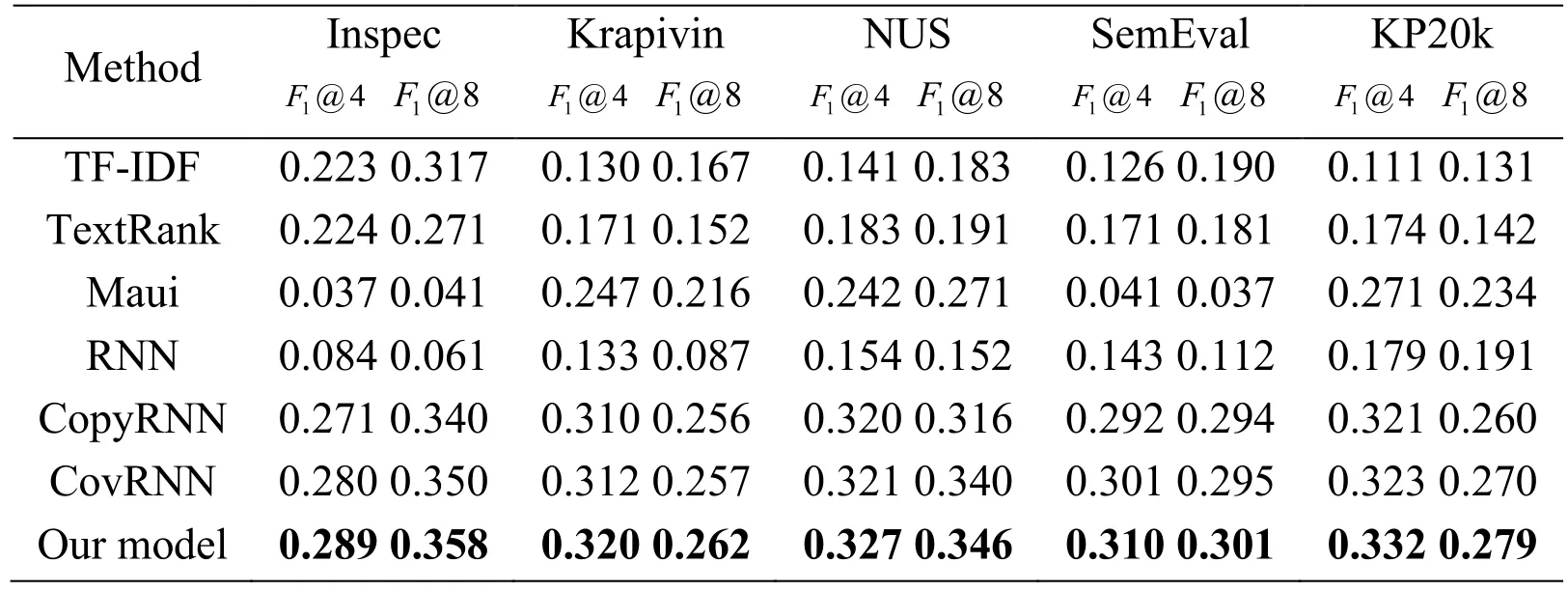
Table1:Each model predicts the performance results of the present keyphrases
The results of the experiment show that the four supervised models (Maui,RNN,CopyRNN,CovRNN)have a robust performance across different datasets.Overall,among all baseline models,CovRNN works extremely well.In KP20k dataset,itsF1@4 andF1@8values reach 0.323 and 0.270 respectively.These baseline models achieve good results from the study,but our proposed model based on self-attention mechanism performs the best.
In the predicting present keyphrases task,although our model with the self-attention mechanism performs best,it does not work well as we expected.For instance,theF1@8 value of the CovRNN reach 0.270 on KP20k dataset,our model is 0.279.It probably because that our model pays high attention to find the hidden semantic information behind the source text,which may result in generating general keyphrases that cannot be referenced from the source text.
4.5.2 Predicting absent keyphrases
It is an important concern to predict the absent keyphrases based on “comprehension” of content.It is worth mentioning that the prediction task is extreme challenging,for our knowledge,it can only be done by the seq2seq model.Therefore,only CopyRNN,CovRNN and our model experiments can be performed.
Here,in order to test the performance of each model to predict the absent keyphrases,we use the recall of top 10 and top 50 as evaluation metrics.The recall metric assists us analyze the predictive performance of each model.Tab.2 shows the performance of CopyRNN,CovRNN and our model for predicting absent keyphrase.The best prediction results are shown in bold.
