
基于数值预测的数据处理与模型评估方法综述
2019-11-15 03:13张海洋张妍马策张丹丹谭鑫宋雪
卫星电视与宽带多媒体 2019年12期
张海洋 张妍 马策 张丹丹 谭鑫 宋雪

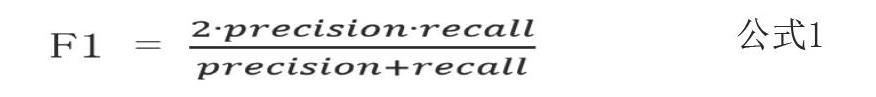
【摘要】数值预测问题,即为针对大量数据,利用机器学习的分类算法,对数据的各项特征间的关系,和各样本及对应的类别的映射关系,生成针对该数据的预测模型。不同的分类算法可建立不同的分类模型。本文针对生成模型的评估方法和对收集到的数据进行处理的方法进行简要介绍,最后提出一个完整的针对具体数值预测问题如何处理数据和如何选择最优评估方法的解决流程。
【关键词】模型评估;数值预测;数据处理;机器学习
项目来源:大连海洋大学大学生创新创业训练计划项目(项目编号为201810158152),辽宁省国际教育十三五科研规划课题:通信工程专业课程思政课程体系及教学方法研究(项目编号为18LNGJ042),大连海洋大学青年马克思主义者培养工程专项研究课题:“互联网+”背景下通信工程专业课程思政教育模式创新研究,大连海样大学信息工程学院项目。
1. 引言
针对实际问题生成预测模型,常需要以下4步:采集数据、可行性分析,数据预处理,训练并生成预测模型,模型性能评估。实际问题中收集到的数据往往不适合直接使用。需要人工进行数据预处理过程。而通过训练形成预测模型后还需要对生成的模型性能进行评估。下面分两部分分别介绍数据处理和模型评估的主要方法。
2. 数据处理方法
2.1 缺失值
通常情况下,收集到的数据大多含有缺失值,缺失值对于训练出的模型或多或少会带来影响。对于缺失值问题可采取去掉和补充两种方式解决。如果缺失值的样本占比较小,可以考虑直接删除带缺失值的样本。如果收集到的数据含有大量缺失值,删除这些样本会大大减小数据集的含量,所以需要填充缺失值。填充缺失值的方法包括:补插均值,使用固定值,最近邻补插,拉格朗日插值法和牛顿插值法等。
2.2 均值归一化与最值归一化
归一化的思想就是将所有的数据映射到统一尺度。在某些分类算法中,对于数据特征值天生就相对其他特征值明显相差很大的情况,如果不进行归一化,很有可能被误认为该特征对于预测结果影响权重较大,这会产生不正确的预测。对于有明显边界的数据特征值,受边界特征值影响较大,常采用最值归一化。但如果有新数据的加入,需要重新归一化。而对于数值波动不明显的数据,数据分布没有明显边界,常采用均值归一化方法。对于决策树算法,对样本每一个特征的阈值进行划分,无需考虑特征间的联系,所以无需进行归一化处理。
2.3 交叉验证
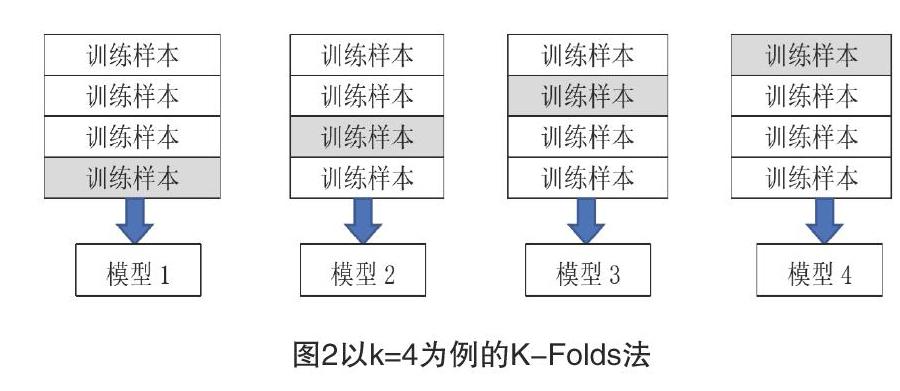
收集到的数据需要切分成训练集和测试集两部分。训练集用于训练模型参数并生成模型,测试集用于衡量模型性能优劣。为了能够充分利用收集到的全部数据。单纯的只按照一定比例切分全部数据是不划算的。故常采用交叉验证的方法,将全部数据分段划分,轮换作为训练集和测试集,充分利用到全部样本,使机器学习到更多的特征关系。为了更接近现实中无法获得测试数据集的均值和方差的情况,通常先对数据集进行划分,而后将测试集按照训练集的均值和方差进行归一化。划分数据集时主要可采用K-Folds交叉验证法(K-Folds Cross Validation)和LOO-CV(Leave-One-Out Cross Validation)留一法。对于K-Folds法以k=4为例,如下图2所示,将数据集均等分成4份,轮换一部分数据作为训练集和测试集,最后对生成的4个模型的均值作为结果调参。
