
Distant Supervised Relation Extraction with Cost-Sensitive Loss
2019-11-25 10:22DaojianZengYaoXiaoJinWangYuanDaiandArunKumarSangaiah
Computers Materials&Continua 2019年9期
Daojian Zeng ,Yao Xiao ,Jin Wang, ,Yuan Dai and Arun Kumar Sangaiah
Abstract:Recently,many researchers have concentrated on distant supervision relation extraction (DSRE).DSRE has solved the problem of the lack of data for supervised learning,however,the data automatically labeled by DSRE has a serious problem,which is class imbalance.The data from the majority class obviously dominates the dataset,in this case,most neural network classifiers will have a strong bias towards the majority class,so they cannot correctly classify the minority class.Studies have shown that the degree of separability between classes greatly determines the performance of imbalanced data.Therefore,in this paper we propose a novel model,which combines class-to-class separability and cost-sensitive learning to adjust the maximum reachable cost of misclassification,thus improving the performance of imbalanced data sets under distant supervision.Experiments have shown that our method is more effective for DSRE than baseline methods.
Keywords:Relation extraction,distant supervision,class imbalance,class separability,cost-sensitive.
1 Introduction
Relation extraction plays a core role in Natural Language Processing (NLP),and it has always been the focus of many researchers.Supervised methodsoften achieve good results in relation extraction [Kambhatla (2004);Zhou,Su,Zhang et al.(2005)],But it relies on huge amount of data and entails better separation between classes [Raj,Magg and Werm ter (2016)].
To overcome the shortcomings of the e lack of labeled training data in the supervised paradigm,distant supervision has been proposed,which can automatically generate training data.Distant supervision can convert massive unstructured data into labeled data by leveraging existing know ledge bases,then the supervised model uses these labeled data to create features [Mintz,Bills,Snow et al.(2009);H of fmann,Zhang,Ling et al.(2011);Riedel,Yao and McCallum (2010);Surdeanu,Tibshirani,Nallapati et al.(2012)].Recently,many researchers combine distant supervision with deep neural network to automatic learn features [Zeng,Liu,Lai et al.(2014);Zeng,Liu,Chen et al.(2015);Lin,Shen,Liu et al.(2016);Jiang,Wang,Li et al.(2016);Zeng,Dai,Li et al.(2018)],which have made a series of progress.Distant supervision assumes that if the sentence in the dataset contains the entity pairs expressing a relation in the know ledge base,then all sentences containing the same entity pairs in the dataset are considered to express this relation.Since this assumption is too absolute,and the data in the real world has its distribution,the method of distant supervision still has the following shortcomings.
First,there is a serious class imbalance problem in the data which automatically labeled by the distant supervision.Secondly,the data automatically generated by distant supervision have a poor class-to-class (C2C) separability.
Currently,there are two mainstream methods to address class imbalance.One is changing the dataset’s distribution and another one is adjusting the corresponding algorithm.For the first method,it changes the distribution of data by under-sampling or over-sampling.Specifically,under-sampling removes some instances from the majority class so that the number of samples from the majority class and minority class is close.Since many instances are discarded,the training set is smaller than the original one,it is possible to cause under-fitting.Over-sampling is the opposite of under-sampling.These methods add some instances into minority class to fill the quantity gap of imbalanced classes and then learn.Due to the repeated sampling from minority class,it is prone over-fitting.In this paper,we propose a new algorithm to address the problem of class imbalance.In order to reduce the negative influence of the artificial class noise in distant supervision,we use the ranking loss function.In the conventional ranking loss function,because the conventional cost function will treat all individual errors as equal importance,the classifier tends to classify all instances into the majority class [Murphey,Guo and Feldkamp (2004)].To avoid this kind of situation,we use cost-sensitive ranking loss function.When misclassifying the instance from minority class,we will give it more punishment than misclassifying a majority instance,so this method is more beneficial to correctly classify the minority class.
