
基于多模态身体行为信息融合的学生学习兴趣分析方法研究
2019-11-22 05:47:22任婕
仪器仪表用户 2019年12期
任 婕
(北方工业大学 信息学院,北京 100144)
0 引言
在当前的教学领域中,评价者不能简单地凭借学生的成绩或者调查问卷去分析学生对课堂的学习兴趣,需要综合考虑学生在学习过程中的多种行为表现,从而为课堂中学生的参与意识和投入程度提供有效的改进意见。
学生的学习兴趣可以通过身体行为体现。课堂中的身体动作,往往能直观反应学生上课的专注程度。而身体动作又可以分为很多种,譬如对举手特征动作的识别,趴桌子特征动作的识别,托腮特征动作的识别,低头特征动作的识别,写字和正坐特征动作的识别。
根据获得的身体行为数据,可以把一个课堂环境下的学生在某段时间的身体行为数据转化为一个一维向量。由于随机森林在解决小样本非线性分类问题中所表现出的分类效果极佳,同时随机森林可以解决分类、函数拟合等其他机器学习问题的特性,所以本文决定采用随机森林算法对所得到的向量进行训练并对参数进行调优,训练得到一个可以分类学习状态的分类器,最终通过多模态信息融合得到结果。
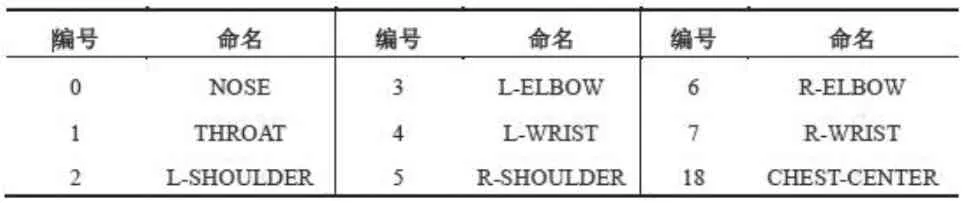
表1 身体躯干关节点的编号及命名Table 1 Number and name of trunk nodes

图1 课堂环境数据采集示意图Fig.1 Schematic diagram of classroom environment data acquisition
1 身体行为数据集构建
数据集收集是身体行为分析的基础,以往数据集的收集过程都是参与者自己表演、重现和互动的,只有比较少一部分的数据集是自发的,而且并没有一个数据集是用来专门针对课堂环境中的[1]。因为本研究是区分课堂上身体行为的动作状态,所使用的数据集也必须是来自正在上课时的学生的身体行为数据。在实验视频录制方面,该项目采用的是海康威视的DS-2CC597P 超宽动态针孔摄像机,输出设置为1080p、28fps 的实时图像。
整体有25 名学生参与了这次课堂行为数据的录像——6 名女生和19 名男生。首先保证他们都没有参与到本次论文的研究过程与方法中。这25 名参与者都是横跨中学到大学的学生,年龄在9 岁~23 岁之间。在大量的录制与分析后,研究成员收集了这25 名参与者中50 段举手、趴、托腮、低头玩、写字和正坐的身体行为视频(收集的每个参与者的片段数都是不固定的)。在数据集中,这6 种状态的身体行为剪辑的平均时间长度略多于6s 左右。
