
一种面向中文非标建筑地址标准化的自动匹配方法
2019-11-25 10:26:32邹恩岑曾诚张谦徐川朱润奚雪峰
苏州科技大学学报(自然科学版) 2019年4期
邹恩岑,曾诚,张谦,徐川,朱润,奚雪峰*
(1.苏州科技大学电子与信息工程学院,江苏苏州215009;2.苏州市虚拟现实智能交互及应用技术重点实验室,江苏苏州215009;3.昆山市公安局情报中心,江苏苏州215335)
近年来,随着我国智慧城市建设进程的快速发展,门市楼牌的地址信息在应用中的重要性日趋突出,尤其在公安业务领域[1-2]。然而由于当前社会上存在着多样的地址信息,如自来水公司的用户登记地址、燃气公司的用户登记地址、有线电视用户地址、公安被盘查人员登记地址等。从而在包含地址信息的不同数据集中,如户籍地址数据、报警地址数据、案发地址数据中,出现了多样性的地址表述,即地址信息表述不唯一。例如,同样的一个地址,在自来水公司用户地址中被表述为“千灯美景园34#(原1-14#)604”,在被盘查人员登记地址中可能表述为“江苏省昆山市千灯镇美景园34幢604室”,而在户籍地址中却表述为“昆山市千灯镇美景园34幢604室”。
地址信息表述不唯一,导致不同来源的信息无法联通、相关业务无法在公安电子地图上匹配与显示、情报研判难以深入、发现重点人员轨迹困难、预测重大事件成效不显著、整合数据资源不充分等一系列问题。针对上述问题,构建一个标准化的地址库,然后将其他地址统一映射到该标准地址库中,是一种可行的方法[3]。把上述各类地址定义为“非标地址”,把构建的标准化地址库中的地址称为“标准地址”。
因此,昆山市公安局开展了地址标准化建设。第一阶段已完成90多万条的公安标准地址库建设,但同时来自社会各界采集到的非标地址类型达到2 275种,数量达到20亿条。如此海量的非标地址,如何与标准地址进行匹配,存在着以下难点:(1)由于数据量大,人工检索90多万条数据,耗时耗力,可行性差[4];(2)由于地址之间语义级相似度的存在,无法采用传统的字符串匹配检索方式。
针对上述难点,笔者基于哈希映射、词频统计及余弦相似理论,提出一种面向中文非标建筑地址的标准化自动匹配方法,自动实现非标地址与标准地址的匹配映射。
1 相关工作
目前,在构建中文建筑地址库方面使用的数据结构主要有树形结构和鱼型结构等[5],这些结构可以在一定程度上消除数据之间的冗余和强依赖关系,方便存储数据。在面向中文短文本匹配工作中,为使匹配算法具有较低的空间复杂度和时间复杂度,一般采用哈希结构和Tire结构[6-7];也有研究者使用树型结构实现具有较高匹配率的算法模型,但模型过于复杂[8-9]。目前有些应用系统,通常使用地址分级和有限状态机驱动方法[10],初步解决地址越级跳跃和地址分词不准确的问题;使用索引结构与全文搜索[11],依托开源检索引擎构建地址匹配工具也是常用的方法[12-13],但系统的识别率严重依赖标准地址库规模的大小。基于自然语言处理技术,利用大量地址数据进行模型训练,通过语义理解实现自动匹配,是当前人工智能及大数据技术在该领域的探索与尝试[14-17]。
相似度计算技术是解决地址匹配问题的关键技术,目前主要采用如下方法:基于词形和词序匹配的方法、基于语义计算的方法、使用语义依存的方法、基于骨架依存树的方法、基于编辑树的方法,以及基于模式的方法[18-19]。
2 非标地址自动匹配模型
2.1 任务描述
