
基于迁移学习的文学人物心理分析
2019-11-15 10:20韩诺关增达杨莉朱廷劭
心理技术与应用 2019年10期
关键词:迁移学习
韩诺 关增达 杨莉 朱廷劭
摘 要 近年来,随着计算机自然语言处理以及机器学习技术的日愈成熟,利用网络行为预测用户的心理特征逐渐成为跨学科的研究热点,一些学者也随之开始研究利用人工智能方法建立文学人物心理预测模型。目前的文学智能分析使用微博数据建立的预测模型来对文学人物进行分析,这与文学作品中的场景存在差异。本文将迁移学习引入文学智能分析,针对英国文学家毛姆笔下的文学人物的心理特征进行预测,结果发现迁移学习模型使文学人物的心理预测效果有所提升,表明了迁移学习在文学人物心理分析模型中的有效性。
关键词 迁移学习;文学人物心理预测模型;毛姆小说
分类号 TP391
DOI: 10.16842/j.cnki.issn2095-5588.2019.10.005
1 引言
文艺作品中的人物心理过程与人格形象塑造是文学创作、评价的核心,由于其主观性和复杂性,以往研究大多以文学评论或哲学思辨为主。由于文学人物是虚拟的或理想化的,基于自我报告的测量方法难以对文学人物进行施测,而传统的对文学人物进行的性格分析以定性方法为主,本文提出利用机器学习方法,在既有研究的基础上,提高对文学人物心理特征自动识别的准确度,从而达到预测文学人物心理的目的。
近年来,随着计算机自然语言处理以及机器学习技术的日愈成熟,利用网络行为预测用户的心理特征逐渐成为跨学科的研究热点,国内外研究者基于社交媒体内容与大五人格表的映射关系对Facebook用户、Twitter用户与微博用户等进行人格预测的技术也日愈成熟(Li,Li,Hao,Guan, & Zhu, 2014)。大五人格模型是研究者通过词汇学方法,总结了可以涵盖人格描述所有方面的五种特质的人格模型,包含对宜人性(Agreeableness)、尽责性(Conscientiousness)、开放性(Openness)、外向性(Extraversion)与情绪性(Neuroticism)五种特质的分析(John, & Srivastava,1999)。
利用生态化行为数据,使用机器学习方法对个体心理特征进行自动识别的方法稱为生态化识别(ecological recognition,ER)(吴育锋,吴胜涛,朱廷劭,刘洪飞,焦冬冬, 2018)。采用基于生态化识别的文学智能分析,对文学人物进行心理分析被证实是有效的,然而也存在着一定的不足(Liu,Wu,Jiao,Wu, & Zhu, 2018)。由于文学智能分析系统建立在使用网络海量数据进行人格预测所搭建的模型之上,文学人物对白与当代微博文本存在着语用和语言演变带来的差异,而这些差异很难通过增加人格预测模型的训练数据来解决。因此,本文引入迁移学习的方法,尝试对模型进行优化以达到更好的文学人物心理分析效果。
在早期的迁移学习研究中,Daume 等人提出将目标领域和源领域共同的特征,领域间各自独有的特征放到一个扩展的特征向量中,再进行训练的方法,此方法在自然语言处理问题的解决上取得了较好的效果(Daume, 2007; Daume,Kumar, & Saha, 2010)。戴文渊(2009)提出一种TrAdaBoost算法,即给定一个很小的源训练数据集,大量的辅助训练数据与一些未标注的测试数据集,使用Adaboost算法与Hedge算法分别增加源训练数据集的权重、降低辅助训练集的权重从而最终达到减少分类器分类误差的目的。Gupta等人提出首先寻找源领域与目标领域数据集合适的共同特征数,再将源数据矩阵与目标数据矩阵相乘求秩,以秩的大小来确定共同变量个数的思想(Gupta, Phung, Adams, Tran, & Venkatesh, 2010)。Pan等人提出将最大均值差异嵌入(Maximum Mean Discrepancy Embedding,MMDE)的方法,将源领域与目标领域的数据变换至新的特征空间,之后使用降维后得到的共同变量来训练分类器