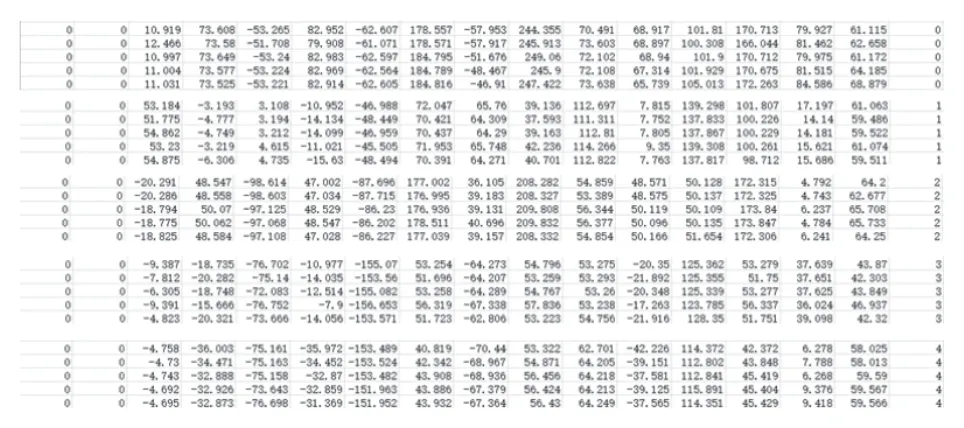
图2 归一化后的数据集Fig.2 Normalized data set
对于收集到的每个片段,研究者将每一个视频数据的片段进行分割,然后对这些视频数据进行标注,这样就完成了对数据集的构建。
2 身体行为识别数据的预处理及特征提取
本研究采用Openpose 去实现特征点的提取,Openpose可以同时追踪捕获多个用户的身体躯干关键点坐标信息。本文将获取的关节点二维坐标信息作为原始数据,每个关节点的空间坐标彼此独立。利用这些关节点坐标数据来构造单帧图片的人体全局特征,再根据所采集的身体动作进行描述[2]。按照本文任务要求,课堂环境和实验设备的设定,胸部以下部位是采集不到肢体坐标信息的,如图1 所示。去除8 号~13 号坐标信息,另外根据1 号坐标x 坐标值不变,y 轴正方向增加200 像素距离作为一个新增点18坐标信息,用于后续行为特征的提取。对应关节点名称详情见表1。
提取关键点坐标之后,以鼻尖作为原点进行归一化,并将归一化后的数据打入标签放入csv 文件中。其中,标签0 为举手、1 为趴、2 为托腮、3 为玩手机、4 为写字、5为正坐,如图2 所示。
3 分类
本文分别对Sigmoid 核函数支持向量机、多项式核函数支持向量机、线性和函数支持向量机、径向基核函数支持向量机、决策树、随机森林等6 种常用的机器学习分类算法对学生课堂行为进行分类。最终结果表明,使用随机森林算法具有最高的分类准确率89.36%,也说明了本文提出的学习状态识别分类方法的有效性。在后续实验中发现,虽然svm 方法中有两类核函数支持向量机对样本测试准确率很高,但对新数据分类结果并不理想,两类方法对样本数据产生过拟合,泛化能力较差,故采用随机森林分类方法。
4 多模态信息融合
4.1 融合方法
就现在的科技水平和研究方法来说,多模态信息融合方式从数据上来讲,可以分为3 个方向:数据级融合、特征级融合、决策级融合。决策级融合是最高级别的融合,该级别的融合是指在已经拿到由相应分类器得到的初步识别结果后,综合各方结论数据,通过规则的方法再进行决策的过程,该级别对应的就好比是公司的决策者。在这3种融合方法中,只有决策层融合能对不同的特征选其相对应的分类器,有更好的准确性和灵活性。身体行为的数据来自于对教室视频监控数据的分析,根据视频数据在分类器中得出的分类结果,将最终的融合因素分为6 层,对于身体行为的6 个融合因素进行层次分析法的决策融合后,去估计学生的兴趣程度。
