
基于深度多监督哈希的快速图像检索
2019-11-12 05:02郁延珍
计算机应用与软件 2019年11期
郁 延 珍
(复旦大学计算机科学技术学院 上海 201203)
0 引 言
随着大规模图像检索需求的日益增加,为了解决使用实值特征进行图像检索效率较低的问题,哈希方法开始被用来将高维的图像数据映射到紧凑的二进制编码空间,产生可以近似地保留图像原始空间信息的哈希码[3-5]。在基于哈希的图像检索中,图像由二进制码而不是实值特征表示,检索的时间和空间开销都大大降低,因而能够在数据库中更快地检索到用户所需要的图像信息。
近年来,随着深度学习理论的飞速发展,以卷积神经网络(Convolutional Neutral Network,CNN)为代表的多种神经网络在诸如图像分类[6-8]、物体检测[9]、人脸识别[10]以及其他视觉任务[11-12]领域不断取得突破。这些任务的成功表明从CNN上学得的特征可以很好地捕捉到图像的潜在语义结构信息。
1 相关工作
深度学习理论的飞速发展及其在众多领域的成功应用,向我们证明了CNN网络的强大学习能力。然而,主流的深度学习方法往往使用较高维度的特征,这极大地增加了图像检索的时间和空间开销。为了提高检索的效率,哈希方法,如LSH[19]开始应用于图像检索领域,哈希特征的使用大大降低了图像检索在空间和时间上的开销。然而,哈希方法的检索准确率往往取决于它们所使用的特征,而手工编码的特征只能编码线性特征,无法捕捉图像的深层语义信息。
最近,很多基于卷积神经网络的哈希方法被提出,如文献[1-2,14-15,23,26-27],用来解决快速图像检索的问题。这些方法表明:深度卷积神经网络可以有效地编码非线性函数,图像特征及其对应的哈希函数都可以通过深度卷积神经网络学习得到。
文献[2]通过挖掘深度卷积网络中的一个隐藏层来代表决定图像标签的隐藏信息,并通过哈希得到了可用于大规模图像检索的特征。文献[23]通过挖掘图像对之间的相似性矩阵来学习哈希编码。文献[1]利用图像的相似信息训练网络并提取特征,将求特征和哈希结合在同一个网络中,避免了二次优化的问题。文献[14]通过将CNN卷积层的特征进行组合,将图像的局部特征应用于尺度变化的图像实例检索并取得了较好的效果。在人脸识别领域中,DeepID2[13]首次将人脸的分类信息和验证信息联系在一起,通过扩大类间的距离并减小类内距离大大提升了人脸识别算法的准确率,但是这些方法存在以下缺点,从而限制了检索准确率的提升:
1) 只使用了分类信息和验证信息的一种;
2) 没有考虑数据不平衡的问题。
本文将图像表示和哈希方法结合起来,提出了深度多监督哈希DMSH,该方法从特征和哈希两个角度来入手,使用多监督信息来对网络进行调整,从而获得更优的哈希特征。实验表明,该方法比目前主流的方法检索效果更好。本文工作的贡献主要如下:
1) 提出了一个深度多监督网络模型(DMSH)来学习哈希编码,使样本之间的非线性关系可以被有效编码。
2) 采用多监督的方式,同时使用分类信息和验证信息来学习得到可区分的哈希编码。
3) 针对正负样本不平衡问题,采用了合适的方式进行处理,解决了样本不平衡的问题。
2 方法设计
在图像检索领域,特征的鲁棒性、可区分性以及编码紧凑性对于提高图像检索的准确率和效率至关重要。为了能够同时满足这三个方面的要求,提高图像检索的表现,本文提出了一种深度多监督哈希(DMSH)方法。
我们从DenseNet[24]得到启发,使用Block作为网络的基础结构,在每个Block内部,层与层之间直接连接,保证了最大信息传输。DMSH网络包含38个Block结构,每个结构两两相连,后接两个全连接层和一个特征层。DMSH网络结构如图1所示。