标准地址是指公安机关自己定义的一套具有清晰结构特征的地理编码,这套编码中既包含了描述地理位置的地址信息,也包括了该地址信息包含的经纬度信息等。非标准地址则是指从社会各界采集来的不具有公安系统规定的必要组成元素的一类地址。该类地址的典型特征就是人能够理解和辨识这个地址所标识的地理位置,但是这类地址无法直接录入公安系统进行信息整合。
文中主要研究如何将非标准地址准确高效地映射到标准地址数据集中,其实验数据集为:(1)95万条标准地址样本集;(2)1.6万条某自来水公司提供的非标准地址样本集;(3)1 000条来自其他5个社会机构(公安某部门、某燃气公司一、某燃气公司二、计生委某部门、某有线电视公司)的非标地址样本集。
笔者已采用人工众包标注[20]的方法完成了数据集(2)的标注,以此作为训练及测试数据集。数据集(3)用来验证文中所提出模型的泛化能力。
2.2 模型设计
地址匹配的实现,输入为一个非标地址,输出为按相似度从高到低排序的标准地址集合。在大量非标地址匹配过程中,采用计算机辅助方式,可以大幅度提高匹配效率,减少所需人工成本。随着自动匹配精度与速度的不断提高,该模型能够联通各非标地址系统间的信息孤岛,形成顺畅的地址搜索网络,为各非标地址系统间转换和地址统一计算提供重要的基础支撑[21-22]。
非标地址自动匹配主要包含两大步骤:(1)标准地址建模。将标准地址建立可快速查找的词典文件,主要结构为哈希结构,供后续非标地址匹配步骤使用。(2)非标地址匹配。根据输入的非标地址,在标准地址模型数据中,通过两级级联的哈希查找和相似度匹配方法,找出与其匹配的标准地址。模型框图如图1所示。

图1 非标地址自动匹配模型框图
2.2.1 标准地址建模
标准地址建模的流程分为如下5个步骤:(1)输入原始标准地址数据InSADS;(2)清洗InSADS,去除不必要的数据,保留规范地址数据,形成ReInSADS;(3)在ReInSADS数据集中提取标准地址关键词AddressKeyWords;(4)将标准地址转换成词向量;(5)以标准地址关键词AddressKeyWords为Key,标准地址词向量为Value,使用哈希表结构建立标准地址词典。
2.2.2 非标地址匹配
非标地址匹配流程分为如下7个步骤:(1)输入原始非标地址数据InNSAD;(2)清洗InNSAD,形成ReInNSAD;(3)在ReInNSAD中提取非标地址中的关键词;(4)地址淘选,在标准地址词典中通过非标地址关键词查找标准地址数据,形成候选标准地址子集CandSubSADS;(5)将淘选后的标准地址集CandSubSADS及非标地址ReInNSAD分别转换成词向量EMofCandSubSADS和EMofReInNSAD;(6)非标地址词向量与淘选后的标准地址集中的词向量逐一进行相似度计算;(7)筛选出与非标地址最相似的一组标准地址,按照相似度由高到低排序输出结果集合SResult。
3 数据结构与算法描述
3.1 构建哈希标准地址词典
哈希标准地址词典由哈希表构成,提取标准地址的关键词作为哈希表的Key,标准地址词向量的数组表作为哈希表的Value,词典数据结构如图2所示。
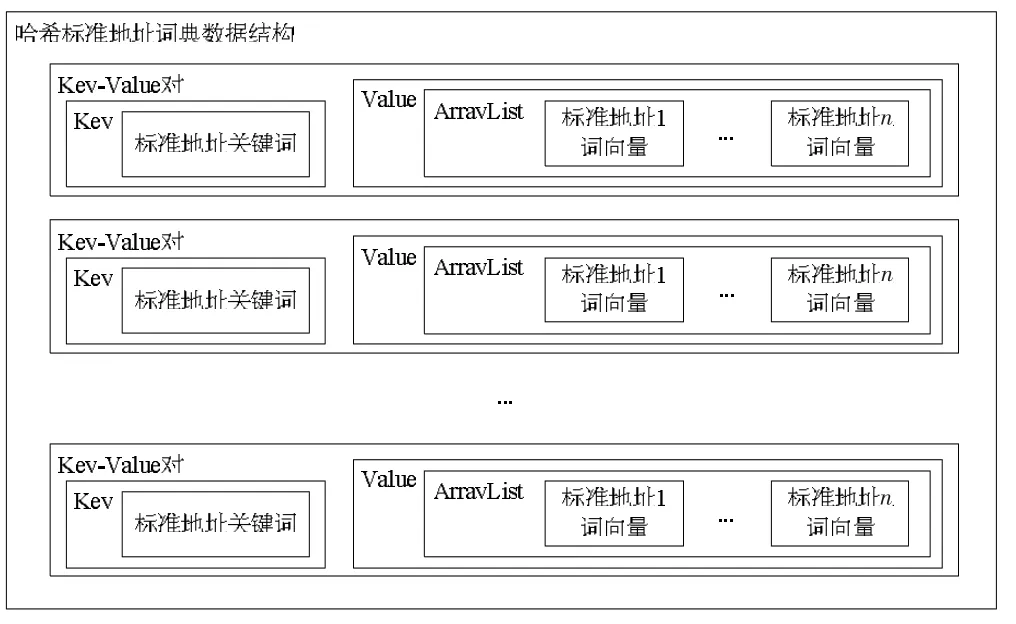
图2 哈希标准地址词典数据结构示意图
3.1.1 标准地址关键词提取
文中设计了两种标准地址关键词提取方法:一种是经验法;另一种是词频法。