Using cost-sensitive ranking loss achieves excellent results in most cases.However,due to some classes have poor C2C separability in the automatically labeled data,these classes cannot be correctly classified.In this case,we use the Silhouette score[Rousseeuw (1987)] as the C2C separability measure,and then adjust the cost of misclassification.Specifically,when the C2C separability is good which means it’s easier to correctly classify at this time,so the error should cost more,and vice versa.Generally,researchers will set the cost of misclassification based on the distribution of the data,and the cost remained unchanged during the training.Different from their works,by considering C2C separability,we can adjust the maximum reachable cost of misclassification,so that the cost of misclassification can be automatically learned based on the final problem,thus,our method is more flexible.
2 Related work
Relation extraction automatically identify the semantic relation between entities,which is a very important task in NLP.Generally supervised learning methods yield high performance [Mooney and Bunescu (2006);Zelenko,Aone and Richardella (2003);Zhou,Su,Zhang et al.(2005)].But supervised relation extraction of ten faces the challenge of a lack of labeled training data.Mintz et al.[Mintz,Bills,Snow et al.(2009)] uses the freebase,a prevalent know ledge base,to align with rich unstructured data for distant supervision,so that a large amount of labeled data can be obtained.But distant supervision has a problem of the wrong label.In order to address this problem,a relaxed distant supervision assumption was proposed by Riedel et al.[Riedel,Yao and McCallum (2010);H of fmann,Zhang,Ling et al.(2011);Surdeanu,Tibshirani,Nallapati et al.(2012)] for multi-instance learning.Nguyen et al.[Nguyen and Moschitti (2011)] extends distant supervision by using relations in Wikipedia.
The above methods are effective for DSRE.But they need high quality handcrafted features.Recently,many researchers have attempted to use neural networks for DSRE rather than hand-crafted features.Zeng et al.[Zeng,Liu,Lai et al.(2014)] adopts CNNs to extract sentence-level features and lexical-level features to make full use of the semantic information of sentences.Santos et al.[Santos,Xiang and Zhou (2015)]proposes the pairwise ranking loss function to alleviate the impact of artificial classes.These methods use sentence-level annotated data to train the classifier.However,since a fact may correspond to multiple sentences during data generation,just like data collection of indoor localization [Li,Chen,Gao et al.(2018)],these methods cannot be applied directly in DSRE.Therefore,Zeng et al.[Zeng,Liu,Chen et al.(2015)] proposes piecewise convolutional neural network (PCNN) model,and incorporates multi-instance learning to solve the above problem.Lin et al.[Lin,Shen,Liu et al.(2016)] makes use of the attention mechanism to minimize the negative impact of the wrong label in the DSRE.Jiang et al.[Jiang,Wang,Li et al.(2016)] uses the cross-sentence max-pooling to share information from different sentences.Zeng et al.[Zeng,Zeng and Dai (2017)] Combines ranking loss and cost sensitive to solve the class imbalance problem in DSRE and reduce the impact of the artificial class.
The above work has greatly promoted the relation extraction task.However,the works[Zeng,Liu,Lai et al.(2014);Zeng,Liu,Chen et al.(2015);Jiang,Wang,Li et al.(2016);Lin,Shen,Liu et al.(2016)] don’t pay attention to the class imbalance problem.In Zeng et al.[Zeng,Zeng and Dai (2017)],a new cost-sensitive loss function is proposed,which replaces the traditional cross-entropy loss,but their costs are predefined and fixed during the training process.When the C2C separability is not good,it does not achieve the expected experimental results.Different from these works,we let the C2C separability as one of the factors that affect the cost of misclassification,and let the cost parameter as an automatically learnable parameter.Our method automatically learns cost parameters based on the final problem,so its relatively more flexible.
3 Methods
The structure of our model is similar to Zeng et al.[Zeng,Zeng and Dai (2017)],which is made up of two parts:the PCNNs feature extractor and the ranking based classifier.As shown in Fig.1,the PCNNs feature extractor adopts a piecewise max pooling to extract the feature vectors of an instance in a bag.After that,in order to get the most appropriate instance and predict the relation of the instance from the bag,we use the rank-based classifier as shown in Fig.1(b).
