
An Im proved End-to-End Memory Network for QA Tasks
2019-11-25 10:23:00AziguliWulamuZhenqiSunYonghongXieCongXuandAlanYang
Computers Materials&Continua 2019年9期
Aziguli WulamuZhenqi SunYonghong Xie Cong Xuand Alan Yang
Abstract:At present,End-to-End trainable Memory Networks (MemN2N) has proven to be promising in many deep learning fields,especially on simple natural language-based reasoning question and answer (QA) tasks.However,when solving some subtasks such as basic induction,path finding or time reasoning tasks,it remains challenging because of limited ability to learn useful information between memory and query.In this paper,we propose a novel gated linear units (GLU) and local-attention based end-to-end memory networks (MemN2N-GL) motivated by the success of attention mechanism theory in the field of neural machine translation,it shows an improved possibility to develop the ability of capturing complex memory-query relations and works better on some subtasks.It is an improved end-to-end memory network for QA tasks.We demonstrate the effectiveness of the ese approaches on the 20 bAbI dataset which includes 20 challenging tasks,without the use of any domain know ledge.Our project is open source on github4.
Keywords:QA system,memory network,local attention,gated linear unit.
1 Introduction
The QA problem has been around for a long time.As early as 1950,the British mathematician A.M.Turing in his paper put forward a method to determine whether the machine can think-Turing Test,which is seen as the blueprint for the QA system [Turing(1950)].The first generation of intelligent QA system converts simple natural language questions into pre-set single or multiple keywords and queries the information in a domainspecific database to obtain answers.Its earliest appearance can be traced back to the early 1950s and 1960s when the computer was born.The representative systems include two well-known QA systems,baseball [Green Jr,Wolf,Chomsky et al.(1961)] and lunar[Woods and Kaplan (1977)].They have a database in the background that holds various data the system can provide.When the user asks a question,the system converts the user’s question into a SQL query statement,and queries the data from the database to the user.
Shrdlu was a highly successful QA program developed by Terry Winograd in the late 60s and early 70s [Winograd (1972)],it simulated the operation of a robot in a toy world (the“blocks world”).The reason for its success was to choose a specific domain and the physical rules were easily w ritten as programs.The travel information consultation system GUS developed by Bobrow et al.in 1977 is another successful QA system [Bobrow,Kaplan,Norman et al.(1977)].In the 1990s,with the development of the Internet,a second generation question and answer system emerged.It extracts answers from large-scale text or web-based libraries based on information retrieval techniques and shallow NLP techniques [Srihari and Li (2000);Voorhees (1999);Zheng (2002)].A representative example is Start (1993),which is the world’s first web-based question answering system,was developed by the M IT Artificial Intelligence Lab [Katz (1997)].In 1999,the TREC (Text REtrieval Conference)began the evaluation of the question and answer system.In October 2000,ACL(the Association for Computational Linguistics) used the open domain question and answer system as a topic,which promoted the rapid development of the question and answer system.With the rise of web 2.0 technology,the third generation question answering system has developed [Tapeh and Rahgozar (2008)].It is characterized by high quality know ledge resources and deep NLP technology.Up to now,in addition to the “Cortana” of Microsoft[Young (2019)],the “Dumi” of Baidu [Zhu,Huang,Chen et al.