图1 DMSH网络结构
目标函数通过可区分项(分类信息、验证信息)以及哈希项来优化网络,从而学习到具有可区分性的哈希特征。具体来说,网络模型通过顶层的三个约束任务学习得到:
1) 通过分类任务,增加图像的类间距离;
2) 利用验证任务,减小图像的类内距离;
3) 通过哈希监督,获得有效的哈希编码。
训练模型时,图像以组为单位进入网络,先经过一个卷积层,然后经过多个Block结构以及其后的卷积采样层,最后经过两个全连接层和一个特征层,分别进入分类、验证和哈希分支。
在验证分支中,在网络内部组合成图像对,并根据标签信息来判断两图像是否相似。
2.1 分类任务
为了保证编码的可区分性,学习到的特征应该能很好地预测图像的标签信息。因此,分类任务使用softmax层将每幅图像分类到不同的n类中,softmax层输出图像在n类上的概率分布。输入图像i,损失函数表达式为:
(1)

2.2 验证任务
图像检索的准确率相似图像对的特征也尽量相似,非相似图像对的特征也尽量不相似。在衡量特征相似程度时,一般采用三种方法,分别为:L1、L2和余弦相似性。因为网络最终输出结果为哈希特征,而L2在欧氏空间和汉明空间上一致,因此我们使用L2距离衡量特征之间的相似性。
验证任务的目的是使相似的图像映射成相似的特征,非相似图像映射成非相似的特征。因此,相似图像对的特征应该越近越好,而非相似的图像对特征之间的距离应该足够大。
在图像配对时,非相似图像对数要远多于相似图像的对数,从而造成了正负样本不平衡问题。某些分类任务中,非平衡数据的存在,甚至造成了正样本准确率接近100%,而负样本的准确率却只有0~10%。因此我们需要对这种不平衡问题进行处理。应对数据不平衡问题时常用的方法包括采样、数据加成、加权等方法[25]。根据本文的情况,由于数据样本足够多且比例相差不是特别悬殊,因此本文采用加权的方法来解决数据不平衡问题,通过添加惩罚项,增加相似图像对的权重,降低非相似图像对的权重,使得网络能够取得较好的效果。
基于以上考虑,我们设计了验证任务的损失函数:
L2(a1,a2)=αδ(y1=y2)J(a1,a2)+
βδ(y1≠y2)K(a1,a2)
(2)
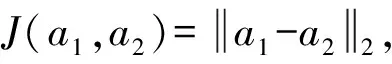
对于所有的图像对,验证任务的损失函数为:
(3)
式中:ai∈{+1,-1},i∈{1,2,…,N}。
经过实验我们发现,处理数据不平衡后,网络性能会有2%~5%的提升。
2.3 哈希监督
为了降低图像检索的空间和时间开销,本文将网络最终的输出为二进制哈希码。然而,如果直接将输出限定为二进制码,反向传播将变得很困难。而如果忽视这个限制,欧式空间和汉明空间会有很大的差异,从而造成检索准确率的下降。针对这个问题,常用的方法是使用sigmoid函数或者tanh函数来近似表示阈值,但是,使用这些非线性的函数会使网络收敛速度变慢。因此,本文在网络输出上直接进行正则化来输出近似二值的特征。
网络使用欧氏距离对输出做一个二进制的限制,使输出近似二值的特征。我们使用基于L2的正则化。为了使输出接近-1或+1,通过增加限制项,使得输出的每一维数据的绝对值与1的方差最大和最小化,即:
(4)
式中:a是一个k维的向量。
有了这个限制,网络产生的输出可以满足近似二进制的要求。此外,我们也测试了L1正则化的方法,最后证明L2优于L1。
另外,对特征加入了平衡性的因素,假设网络中每个哈希码输出的+1和-1的个数尽可能相同,这个要求可以通过让每个训练样本输出的每个bit有50%的概率为+1,50%的概率为-1来达到,如下式所示:
(5)