In PCNNs feature extractor,we combine the word embedding which isoften used in NLP[Xiang,Yu,Yang et al.(2018)] and position embedding as vector representations.Here we denote the word embedding asEand the position features asPFs.First,we initialize each word token with its corresponding pre-trained word embedding,and next,we train the word embedding by adopting the method in M ikolov et al.[M ikolov,Chen,Corrado et al.(2013)].After that,we use the method in Zeng et al.[Zeng,Liu,Lai et al.(2014);Zeng,Liu,Chen et al.(2015)] to obtain the positional features of each word token,and we also transform them into vectors.Finally,after convolution and piecewise max-poling,we can obtain the feature vector of the sentence.
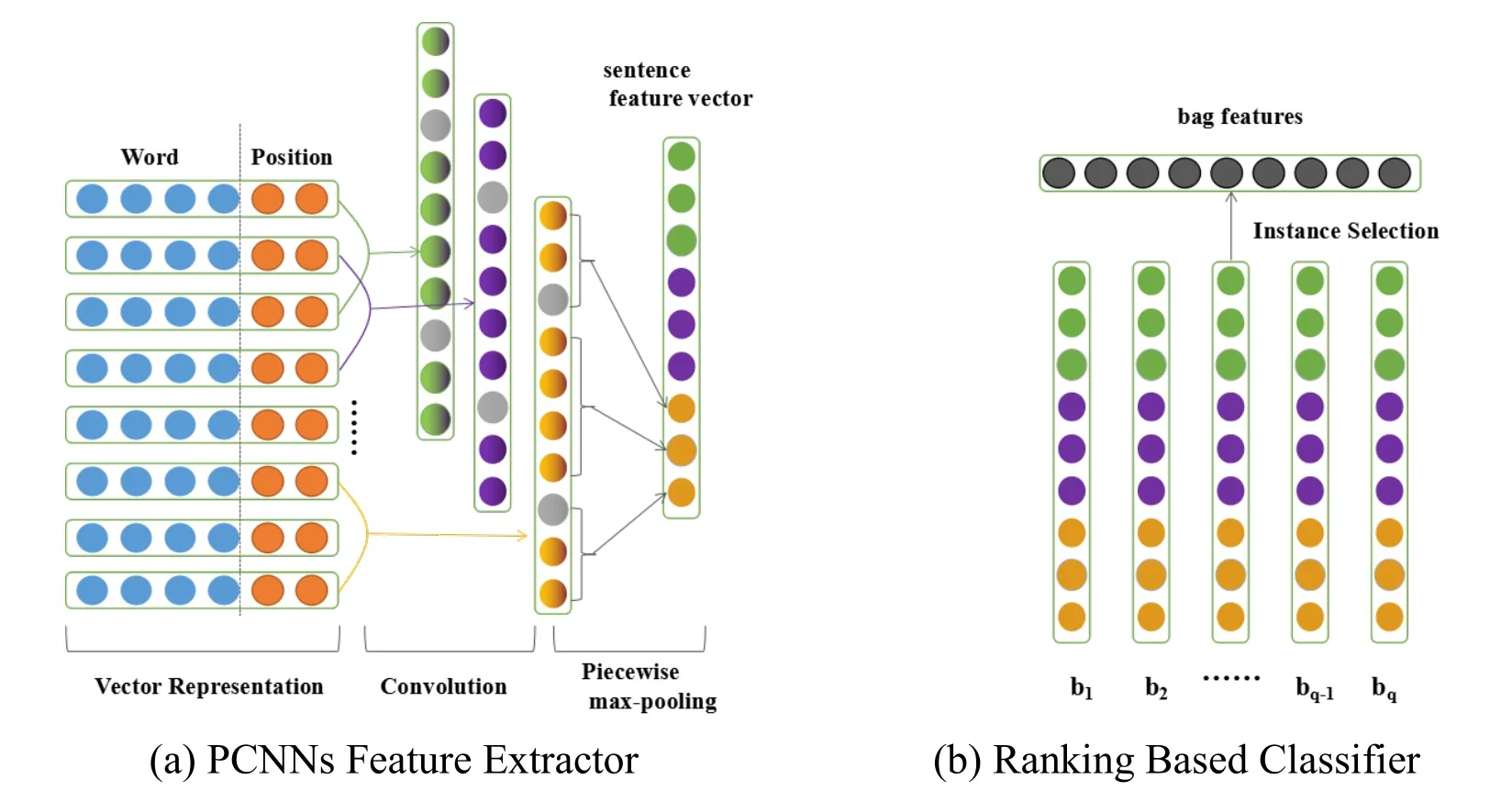
Figure1:The architecture used in this work
Each feature vector of instance is denoted asb.Then,we fed it to the ranking based classifier.The network uses the dot product to calculate the score of the class label ti:

where wtiis the embedding of class label ti.After calculating the score of each instance,we select the instance with highest score in the bag and use the corresponding label as the bag label.
