
面向知识库问答的实体链接方法
2019-11-18 02:44:08李慧颖
中文信息学报 2019年11期
赵 畅,李慧颖
(东南大学 计算机科学与工程学院,江苏 南京 210000)
0 引言
近年来,知识图谱(knowledge graph)作为一种新型的知识库,成为计算机科学领域的热点。知识图谱通过资源描述框架(resource description framework,RDF)标记Web资源,只保留非结构化文本中的结构化信息,所有数据以三元组的形式存储。目前国内外已经有一些较为成熟的知识图谱,其中面向英文的有Freebase[1]、DBpedia[2]、YAGO[3]等,面向中文的有Zhishi.me[4]、CN-DBpedia[5]等。这些知识库在工业界有很多应用,比如基于知识库的搜索引擎系统,在指定的知识库中搜索结果;面向知识库的问答是知识库结合自然语言处理技术,实现自动问答的过程。过程中机器能够理解用户提问背后的语义信息,通过查询知识库,返回精确答案。
知识库中的信息是通过三元组的形式组织的,三元组形式为实体、关系和实体或字面量值。面向知识库的问答任务,首先解决的是实体对齐的问题,即将问句中的实体指称对应到知识库中的实体,其次是关系对齐,将问句中的关系映射到知识库的关系,最后根据实体和关系检索知识库得到精确的答案。
实体对齐即是实体链接,面向知识库问答的实体链接,即通过将自然语言问句中的实体指称映射到知识库对应的实体,赋予指称现实、明确的含义。实体链接需要解决自然语言问句中实体指称的一词多义和多词一义的问题,帮助理解自然语言问句的具体含义。实体链接可以划分为两个子任务,分别是候选实体生成和候选实体消歧。候选实体生成是前提,同一指称可以对应知识库中若干的实体。候选实体消歧的目的是从候选实体集合中找到最符合语句上下文语境的一个候选实体作为目标实体。实体链接是连接自然语言和知识库的重要途径,也是理解自然语言问句的必要条件。图1是解释实体链接过程的一个例子,左边的方框里是问句,实体指称已用下划线标记出来,问句上方是指称的相似实体指称,本文使用这些信息补充实体指称的背景知识,中间是候选实体集合,包括一些在知识库与实体指称同名的实体,右边是候选实体集合中的某一候选实体“New York City”对应在知识库中的表示,包括相邻近实体、实体类别和实体关系。实体链接就是根据这些信息,找到最符合问句语境的目标实体。

图1 实体链接示例
不同于基于文档的实体链接任务,知识库问答处理的是简短的自然语言问句,这些问句通常是由少数单词组成的短文本形式,因此对面向知识库问答的实体链接工作提出了新的挑战:
(1) 指称上下文的缺失。语句仅包含少数单词,不能提供充足的上下文辅助实体消歧;
(2) 绝大多数短文本只存在一个指称,因此不能使用实体联合消歧的方法;
(3) 结构化知识库中缺少实体的文本描述信息,难以表示知识库中的实体。