(2018)] and the “Siri” of Apple [Hoy (2018)],many companies and research groups have also made breakthroughs in this field [Becker and Troendle (2018);Zhou,Gao,Li et al.(2018)].
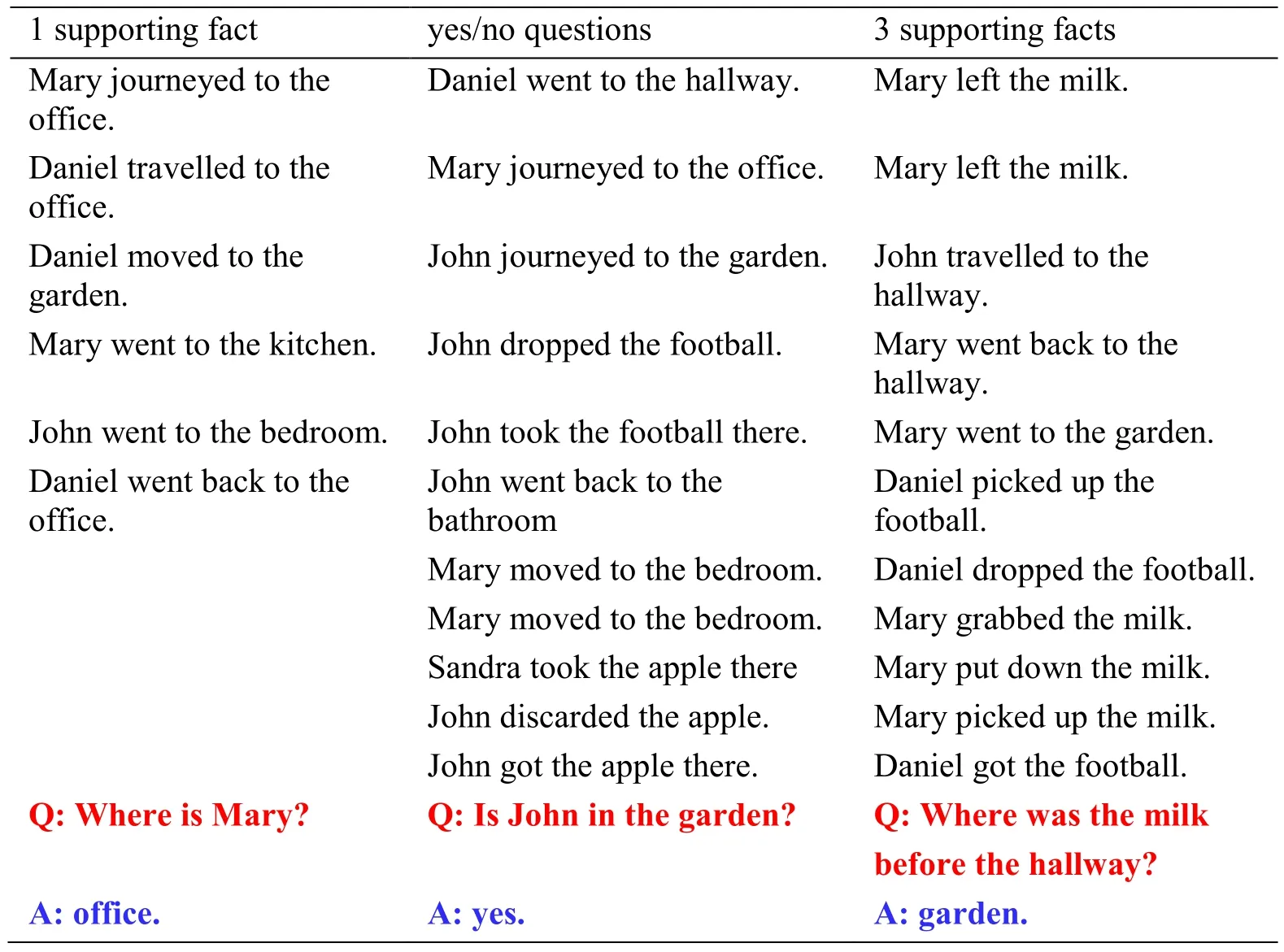
Table1:Samples of the ree typesoftasks
In such a situation,end-to-end learning framework have shown promising performance because of their applicability in the real environment and efficiency in model updating [Shi and Yu (2018);Madotto,Wu and Fung (2018);Li,Wang,Sun et al.(2018);Liu,Tur,Hakkani-Tur et al.(2018)].In end-to-end dialog systems,End-to-end memory network(MemN2N) and its variants have always been hot topics of research [Perez and Liu (2018);Ganhotra (2018)],in light of the powerful ability to describe long term dependencies [Huang,Qi,Huang et al.(2017)] and the flexibility in the implementation process.
Although MemN2N has achieved good performance on the dialog bAbI tasks,where the memory components effectively work as representation of the dialog context and play a good role in inference.There are still many tasks not very satisfactory in the bAbI [Shi and Yu (2018)].In order to find out the reasons for this,we have made a careful comparison.We found that tasks achieved good performance on the dialog bAbI tasks (such as Task 3 supporting factsin Tab.1) have in common that there are many more contextual sentences than those perform well (such as Task yes/no questions in Tab.1).And when calculating the relevance of the memory and the query,MemN2N attend to all sentences on the memory side for query [Sukhbaatar,Szlam,Weston et al.(2015)],which is expensive and can potentially render it impractical.Inspired by the field of machine translation [Minh Thang and Hieu Pham (2015)],we introduce the local-attention mechanism when calculating the correlation between memory and query.We don’t consider all the information of memory,but a subset of sentences which are more relevant to the query.At the same time,inspired by the gated convolutional network(GCN) [Dauphin,Fan,Auli et al.(2017)],we investigate the idea of the gated linear units (GLU) into MemN2N to update the intermediate state between layers.The purpose of these two improvements is the same,that is to appropriately reduce the complexity of the model,let the model pay more attention to useful information when training.
We have compared our two improved methods to MemN2N in the bAbI tasks,analyzed their number of successful tasks and error rates in different tasks.We also analyzed from the perspective of training speed and visual weight.Experimentally,we demonstrate that both of our approaches are effective.
In the following sections,we first introduce the application of MemN2N model and the innovation of our MemN2N-GL model in the second section;in the third section,we introduce the implementation methods of our model in detail,including local-attention matching and GLU mapping;then,we show our experimental results in the fourth section,and make a comparative analysis with baseline;finally,in the fifth section,we show our conclusion and planning for future work.