3.1 Cost-sensitive ranking loss
In order to reduce the impact of artificial class and compare more conveniently with baseline methods,we use cost-sensitive ranking loss.Suppose that our training set are composed byNbags,thei-thbag is represented as Bi,and its label is relationri.When thei-thbag whose label is ri=tjis fed into the network,using Eq.(1),we can get the classification score of the current bag labelfor class tj,and the highest score of the negative class in the current bagfor class tk.The cost-sensitive ranking loss is given by:
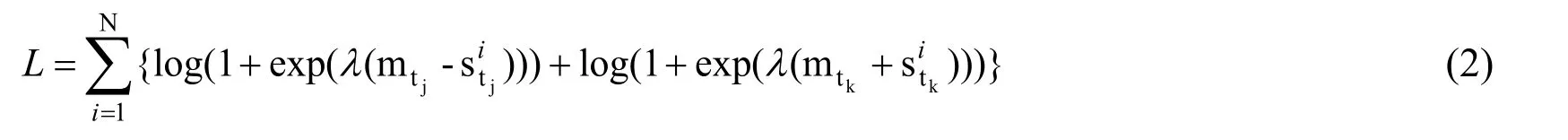
Where tirepresents the class label,and tk≠tj(j,k∈{1,…,T},Tequals the number of all relation types).λ is a constant term.i indicates the i-tℎ bag is fed into the network.mtjand mtkcan be obtained by calculate the following Eq.(3),which represents the different margin of the class ti,that is,a cost sensitive parameter:

where γ is a constant item,and #tjequals the number of samples corresponding to the relation label tj.
We can observe from Eq.(2) that as the score stjincreases,the first term on the right side of the equation decreases;and as the score stkdecreases,the second term on the right decreases.Since the goal of our model is to let the score of correct class tjgreater than mtjand the score of incorrect class tksmaller than mtk.Thus,when misclassify the minor classes,our model give more penalties for it than the major classes.
However,one of the drawbacks of the is method is that it cannot find the optimum value for mti.Experiments show that if the cost is simply set according to the percentage of the classes in the data distribution,the performance improvement is not obvious [Zeng,Zeng and Dai (2017)],especially when poor separability between classes.Thus,we now let mtias an adaptive parameter,and experiment show that comparing to static values,the adaptive cost-sensitive parameter can get better performance.In this paper,we use C2C separability to adjust the maximum reachable cost of misclassification,change the originally fixed cost parameter into an optimizable cost parameter,and update the corresponding cost for different classes.
3.2 m ti optim ization
We will optimize the weight parameters and mtisimultaneously during the training process,that is,to keep one parameter constant while minimizing the cost relative to the other parameter [Jiang,Wang,Li et al.(2016)].In our work,we will optimize mtiin Eq.(2) as follows:

Tis expressed by the following Eq.(5).His the ratio of imbalance,which is the maximum reachable cost of misclassification.

Through the above steps,we get a mtibetween 1 andH,which is a learnable parameter during the training process,and we call it adaptable mti.
3.3 Class-to-class separability
Since effective learning under imbalanced data depends on the degree of separability between classes [Murphey,Guo and Feldkamp (2004)].For this,our method is,when classes are well separated,if misclassified,more punishment should be given.Conversely,when the C2C separability is poor,classification is difficult to achieve,errors should cost less.