同时,基于以上身体行为的多模态信息融合思想做以下定义:
一般地,令D={x1,x1,…,xm}表示包含m 个示例的数据集,每个示例由6 个动作描述(例如举手、趴、写字、低头、正坐、托腮),则每个示例xi={Ai,Bi,Ci,Di,Ei,Fi}中,Ai是xi在A 属性上的取值。即,基于身体行为的多模态信息融合形式化表示为:
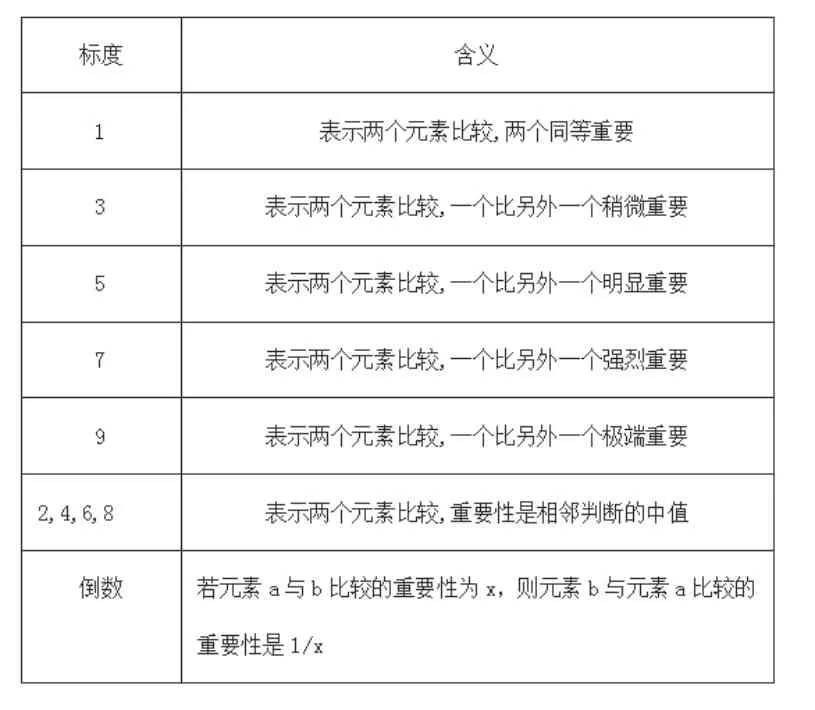
表2 重要性权重含义表Table 2 Significance weight meaning table

图4 层次分析法流程图Fig.4 Flow chart of analytic hierarchy process
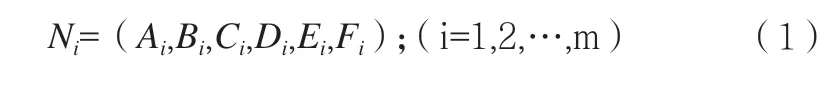
这里,N 表示身体行为信息融合的结果;m 表示融合对象的个数;A,B,C,D,E,F 分别表示融合对象i 的6 种融合因素。最终,基于身体行为特征的多模态信息融合得到的兴趣度,可定义为:
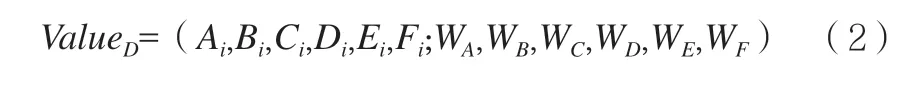
其中,WA,WB,WC,WD,WE,WF也就是将会在下文提到的权重。
4.2 权重分析
在基于身体行为的综合评价模型中,各指标权重的确定是其核心问题。因此,要实现综合评价信息的融合,首先要了解每个属性的影响度可由权重值来表示,权重大的即影响程度大,权重小也就代表影响小。而权重的确定方法可分为主观赋权法和客观赋权法。
主观赋权法中的层次分析法(Analytic Hierarchy Process)[3]是使专家决策者对照相对重要性的参照表2 给出指标两两比较的重要性等级,因而可靠性高,误差小,并且经该方法取得的最终结果具有一定的可遗传性,所以决定在权重分析中采用层次分析法。首先由专家对评价指标根据表2 进行两两比较,得到判断。构造了判断矩阵后,再由和积法求该判断矩阵的最大特征值和对应的特征向量。具体步骤如图4 所示。
按照上述步骤可分别求出学生身体行为属性的权重向量为:

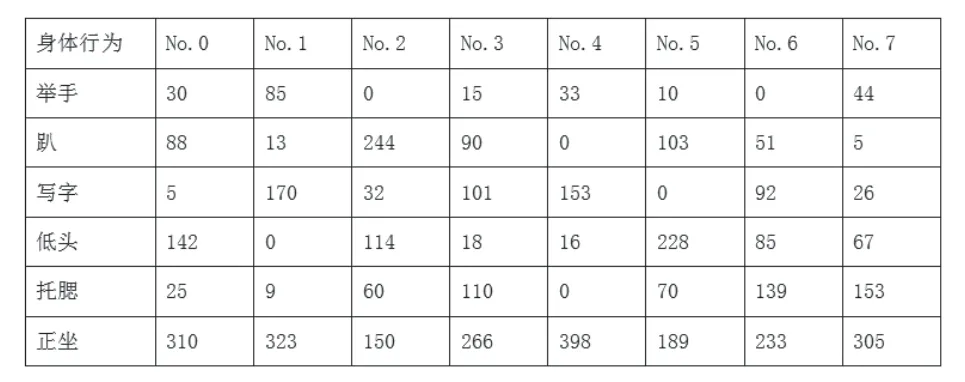
表3 身体行为时长检测结果Table 3 Test results of physical behavior duration
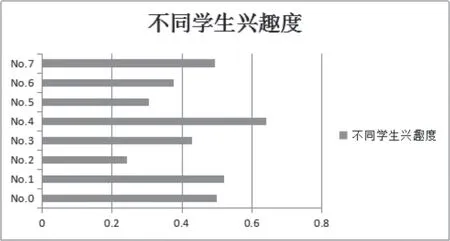
图5 基于本文方法得到的学生学习兴趣度分布Fig.5 Distribution of students' learning interest based on the method in this paper