经验法使用经验法提取关键词,并实现匹配的启发式规则如下:(1)提取“镇”字后面的2个字作为关键词,例如,在地址“昆山市玉山镇柏庐南路1126号”中,提取“柏庐”作为关键词;(2)提取“镇”字后面的3个字作为关键词,例如,在地址“昆山市玉山镇柏庐南路1126号”中,提取“柏庐南”作为关键词;(3)提取“镇”字后第3个位置到第5个位置作为关键词,例如,在地址“昆山市玉山镇柏庐南路1126号”中,提取“南路”作为关键词。
词频法使用词频法提取关键词,为关键词查找提供匹配规则的算法步骤如下:(1)统计标准地址库,按步长1、窗长2切割所有词的频率。(2)按照一定规则去除某些频率的词,并构建关键词。例如,每个标准地址中都有“昆山”一词,出现频率为915 407次,“单元”一词出现136 266次,“新村”一词出现121 286次。这些高频词无法表示标准地址的关键特征,因此,需要去除。与此类似,有些包含数字或带有特殊字符的词,也同样需要去除。
3.1.2 词向量切分
为了计算地址之间的相似度,需先将地址转换成词向量。文中选择使用步长为1、窗长为2的词向量切分法来分割地址字符串,切割出的两字字符串作为向量的基,每切割出一次基字符串,就在向量的这一维上增加一,以此构成词向量。
例如:地址“昆山市玉山镇柏庐南路1126号”中,分割后的词向量的基集合为U={昆山,山市,市玉,玉山,山镇,镇柏,柏庐,庐南,南路,路1,11,12,26,6号,号},用该集合表示的向量共有15个维度。
构成的词向量和所对应的基为:(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1);(昆山,山市,市玉,玉山,山镇,镇柏,柏庐,庐南,南路,路1,11,12,26,6号,号)。
3.1.3 插入标准地址词典
词典由哈希表构成,系统将提取的关键词作为Key,包含关键词信息的整条地址词向量数组表ArrayList作为Value,加入到哈希表中。若新加入的地址和已存在的Key-Value具有相同的Key,则在Value中的ArrayList尾部添加新的地址的词向量,形成如图2所示的地址词典结构。
3.2 地址淘选
地址淘选是将原先1个非标地址与95万的标准地址匹配的问题,通过计算机辅助缩小为1个非标地址与数万个标准地址匹配的问题。
3.2.1 经验淘选法
文中所使用的经验淘选方法步骤如下:
(1)地址淘选模块会提取非标地址的前两个字作为关键词,淘选子模块查询标准地址词典得到淘选地址数据集。
(2)如果得到的数据集数量不为空且小于15 000,则转向步骤(3)。如果得到的数据集数量大于15 000或数据集为空,则跳过地址的第一个字,利用步长1、窗长2的字符切分法分割地址字符串作为关键词,利用这些关键词查找标准地址词典,得到多个淘选地址数据集。该步骤中15 000是依据标准地址库中地址数量和经验淘选算法的特点,经过程序调试给出的一个在保证准确率情况下,冗余计算较少、计算速度较快的经验参数值。
(3)使用前三个字作为关键词查询标准地址词典得到淘选地址数据集。
(4)在得到的多个淘选地址数据集中选择包含地址数目最小的非空地址集,输出作为淘选结果地址集。
3.2.2 词频淘选法
文中所使用的词频淘选方法步骤如下:
(1)地址淘选模块会以步长为1、窗长为2的词向量切分法来分割非标地址字符串作为关键词。
(2)查找关键词的词频,如果数量大于45 000,则跳过该关键词,查找下一关键词。如果词频数量小于45 000,则添加字典中关联该关键词的所有地址到地址候选集中。该步骤中45 000是依据标准地址库中地址数量和词频淘选算法的工程特点,给出的一个限定计算规模、减少冗余计算的参数值,用于提高计算速度,该参数值在设置成大于等于45 000的数值情况下虽不会影响计算准确率,但增加了冗余计算,降低了计算速度。