由于本文实验使用的是Freebase知识库,其没有Wikipedia[6]中关于实体的长短摘要和锚文本的内容,并且Freebase中关于实体的描述也很简短,不能全面描述该实体,很难借助知识库本身为候选实体提供更多的文本信息。但是Freebase的实体具有丰富的类型和明确定义的模式[7]。本文针对目前面向知识库问答的实体链接存在的挑战,分别扩充指称和候选实体的背景知识,以此弥补上下文不足的问题。本文通过语料训练得到问句指称的相似实体指称,作为问句指称的背景知识。根据知识库的特点,分别抽取了候选实体的类别、关系和邻近实体作为候选实体的背景知识,通过比较候选实体与指称的语义相似性,达到实体消歧的目的。
本文的主要贡献有:
(1) 通过Wikipedia语料训练得到相似的实体指称作为问句指称的背景知识,解决自然语言问句中指称上下文信息不足的问题。
(2) 根据目标知识库的特点,抽取候选实体特征,包括实体类别、实体关系和邻近实体,缓解了知识库对候选实体缺少描述性文本信息的影响。
(3) 组合多种特征,并比较它们的结果。
本文的组织结构如下: 第1节介绍了实体链接的相关工作;第2节介绍了实体链接方法,包括提出的四种特征,并分析它们的长处和不足,结合四种特征进行面向知识库问答的实体链接;第3节为实验结果分析;第4节是总结与展望。
1 相关工作
目前学术界已经有不少学者研究短文本的实体链接技术,并取得了一定的成果。实体链接分为候选实体生成和候选实体消歧,因此可以从这两方面来提升最后的结果。Wikipedia为生成候选实体提供了一些有用的特征,Guo等[8]通过从Wikipedia的实体页面、重定向页面和歧义实体页面提取出实体的字面表示形式,构造指称到候选实体的映射词典。另外也有专家利用搜索引擎生成候选实体集合。Tan等[9]人工标注从Wikipedia文章页面搜索到的与目标语句相似的句子,直接将标注出的实体作为候选实体。在指称精确匹配的基础上,Varma等[10]加入了部分匹配,Lehmann等[11]加入了模糊匹配的方式,用于提高候选生成的召回率。
当然,早期的实体链接论文中,也有很多工作更关注候选实体消歧部分。Bunescu等[12]提出了一种根据指称的上下文文本和候选实体的维基百科类别信息进行实体消歧的方法。本文认为直接计算指称上下文与候选实体描述文本的相似性会因为描述文本较短、不完整或同义词情况导致链接过程出现错误,所以本文把候选实体的类别信息也添加进来,与上下文信息一起参与消歧。Mihalcea和Csomai等[13]提出三种不同的排序方法包括TF-IDF、卡方相关性及关键词。通过三种排序方法的组合对候选实体进行排序。Dredze等[14]把指称看作查询,把候选实体集合看作查询结果,从而将实体链接任务转换成为信息检索问题,然后采用Learning to Rank方法将指称链接到最有可能的候选实体。Han等[15]提出一种生成概率模型,利用异构实体知识来消除候选实体的歧义。Barrena等[16]以新颖的方式从平行语料抽取指称的两种背景知识,以解决上下文不足和误导的问题。Yang等[17]通过学习多元回归树来拟合指称到实体的映射函数,并应用于推文实体链接的任务。Cornolti等[18]通过搭载网络搜索引擎引入SMAPH-2的端到端系统,联合命名实体识别和实体链接两个任务,这样可以减少噪声影响,找到最适合语境的目标实体。Cao等[19]提出了TremenRank的图模型,采用随机游走的方法传播置信度,这种情况适用于语句中有超过一个的实体。
2 实体链接方法