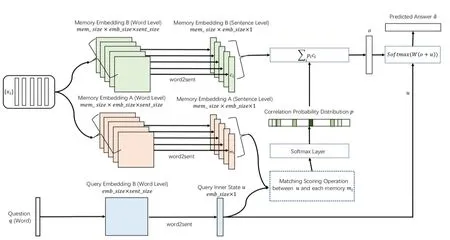
Figure1:A single layer version of MemN2N
2 Model
The MemN2N architecture,introduced by Sukhbaatar et al.[Sukhbaatar,Szlam,Weston et al.(2015)],is a hot research method in the field of current QA system [Ganhotra and Polymenakos (2018);Perez and Liu (2018)].It is a form of Memory Network (MemNN)[Weston,Chopra and Bordes (2014)],but unlike the model in that work,it is trained endto-end that makes it easier to apply in practical situations [Sukhbaatar,Szlam,Weston et al.(2015)].Compared with traditional MemNN,MemN2N gets less supervision during training,which means it will reduce some complexity and may not be able to fully capture the context information.
Because of the good characteristics of MemN2N,it has been used in a wide range of tasks in recent years.Boyuan Pan et al.introduced a novel neural network architecture called Multi-layer Embedding with Memory Network (MemNN) for machine reading task,where a memory network of full-orientation matching of the query and passage to catch more pivotal information [Pan,Li,Zhao et al.(2017)].M Ghazvininejad et al.presented a novel,fully data-driven,and know ledge-grounded neural conversation model aimed at producing more contentful responses [Ghazvininejad,Brockett,Chang et al.(2018)].In the field of computer vision,Wu et al.proposed a long-term feature bank,which extracts supportive information over the entire span of a video to augment state- of -the-art video models [Wu,Feichtenh of er,Fan et al.(2018)].Although MemN2N has been widely used in many fields and has achieved good results,it may not scale well to the case where a larger memory is required [Sukhbaatar,Szlam,Weston et al.(2015)].
In this paper,inspired by the attention mechanism and its many deformations in the field of deep learning [Shen,Zhou,Long et al.(2018);Zhang,Goodfellow,Metaxas et al.(2018);Shen,He and Zhang (2018)],we propose an improvement point to introduce local attention mechanism into MemN2N to improve the model effect.Compared to the use of global matching between u and each memory miin MemN2N (Eq.(4)),local attention mechanism pays more attention to the local information related to the question state u in the memory.We also consider to optimize the updating of hidden state u between layers of MemN2N (Fig.1).The original method uses a linear mapping H (Eq.(10)) while we draw on the experience of GLU (Gated Linear Unit) proposed by Dauphin et al.[Dauphin,Fan,Auli et al.(2017)].We compare the improved model based on these two points with MemN2N in the same data sets.As a result,our model performs better in more complex QA tasks.
3 Methods
In this section,we introduce our proposed model MemN2N-GL.Our model aims to extract more useful interactions between memory and query to improve the accuracy of MemN2N.Similar to MemN2N,our MemN2N-GL consists of the ree main components:input memory representation,out memory representation and final answer prediction.
In the part of input memory representation,an input set x1,...,xi are converted into memory vectors {mi} and {ci} of dimension d in a continuous space,using embedding matrixes A and C,both of them are d×V,where d is embedding size,V is vocabulary size.Similarly,the query q is also embedded (by matrix B) to an internal state u.We use position encoding (PE) [Sukhbaatar,Szlam,Weston et al.(2015)] to convert word vectors as sentence vectors.This takes the form:

where ljis column vector with the structure:

J is the number of words in the sentence,and d is the dimension of the embedding.In this way,the position information of the words are taken into account when generating the sentence vector.Questions,memory inputs and memory outputs also use the same representation.In order to enable memory to have context temporal information,we also modify the memory vector by:

where TA(i) is the i th row of a special matrix TAthat encodes temporal information,and TAis learned during training.
Then in the embedding space,MemN2N calculate the relevance score between u and each memory miby means of matching in dot form [Minh-Thang Luong (2015)]followed by a softmax:

where

After applying softmax function,each component of the matrix uTmiwill be in the interval(0,1),and the components will add up to 1,so that they can be interpreted as probabilities.Furthermore,the larger input components will correspond to larger probabilities.
By contrast,we develop local-attention mechanism to calculate the correlation and filtering out irrelevant information between u and {mi},compared with the attention mechanism used in MemN2N,our model does not focus on the relevance of the global memory and query,but focuses on the local memory associated with the query.
3.1 Local-attention matching
As mentioned before,local-attention matching chooses to focus only on a small subset of the memory,which is more relevant to query q (Fig.2).Concretely,the model first generates an aligned position pufor the query q in the memory embedding A:

where vp,Waare the model parameters which will be learned to predict positions.S is the memory size,δ is activation function and pu∈ [0,S].
Then the relevance score between u and each memory miis defined as:

where piis the original score (Eq.(4)),is the standard deviation and D is the window size of subset memory.Finally,we use the new relevance score pito calculate the out memory representation in Fig.2.The response o from output memory is a sum of memory vectors {ci},weighted by the input probability vector:

Finally in final answer prediction,the predicted answer distribution a^ is produced by the sum of the output vector o and the input embedding u which then passed through a final weight matrix W (of size V×d) and a softmax:
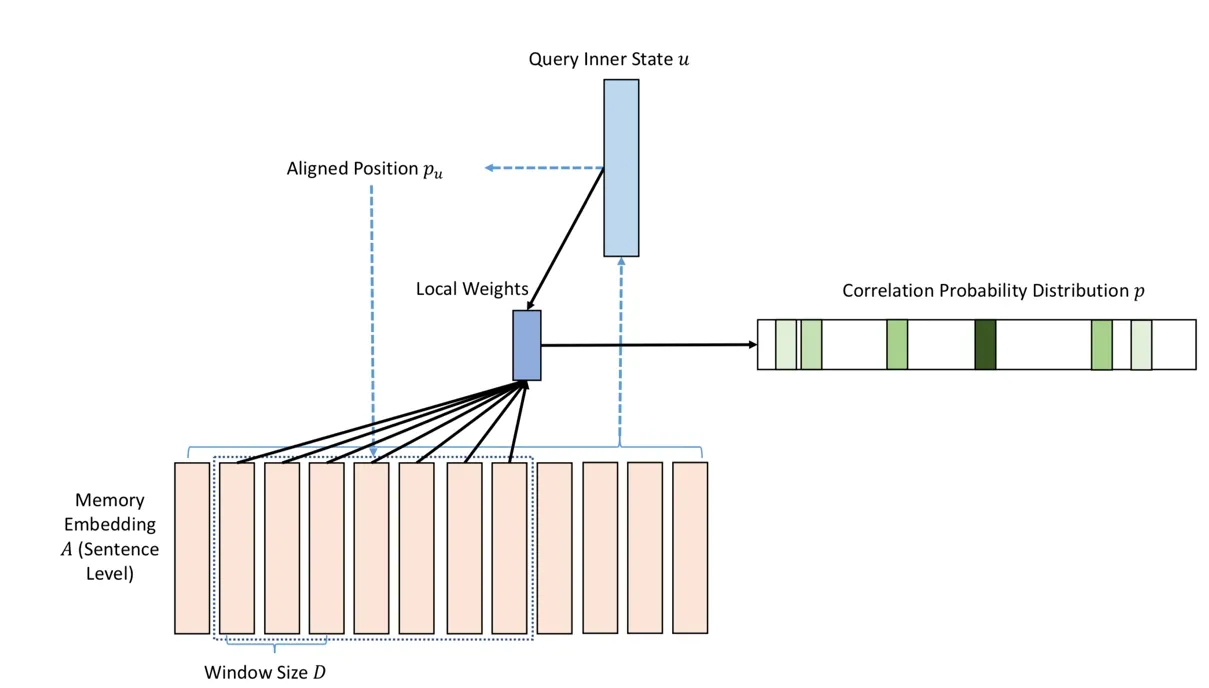
Figure2:Local-Attention Matching