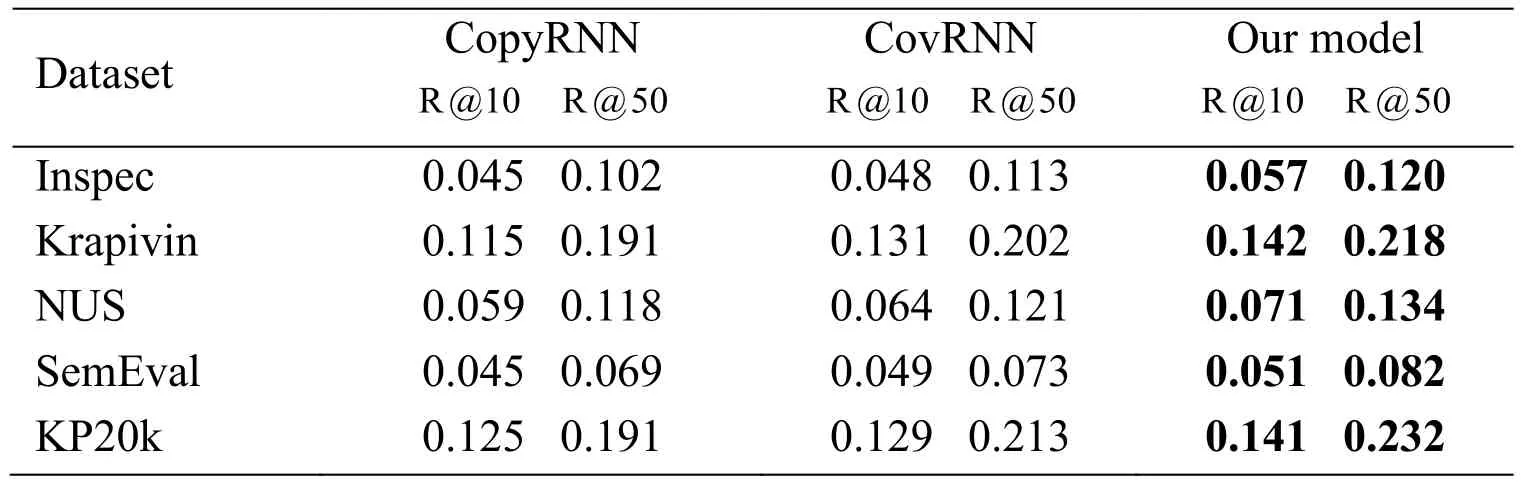
Table2:Absent keyphrases prediction performance of CopyRNN,CovRNN and our model on five datasets
In Tab.2,the recall of CopyRNN,CovRNN and our model can reach about 7.8%(13.4%),8.4% (14.4%)and 9.2% (15.7%)of accurate keyphrases at top 10 (50)predictions.In addition,our model shows better performance than CopyRNN and CovRNN.This performance shows that our model can better extract the semantic meaning hidden in the text.
Our proposed model completely relies on the self-attention mechanism to learn the global dependence information of the text,more comprehensively considers the dependencies between words,and solves the problem of weakening dependence caused by the long distance between words,has the property of parallelization.In addition,we consider the semantic relevance between keyphrases.The experimental results show the important role of the global dependence information of the text on keyphrase generation.This progress also shows that self-attention mechanism is extraordinary significant in the task of absent keyphrase prediction.
5 Conclusion and future work
In our work,we propose a keyphrase generation model based entirely on the selfattention mechanism,which is an encoder-decoder framework.In addition,we add the semantic similarity module to our model.As far as we know,this is the first time that self-attention mechanism applies to a keyphrase generation task.Our model relies entirely on the self-attention mechanism to learn the global dependence information of text,without the limitation of the distance between words,has the property of parallelization,and can generate absent keyphrases based on text semantics.The effectiveness of our proposed model is demonstrated in the comprehensive empirical studies.
In the future,we consider applying our model to different types of testing datasets to test their performance.In addition,we also consider exploring a new way to deal with semantic correlation between keyphrases.
Acknowledgement:This work is supported by National Key R&D Program of China(No.2018YFC0831800)and Innovation Base Project for Graduates (Research of Security Embedded System).
 Computers Materials&Continua2019年11期
Computers Materials&Continua2019年11期
- Computers Materials&Continua的其它文章
- Efficient Computation Offloading in Mobile Cloud Computing for Video Streaming Over 5G
- Geek Talents:Who are the Top Experts on GitHub and Stack Overflow?
- Implementing the Node Based Smoothed Finite Element Method as User Element in Abaqus for Linear and Nonlinear Elasticity
- Dynamics of the Moving Ring Load Acting in the System“Hollow Cylinder + Surrounding Medium” with Inhomogeneous Initial Stresses
- Human Behavior Classification Using Geometrical Features of Skeleton and Support Vector Machines
- Improvement of Flat Surfaces Quality of Aluminum Alloy 6061-O By A Proposed Trajectory of Ball Burnishing Tool