实体链接分为候选实体生成和候选实体消歧两部分,前者是根据指称找到知识库中对应的所有实体作为候选实体,后者是利用指称的上下文从候选实体集合中筛选出最符合语境的实体作为目标实体。
2.1 候选实体生成
对于已经识别出的指称,下一步是根据指称,产生对应的候选实体集合。为保证实体链接的正确率,必须提高候选实体集合的覆盖率,即是否包含目标实体,候选实体集合的质量对最终的链接效果相当重要。候选实体集合过小,容易遗漏目标实体;候选实体集合过大,影响实体消歧的效率。
数据集基于Freebase知识库,区别于Wikipedia和DBpedia的半结构化数据。Freebase中的实体统一用唯一的机器码表示,同时所有的数据以三元组的形式组织。因此,歧义词词典的构建实质是抽取知识库中包含实体名称属性的三元组。这里实体的名称属性指的是包含实体名称、别名、名称缩写等属性,如“type.object.name”表示实体的名称,“common.topic.alias”表示实体的别名。最后,根据指定的实体名称属性,从Freebase中抽取信息构建歧义词词典。在候选实体生成过程中,为了缩小候选集大小,利用实体流行度进行初步筛选,得到一个大小合适的候选实体集合。
2.2 候选实体消歧
对于结构化组织的知识库,往往会存在实体描述信息不全或缺失的问题,因此,需要通过其他特征来表示知识库中的实体。实体消歧的任务中,实体流行度是比较有力的一项特征,但是它表示的是实体与实体间的链接次数关系,仅从特定角度描述知识库中的实体。于是,本文根据知识库本身的特点,利用了知识库中的实体类别、实体关系和邻近实体以及通过语料得到的相似实体指称,最终得到三种特征,即实体流行度、基于问句的相似度特征和基于相似实体指称的特征。
2.2.1 实体流行度
流行度指的是实体在知识库中出现的频率,代表实体的热度。本文利用实体流行度对候选实体集合进行筛选,同时也将流行度作为一个消歧的特征。
由于知识库是结构化的数据,每条知识以三元组形式存储。假设一个实体流行度高指的是三元组中有更多的边指向该实体,可以使用实体的入度作为实体流行度。但是后来发现很多实体入度值较小,最终选择实体的出、入度之和作为该实体流行度,归一化后结果如式(1)所示。
(1)
其中,Sp表示实体在知识库中出现的概率,etarget表示目标实体,count是实体出入度之和,N表示知识库实体的数量。这里使用拉普拉斯平滑,防止目标实体在知识库中不存在而导致结果为0的情况。
值得注意的是,实体流行度是实体固有的数值属性,只能作为客观因素,不能直接与指称上下文匹配。而实体消歧目标是从候选实体集合中找到最适合语境的实体,流行度最高的实体并不一定就是目标实体。
2.2.2 基于问句的相似度特征
实体消歧是从候选实体集合选择最适合指称上下文内容的实体,也就是目标实体是与问句相似度最高的一个候选实体。比如下面两句话,“Jordan played three seasons for coach Dean Smith…”和“Jordan is currently a full professor at the …”,对于同样的指称“Jordan”,由于拥有不同的上下文内容,导致指向的是知识库中不同的实体。前者表示退役的篮球运动员;后者表示机器学习方向的教授。因此,指称上下文内容可以作为实体消歧的衡量标准。本文的目标知识库是Freebase,对于结构化组织的知识库,往往会存在实体描述信息不全或缺失的问题,因此,需要通过其他特征来表示知识库中的实体。于是,本文根据知识库本身的特点,使用实体类别和实体关系作为实体在知识库中的表示,并且分别计算与指称上下文内容的相似度,选择相似度最大的实体作为目标实体。