(3)若有多个关键词满足条件,则添加多个候选地址集,并对这些地址集做合并操作。
(4)得到所有关键词所对应的地址候选集并集,即为词频淘选法得到的地址集。
3.3 非标地址与标准地址相似度计算
3.3.1 共同向量空间的转换
以非标地址字符串分割后的词向量记为向量a,标准地址分割后的词向量记为b,a和b由于各自的基不同,所在的向量空间不同,需要换算至相同的向量空间。模块程序提取a和b两向量基的并集,构成合并基,将a、b两向量转换到合并基所组成的新的合并向量空间中。
设向量a基的集合为:A={a1,a2,…,ai,c1,c2,…,ck},其中,a1至ai表示向量a独有的基集合,c1至ck表示向量a和向量b所共有的基集合。
向量b基的集合为:B={b1,b2,…,bj,c1,c2,…,ck},其中,b1至bj表示向量b独有的基集合,c1至ck表示向量a和向量b所共有的基集合。
则a与b的合并基集合为:C=A∪B={a1,a2,…,ai,b1,b2,…,bj,c1,c2,…,ck}。
例如,非标地址“柏庐南路1126#”的基集合为:A={柏庐,庐南,南路,路1,11,12,26,6#,#};标准地址“昆山市玉山镇柏庐南路1126号”基的集合为:B={昆山,山市,市玉,玉山,山镇,镇柏,柏庐,庐南,南路,路1,11,12,26,6号,号}。对上述两组集合取并集,得到的合并基为:C={昆山,山市,市玉,玉山,山镇,镇柏,柏庐,庐南,南路,路1,11,12,26,6号,号,6#,#},合并基后用该集合表示的向量共有17个维度。
非标地址“柏庐南路1126#”变换为合并基后的词向量和对应的基为:a=(0,0,0,0,0,0,1,1,1,1,1,1,1,0,0,1,1),(昆山,山市,市玉,玉山,山镇,镇柏,柏庐,庐南,南路,路1,11,12,26,6号,号,6#,#)。
地址“昆山市玉山镇柏庐南路1126号”变换为共同基后的词向量和对应的基为:b=(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0),(昆山,山市,市玉,玉山,山镇,镇柏,柏庐,庐南,南路,路1,11,12,26,6号,号,6#,#)。
3.3.2 余弦相似度计算
非标地址词向量a与标准地址词向量b之间使用余弦相似公式计算相似度

记向量a=(x1,x2,…,xn),向量b=(y1,y2,…,yn),代入公式(1),得到a与b之间的余弦相似度

3.3.3 相似度混合方法
非标地址与多个标准地址之间的相似度经过计算后排序输出,理论上相似度最高的组合对(非标地址,标准地址)即是所求的最优解,但有时候并非如此。例如:与非标地址“震川东路3#401(原A幢)”匹配的多个标准地址,它们相似度相同,均以“昆山市玉山镇震川东路商住小区”起头,后半部分分别为“5幢401室”、“6幢401室”,“1幢401室”、“2幢401室”、“4幢401室”和“3幢401室”。在这组相似度相同的标准地址中,顺序会被随机排列,而最优解“昆山市玉山镇震川东路商住小区3幢401室”被排在了第六号位置上。
为了让最优解能够排名靠前,系统将非标地址与标准地址中的数字作为关键词单独抽出计算相似度,以一定合适的比例与前面计算所得的地址相似度联合加权,得到最终准确结果。