本文方法受到了文献[15,17]的启发,也使用类似的方法来达到平衡性的要求,提高了特征的表现。
根据上文所述,总体的损失函数如下:
(6)
式中:wi为权重系数。
对于输入的任意图像,都可以从特征层提取一个k维的哈希特征(k=12,24,36,48 bit)。哈希码可以通过使用sgn()函数获得,当ai>0时,sgn()=1; 反之sgn()=-1。
3 实 验
为了证明本文方法的有效性,我们在两个广泛使用的数据集(CIFAR-10、NUS-WIDE)上进行实验。
3.1 数据集
在快速图像检索领域,CIFAR-10和NUS-WIDE是两个常用的数据集,将本文所提到的方法与其他主流方法进行了充分的比较。
CIFAR-10:该数据集由60 000幅32×32的图像组成,共分为10个互不相交的类,每类6 000幅图像。图像类别由手工标注。
NUS-WIDE:该数据集由269 648幅从Flicker上得到的图像组成。每一幅图像被手工标注为81个类别中的某个或某几个用于模型评估。参考DSH的方法,使用最常用的21个类别,每个类别下至少包含5 000幅图像,共计195 834幅。
在基于CNN的哈希方法中,直接使用图像作为网络的输入,对于传统方法,使用512维的GIST特征作为输入。
3.2 评价指标
在我们的实验中,拥有相同标签的图像被归于相似图像,而标签均不相同的图像被认为是非相似图像。对于CIFAR-10,来自相同类的图像被认为是相似图像,反之则认为是非相似图像。对于NUS-WIDE,如果两幅图像至少共享一个标签,则认为它们是相似的,反之认为它们是非相似的。
参照文献[8,23,28],我们使用Mean Average Precision (MAP) 作为评价指标。将数据集随机划分为两部分,分别作为训练集与验证集。给定一幅查询图像,如果查询图与被查询图共享一个标签,那么它们是相似的;否则,它们是非相似的。实验将数据集随机划分为两部分,分别作为训练集与验证集。在本文中,训练集与验证集的比例为5∶1。
3.3 对比实验及分析
我们通过实验结果的对比来验证本文所提到方法的有效性。
将本文提出的DMSH模型的检索效果与其他哈希方法进行比较,包括四个传统网络LSH[9]、MLH[21]、BRE[22]、KSH[5]和四个深度学习网络CNNH[23]、DNNH[16]、DSH[1]、SDH[20]。实验使用特征层作为输出,特征维度分别为12 bit、24 bit、36 bit和48 bit。实验在两个广泛使用的图像检索数据集上进行:CIFAR-10和NUS-WIDE。
表1给出了不同方法在CIFAR-10和NUS-WIDE上的MAP结果。哈希码的长度从12 bit到48 bit。数据显示,本文所提出的DMSH对比其他方法在检索准确率上有较大的提升。特别地,DMSH在两个数据集上的检索性能比DSH分别提升了18.26%和10.26%。在CIFAR-10数据集上,在不同的编码长度上的检索效果,MAP在24 bit时取得最好的效果,从而表明了特征不是越长越好,紧凑的编码由此产生。

表1 DMSH与其他方法在CIFAR-10和NUS-WIDE上的检索MAP对比
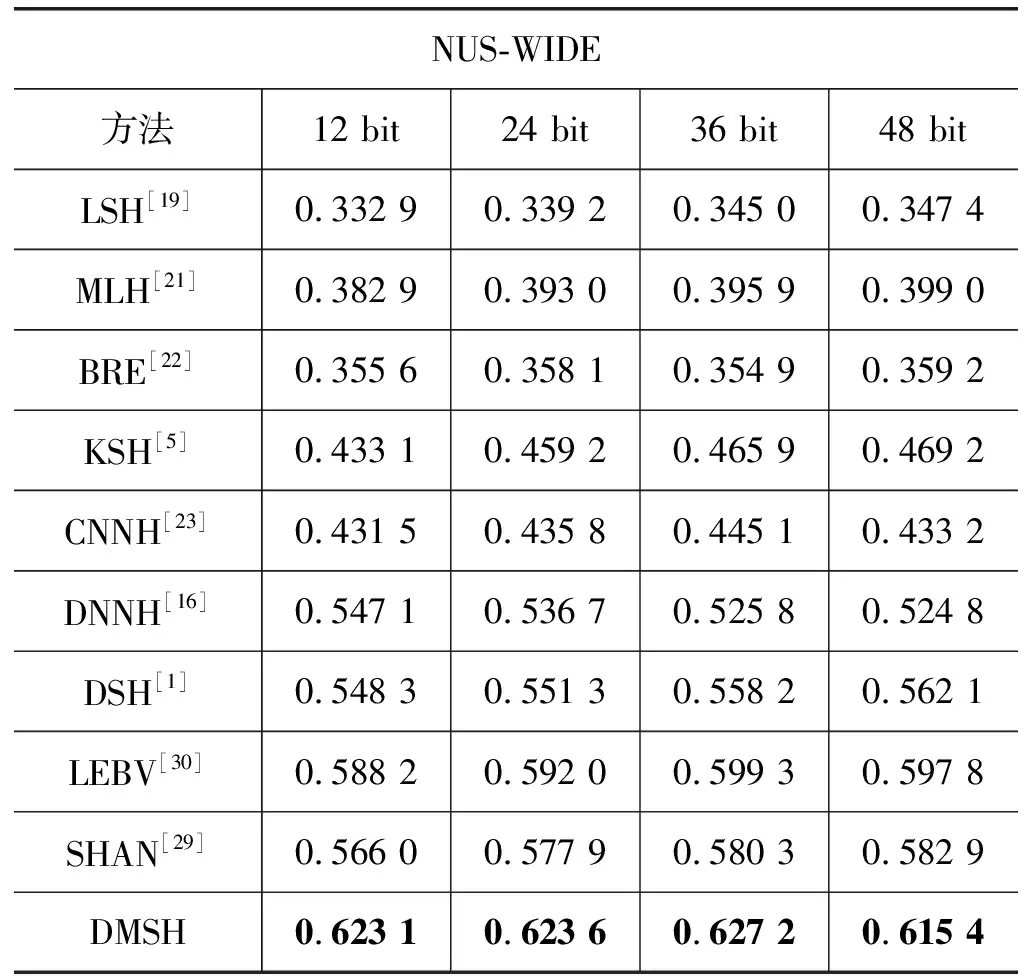