Freebase为每个实体提供了丰富的类别信息,图2是实体“New York City”的类别结构,这里只列举了部分类别。知识库中对实体类别分为两个层次,第一层是相对泛化的概念,第二层则细化为具体类别。第一层包含第二层的概念,比如图中的“film_screening_venue”作为“film”这个概念集合的一个元素。
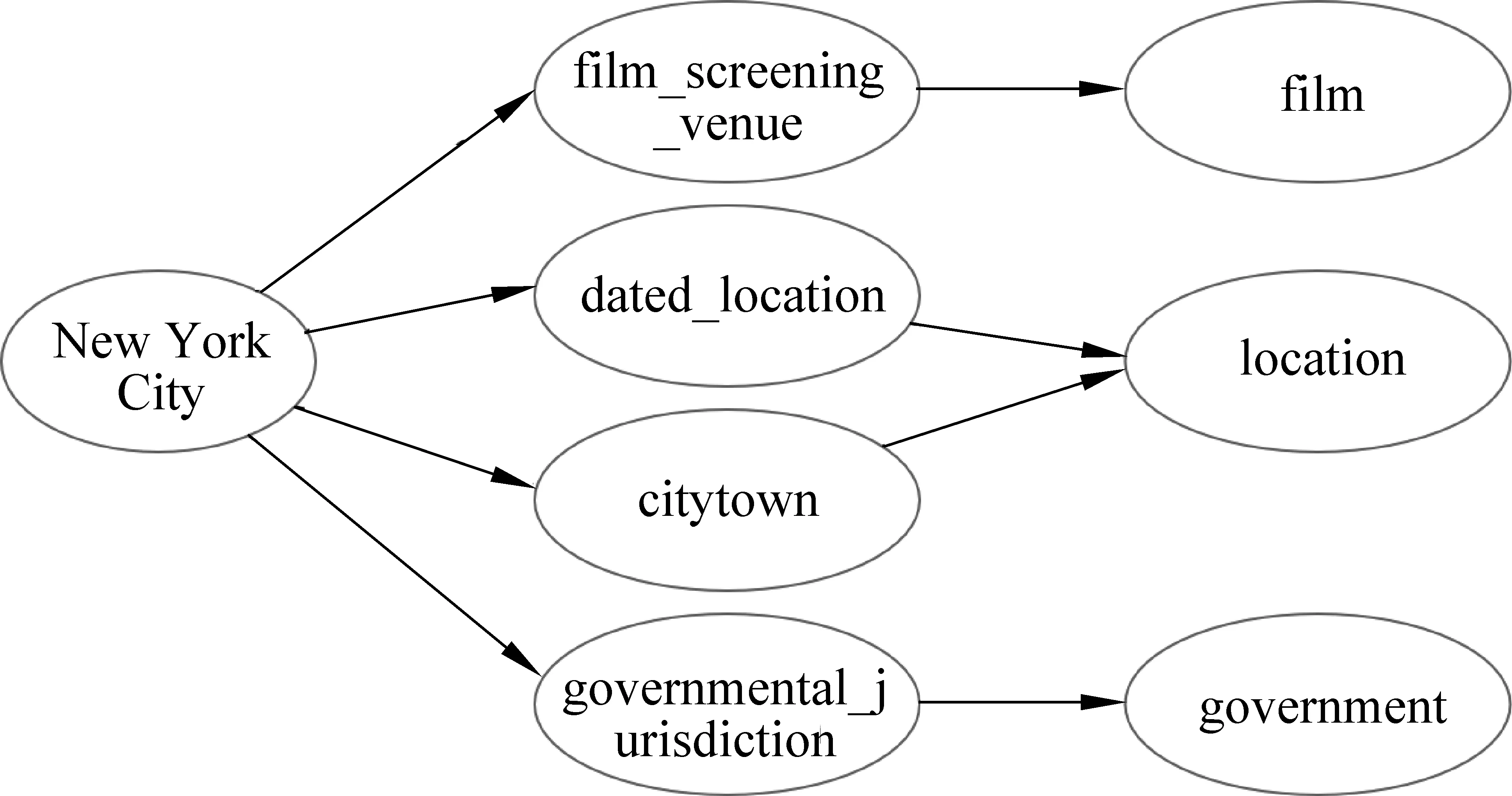
图2 实体类别结构
当问句提及到一个实体指称时,问句的内容极有可能出现与实体类别相关的词汇。因此本文将实体类别和指称的上下文内容间的相似度作为实体消歧的特征。实体类别的两层概念是包含与被包含的关系,同时将两层概念作为考虑的话,一方面会给实体类别的描述带来不少噪声;另一方面特征计算的复杂度较高。于是,本文仅保留第一层概念直接作为实体的类别。Freebase中的每个实体的类别相对丰富,不存在所有类型均相似于问句本身。因此首先分别计算实体每个类别和指称上下文间的相似度,取最相似的类别作为实体的唯一类别tfinal,St是根据最终选择的实体类别计算的得分,具体如式(2)、式(3)所示。
其中vecm指的是问句指称上下文的向量,通过所有词向量累加后的平均向量表示,tfinal表示最终选择的实体类别,Tj是候选实体j对应的所有类别,vecti是类别ti的向量表示。实体类别由“.”分隔,这里vecti是类别每个子部分的GloVe词向量累加后的平均向量表示。
面向知识库的问答过程包括实体对齐、关系对齐和知识库检索。实体对齐对应实体链接,即将问句指称链接到知识库,找到指称在知识库中对应的目标实体;关系对齐是根据问句提及的关系,将其对应到知识库中实体的关系;知识库检索是根据确定的目标实体和实体关系,按照条件限制检索知识库,返回答案。因此问句中可能会出现目标实体的关系名,相反实体关系可以辅助实体对齐,作为候选实体的另一特征。
一个实体在知识库中可能有很多关系,如果想通过关系来区分目标实体和其他候选实体,需要选择具有一定区分度的实体关系。符合指称上下文的关系对消歧的结果有辅助作用,但是更多的关系对于这个过程没有帮助,甚至起到负面作用。因此,本文通过比较候选实体的所有关系与指称上下文的向量表示之间的相似度,最终保留相似度最高的实体关系,Sr是实体关系这一特征最终的得分,详细的计算过程如式(4)、式(5)所示。
其中,rfinal表示最终选择的实体关系,Rj是候选实体j对应的所有关系,vecri是关系ri的向量表示。本文实体关系选择的是最细粒度的关系,关系由“.”分隔,这里vecri是关系每个子部分的GloVe词向量累加后的平均向量表示。