(Pan, Kwok, & Yang, 2008)
。也可以在MMD方法中加入不同的内核,如高斯核(Gaussian kernal),Louizos等曾采用此方法用于特征间的迁移学习(Louizos, Swersky, Li, Welling, & Zemel, 2015)。
在近期的研究中,Ganin等在域对抗神经网络(DANN)中引入梯度反转层,从而达到使源领域与目标领域更为相似的目的(Ganin & Lempitsky, 2015)。Tzeng等人提出对抗性判别域适应(Adversarial Discriminative Domain Adaptation,ADDA)方法,目标领域与源领域数据相互独立,即不受权值约束,使用训练好的源领域数据集权重来建立目标领域模型(Tzeng, Hoffman, Saenko, & Darrel, 2017)。
上述迁移学习的研究均有一个相同的思想,即试图使源领域与目标领域具有相同的数据分布。因为一旦找到了两个领域间数据的映射关系,就可以使用源标注领域的分类器来划分未标记目标域。因此模型性能关键在于如何寻找源域与目标域数据间的映射关系。
由于本文对文学人物的对白处理与微博用户数据的处理过程一致,特征空间相同,而数据分布不同,此时需要将源领域与目标领域的数据集映射到一个共同的变量空间中。由于源领域数据集较为稠密,而目标领域数据集过于稀疏,恰当的稀疏可以使学习任务变得简单可行,并有助于提高预测模型的性能。本文选择使用字典学习(Dictionary Learning)方法来寻找源域与目标域间的数据映射关系,之后选择合适的回归学习方法来建立文学人物人格预测模型。因小说人物无法进行自我报告或者填写问卷,也无法找到熟悉他的人来对其进行评价,为保证实验的准确性,选取部分性格鲜明的文学人物作为心理分析对象,对模型进行评价。
2 方法
本研究中,源领域数据为微博用戶文本数据,包含用户的在线微博文本数据与用户的大五人格得分,以下称为源域数据。目标领域数据为英国著名小说家威廉·萨默塞特·毛姆的五部长篇小说《人性的枷锁》、《月亮与六便士》、《刀锋对话》、《面纱》与《寻欢作乐》中所出现的文学人物的所有对白内容,以下称为目标域数据。这些数据经过数据预处理后,分别得到源数据集与目标数据集。
2.1 数据预处理
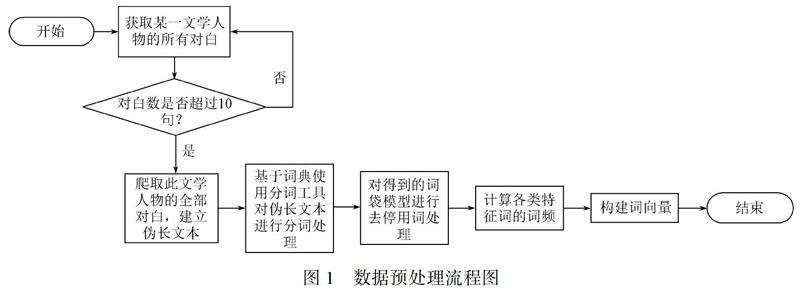
源域数据与目标域数据的预处理过程类似,以目标域数据预处理过程为例,数据的预处理过程如下:先提取各文学人物在小说中的对白,建立为长文本;再将SC-LIWC词典作为分词词典,使用中文“结巴”分词工具对长文本进行分词处理操作;借助哈尔滨工业大学停用词表进行去停用词处理;之后基于词袋模型,根据SC-LIWC词典的功能词计算各类功能词的词频;最后基于上述一系列操作,得到分别针对各文学人物的词向量。数据预处理流程如图1所示。
2.2 模型建立
本文将迁移学习应用于文学人物的心理分析,以期提高预测的准确度。为此,本文首先建立基于微博文本数据的人格预测模型,使用此人格预测模型对文学人物对白进行分析,得到文学人物的大五人格分数。之后在此人格模型基础上引入迁移学习,得到迁移后的预测模型预测的大五人格分数。最后将前后得到的分数进行比较,验证迁移学习是否在文学人物心理分析方面具有一定的有效性。
2.2.1 人格预测模型的建立
(1)过滤离群点
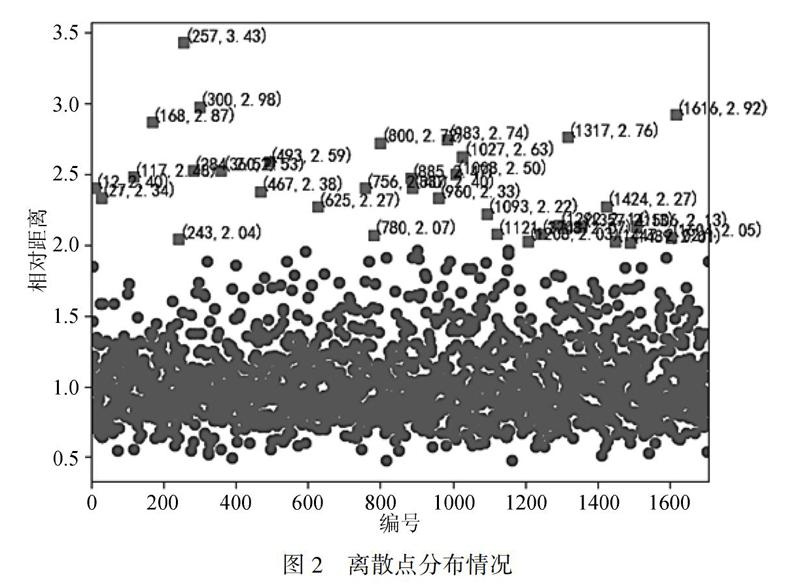
在进行数据分析时,本研究将那些明显偏离其他数据、不满足数据的一般行为或模式、与存在的其他数据不一致的点称为离群点。为保证模型的稳定性与准确性,在训练模型前首先进行离群点过滤工作。