The above is for single layer structure (Fig.2),for many different types of difficult tasks,the model can be extended to multi-layer memory structure (Fig.1),where each memory layer is named a hop and in MemN2N,the (K+1)tℎhop’s state uK+1is calculated by:

By contrast,we utilize gated linear units (GLU) in our MemN2N-GL.Compared to linear mapping H or frequently used nonlinear mapping functions,GLU effectively reducing the gradient dispersion,but also retaining the ability of nonlinearity.Proved by experiment,it is better suit for MemN2N.
3.2 Gated linear units mapping
In our MemN2N-GL,we use the layer-wise [Sukhbaatar,Szlam,Weston et al.(2015)]form (where the memory embeddings are the same across different layers,i.e.,A1...=AKand C1...=CK.) to expand the model from a single-layer to a multi-layer structure.In this case,we utilize GLU mapping to the update of u between layers:

where W,V ∈ ℝm×m,m is embedding size,b,c∈ ℝm×1,W,V,b,c are learned parameters,oK∈ ℝm×1is the output of the Ktℎ layer (Fig.1).
Then,the predicted answer distribution a is the combination of the input and the output of the top memory layer:

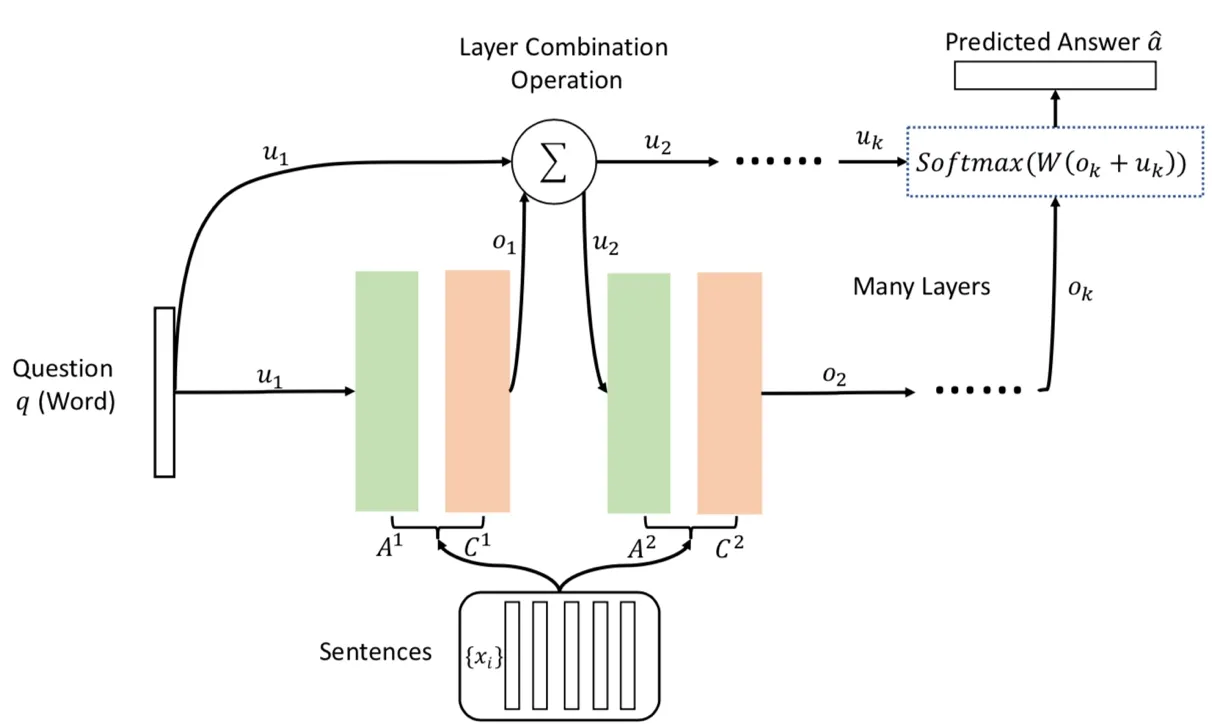
Figure3:A k layers version of MemN2N
Finally,at the top of the network,we adopt the original approach combining the input ukand the output okof the top memory layer:

where Wis the parameter learned during training.
Compared with MemN2N,our model performs better in complex QA problems,which can be confirmed in the experimental results in the next section.We believe that the local attention mechanism removes redundant memory when calculating the correlation between memory and query,so the weight vector obtained is “purer” and contains more useful information.Besides,compared with linear mapping,GLU mapping has the ability of nonlinearity,which makes the model has stronger learning ability in the update of u between layers.
4 Experiments and results
We perform experiments on goal-oriented dialog datasets Dialog bAbI [Weston,Bordes,Chopra et al.(2015)],which contains 20 subtasks.Each of subtasks consists of the ree parts:the context statements of the e problem,the question,and correct answer.There are samples of the ree of the tasks in Tab.1.For each question,only certain subsets of the e statement contain the information needed for the answer,while other statements are basically unrelated interferers.And the difficulty of various subtasks is different,which is reflected in the increase of interference statements.During training,we choose to use 10K dataset,our goal is to improve the ability of the model to answer questions correctly based on context.
4.1 Training details
We perform our experiments with the following hyper-parameter values:embedding dimension embed_size=128,learning rate λ =0.01,size of each batch batcℎ_size=32,number of layers K=3,capacity of memory memory_size=50 and max gradient norm to clip max_clip=40.0.We also used some skills during the training,for example,the learning rate of our model automatically adjusts with the change of loss.If the loss value does not decrease but increases between adjacent training epochs,the learning rate will be reduced to 2/3 of the current value.The condition of training termination is that the loss value is less than a certain threshold (the experiment was 0.001),or the number of training epochs reaches the upper limit.In the course of training,the training time varies with the difficulty of different subtasks,but all of them are within one day.
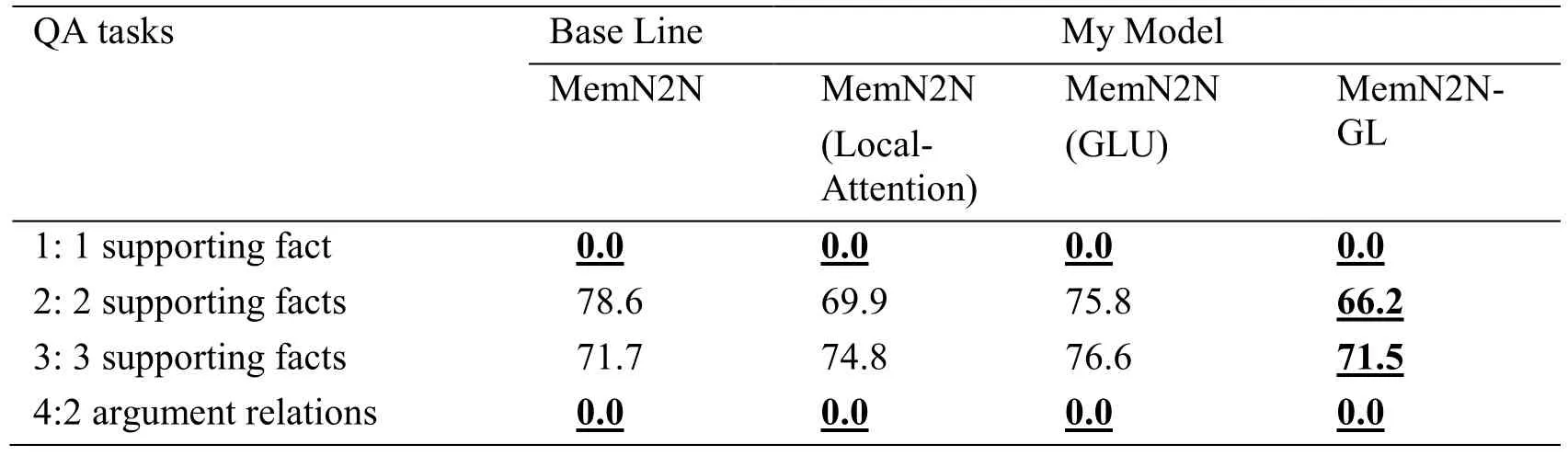
Table2:Test error rates (%) on the 20 QA tasks