5 结果分析
为了验证本文权重计算方法的合理性,以及学生学习兴趣度结果是否能真实反映学生的学习兴趣表现,本文以一段600s 的视频为例,跟踪整个视频中随机抽取的8 名学生的6 种身体行为动作时长(单位:s)见表3。
根据层次分析法得到的6 个身体行为动作的权重关系见表4。
基于文本分析法的身体行为特征融合结果如图5 所示。
最后根据兴趣度具体值的整体分布,取0.4 为阈值,将大于0.4 的归为有兴趣,小于0.4 的归为不感兴趣。再将基于以上算法得出的检测结果分别与自我评价是否感兴趣的客观真值和教师评价学生是否感兴趣的客观真值进行比较[4],从而计算出本文方法与这两个值比较的比较结果见表5。

表4 权重关系Table 4 Weight relationship

表5 兴趣分类识别率(%)Table 5 Interest classification recognition rate (%)
这个表可以很直观地说明通过本文的数据提取以及分类器分类再经过一系列的计算所得到的反映学生在课堂环境中兴趣程度的结果是非常有效并且实用的。
6 结论
首先,本文对教学中学习状态识别的基本思想进行了介绍,详细论述了教学中学习状态识别的特点并论证了可行性。其次,本文介绍了教学中反映学习状态的特征动作,定义了6 种特征动作并叙述了6 种特征动作的识别方法,从而得出了分类器的识别准确率。并经由综合评价信息融合以及层次分析法确定权重。最后,结合实验结果分别与自评和教师评价的客观真值进行比较,同时验证了本文权重计算方法的合理性。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
小学阅读指南·低年级版(2021年4期)2021-04-20 03:56:27
当代陕西(2020年17期)2020-10-28 08:18:18
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
人大建设(2018年5期)2018-08-16 07:09:00
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
电信科学(2017年6期)2017-07-01 15:44:57
小天使·一年级语数英综合(2017年6期)2017-06-07 23:38:11
大灰狼(2016年9期)2016-10-13 11:15:26