4 实验
4.1 实验准备
4.1.1 数据集
实验使用某自来水公司非标准地址数据集16 682条(采用众包技术实现人工标注匹配);标准地址数据集953 510条;来自5个社会机构的泛化非标地址数据1 000条(同样采用众包技术实现人工标注匹配)。
非标地址的数据格式即为非标地址字符串,典型的非标地址数据如下所示:
柏庐南路1126#
锦景园63#(原1-18)404
千灯美景园6#(原3-15#)204
新阳广场店面北5(有家床上品)
北门路1014-302#(原永盛广场B1区A外街南)(厕所)
典型的标准地址格式由地址索引码、地址字符串和经纬度等信息组成,如下所示:
“416F8B2A488741E7A87976662556C1BC”,“昆山市玉山镇柏庐南路1126号”,“KUSYSZBLNL”,“120.9613000”,“31.3703500”,“320583”,“168B61105BC84D77975300FAD141929D”,“”,“”,“0”,“0”,“20-2月-12 10.57.01.109000上午”,“1126”,“1”,“0”。
人工标注匹配地址数据集描述了淘选基础上非标地址与标准地址的人工查找和观察对应关系,地址中“ ”符号为制表分隔符,如下所示:
震川中路2#底车库12室 其他
中华园15#405 昆山市玉山镇中华园15幢405室
富阳新村29#704(原604) 昆山市玉山镇富阳新村29幢704室
4.1.2 实验工具与环境
非标地址自动匹配系统采用Java语言设计与开发,系统包含四个程序包,分别为:数据清洗工具程序包dataClean、地址自动匹配程序包addressSim、数据结果验证工具包addressCheck和常用封装库程序包lib。
数据清洗工具程序包dataClean用于提供清洗标准地址的子模块程序;地址自动匹配程序包addressSim提供了标准地址建模模块和非标地址匹配模块;数据结果验证工具包addressCheck用于验证匹配结果是否正确;常用封装库程序包lib提供了常用的文件I/O、二元组数据结构和二元组比较器等常用自制程序库。
实验硬件环境:文中使用计算服务器为8核Intel Xeon E5-2640 V2,2.00GHz处理器,128G内存。软件配置为Ubuntu 16.04 LTS,Java JDK 1.8.0。
4.2 评价指标
文中实验共设置计算速度和匹配准确性两类指标,其中速度指标由标准地址数量、查找次数和查找时间反映,准确性指标由准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值反映。
实验的计算速度中的标准地址数量指的是模型所构建的标准地址词典中的地址数量;查找次数表示需自动匹配的非标地址总数量;查找时间表示自动匹配所有非标地址的总时间。
实验的准确性指标计算方法如下所示:在非标地址匹配中,设TP为模块匹配正确的地址数量,设FP为模块匹配错误的地址数量,设TN为模块找到的匹配地址在实际情况下无标准地址,设FN为0。
准确率计算公式

精确率计算公式

召回率计算公式

F1计算公式

4.3 实验设计