Silhouette score isoften used as a measure of C2C separability.The value of Silhouette ranges from -1 to +1,which indicates how close each data point relative to its own cluster.Particularly,when its value is +1,it means that a point is within its own cluster,correspondingly,-1 indicates that the point is completely in the opposite cluster,and when the point is on the boundary of two clusters,the value of Silhouette is 0.The degree of separability of two clusters is calculated by the sum of the Silhouette scores of all points which in these two clusters.So,for the class tjand class tk,the separability can be calculated by Eq.(6):

where,K(i)=m inimun d(i,tk),and d(i,tk) is the average dissimilarity of object i in the class tjto all objects from class tk;Similarly,J(i)=m inimun d(i,tj),where d(i,tj) is the average dissimilarity of object i in the class tjto all other objects in this class (As shown in Fig.2).
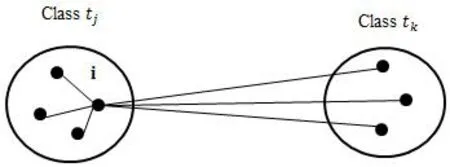
Figure2:Relation of all elements which included in the computation of S(i)
We useSto represent the Silhouette score and give the imbalance ratio as Eq.(7):

Now,His defined as the following form:

From Eq.(8) we can observe that if two classes are well separated (in this case |S| = 1),the maximum cost at this time can be twice ofIR.In this way,we can adjust the maximum reachable cost of misclassification based on separability.The entire optimization process can be seen in the Algorithm 1.

Algorithm 1.Learning optimal parameters Input:network parameters,training data,cost-sensitive parameters Output:learned optimal parameters w∗ and m ti∗1 randomly initialize the network parameters,and divide a given training sam ple into m ini-batch 2 m ti is initialized to 1 3 while epoch ∗≠max-epoch do 4 for mini-batch do 5 Forward propagation;6 calculate the error by formula (2);7 Calculate the gradient of the error;8 Update 9 end 10 Calculate the gradient of m ti by formula (4);11 Update 12 end
4 Experiment
In this section,first,we introduce the dataset and evaluation used in our paper.Then,in order to determine the parameters used in the experiment,we used cross-validation to test several variables.Finally,we show the results of the e experiment in charts and analyze them in detail.
4.1 Dataset and evaluation metrics
The dataset3used in this paper has been widely used in distant supervision relation extraction,it was developed by Pennington et al.[Pennington,Socher and Manning(2014)] and used by Santos et al.[Santos,Xiang and Zhou (2015);Riedel,Yao and M cCallum (2010);Zelenko,Aone and Richardella (2003)].It generated by aligning the NYT corpus with Freebase.We use corpus from 2005-2006 as the training corpus and corpus from 2007 as the test corpus.
The goal of our methods is to improve the overall precision but not affect the precision of the majority and minority classes.In order to compare with baseline methods and test the performance of our method,we evaluate the models via precision,recall and F1-score.
4.2 Experiment settings
We pretrained skip-gram to generate word embedding.If the entity has multiple word tokens,then we use the ## operator to connect the tokens.We randomly initialized the Position Features to a uniform distribution between [-1,1].Parameters used in PCNNs model are set as the same as Zeng et al.[Zeng,Zeng and Dai (2017)].All parameters of our model are in Tab.1.