5:3 argument relation 9.5 11.2 3.2 0.9 6:yes/no questions 50.0 50.0 25.2 48.2 7:counting 50.3 11.5 16.1 10.9 8:lists/sets 8.7 7.3 6.0 5.6 9:simple negation 12.3 35.2 13.1 4.4 10:indefinite know ledge 11.3 2.6 3.9 13.9 11:basic coreference 15.9 18.0 40.9 9.0 12:conjunction 0.0 0.0 2.8 0.0 13:compound coreference 46.1 21.3 18.8 1.4 14:time reasoning 6.9 5.8 4.4 10.3 15:basic deduction 43.7 75.8 2.4 0.0 16:basic induction 53.3 52.5 57.8 53.1 17:positional reasoning 46.4 50.8 48.6 46.2 18:size reasoning 9.7 7.4 13.6 12.9 19:path finding 89.1 89.3 14.5 24.7 20:agent’s motivation 0.6 0.0 1.7 Mean error (%) 30.2 29.2 21.2 19.0 0.0 Successful tasks (err < 5%) 4 5 8 8

Table3:The visualization weights of layers
4.2 Results and analysis
Our baseline is MemN2N.We try three different combinations of improvements and compare their performance in different subtasks (as shown in Tab.2).MemN2N (Local-Attention) and MemN2N (GLU) indicate that the model only adds the local attention mechanism and the GLU mechanism respectively,MemN2N-GL means that both improvements exist simultaneously.The number in the table represents the error rates of each sub-task,and the bold number represents the result of the model that performs best in the same subtask.In the last two rows of the e table,we counted the mean error rates of all models and the number of successful tasks (subtasks with error rates less than 5).
In terms of results,MemN2N-GL achieves the best results both in mean error rates and in the number of successful tasks.Compared with MemN2N,the mean error rates is reduced by 37.09%,and the number of successful tasks doubled from four to eight.MemN2N(Local-Attention) and MemN2N (GLU) have their own advantages and disadvantages,but both of their effect are better than MemN2N.
4.3 Related tasks
In addition to comparing the results of different tasks with each model in Tab.2,we use a specific example to quantitatively analyze the result by the visualization weights of layers.As shown in Tab.3,the most relevant memory sentence to the query “Who did Fred give the apple to ?” is the first memory sentence:“Fred gave the apple to Bill”.After training,MemN2N does not focus on the memory sentences of greater relevance,which led to the wrong answer as a result.While our model pays close attention to contextual information that is highly relevant to query,which can be reflected in the size of the correlation weight at each layers.The darker the color,the greater the weight.
5 Conclusion and future work
In this paper we proposed two improvements based on MemN2N model for QA problem and perform empirical evaluation on dialog datasets bAbI.The experimental results show that our improved model has a greater performance than the original model,which strongly confirms our conjecture that the model should pay more attention to the useful information when training.In the future,we are prepared to further improve the ability of the model to handle complex tasks.At the same time,we are going to test our model on more datasets.We also intend to combine our model with recent research results Bert (Bidirectional Encoder Representations from Transformers) and use our model as a downstream part to see if it will achieve better results.
Acknowledgement:This work is supported by the National Key Research,Development Program of China under Grant 2017YFB1002304 and the National Natural Science Foundation of China (No.61672178)
 Computers Materials&Continua2019年9期
Computers Materials&Continua2019年9期
- Computers Materials&Continua的其它文章
- A DDoS Attack Situation Assessment Method via Optim ized Cloud Model Based on Influence Function
- Distant Supervised Relation Extraction with Cost-Sensitive Loss
- Privacy-Preserving Quantum Two-Party Geometric Intersection
- Tibetan Multi-Dialect Speech and Dialect Identity Recognition
- Sentiment Analysis Method Based on Kmeans and Online Transfer Learning
- Three-Dimensional Numerical Analysis of Blast-Induced Damage Characteristics of the e Intact and Jointed Rockmass