本节从问句本身出发,在充分利用实体指称的上下文内容的同时,考虑了问句的构成因素,即有一定概率会出现与实体指称同一领域(类别)的词汇,如包含“Michael Jordan”问句会出现“basketball”等。面向知识库的问答,通常是根据问句中出现的实体和关系,到找出知识库内对应的答案,存在答案的问句也会存在实体在知识库中的关系。因此,本文通过抽取候选实体的类别和关系,分别与问句进行相似度匹配,单独作为消歧特征。
2.2.3 基于相似实体指称的特征
短文本问句比较简短,作为指称描述信息的上下文内容不够充足,仅从候选实体与问句的相似度角度出发,容易误导实体消歧的过程。因此,还需要扩充问句实体指称的背景知识。本文借鉴面向文档的实体链接中常用的联合消歧的思想,通过其他语料得到当前指称的相似实体指称作为其背景知识。对于候选实体,则使用候选实体的邻近实体作为它的相似实体。结构化的知识库是通过从非结构化文本抽取实体和关系,组成知识库的结构化表示形式。因此实体的邻近实体,对应的是在语料中与该实体共现的其他实体,即如果某一候选实体是目标实体,则对应的邻近实体与问句中指称的相似实体指称相似性较大。通过比较候选实体集合中所有候选实体的邻近实体与相似实体指称的相似度,对候选实体排序,实现实体消歧。
相似实体指称的例子如图3所示,左边加粗的“Michael Jorden”是问句的一个实体指称,右边的“NBA”、“Chicago Bulls”等表示的是“Michael Jorden”的相似实体指称,它们表示与问句中的实体指称语义相似的其他实体指称。这里使用这些相似的实体指称作为问句实体指称的背景知识。
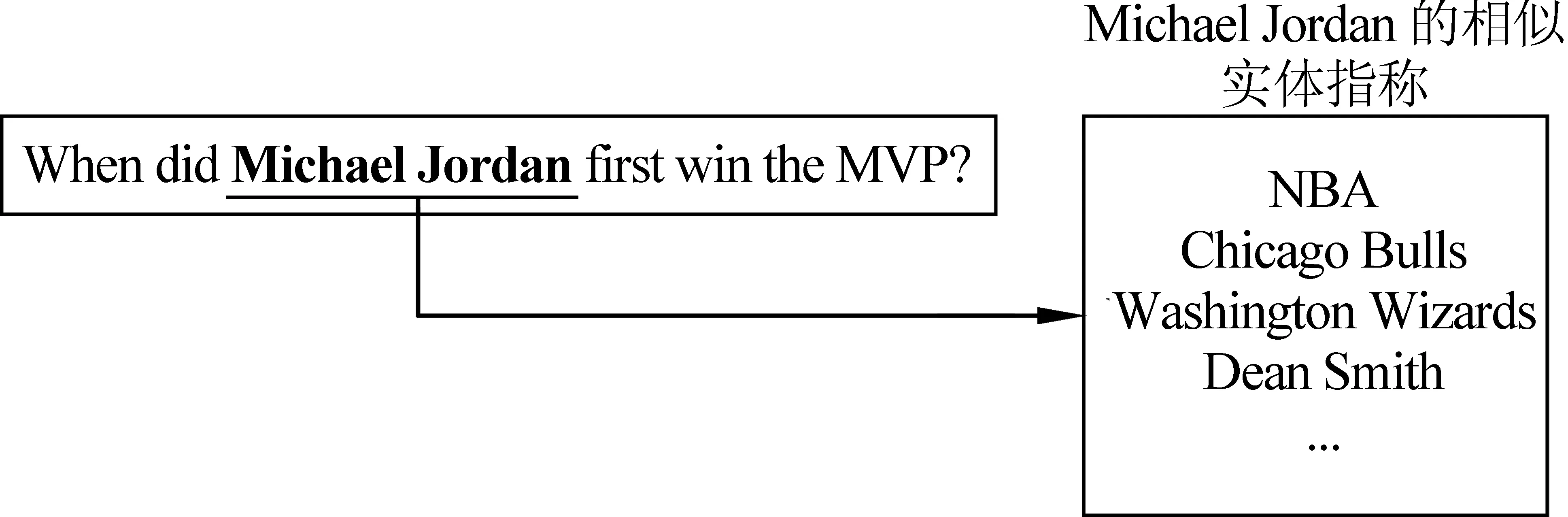
图3 相似实体指称样例
相似实体指称的生成语料是Wikipedia。首先标识出语料中的命名实体,将命名实体指称用下划线连接成整体,同时剔除语料中其他词,使用Gensim Word2vec 工具训练出实体指称向量。根据问句中的指称,通过计算其与语料中其他实体指称向量间的相似度,选择相似度最高的前S个实体指称。候选实体的相似实体选择的是知识库中实体一跳的邻近实体,同样为了避免部分相似实体指称的影响,这里先计算相似实体与相似实体指称的相似度,保留相似度最大的相似实体,如式(6)~式(8)所示。
其中,vecsim是问句指称相似的实体指称向量累加和的平均向量表示,实体指称的向量通过Wikipedia语料训练得到。Ej是候选实体j的邻近实体集合,efinal是最终选择的与vecsim相似度最大的邻近实体,Se指特征最终的得分。
2.2.4 特征组合
流行度是实体固有的属性,对于同名的实体,流行度高的实体更大概率是目标实体,这样一方面可以筛选候选实体集合;另一方面也可以直接作为候选实体排序的指标。考虑到结构化知识库的特点,实体详细的文本描述信息较少,因此分别通过将实体类别、实体关系和邻近实体作为候选实体在知识库中的表示。实体类别和实体关系包含实体的语义信息,以此与指称上下文进行语义匹配。另外,因为指称的上下文有限,通过语料得到指称的相似实体指称可作为指称的背景知识。这些相似实体指称与目标实体的邻近实体存在相关性,它们间的相似度信息也可以辅助消歧。
为综合考虑上面提到的四个特征,对其进行加权求和,根据最终的结果对候选实体排序,具体公式如式(9)所示。
Stotal=αSp+β St+γSr+δSe
(9)