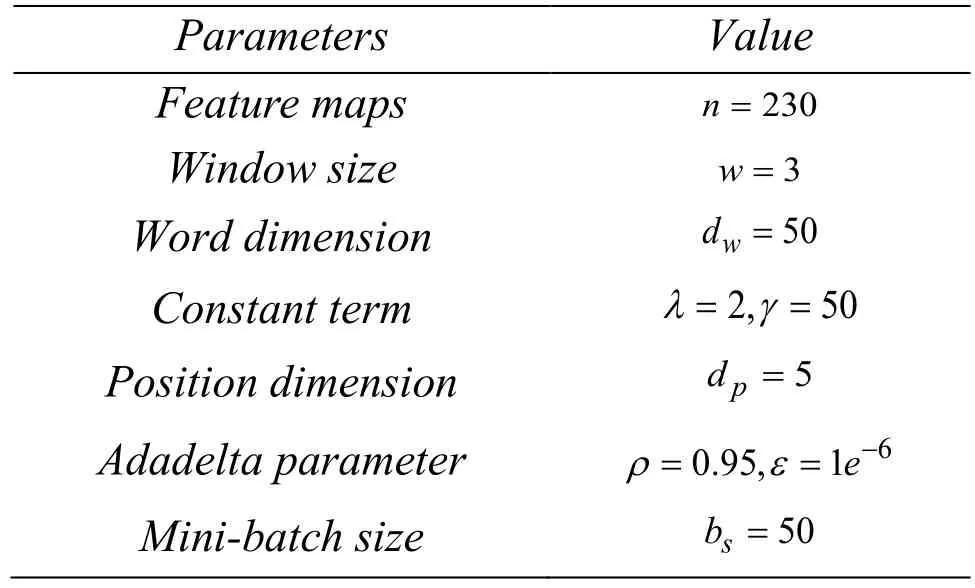
Table1:All parameters used in our experiments.
4.3 Baseline
In our baseline methods,there are three methods that use handcrafted features,and the others use convolutional neural networks to extract features.Mintzextract features from all sentences,which proposed by Mintz et al.[Mintz,Bills,Snow et al.(2009)];MultiRis proposed by H of fmann et al.[H of fmann,Zhang,Ling et al.(2011)],which treats DSRE as a multi-instance learning task;theMIMLmethod used in [Surdeanu,Tibshirani,Nallapati et al.(2012)] is a multi-instance and multi-label method for relation extraction;PCNNs+M ILis proposed by [Zeng,Liu,Chen et al.(2015)],which extract bag features by using PCNNs and multi-instance learning;CrossMaxselects features across different instances by incorporating cross-sentence max-poolingandPCNNs,it’s proposed by Jiang et al.[Jiang,Wang,Li et al.(2016)];R-Lwas proposed by [Zeng,Zeng and Dai(2017)],which uses cost sensitivity learning to solve the class imbalance problems.
4.4 Comparison with baseline methods
In this part,we present the results of our experiments in charts,and perform some analysis based on these results.In the following charts,we use ours to represent the method that use C2C separability.
We use the class separability scoresSto adjust the maximum reachable cost of a misclassification,thereby changing the cost-sensitive ranking loss from a fixed cost into an adaptive cost.The precision/recall curve of the method proposed in this work and baseline methods as shown in Fig.3.We can observe that our method gain the highest precision at all recall levels,and it can achieve a maximum recall level of approximately 39%.PCNNsM IL can achieve a recall level of 36%,but their precision is too low.R-L can get about 38% recall level,but its precision is lower than the method in this paper.Taking into account the precision and recall at the same time,our method can achieve better results.
4.5 Effect of class separability score on cost-sensitive ranking loss
Since our model degrades toR-Lafter removing the metrics of the e C2C separability,in order to verify the impact of C2C separability to cost-sensitive ranking loss,we calculated F1-score for some relations to make a comparison between the R-L baseline with fixed cost and our method with adaptable cost.The results are in Tab.2.
From Tab.2,we can see the advantages of incorporating C2C separability metrics.Especially in relation labelpeople/person/place_livedandpeople/person/place_ of _birth,F1-score is lower when using theR-Lbaseline,because of the poor separability of these two relation classes.In our approach,since the metrics of C2C separability are considered,the classification performance of these two classes is greatly improved.In summary,incorporating class separability metrics to cost-sensitive ranking loss improves the performance effectively.