文中实验分为四类:(1)系统运行速度指标实验。该实验在系统中编写了时间戳程序,以计算时间差的方法获取模块运行时间。由于系统运行时间易受到计算机软硬件环境等其他因素影响,该实验使用多次运行取平均值方法确定时间。(2)地址淘选算法准确性实验。该实验用于评价淘选工作是否将非标地址自动匹配的计算空间缩小了范围并仍使标准答案处于缩小后的计算空间中。该实验中设缩小范围后的搜索关键词仍在结果中的计算次数为TP;设缩小范围后搜索关键词丢失的计算次数为FP;设原地址在字典中无关键词的计算次数为TN,设FN为0。(3)系统整体自动匹配准确性实验。该实验在淘选实验完成之后,使用某自来水公司非标地址数据集,将系统整体自动匹配的计算结果与人工标注答案比较,得出实验结果。该实验中假设与人工标注的正确标准地址一致的非标地址数量为TP,与人工标注的正确标准地址不一致的非标地址数量为FP。假设人工标注中无正确答案的非标地址数量为TN,该实验中不设置将无正确答案地址做自动匹配,设FN为0。文中系统使用一级算法与二级算法组合的方法,设计了四组对比实验。(4)系统整体自动匹配泛化能力准确性测试实验。该实验在淘选实验完成之后,使用来自5个社会机构的泛化非标地址数据集,将系统整体自动匹配的计算结果与人工标注答案比较,得出实验结果。该实验分为四组,参数、实验方法与实验(3)相同。用于验证匹配方法的泛化能力。
4.4 实验结果
各项实验经过调试运行得到结果。系统运行速度指标实验结果见表1。地址淘选准确性实验结果见表2。系统整体自动匹配准确性度量指标实验结果见表3。系统整体自动匹配泛化能力准确性测试指标见表4。

表1 系统运行速度指标

表2 地址淘选算法准确性度量指标(自来水公司非标地址数据集)

表3 系统整体自动匹配准确性度量指标(自来水公司非标地址数据集)

表4 系统整体自动匹配泛化能力准确性度量指标(拓展到五类来自其他机构的非标地址数据集)
5 讨论与分析
5.1 系统运行速度指标分析
由表1可知,在查找总时间方面,方法一为38 368 s,该方法在五种方法中最耗时,主要原因是因为使用了词频淘选法。该淘选方法相比经验淘选法,牺牲了大量淘选结果空间来提高淘选准确率,在淘选步骤后的余弦相似计算也需计算更多的候选项,因此,会耗时更多,约2 s才能匹配一个非标地址。
方法二在方法一的基础上,加入了多线程技术,使用20线程同时计算地址匹配数据,因此,统计的耗时缩短为2 126 s。
方法三与方法四的1.6万非标地址匹配时间均为12 min左右,说明这两类方法每秒可为约23条非标地址提供自动匹配。方法三的查找时间为734 s,比方法四使用的时间725 s多了9 s左右,原因是方法三添加了余弦相似的混合方法,因此,计算量增加。方法五的查找时间为587 s,小于方法四所用时间,其实质是因为减小窗长引起了向量空间维度的重叠,将原本应属于不同维度的向量基合并到了一起;向量空间维度的降低使得查找范围缩小,查找时间缩短,但严重降低了准确率和精确率。
5.2 面向自来水公司非标地址淘选算法准确性度量指标分析
由表2可知,面向自来水公司非标地址的经验淘选法其准确率、精确率和F1值分别为99.57%、99.43%和99.72%,表明基于经验的地址淘选方法具有较高的准确性。而单个关键词对应最大地址数为15 000,表示通过对非标地址的一个关键词查找后,可以将95万条待选标准地址缩小到15 000以内,理想情况下,单关键词查找范围至少缩小了63倍。
由于经验淘选法在缩小查找范围时丢失了部分的正确匹配项,在系统地址匹配环节行引入了误差,因此设计词频淘选法,该方法能够在淘选时保留所有正确匹配项。相比经验淘选法,词频方法扩大了结果的查找范围,但仍具有一定的缩小查找范围的能力。由于保留了所有正确匹配项,词频淘选法的准确率、精确率、召回率和F1值均为100%。而单个关键词对应最大地址数为45 000,表示通过对非标地址的一个关键词查找后,可以将95万条待选标准地址缩小到45 000以内,理想情况下,单关键词查找范围至少缩小了21倍。