式(9)中的α,β,γ,δ分别是对应各项的权重,由实验确定具体取值。加权求和是为了区别它们之间的差异,某一项表现结果更好,则考虑赋予更大的权重。
3 实验
3.1 数据集
实验数据集选择的是问答数据集WebQuestions-SP(WebQSP)[20],其包含WebQuestions数据集内有答案问句语义解析的结果,省去了命名实体识别的工作,可以直接使用问句标注的指称展开实体链接的研究。表1为数据集的数据统计情况。
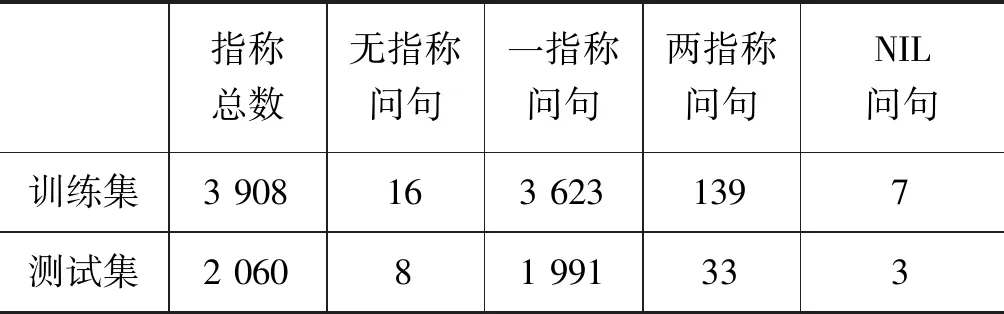
表1 WebQSP数据统计
从表1中可以看出,数据集99.6%的问句都只存在一个指称,很难使用联合实体消歧的方法。表中的NIL是指语句的指称无法链向知识库,在知识库内不存在这样的实体。由于WebQSP依赖Freebase知识库,所以本文选择Freebase作为实体链接的知识库。Freebase在2016年停止了提供API服务和维护,这里使用的是2015年Freebase的Dump数据。
3.2 评估准则
实验采用常见的指标准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-Score)来评估实体链接的结果。考虑到一条问句中会出现不止一个实体,因此这里采用的是宏平均F1值(MacroF1-Score)和微平均F1值(MicroF1-Score)作为实验结果衡量方法。
记正确链接为T,系统预测链接为O,Tent和Oent分别为正确链接到实体的指称个数,Tnil和Onil分别为正确链接到NIL的指称个数,各指标定义如式(10)~式(15)所示。
其中,F1i是第i个问句的F1值,Precisiontotal和Recalltotal分别表示计算数据集中所有问句得到的精度和召回率,Macro_F1,Micro_F1表示宏平均F1值和微平均F1值。
3.3 实验细节
3.3.1 候选实体生成
通过构建指称到实体的映射词典,产生候选实体集。为保证词典的覆盖率,根据象征指称的属性,从Freebase知识库中进行抽取,并且统计指称与实体共现次数。知识库中实体名称属性对应的宾语存在乱码和特殊符号问题,如“Don鈥檛Play Around”和“J$002EF$002EK”,本文直接删除包含乱码的三元组。对于特殊符号的问题,经过查阅资料,将编码转化为对应的符号,如上面字符串可以转义为“J.F.K”,其中“.”表示“$002E”。同时考虑到知识库中存在一些格式错误,例如,“c. b. colby”和“cb colby”,除了表示形式不同,本质上它们都是一样的。本文重新定义了字符匹配方式,考虑了误拼情况。最终词典的结构是一条指称对应多个实体,并且存储了指称与该实体共现的次数。
目前已经创建的指称到实体映射词典的词条数量达到20M。为了缩减搜索时间,通过Apache Lucene对词典建立索引,索引关键词是指称,返回的是所有的候选实体。因为很多指称对应的候选集较大,在消歧前,先通过实体流行度进行初步筛选,最终在确保候选实体数目不超过30个时,目标实体的覆盖率达到88%。
3.3.2 候选实体消歧