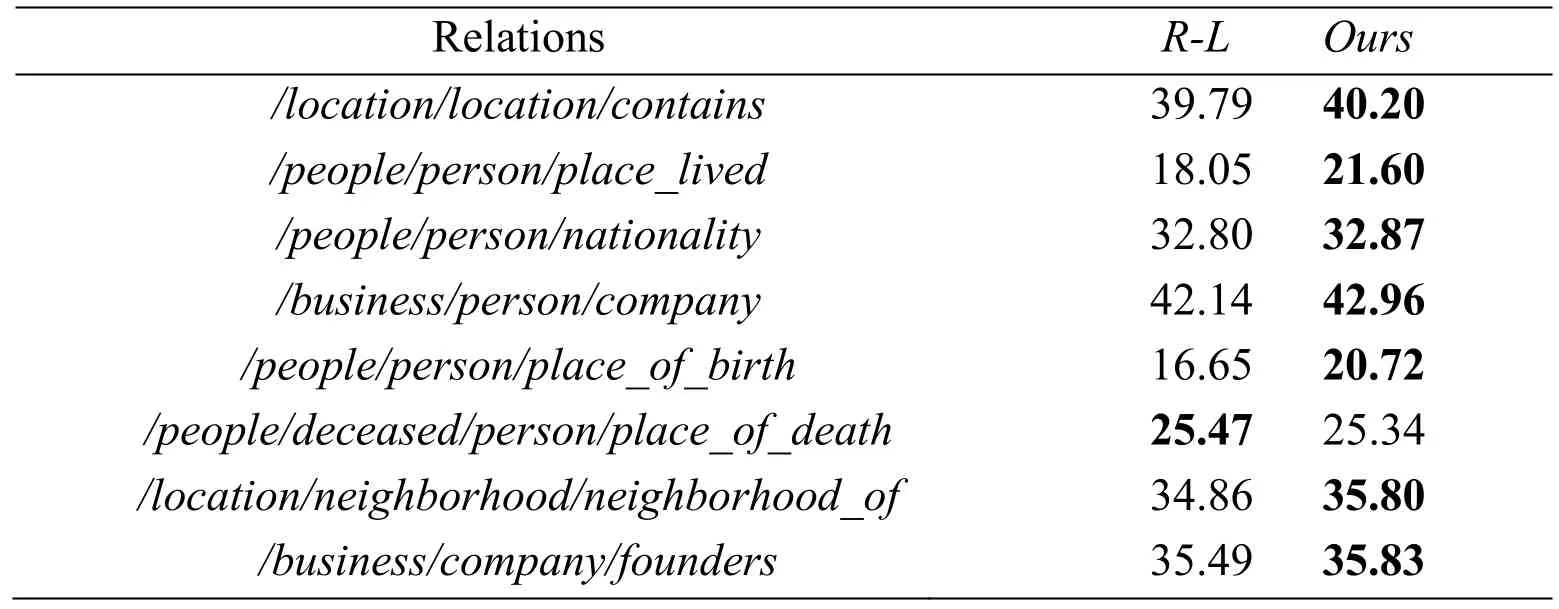
Table2:F1-score for some relations to verify the impact of class separability
5 Conclusions
We concentrate on the class imbalance problem in DSRE.We use the Silhouette score to measure C2C separability and incorporate this measure to cost-sensitive ranking loss to adjust the maximum applicable cost.Through extensive experiments,the result shows that our method has more significant effect on improving the experimental results.The problem of class imbalance in DSRE can be effectively solved by incorporating the C2C separability measure into the cost-sensitive ranking loss.In future work,we want to further study the impact and difference of other loss functions and cost-sensitive strategies in DSRE.
Acknowledgments:This research work is supported by the National Natural Science Foundation of China (Nos.61602059,61772454,6171101570).Hunan Provincial Natural Science Foundation of China (No.2017JJ3334),the Research Foundation of Education Bureau of Hunan Province,China (No.16C0045),and the Open Project Program of the National Laboratory of Pattern Recognition (NLPR).
 Computers Materials&Continua2019年9期
Computers Materials&Continua2019年9期
- Computers Materials&Continua的其它文章
- Retinal Vessel Extraction Framework Using Modified Adaboost Extreme Learning Machine
- Dynamic Analysis of a Horizontal Oscillatory Cutting Brush
- Localization Based Evolutionary Routing (LOBER) for Efficient Aggregation in Wireless Multimedia Sensor Networks
- Failure Prediction,Lead Time Estimation and Health Degree Assessment for Hard Disk Drives Using Voting Based Decision Trees
- High Precision SAR ADC Using CNTFET for Internet of Things
- An Efficient Greedy Traffic Aware Routing Scheme for Internet of Vehicles