NUS-WIDE方法12 bit24 bit36 bit48 bitLSH[19]0.332 90.339 20.345 00.347 4MLH[21]0.382 90.393 00.395 90.399 0BRE[22]0.355 60.358 10.354 90.359 2KSH[5]0.433 10.459 20.465 90.469 2CNNH[23]0.431 50.435 80.445 10.433 2DNNH[16]0.547 10.536 70.525 80.524 8DSH[1]0.548 30.551 30.558 20.562 1LEBV[30]0.588 20.592 00.599 30.597 8SHAN[29]0.566 00.577 90.580 30.582 9DMSH0.623 10.623 60.627 20.615 4
由表1可知:(1) 本文提出的方法取得了最好的效果并且相比其他哈希方法有显著提升;(2) 通过将图像特征和哈希特征结合到同一个模块中,取得了较好的效果;(3) 深层哈希方法比浅层哈希方法效果好。
DMSH的优势主要体现在下面三个方面:(1) DMSH同时使用了分类和验证信息,而DSH只使用了验证信息;(2) DMSH的网络结构可以更好地挖掘图像的深层信息,DSH使用图的网络略显简单;(3) DMSH增加了对数据不平衡问题的处理。
表2给出了多监督方法与非多监督在CIFAR-10上的MAP结果,可以看出,使用单一验证网络比单一分类网络效果好,而二者结合起来能够取得更好的效果。

表2 多监督方法与非多监督方法的MAP的比较
表3给出了真值特征、哈希特征及其之间的损失,数据表明,真值特征和哈希特征之间损失很小。
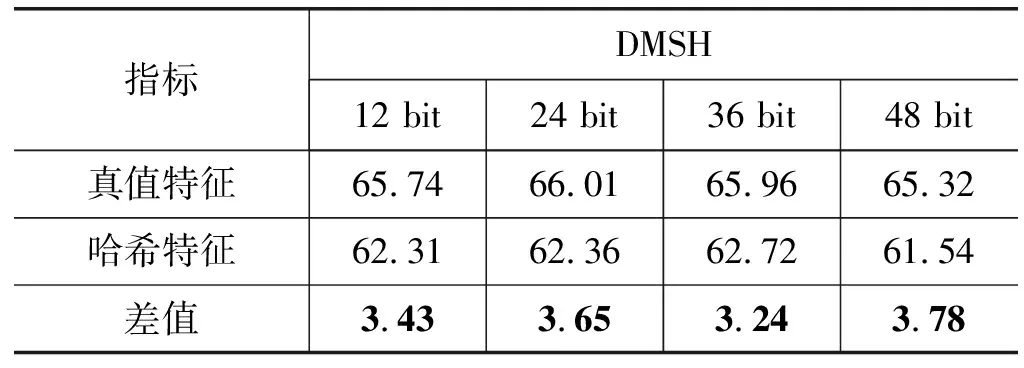
表3 NUS-WIDE哈希效果对比 %
通过实验和分析,我们可以得出以下几个结论:
1) 本文所使用的真值特征和哈希特征之间的损失很小;
2) 同时使用分类信息和验证信息可以更好地保留图像信息,提高检索精度;
3) 深度学习网络可以很好地编码哈希函数,获得优秀的哈希特征。
3.4 编码时间
在实际应用中,对于一个新的图像,应该能够快速地提取其哈希编码。为了比较DMSH与其他8个监督哈希方法的编码时间,在CIFAR-10数据集上分别对24 bit和48 bit的编码长度进行了实验。为了全面的比较,分别在CPU和GPU上对基于卷积神经网络的方法进行了实验,得到传统哈希方法的特征提取时间,实验结果如图2所示。

图2 新图像的编码时间/μs
可以看出,基于卷积神经网络的哈希方法对新图像的编码时间几乎相同,将特征提取时间包括在内后,深度学习哈希方法的编码速度比传统哈希方法快10倍以上。
4 结 语
本文提出了一种基于深度多监督的快速图像检索方法,该方法通过端到端的方式同时得到图像的真值特征和哈希特征,在此基础上,使用多监督信息,达到同时降低类内距离,增加类间距离的目的,大大提升了图像检索网络的准确率和效率。我们将DMSH的检索效果归功于以下三个方面:1) 使用多监督方法,在减小类内距离的同时增加类间距离;2) 采用合适的方法解决了正负样本不平衡的问题;3) 采用端到端的方式得到图像的哈希特征,并使用正则化的方式降低了图像真值特征和哈希特征二者的差异。实验表明,该方法可以快速将任意图像编码成紧凑的二进制哈希编码,有效提升图像检索的准确率。
猜你喜欢
大数据(2021年6期)2021-11-22
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
电脑爱好者(2021年8期)2021-04-21
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电脑爱好者(2020年20期)2020-10-22
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
科学与财富(2017年28期)2017-10-14