实体类别和实体关系直接与数据集中问句指称的上下文计算相似度,相似度高,表示候选实体更符合当前问句的语境。根据通常问句的构成,这两项特征对于区分出目标实体有一定作用。但是受到上下文的限制,以及实体类别和实体关系数目的选择问题,最终选择保留所有实体类别和实体关系,然后分别与指称上下文计算相似度,最高相似度对应的类别和关系为该候选实体的类别和关系得分。这样考虑主要有两点因素: 首先是候选实体的数量和其对应的特征数量不大;其次是选择部分特征或者选择所有特征的均值,会造成信息损失,同时也会引入噪声。实验证明,这样的做法对最终的结果有明显的提升。
3.4 实验结果及分析
下面根据上文提到的三类共计四种特征实现候选实体的消歧分别进行实验,实验结果如表2所示。其中,Sp、St和Sr分别表示实体流行度、实体类别与问句相似度、实体关系与问句相似度。对基于相似实体指称的特征,本文分别试验了基于词向量和基于实体指称向量的方法,用Se_word和Se_entity表示。基于词向量方法是指用指称中出现词的向量累加平均来表示该指标的方法。基于实体指称向量方法见2.2.3小节。
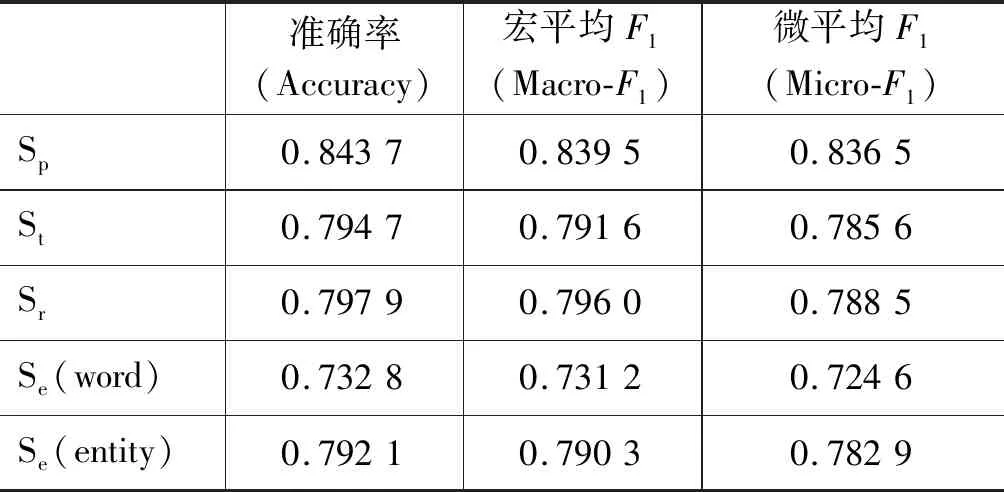
表2 独立特征的实验结果
WebQSP数据集是由Google Search API根据搜索实体名称得到的问题以及替换原问题中实体来构造数据集,而出现在搜索日志内的实体绝大部分都是相对热门的。因此,从单个特征的角度看,实体流行度对于实体消歧效果最好。
实体类别是考虑到数据集的问句中会出现与实体类别有关的限制性词,如“city”、“who”,这些词限制了目标实体的类型。但是有些情况问句中出现的限制词针对的是目标实体或问句的其他指称,如“who plays ken barlow in coronation street?”,修饰词“who”指的是前一个指称,当对“coronation street”进行消歧时,上下文中不存在对于该指称的类别限制,因此仅仅通过实体类别无法解决这类问题。
实体关系是从面向知识库问答的全局角度反向考虑而提出的对于目标实体的另一限制条件,即目标实体需要包含问句出现的实体关系。但是,由于一些问句中实体关系表述不明确,存在关系不在使用的Glove词向量中,实体消歧仅考虑实体关系仍然不够全面。如“who was vp for lincoln?”,这个问题中实体关系不明确,对于实体消歧没有帮助,并且非关系的词对结果有干扰,最终容易忽略目标实体。
面向知识库问答对应的答案是实体的邻近实体,本文目前仅考虑知识库中实体一跳对应邻近实体的情况。相似实体指称是问句指称的相似实体,在语料中的表示就是与指称共现次数多的实体。结构化的知识库中实体和实体关系都是从非结构化文本中抽取而来的。因此,本文将指称的相似实体指称和候选实体的邻近实体对应,通过这个指标辅助实体消歧。但由于训练实体向量语料大小的问题,最终实体向量的词典不能够覆盖所有实体,因此影响实验的结果。
相似实体指称是通过标注好实体的Wikipedia训练得到。为了验证实体向量的有效性,本文同时用基于词向量和基于实体指称向量的方法获得相似实体指称,结果如表2所示。实验证明: 使用实体指称向量方法效果更好。这是由于当实体指称是短语时,根据词向量找到的相似的词组合成的短语不一定表示一个实体,在与候选实体的邻近实体计算相似度时,会起到负面作用。