5.3 面向自来水公司非标地址的系统整体自动匹配准确性度量指标
方法一:以词频淘选法为基础,使用步长为1、窗长为2的词向量切割方法搭配余弦相似算法和余弦相似混合方法,所得结果的准确率和精确率分别为97.95%和97.35%。方法二未使用方法一中的淘选方法,改用经验淘选法,其他与方法一相同,所得结果准确率和精确率分别为98.32%和97.82%;方法二对比方法三,由于加入了余弦相似混合算法,准确率提高了8.26%,精确率提高了10.66%,改进明显。
方法三:以经验淘选法为基础,使用步长为1、窗长为2的词向量切割方法搭配余弦相似算法,所得结果的准确率和精确率分别为90.06%和87.16%。对比方法四:步长为1、窗长为1的计算方法的准确率和精确率为42.85%和26.15%,可知增加词向量切割窗长可大幅提高准确率和精确率。窗长为1时计算两个词向量的相似度,原本应为不同维度的向量基互相产生重叠,使得向量空间的维度减少,最终导致准确度和精确度严重下降。而方法一增加一个窗长长度,使得向量空间的各向量基保持在自己的维度上,不会互相重叠和影响,因而能得到较高的准确率和精确率。方法三的F1值为93.13%说明该相似度计算方法具有一定的可用性,而方法四的F1值仅为41.46%,说明该参数的相似度计算方法可用性很低。
5.4 系统整体自动匹配泛化能力准确性测试指标
由表4可知,在拓展到五类非自来水公司机构提供的非标地址数据集上实验时,除了采用词频理论的方法一能够保持性能稳定,F1值达到98.33%之外,表中其他采用经验法的各项方法性能指标与表3相比显著下降。说明这些方法泛化能力不佳,可能存在过拟合现象;而方法一在某自来水厂提供的非标准地址和其他5个社会机构地址的表现和性能一致,说明基于词频理论的算法具有良好的准确性和泛化能力。
6 结语
文中提出了一种建筑非标地址标准化自动匹配模型,主要包括标准地址建模和非标地址匹配两个步骤;使用标准地址词典、地址淘选、地址相似度计算等方法,完成非标地址与标准地址的匹配。实验结果表明,基于词频理论所构建模型在准确率和泛化能力方面表现突出,已经能够达到实用要求;但计算速度还有待提高。下一步研究方向:(1)将模型实现移植到高性能云计算平台,采用分布式计算架构,提高模型计算速度,为实战应用提供基础支撑;(2)将深度学习方法引入到地址匹配过程中,提升非标地址语义级别的处理性能。
猜你喜欢
设备管理与维修(2022年21期)2022-12-28 07:33:34
新高考·高一数学(2022年3期)2022-04-28 07:02:46
园林科技(2021年3期)2022-01-19 03:17:48
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
制造技术与机床(2019年7期)2019-07-22 03:42:48
石油化工建设(2018年3期)2018-11-30 02:03:08
项目管理技术(2016年8期)2016-05-17 05:39:19
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
读者·校园版(2015年7期)2015-05-14 13:11:40