本次试验选择K均值聚类算法来过滤离群点。K均值聚类算法是一种迭代求解的聚类分析算法,首先选取N个对象(N=3)作为初始的聚类中心,接着计算每个对象与各个种子聚类中心之间的距离,并把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。本研究将离散点阙值定为2.0,即距离聚类中心超出2.0的点为离散点。将离群点及其所对应的标注过滤后,得到新的源数据集。聚类情况如图2所示。
(2)逐步回归降维
在现实任务中经常会遇到维数灾难问题,这是由于属性过多造成的,如果可以从中选择出重要的特征,使得后续学习过程仅需在一部分特征上进行模型构建,那么维数灾难问题将会大为减轻。此外,去除不相关特征可以降低机器学习的难度(周志华, 2018)。
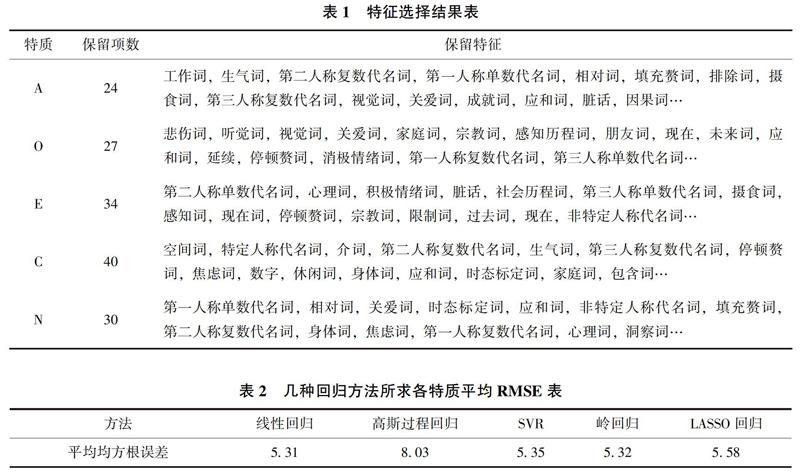
鉴于源数据集过滤离群点后,分析对象为1672个,而特征项有76项,此时特征项较多而数据量较少,易出现过拟合问题。因此在分析对象过滤离群点后,对得到的新的带标注的源数据集进行特征选择。本次实验选择线性逐步回归法进行特征选择。各特质所对应的特征选择的部分结果如表2所示。
(3)训练回归预测模型
在过滤离群点与特征选择后,开始训练回归预测模型。为使文学人物智能分析系统的预测效果更为准确,同时排除最终结果对比时除迁移学习外其他因素影响,本研究先后使用线性回归、高斯过程回归、支持向量回归(Support Vector Regression,SVR)、岭回归(Ridge Regression)、LASSO回归等方法分别训练人格预测模型并使用五折交叉验证方法,通过求得各个模型五个特质的平均均方根误差RMSE来对各回归方法建立的模型进行评估,选择效果最好的方法用于模型最终的建立。几种回归方法所建模型的均方根误差如表2所示。
经比较发现,使用线性回归方法训练人格预测模型的平均均方根误差较小,即模型拟合效果更为良好。因此,此次实验使用逐步线性回归法训练文学人物心理分析模型。各特质预测值与真实值分布散点图如图3所示。
2.2.2 建立迁移学习模型
基于上述建立的人格预测模型,本文建立了基于迁移学习的文学人物人格预测模型。鉴于源域数据集较为稠密,而目标域数据集过于稀疏,此时应令数据集分布恰当稀疏,从而可以使学习任务变得简单可行,并有助于提高预测模型的性能。基于此思想,本文选择使用字典学习方法来寻找源域与目标域间的数据映射关系。基于迁移学习的文学人物心理预测模型建立过程如下:
(1)对源数据集进行过滤离群点处理,得到不含离群点的源数据集;
(2)对源数据集与目标数据集分别进行特征选择,去除冗余特征项,得到源数据集与目标数据集;
(3)使用源数据集进行线性回归,得到人格预测模型;
(4)基于源数据集进行字典学习,得到字典,之后使用稀疏编码(Sparse Encoding)算法得到映射到源域的目标数据集;
(5)使用人格预测模型对目标数据集进行预测,得到文学人物的大五人格分数。
3 结果
通过阅读各类文学评论(李晓涵, 2018;苏虹蕾, 2016;万丽君, 2017;王落茹, 2018;刘豆, 2016),本文选取毛姆的代表作《月亮与六便士》中,性格较为鲜明的主人公查理斯·思特里克兰德、好友戴尔克·施特略夫以及第一任妻子思特里克兰德太太为分析对象。
本研究所应用的大五人格问卷为O. John的44道题大五人格问卷。其中,外向性、情绪性满分为40分,当得分小于22分时,此特质有偏弱的表现,当得分大于28分时,此特质有偏强的表现;宜人性、尽责性满分为45分,当得分小于25分时,此特质有偏弱的表现,当得分大于31分时,此特质有偏强的表现;开放性满分为50分当得分小于21分时,此特质有偏弱的表现,当得分大于34分时,此特质有偏强的表现。
猜你喜欢
文学教育(2018年7期)2018-07-17
智能计算机与应用(2018年2期)2018-05-23
现代交际(2017年18期)2017-09-11
振动工程学报(2017年1期)2017-04-21
现代电子技术(2015年14期)2015-07-22