考虑到特征之间的联系,下面实验从特征的线性组合出发,分别考虑四种特征总体的效果以及单个特征对于整体结果的影响。表3中SAll指的是四个特征的线性组合的方法,下面内容表示SAll分别除去一个特征和除去两个特征后的实验结果。实验结果说明,组合所有特征的效果表现最好,实体流行度这一特征对结果相对影响最大。

表3 特征组合的实验结果
由于实体流行度单独作为特征的表现相对较好,因此包含流行度的三种组合方式结果比较稳定,较Sp结果略有提升。对比表格四、五、六行的结果,表示通过比较扩充的相似实体指称和候选实体的邻近实体间的关系,与实体类别和实体关系相比,具有一定的作用。当除去实体流行度这一特征后,表现相对它们三者单独作为特征后的结果有很大的上升。经过对识别错误文件的分析,除了目标实体不在候选实体集合的情况外,三种特征之间出错的问句交集较小,因此结果的显著提升可以认为是特征之间的互补关系。在两个特征的组合结果中实体流行度与其他三个特征的组合表现更好,其中与基于相似实体指称特征的组合效果最好。
本文与Qu等[21]的工作进行了对比实验,因为Qu的工作同时包含命名实体识别和实体链接。表3中分别列出了给定指称后的实体链接结果Qu_EL和用该方法进行命名实体识别后再进行实体链接的结果Qu_NER+EL。Qu的实体链接结果依赖于构建的歧义词词典,即生成的候选实体集合,但是本文只抽取知识库中包含“type.object.name”属性的三元组来构建词典,忽视了实体名称的其他变种形式,如首字母缩写、别名等。实验结果表明: 本文提出的方法表现更好。
4 总结与展望
本文分别从实体链接的两个子任务出发,详细介绍了面向知识库问答中实体链接的技术,重点在于实体消歧部分。由于结构化知识库对实体的文本描述信息较少,本文通过知识库中抽取的实体类别、实体关系和邻近实体来补充实体的上下文信息。同时由于知识库问答中问句指称上下文信息少,仅以此作为指称的上下文容易造成信息缺失。因此本文借助Wikipedia语料获取指称在语料中的相似实体指称,补充指称的背景知识辅助实体消歧。除了单独的特征外,最后考虑特征的组合对结果的影响。经过实验论证,上述提及的方法一定程度上提升了实体链接的结果。
未来可从两个大方向考虑改进,首先是可以通过模糊匹配等方法提升候选实体集合的召回率;其次是实体消歧部分的改进,如利用目前流行的ELMo[22]和Bert[23]方法学习向量的表示、考虑多跳的邻近实体、利用更大的语料训练词向量模型而得到更全面的向量表示等。
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
制造技术与机床(2019年6期)2019-06-25 10:17:46
电脑与电信(2018年12期)2018-03-23 02:37:20
海外华文教育(2016年1期)2017-01-20 08:21:58
中国交通信息化(2016年9期)2016-06-06 07:42:23
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
图书馆研究(2015年5期)2015-12-07 04:05:48
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