但每次训练都会生成k个模型,运算量较大,生成时间较长。还有一种最接近模型性能的方法为留一法。留一法将有m个样本的数据集分为m份,将每一条样本作为测试集,其余的样本作为训练集,训练出m个模型,然后再综合考虑所有的模型参数,将m个模型的均值作为结果调参。该方法计算量巨大,但能够充分考虑每一条样本的特征,适合对模型精度要求高的问题使用。
2.4 数据可视化
在对未知问题进行可行性分析时,还可采用数据可视化方法,直观地查看数据样本与标签之间的联系。根据不同的数据分布,选择用不同的图形展示数据,如直方图,散点图,桑基图和河流图等等。对于机器学习的分类问题,数据样本与标签属于离散变量,通过绘制散点图和决策边界,可以直观显示出样本特征对于预测的影响;对于回归问题,数据样本与标签都是连续变量,常采用绘制折线图显示拟合曲线与实际标签的曲线的误差。对于数据包含特征数过多的情况,无法用二维或三维空间表示,可以采用绘制平行坐标图来显示。还可采用主成分分析法,将高维数据降至低维,并且还能去掉数据间的噪声。
3. 模型评估方法
对于给定的几组数据,人类无法直观的发掘每条数据及其类别间的关系,基于数值预测的思想,机器学习分类算法可以在给定足够的样本数据的情况下,解决许多实际的预测问题。针对不同的分类算法可生成不同的预测模型,该模型可以对给出的未知数据预测其对应的类别,而分析通过算法生成的预测模型的性能需要使用下面介绍的几种模型评估方法。
3.1 分类准确度与混淆矩阵
对于样本包含的类别数量在极度不平均的情况下,不能只根据准确度来评估模型,因为在某种样本对应类别数目很多的情况下,只看模型对于该类别的预测效果虽然是很理想的,但对于样本对应类别数目很少的样本预测效果就会很不理想。于是人们引入混淆矩阵的概念,更加全面的評估样本准确度,如表1。
针对不同的问题着重点不同,若是类似股票预测这样的问题,希望模型精准率要高;类似医疗诊断这样的问题,希望模型的召回率要高。综合来说,一个分类模型准确度高意味着精准率和召回率都要高。于是可用F1 Score指标衡量,如公式1:
F1 Score是精准率和召回率的调和平均值,F1 Score越大,分类效果越好。考虑到不同的阈值分类出的效果不同,引入FPR(False Positive Rate),TPR(True Positive Rate)作为两个坐标轴绘制出ROC(Receiver Operation Characteristic Curve)曲线来评估,ROC曲线所围面积越大,分类效果越好。
3.2 回归模型误差
对于线性回归问题,设测试集中第i个样本对应标签值为 将第i个样本输入到模型中后的预测结果为 可通过均方误差MSE(Mean Squared Error)评估模型,若考虑到预测样本标签的量纲与实际量纲一致,还需做开方处理,即均方根误差RMSE(Root Mean Squared Error)。当然也可利用绝对值衡量误差,即平均绝对误差MAE(Mean Absolute Error)。具体公式如表2。
由于均方根误差公式中使用了误差的平方,相对扩大了误差,故在实际使用中常使用均方根误差作为衡量线性回归模型的标准。对于线性回归模型还有一个更为科学的评估方法,即R Squared法,如公式2所示:
R2越接近1,说明模型分类效果越好,R2为0时说明模型等价于基准模型,即以样本平均值来分类的模型,R2小于0时说明模型不具有线性关系,需要考虑非线性回归的算法。
3.3 偏差与方差
模型的误差来源于模型偏差,模型方差与无法避免的误差这三方面。对数值预测问题的假设不正确,比如将非线性回归问题假设为线性回归问题来建模,这种错误的假设会导致模型出现偏差。欠拟合的模型通常会导致模型高偏差,过拟合的模型会导致模型高方差。如果数据出现微小的扰动,预测的结果会出现极大的偏移,这样的模型为高方差模型。高方差模型究其原因是因为模型太过复杂,例如高阶多项式回归模型。机器学习算法中的非参数学习算法都是高方差算法,因为不对数据进行假设,很容易造成过拟合。而参数学习都是高偏差算法,因为预先对数据进行了假设,例如线性回归模型。机器学习中的调参方法就是在模型偏差与方差之间做平衡取舍。大多数机器学习算法容易产生过拟合,而机器学习主要任务也就是在降低模型的高方差。关于解决高方差与高偏差的主要方法如下表3:
3.4 模型的泛化能力
模型评估中分为过拟合和欠拟合问题。算法训练生成的模型无法完整地描绘数据关系,则视为欠拟合模型。而生成模型中不光覆盖全部数据关系,还将数据的噪声也被认为是分类依据加入到模型中,这样的模型视为过拟合模型。大量实验结果显示,模型复杂程度越高,训练集上的预测准确率越高,而测试集的预测准确率越低,越容易产生过拟合,而欠拟合问题则恰恰相反。由于多层感知机的结构之复杂,虽然能很大程度提升预测准确率,但模型的泛化能力却相对差一些。模型评估很大程度上是在调整模型来抑制过拟合,提升模型的泛化能力。
4. 数据处理与模型评估主要流程
(1)判断收集到的数据中缺失值数量,数量大的使用近邻插值,牛顿插值等方法替换缺失值;数量小的直接去掉带有缺失值的样本。
(2)根据数据规模与具体需求,可采用K-Folds或留一法来对数据划分以用来交叉验证。
(3)判断训练出模型用到的算法是否是根据数据特征阈值来分类数据的数值预测算法,如果不是,则直接进入步骤(4),如果是则进入步骤(5)
(4)判断数据样本的特征值中是否有明显边界,如果是则使用最值归一化处理数据;如果没有明显边界则使用均值归一化方法处理数据。
(5)使用数值预测算法训练输入的样本数据,形成具体的预测模型。
(6)将测试数据集输入到模型中,根据预测模型是分类模型或回归模型来使用相应的评价指标评估模型,根据结果不断调整模型,以此得到最优解。
5. 结语
在机器学习任务中处理数据占据大量时间。模型性能的好坏,很大程度地取决于数据处理的好不好,数据量是否足够。可见拥有处理好的大量数据样本是解决机器学习问题的重要因素。机器学习的最终目的就是得到性能良好的模型,本文介绍了常用的模型评估方法与数据处理方法,提出一个有效的数值预测模型的数据处理和模型评估流程,该流程经过实践检验是科学有效的。数据处理方法和模型评估方法远不止这些,比如聚类模型的评估本文没有涉及,面对实际问题,具体采用哪种方法,需要根据工程师的知识储备和实际经验进行选择,而后试验评估模型的性能,并进行取舍,从而找寻能最大限度提升模型性能的处理方法。
参考文献:
[1]乔莹莹.基于数值预测的机器学习相关算法综述[J]..安阳工学院学报,2017,(4):71-74
[2]王宏志.工業大数据分析综述:模型与算法[J].大数据,2018,(5):62-79
[3]钟华明 梁玉楠 曾少军.数值预测算法比较研究. 信息技术与网络安全[J],2019,(1):44-48
[4]杨剑锋等.机器学习分类问题及算法研究综述.统计与决策[J],2019,(6):36-40
作者简介:张妍(通讯作者)(1977—),辽宁鞍山人,硕士,讲师,大连海洋大学信息工程学院,通信教研室主任,研究方向:电子线路教学与实践(116023)。张海洋,马策,张丹丹,谭鑫,宋雪为大连海洋大学信息工程学院学生。
猜你喜欢
计算技术与自动化(2022年1期)2022-04-15
科技创新导报(2021年33期)2021-04-17
科学导报(2020年22期)2020-04-21
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
电子技术与软件工程(2016年24期)2017-02-23
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
数字技术与应用(2016年9期)2016-11-09
